




Embedding概念的提出并不是源自Transformer,而是来源于深度学习,但是Transformer中的Embedding却是区别于深度学习中的Embedding的,而且Transformer的Embedding成为了该模型中一个核心之一。
1. Transformer中Embedding的概念
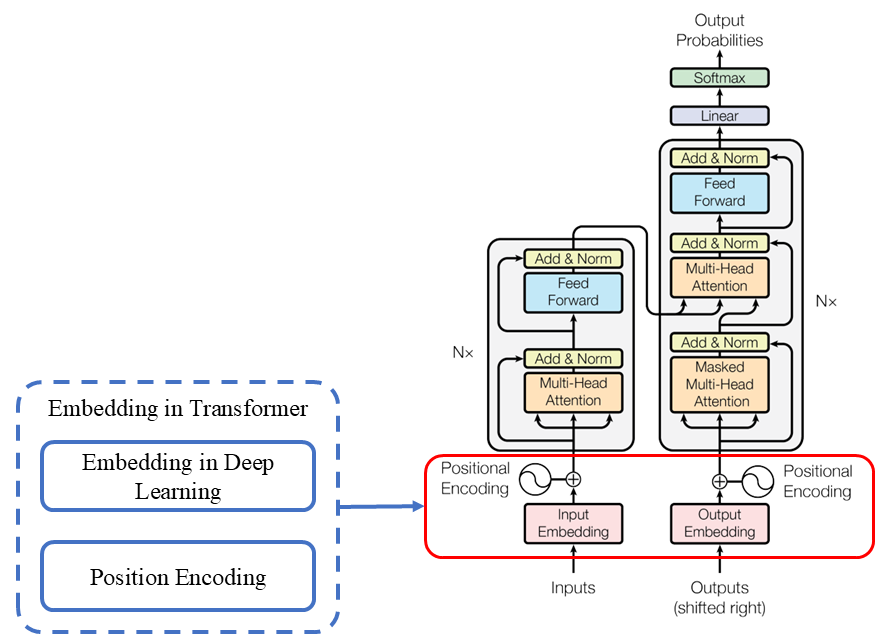
简单概括Transformer中Embedding概念包含2层含义,一是深度学习中的Embedding,二是Position Encoding,如下图所示:
Embedding in Deep Learning
Embedding in Deep Learning中的作用主要可以概括为以下几项:
- 将原来离散的向量转换为连续型(近似连续)的向量:将孤立的、离散的符号(如单词ID、类别ID)转换为连续的数值向量。计算机(神经网络)非常擅长处理连续数值。
- 将原来高维、稀疏的向量转为低维、密集的向量:相比One-Hot编码(词汇表有5万个词,向量就是5万维),Embedding向量通常是50维、100维、300维,极大地降低了计算复杂度;One-Hot向量是稀疏的(绝大部分是0,只有一个1),而Embedding向量是密集的,每一个维度都包含有意义的信息。
- 向量转化的过程可学习:向量Embedding的过程实际就是张量乘法的过程,而向量所乘的转换张量并不是静态的,而是通过训练的过程,按照某种最优标准一步一步获得的,也就是转换过程是一个动态过程。
一般来讲,进行Embedding得到张量的维数用dmodel来表示。
无论是Tensorflow还是Pytorch都提供了Embedding的API,下面给出一个Tensorflow实现Embedding的实例:
import tensorflow as tf
vocab_size = 10000 # 词汇表的大小
embedding_dim = 16 # 每个单词向量的维度
embedding_layer = tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim)
# 假设我们有以下批量的整数索引
indices = tf.constant([[1, 2, 3], [4, 5, 6]] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









