




 本文深入探讨了CBOW和Skip-gram两种词嵌入模型,详细讲解了它们如何简化神经网络结构,提高训练效率。CBOW模型通过上下文预测中心词,而Skip-gram则相反,通过中心词预测上下文,两者都使用softmax计算词概率分布。
本文深入探讨了CBOW和Skip-gram两种词嵌入模型,详细讲解了它们如何简化神经网络结构,提高训练效率。CBOW模型通过上下文预测中心词,而Skip-gram则相反,通过中心词预测上下文,两者都使用softmax计算词概率分布。
CBOW模型和Skip-gram模型
在前面提到的神经网络语言模型、c&W模型,都没有缺少隐藏层,而模型运算的高消耗都在输入层到隐藏层的矩阵运算中,如果能减少这部分开销,那么模型会更加高效。而CBOW模型和Skip-gram模型就属于这一类模型。
CBOW模型
CBOW模型的思想与c&w模型的思想类似:输入上下文词语,预测中心目标词。
与c&w模型以优化正样本与负样本之间的差异不同,CBOW模型仍然是以预测目标词的概率为最终目标来建模的。CBOW模型在网络结构上进行了两点简化:
- 输入层不再是上下文词对应的词向量拼接,而是忽略了词序信息,直接采用所有上下文词向量的平均值
- 省略了隐藏层,输入层直接与输出层相连,采用logistic回归的形式计算中心词的概率
通过上面两点的优化,减少了矩阵运算,也较少了一次层之间的运算,使得模型的效率得到了提升。
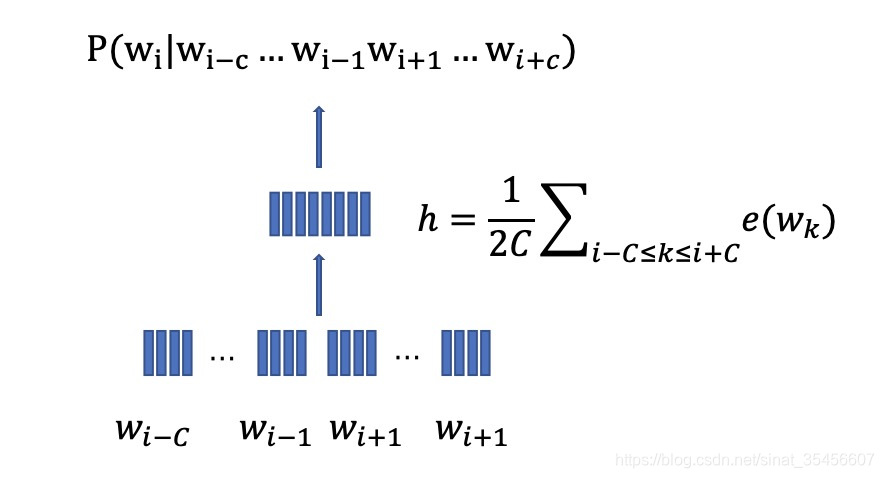
- 依旧是从训练语料中选取任意的n元组(n=2C+1)(n=2C+1)(n=2C+1): (wi,C)=(wi−C...wi−1wiwi+1...wi+C)(w_i,C)=(w_{i-C}...w_{i-1}w_iw_{i+1}...w_{i+C})(wi,C)=(wi−C...wi−1wiwi+1...wi+C)
- 将WC=wi−C...wi−1wi+1...wi+CWC=w_{i-C}...w_{i-1}w_{i+1}...w_{i+C}WC=wi−C...wi−1wi+1...wi+C作为输入,将计算上下文词向量的平均值:h=12C∑i−C<=k<=i+Ce(wk)h= \frac{1}{2C}\sum_{i-C<=k<=i+C}e(w_k)h=2C1∑i−C<=k<=i+Ce(wk)
- 直接用softmax利用上面计算的平均值作为输入,来预测中心目标词的概率:p(wi∣WC)=exp(h⋅e(wi))∑k=1∣v∣exp(h⋅e(wk))p(w_i|WC)=\frac{exp(h·e(w_i))}{\sum^{|v|}_{k=1}exp(h·e(w_k))}p(wi∣WC)=∑k=1∣v∣exp(h⋅e(wk))exp(h⋅e(wi))
- CBOW模型的目标函数是最大化所有词概率的对数似然:
