




声明:本文只作为技术交流,看小说,请支持正版。
初试使用python自动抓取小说,由于看到同事ui妹子用手机看小说时总是用手机遮住上半部分在看(还以为在看什么见不得人的东西呢,了解后发现是很多小说网站为了盈利头发的广告 都是让人看了比较脸红的广告。。。。)
爬取指南
实现步骤
- 获取小说所有章节以及对应地址
- 遍历所有章节地址,获取其标题以及内容
- 最后,把内容写入文本
1. 获取我们相看的小说的地址
这次是拿 114中文网https://www.114zw.la/这个网站试试手
选一个自己相看的小说,我这里选择《医婿》作为例子,地址:https://www.114zw.la/book/9237/
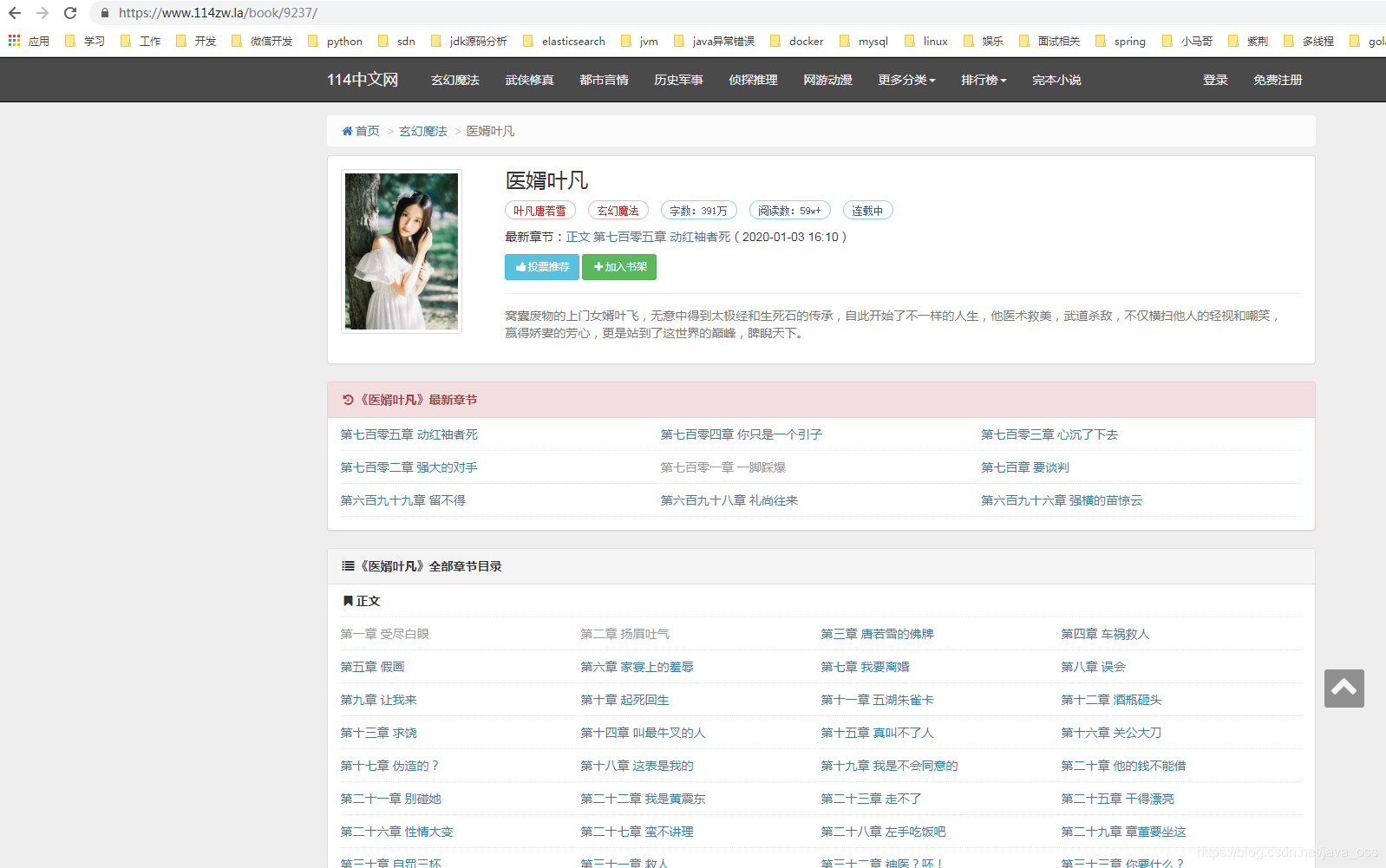
在上图看到 小说的所有章节都在上面,我们首先获取所有章节的地址,在上面页面点击右键查看网页源代码如下:

鼠标滑动到下面我们就能看到有个div标签里面全是每一章节的地址,这里我们留意一下框出来的div标签,可以看一下所有的这个小说的章节地址都包含在了
<div class="panel panel-default" id="list-chapterAll">

下面直接贴代码:
# 导入requests库
import requests
# 导入文件操作库
import codecs
from bs4 import BeautifulSoup
import sys
import importlib
importlib.reload(sys)
# 给请求指定一个请求头来模拟chrome浏览器
global headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'}
server = 'https://www.114zw.la/book/9237/'
# 星辰变地址
book = 'https://www.114zw.la/book/9237/'
# 定义存储位置
global save_path
save_path = 'G:/医婿叶凡'
# 获取章节内容
def get_contents(chapter):
req = requests.get(url=chapter)
html = req.content
html_doc = str(html, 'gbk')
bf = BeautifulSoup(html_doc, 'html.parser')
texts = bf.find_all('div', id="content")
# 获取div标签id属性content的内容 \xa0 是不间断空白符
content = texts[0].text.replace('\xa0' * 4, '\n')
return content
# 写入文件
def write_txt(chapter, content, code):
with codecs.open(chapter, 'a', encoding=code)as f:
f.write(content)
# 主方法
def main():
res = requests.get(book, headers=headers)
html = res.content
html_doc = str(html, 'gbk')
# 使用自带的html.parser解析
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
# 获取所有的章节,这里就是我们上面从网页源代码里面找到的div
a = soup.find('div', id='list-chapterAll').find_all('a')
print('总章节数: %d ' % len(a))
for each in a:
try:
chapter = server + each.get('href')
content = get_contents(chapter)
chapter = save_path + "/" + each.string + ".txt"
write_txt(chapter, content, 'utf8')
except Exception as e:
print(e)
if __name__ == '__main__':
main()以上代码能成功运行爬取数据,这里没处理一章有两页的情况,其实都是有规律的 就是_2就是第二页,实例我就不做处理,有兴趣的小伙伴可以自己处理一下

















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









