




 本文详细介绍了C&W模型及其损失函数,并对比了Word2Vec-CBOW模型的结构特点,深入探讨了这两种模型在自然语言处理中的应用。
本文详细介绍了C&W模型及其损失函数,并对比了Word2Vec-CBOW模型的结构特点,深入探讨了这两种模型在自然语言处理中的应用。
C&W Loss Function
∑ ( w , c ) ∈ D ∑ w ′ ∈ V m a x ( 0 , 1 − s c o r e ( w , c ) + s c o r e ( w ′ , c ) \sum_{(w,c)\in D}\sum_{w'\in V}max(0, 1-score(w,c)+score(w',c) ∑(w,c)∈D∑w′∈Vmax(0,1−score(w,c)+score(w′,c)
想起了机器视觉课上老师讲的损失函数。
对于每个样本,其错误分类的得分减去正确分类的得分,再加一个鲁棒值(自己起的名)1,作为整个数据集的损失。
C&W 模型结构
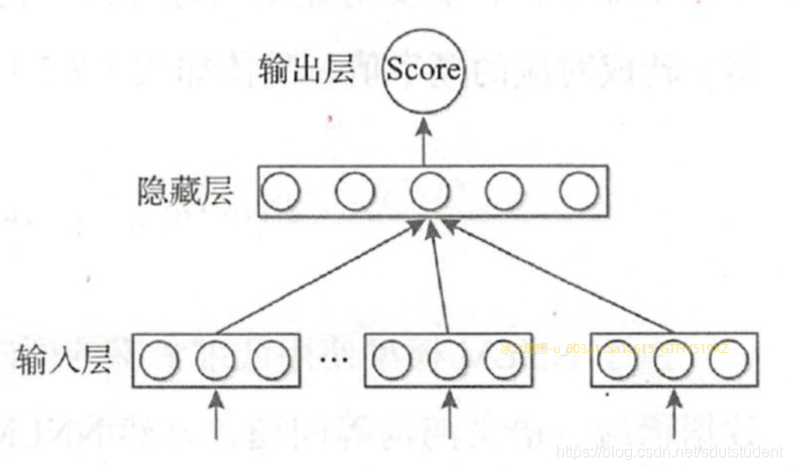
Word2Vec - CBOW
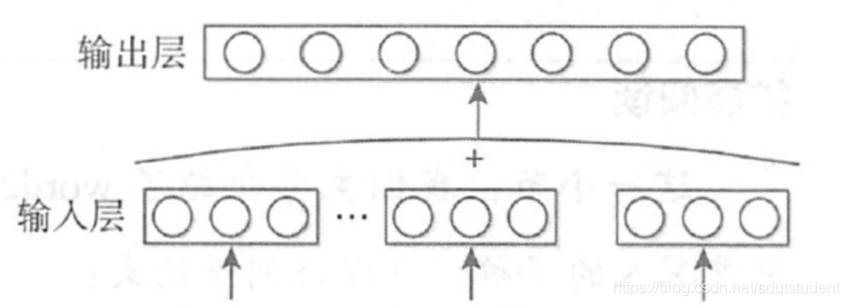
模型很简单:将上下文向量求和,作softmax,即得到结果。
输入:上下文。
输出:中间词是哪个词。
与NNLM相比:
- 去掉了隐藏层。
- 用输入向量的和代替了向量的拼接。
在代码实现部分,有一个很实用的技巧,将index转化成onehot向量,不需要用OnehotEncoder,可以用torch.eye(vocab_size)[index],得到的行向量即onehot向量。

















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









