







本课程根据李宏毅2020课程中的Transformer章节进行学习
对视频学习过程进行记录
Transfomer是一个seq2seq结构,重点使用的self-attention layer取代了RNN layer
一般情况下处理一个sequence时候最常使用的RNN处理:
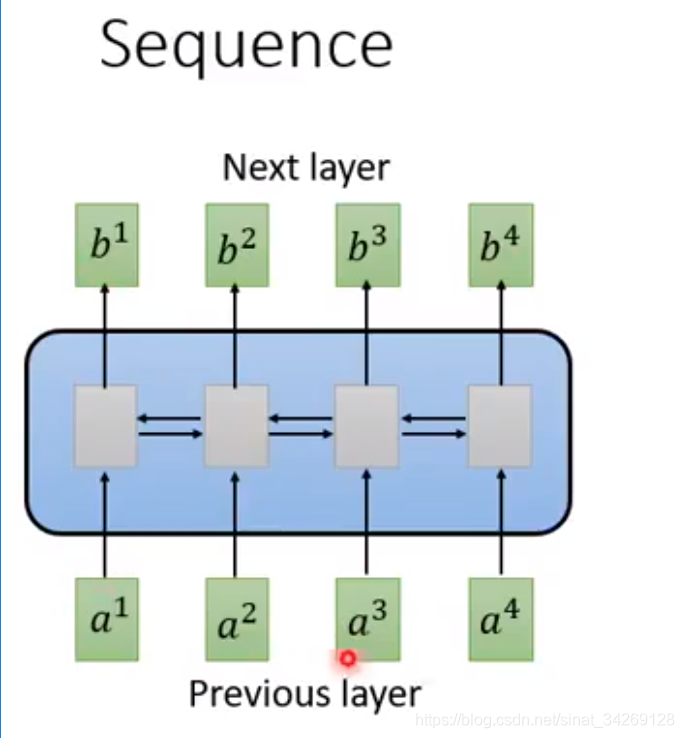
a为输入层,b为输出层,但是这种使用RNN的结构有一个很大的缺点,就是不能够平行化(所谓的平行化就是,RNN在处理得到b4的时候,需要先从a1-->a2-->a3-->a4)不能够并行处理,是一个串行过程。
