






 本文介绍了一个使用Python实现的功能,能够根据用户指定的书目,通过小说网站的索引接口抓取文本。利用requests进行网页请求,BeautifulSoup解析HTML数据。虽然网站结构变化可能导致代码失效,但基本思路仍具有参考价值。
本文介绍了一个使用Python实现的功能,能够根据用户指定的书目,通过小说网站的索引接口抓取文本。利用requests进行网页请求,BeautifulSoup解析HTML数据。虽然网站结构变化可能导致代码失效,但基本思路仍具有参考价值。
功能简介
- 支持人为指定书目,而后根据书名,通过站内的索引接口进行检索
- 抓取对象为一个比较大型小说网站(网站见代码内),当然如果该站内没有对应小说的文本是无法抓取的
- 书名需要指定,如果要获取书单,直接解析网址首页即可获取较多的数据,本人分析了一下网址,没有发现可以直接遍历整个站内地图的方法,所以就没做遍历站内地图的模板(偷偷说一下,新版的网址支持遍历,不过这个已经能实现咱的需求,就懒得去解析了)
实现模块
-
整体流程
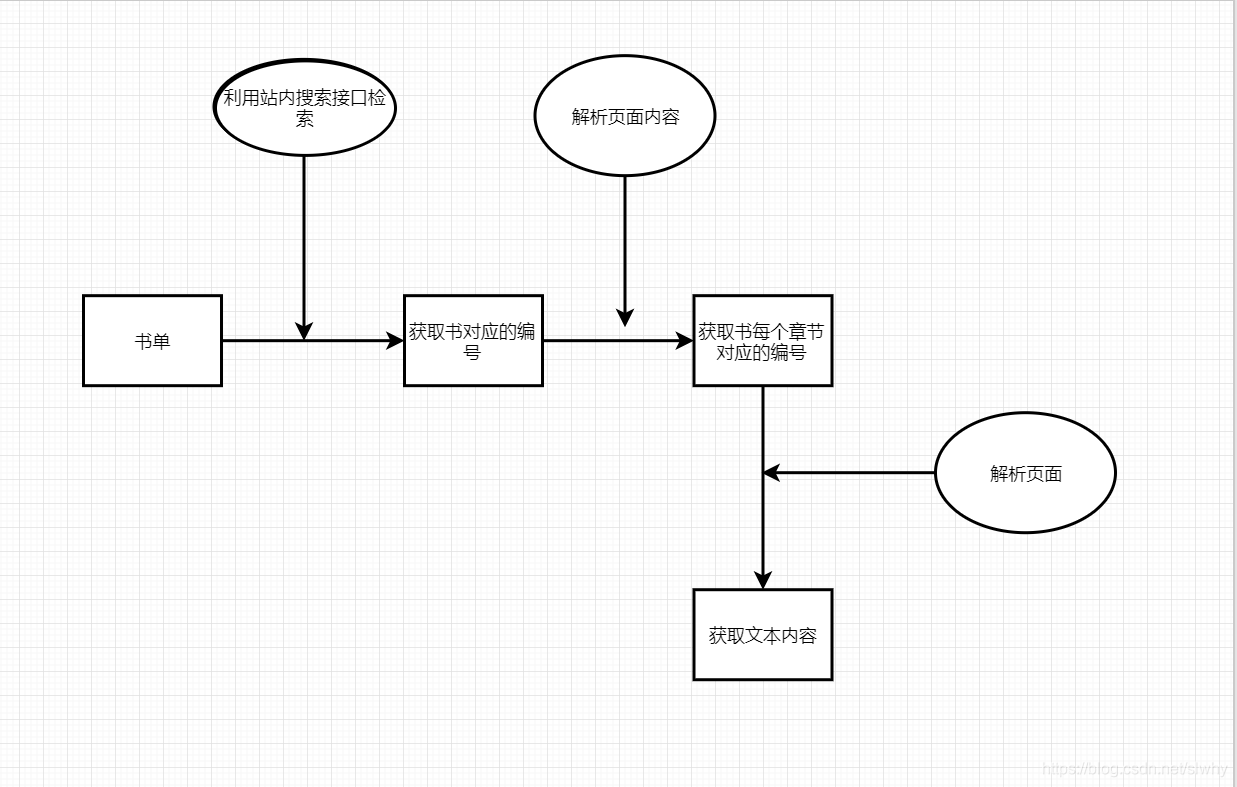
-
用到的模块
requests 请求页面数据
BeautifulSoup 解析html数据
实现代码
'''
-*- coding: utf-8 -*-
@Time : 2019/8/25 22:00
@Author : slwhy
@Desc : 获取已知书单对应的文本内容
'''
import requests
from bs4 import BeautifulSoup
from header import header
def get_data(url, verify):
'''
:param url:
:return:
'''
print(url)
try:
r = requests.get(url, headers=header, verify=verify)
print(r.status_code)
return BeautifulSoup(r.text, "html.parser")
except:
print("请求页面失败")
return ""
def search_novel_num(novel_name):
print("正在搜索小说" + novel_name)
search_url = "https://sou.xanbhx.com/search?siteid=qula&q="
url = search_url + novel_name
soup = get_data(url, False)
for span in soup.findAll("span", class_="s2"):
try:
href = span.a.get("href")
return href
except:
pass
def parser_novel_directory_num(soup):
print("正在解析小说目录")
hrefs = []
for i in soup.findAll("dd"):
try:
href = "https://www.qu.la/" + i.a.get("href")
if "book" in href:
hrefs.append(href)
except:
print("没有获取到目录")
return hrefs
def parser_novel_content(soup):
print("正在解析小说文本内容")
content = ""
for i in soup.findAll("div", id="content"):
try:
content = content + i.get_text()
except:
print("未曾获取到内容数据")
return content
def deal_every_novel(novel_name):
href = search_novel_num(novel_name)
soup = get_data(href, True)
if soup != "":
hrefs = parser_novel_directory_num(soup)
for i in hrefs:
soup = get_data(i, False)
if soup != "":
content = parser_novel_content(soup)
print(content)
if __name__ == '__main__':
deal_every_novel("小说名称")
'''
-*- coding: utf-8 -*-
@Time : 2019/8/25 22:10
@Author : slwhy
@Desc : 请求笔趣阁数据需要用到的头部伪造数据
'''
header = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'max-age=0',
# 'cookie': '__cfduid=ddb553602546b708d684448d505220bb91566289848; UM_distinctid=16cae26709225-084a0b3020f4d-396a4507-1fa400-16cae2670933d9; Hm_lvt_5ee23c2731c7127c7ad800272fdd85ba=1566290261,1566290285,1566290297,1566292685; CNZZDATA1261736110=1523889333-1566289054-https%253A%252F%252Fwww.baidu.com%252F%7C1566294454; Hm_lpvt_5ee23c2731c7127c7ad800272fdd85ba=1566295319; cscpvrich7919_fidx=2',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
爬虫都是具有时效性的,html界面随时会发生变化,可能过段时间代码就不管用,不过思想可以借鉴,如果有什么问题,欢迎指正交流

















 1552
1552




 到【灌水乐园】发言
到【灌水乐园】发言







