




 本文详细记录了在Ubuntu系统上安装显卡驱动、CUDA、CUDNN及PyTorch和TensorFlow的步骤,包括添加PPA、处理gcc验证问题、链接符号文件错误,并提供安装验证方法和常见错误解决方案。
本文详细记录了在Ubuntu系统上安装显卡驱动、CUDA、CUDNN及PyTorch和TensorFlow的步骤,包括添加PPA、处理gcc验证问题、链接符号文件错误,并提供安装验证方法和常见错误解决方案。
折腾了两天,整理一下安装过程。
一、安装显卡驱动
参考https://zhuanlan.zhihu.com/p/59618999
第一种安装方法(推荐)
ubuntu-drivers devices #查看显卡硬件型号,其中推荐安装的版本号带有recommended
sudo ubuntu-drivers autoinstall # 同意安装推荐版本
#或者 sudo apt install nvidia-xxx 安装指定版本
第二种安装方法
sudo add-apt-repository ppa:graphics-drivers/ppa#添加 PPA 软件仓库
sudo apt update
sudo apt install nvidia-xxx
nvidia-smi 出现界面即成功,也可以查看nvidia-settings。
二、安装cuda
安装run包(推荐)
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run
# 有wget命令的,可以先行打开网页下载,省这一步。
sudo sh cuda_11.1.0_455.23.05_linux.run
因为已经装了驱动,打开后点击contine,输入accept,然后将driver的X去掉点install。
或者安装deb包
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda-repo-ubuntu2004-11-1-local_11.1.0-455.23.05-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-1-local_11.1.0-455.23.05-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-1-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
设置环境变量
sudo gedit ~/.bashrc
打开配置表在末尾输入以下三行:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.1/lib64
export PATH=$PATH:/usr/local/cuda-11.1/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.1
source ~/.bashrc #更新配置表
输入nvcc -V 或者nvcc --version,有出现版本信息就成功。
错误:
安装时出现:Failed to verify gcc version. See log at /var/log/cuda-installer.log for details.
解决方法:sudo apt install gcc ,接着通过gcc -v查看是否有版本信息。
安装之前一定要卸载NVIDIA驱动,CUDA,CUDNN,再进行安装,否则会报错。
三、安装cudnn,下载cuda对应的cudnn文件
下载
https://developer.nvidia.com/rdp/cudnn-download
需要先注册登录,然后下载指定版本的cudnn,有四个,其中有一个压缩包和三个deb包。
安装
tar -xzvf cudnn-x.x-linux-x64-v8.x.x.x.tgz #也可以直接解压
sudo cp cuda/include/cudnn*.h /usr/local/cuda/include #复制到指定文件夹
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo cp cuda/include/* /usr/local/cuda/include/
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
测试使用cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2,出现以下就成功:

