




 本文概述了视频目标检测领域的研究进展,重点关注精度提升和速度优化的方法,如结合跟踪的检测与追踪、光流引导特征融合、注意力机制等。文章列举了多个关键论文并讨论了常用数据集和评价标准。
本文概述了视频目标检测领域的研究进展,重点关注精度提升和速度优化的方法,如结合跟踪的检测与追踪、光流引导特征融合、注意力机制等。文章列举了多个关键论文并讨论了常用数据集和评价标准。
对目前看过的视频目标检测论文做一个简单的综述,也欢迎大家补充一些其他遗漏掉的,不错的视频目标检测论文。持续更新。。。
github:https://github.com/breezelj/video_object_detection_paper
论文详细笔记:https://blog.youkuaiyun.com/breeze_blows/article/details/104533004
参考链接:原文出处
目标检测已经做到很成熟了,但是视频目标检测确实还在发展之中,视频目标检测主要挑战在于在长视频中往往有些帧的质量非常差,比如目标物体出现以下情况,单纯的目标检测算法难以胜任(图片来自于FGFA论文)
既然单帧图片进行检测效果不好,视频目标检测的主要考虑就是如何去融合更多的时空上面的特征,比如从bbox,frame,feature,proposal等level进行特征融合,从而弥补在训练或者检测中单帧得到的特征的不足。大概就是从上面level上面去融合特征,怎么去融合特征。
数据集:常用的数据集就是ImageNet VID dataset, 其中训练集包含了3862个video snippets,验证集含有555个snippets。共有30个类,这些类别是ImageNet DET dataset类别的子集。有时候训练集也可以用ImageNet DET这30个类的图片集。
评价标准:沿用目标检测中的mAP,但是会根据目标的速度分为mAP(slow), mAP(medium), mAP(fast), 划分标准按照FAFG论文中的方法为求当前帧与前后10帧的IOU的平均得分值score,the objects are divided into slow (score > 0.9), medium (score ∈ [0.7, 0.9]), and fast (score < 0.7) groups。
下面是按照自己的理解进行的分类与整理。主要有两个方向,一个是关注于精度的提升即Accuracy,另外一个就是注重速度即speed,想达到Accuracy和speed的tradeoff。
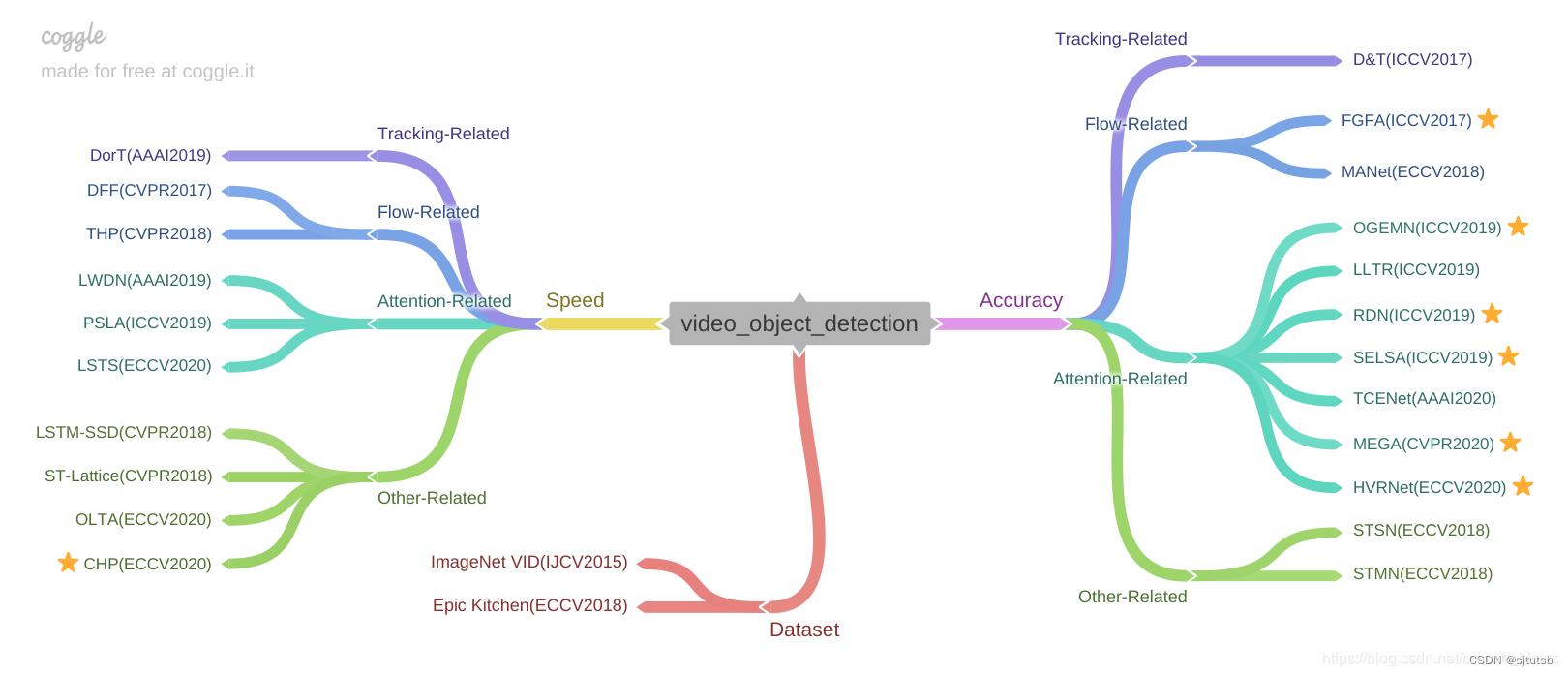
目录
1.Accuracy
Tracking-Related
Flow-Related
Attention-Related
Other-Related
2.Speed
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