- L∗=argmaxL∑wi∈Vlog(p(wi∣WC))L^*=argmax_L\sum_{w_i\in{V}}{log(p(w_i|WC))}L∗=argmaxL∑wi∈Vlog(p(wi∣WC))
Skip-gram模型
与CBOW利用上下文来预测中心目标词不同,Skip-gram反过来利用中心词来预测所有上下文词汇:
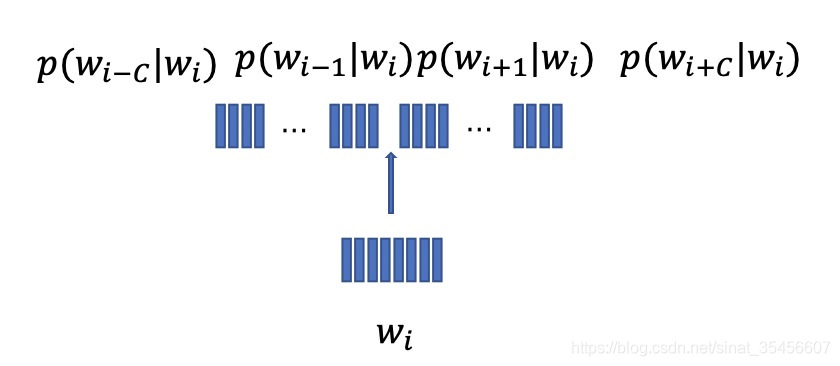
- 依旧是从训练语料中选取任意的n元组(n=2C+1)(n=2C+1)(n=2C+1): (wi,C)=(wi−C...wi−1wiwi+1...wi+C)(w_i,C)=(w_{i-C}...w_{i-1}w_iw_{i+1}...w_{i+C})(wi,C)=(wi−C...wi−1wiwi+1...wi+C)
- skip-gram模型是利用中心词wiw_iwi的词向量e(wi)e(w_i)e(wi)来预测上下文WC=wi−C...wi−1wi+1...wi+CWC=w_{i-C}...w_{i-1}w_{i+1}...w_{i+C}WC=wi−C...wi−1wi+1...wi+C中每个词的概率:
- p(wc∣wi)=exp{e(wi)⋅e(wc)}∑k=1∣V∣e(wi)w(wk)p(w_c|w_i)= \frac{exp\{e(w_i)·e(w_c)\}}{\sum^{|V|}_{k=1}{e(w_i)w(w_k)}}p(wc∣wi)=∑k=1∣V∣e(wi)w(wk)exp{e(wi)⋅e(wc)}
- skip-gram通过优化词向量矩阵L来最大化所有上下文的对数似然:
- L∗=argmax∑wi∈∣V∣∑wc∈WCp(wc∣wi)L^*=argmax\sum_{w_i\in |V|}{\sum_{w_c\in WC}{p(w_c|w_i)}}L∗=argmax∑wi∈∣V∣∑wc∈WCp(wc∣wi)
总结
- CBOW和skip-gram模型极大的简化了神经网络结构
- 但是仍然需要使用到softmax函数计算词表V中所有词汇的概率分布
衍生
还有负采样(NEG)技术可以用来优化模型的训练效率。
以skip-gram为例,通过中心词wiw_iwi预测上下文WC=wi−C...wi−1wi+1...wi+CWC=w_{i-C}...w_{i-1}w_{i+1}...w_{i+C}WC=wi−C...wi−1wi+1...wi+C中的任意词wcw_cwc,负采样技术是为每个正样本wcw_cwc从某个概率分布pn(w)p_n(w)pn(w)中任意选择个负样本{w1′,w2′,...,wk′}\{w'_1,w'_2,...,w'_k\}{w1′,w2′,...,wk′},然后最大化正样本的似然,最小化负样本的似然来进行优化(一般来说当K选为5的时候可以取得很好的性能)。

















 3036
3036


 到【灌水乐园】发言
到【灌水乐园】发言