接下来的安装顺序是:
sudo dpkg -i libcudnn8_x.x.x-1+cudax.x_amd64.deb #出现错误以下有解决办法
sudo dpkg -i libcudnn8-dev_8.x.x.x-1+cudax.x_amd64.deb
sudo dpkg -i libcudnn8-samples_8.x.x.x-1+cudax.x_amd64.deb
验证:
cp -r /usr/src/cudnn_samples_v8/ $HOME
cd $HOME/cudnn_samples_v8/mnistCUDNN
make clean && make
./mnistCUDNN
【显示test passed说明安装成功!】
我在安装libcudnn8_x.x.x-1+cudax.x_amd64.deb时出现错误:
/sbin/ldconfig.real: /usr/local/cuda/lib64/libcudnn_cnn_infer.so.8 is not a symbolic link
/sbin/ldconfig.real: /usr/local/cuda/lib64/libcudnn_ops_infer.so.8 is not a symbolic link
/sbin/ldconfig.real: /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8 is not a symbolic link
/sbin/ldconfig.real: /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8 is not a symbolic link
/sbin/ldconfig.real: /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8 is not a symbolic link
/sbin/ldconfig.real: /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8 is not a symbolic link
/sbin/ldconfig.real: /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8 is not a symbolic link
解决方法:
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/llibcudnn_adv_train.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
sudo ln -sf /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8.0.5 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.8
四、安装anacodna
下载
https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
在清华开源镜像中找到安装包,我选择的是Anaconda3-2020.11-Linux-x86_64.sh。
安装
sudo sh Anaconda3-2020.11-Linux-x86_64.sh
添加环境变量
echo 'export PATH="~/anaconda3/bin:$PATH"'>>~/.bashrc
source ~/.bashrc
输入conda -V 输出指定版本即成功。
其他
其他
- 打包conda环境
conda pack -n envname conda pack -n envname -o /path/to/envname.tar.gz - 复原conda环境
cd /path/to/miniconda3/envs/ mkdir envname tar -xzvf /path/to/envname.tar.gz -C /path/to/miniconda3/envs/envname
五、安装pytorch,tensorflow
pytorch从https://download.pytorch.org/whl/torch_stable.html离线下载
tensorflow和其他的whl可以从https://pypi.org/离线下载
下载后使用pip install xxx.whl进行安装。
【装完测试,出现Ture就成功】
source activate base#base是环境,这里使用的是默认的
python
import torch
torch.cuda.is_available()
六、安装nvidia-docker
离线安装包,可省以下步骤
首先安装docker
sudo apt-get install docker.io
【docker -v出现对应版本就成功】
然后安装nvidia-docker,参照官网步骤来:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
最后就sudo apt-get install -y nvidia-docker
输入nvidia-docker有弹出就成功了
安装错误:
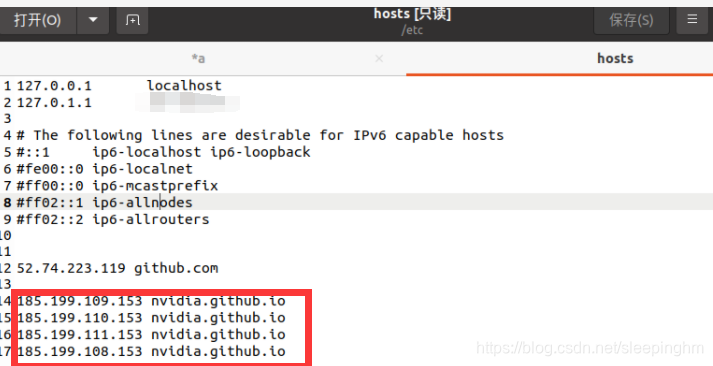
一直卡在无法连接到NVIDIA-GITHUB.IO
打开该网站http://tool.chinaz.com/dns/?type=1&host=nvidia.github.io&ip=
然后修改hosts: sudo gedit /etc/hosts
复制进去即可
docer启动错误:
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/images/json: dial unix /var/run/docker.sock: connect: permission denied
输入即可:sudo chmod a+rw /var/run/docker.sock
一些docker操作:
搜索镜像:docker search xxx
下载镜像:docker pull xxx
查看镜像:docker images
修改镜像名字:docker tag IMAGE_ID REPOSITORY:TAG
导出镜像:docker save -o savefilename 要保存的镜像
导入保存的镜像:docker load --input savefilename
查看容器:docker ps -a
启动容器:sudo docker run --ipc=host --gpus all -v /media:/media -it container_name
停止容器:sudo docker stop/kill container_ID
停止所有容器:docker stop $(docker ps -aq)
删除所有容器:docker rm $(docker ps -aq)
保存容器为镜像:sudo docker commit CONTAINER_ID REPOSITORY:TAG
七、安装KALDI
通过docker运行kaldi(推荐)
从容器中启动,比较方便,已经都编译好了。
从https://registry.hub.docker.com/r/kaldiasr/kaldi/tags搜索到我需要的kaldi版本,我想要的是带有gpu版本的cuda,输入命令docker pull kaldiasr/kaldi:gpu-latest。
从命令行启动docker:
sudo docker run --ipc=host --gpus all -v /home:/home -it kaldiasr/kaldi:gpu-latest
#-v 命令是从本地/media挂载到docker镜像的/home中,可以直接从镜像里面进入本地目录。
从vscode启动docker:
参考这篇博客的步骤
https://blog.youkuaiyun.com/weixin_40641725/article/details/105512106
本地编译Kaldi
参考这篇博客的步骤
https://zhuanlan.zhihu.com/p/44483840
安装好了之后需要把Kaldi的相关工具加到环境变量中,比如把下面的内容加到~/.bashrc下并且重新打开终端。
export KALDI_ROOT=/home/user/kaldi#KALDI_ROOT设置成kaldi的根目录。
PATH=$KALDI_ROOT/tools/openfst:$PATH
PATH=$KALDI_ROOT/src/featbin:$PATH
PATH=$KALDI_ROOT/src/gmmbin:$PATH
PATH=$KALDI_ROOT/src/bin:$PATH
PATH=$KALDI_ROOT/src/nnetbin:$PATH
export PATH
如果运行copy-feats能出现帮助文档,则说明安装成功。
验证是否
REFERENCE
https://www.freesion.com/article/5779967644/



















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











