一、列表 List
list_ = ['a','b','b','c','d','d']
1.1 重复统计
法一
dict([[i,list_.count(i)] for i in list_])
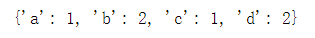
法二
from collections import Counter
Counter(list_)
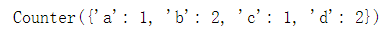
1.2 去重
法一(利用 not in 与append)
dup_list = []
for i in list_:
if i not in dup_list:
dup_list.append(i)
法二(利用set,顺序会乱)
list(set(list_))
法三(利用set + sort,顺序不会乱)
dup_list = list(set(list_))
dup_list.sort(key=list_.index)
二、DataFrame
df = pd.DataFrame(
{
'key1':['a','a','b','b','a','a','b','b'],
'key2':['one','two','one','two','one','one','two','two'],
'key3':[1,2,3,2,1,1,2,3],
}
)

2.1 重复统计
df[df.duplicated()]
df[df.duplicated(['key1','key2'])]
df.value_counts()
df[df.duplicated()].count()
2.2 去重
法一(unique,只能针对1列)
df['key1'].unique()
法二(drop_duplicates,可针对多列)
df.drop_duplicates(
keep = first, # {first:保留第一个,last:保留最后一个}
subset = [], # 默认所有列
inplace = False # 是否在原数据上修改,默认为False
)







 本文介绍了Python中对列表和DataFrame进行重复项统计与去重的方法。对于列表,使用了计数器、不等式操作和集合结合排序的方式;对于DataFrame,利用了`duplicated()`和`drop_duplicates()`函数。此外,还展示了如何查找重复行的频率和去重后的数据。
本文介绍了Python中对列表和DataFrame进行重复项统计与去重的方法。对于列表,使用了计数器、不等式操作和集合结合排序的方式;对于DataFrame,利用了`duplicated()`和`drop_duplicates()`函数。此外,还展示了如何查找重复行的频率和去重后的数据。

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









