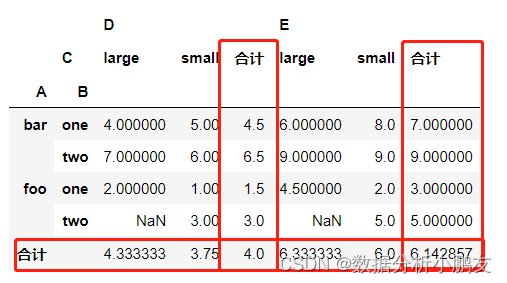
DataFrame.pivot_table(#column to aggregate, optional(要计数的列)
values=None,#column, Grouper, array, or list of the previous(要分组的索引)
index=None,#column, Grouper, array, or list of the previous(要分组的列名)
columns=None,#function, list of functions, dict, default numpy.mean(透视的函数,默认平均值)
aggfunc='mean',#scalar, default None(标量,默认无)
fill_value=None,#bool, default False(合计)
margins=False,#bool, default True(是否删除缺失值)
dropna=True,#str, default 'All'('合计'命名)
margins_name='All',)
三、案例解析
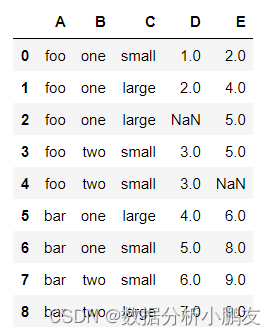
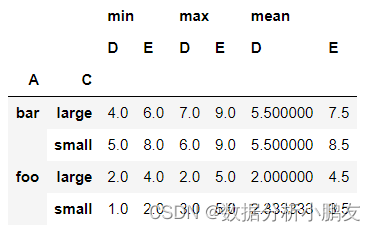
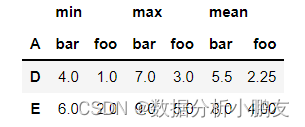
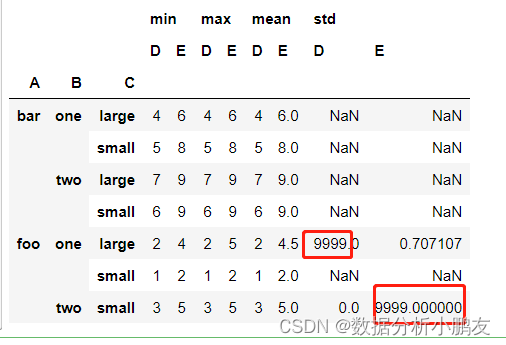
3.1 新建数据集
import pandas as pd
import numpy as np
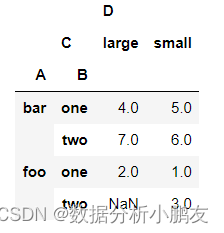
df = pd.DataFrame({"A":["foo","foo","foo","foo","foo","bar","bar","bar","bar"],"B":["one","one","one","two","two","one","one","two","two"],"C":["small","large","large","small","small","large","small","small","large"],"D":[1,2, np.nan,3,3,4,5,6,7],"E":[2,4,5,5, np.nan,6,8,9,9]})




 本文详细介绍了Pandas库中的pivot_table函数,包括其参数解析、实例演示和实用技巧。从新建数据集开始,展示了如何使用pivot_table进行数据透视,如设置不同维度、聚合函数、处理缺失值、计算合计项等。此外,还探讨了自定义聚合函数和填充缺失值的方法,为数据操作提供了实用指南。
本文详细介绍了Pandas库中的pivot_table函数,包括其参数解析、实例演示和实用技巧。从新建数据集开始,展示了如何使用pivot_table进行数据透视,如设置不同维度、聚合函数、处理缺失值、计算合计项等。此外,还探讨了自定义聚合函数和填充缺失值的方法,为数据操作提供了实用指南。



















 2058
2058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