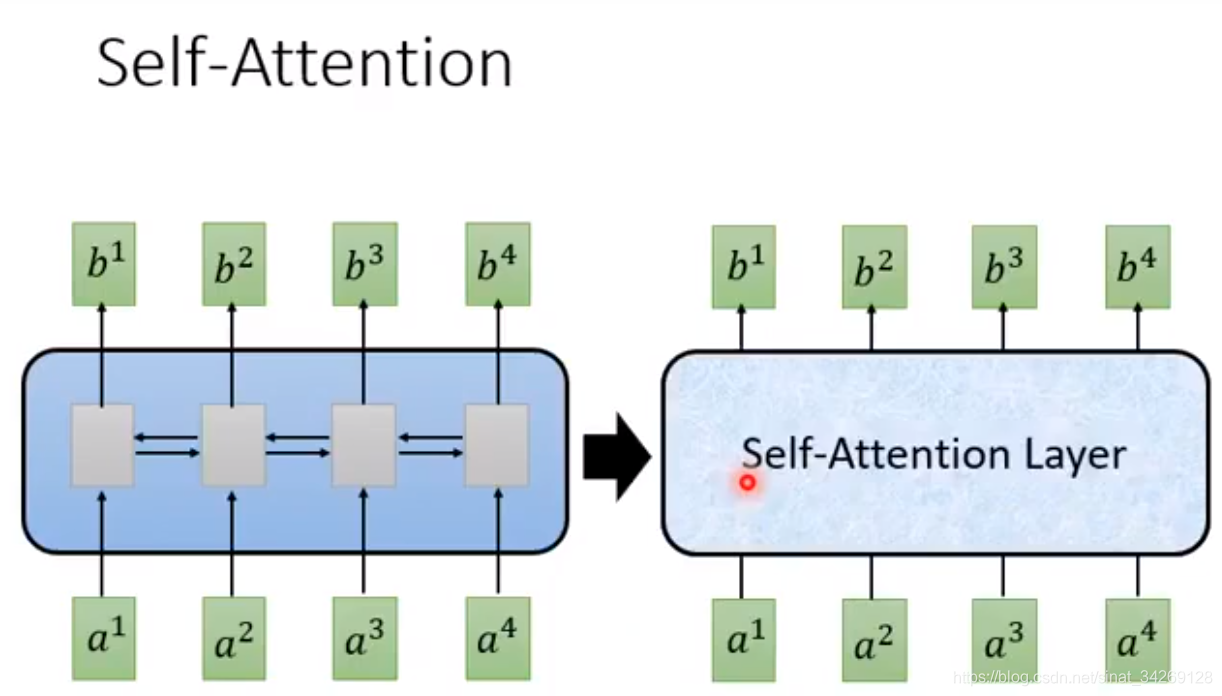
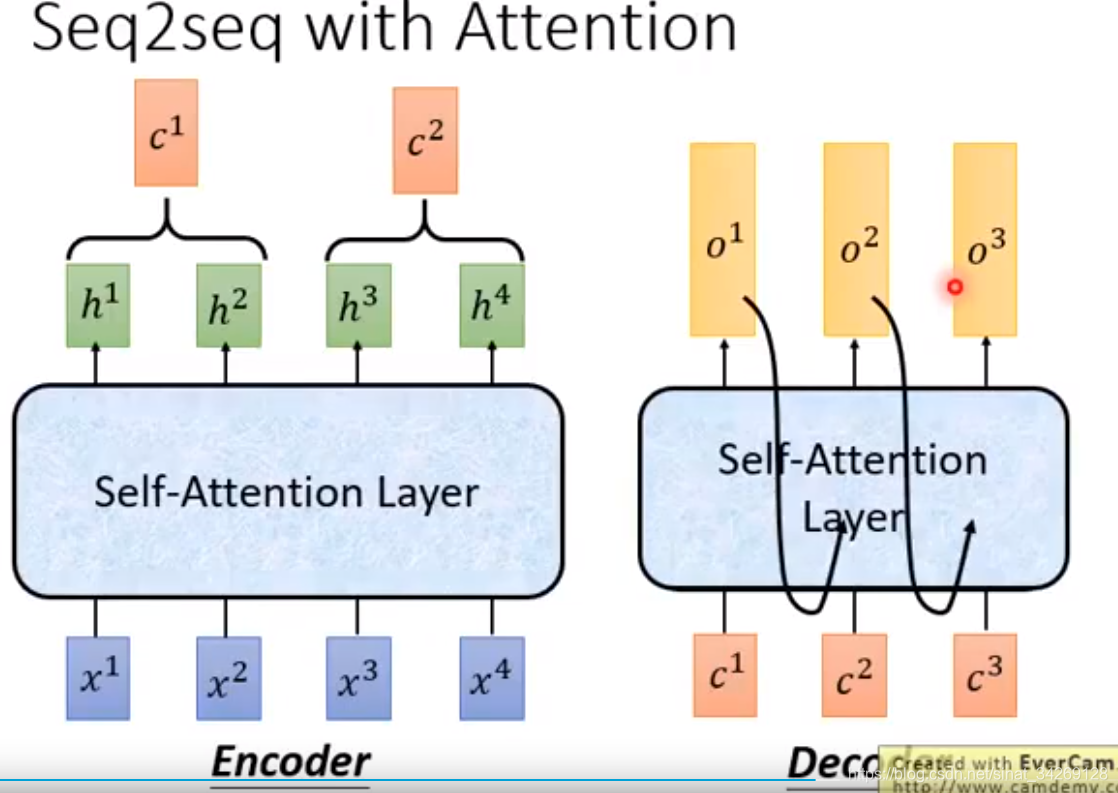
针对上面不能够并行生成b的问题,提出了一个新的layer,代替RNN,同样输入一个seq,输出一个seq,提出的这个self-attention层也具备RNN功能。并且输出的每个b,也理解了输入所有向量的上下文信息。最关键的是输出的每个b可以同时是生成,并行产生每个b。
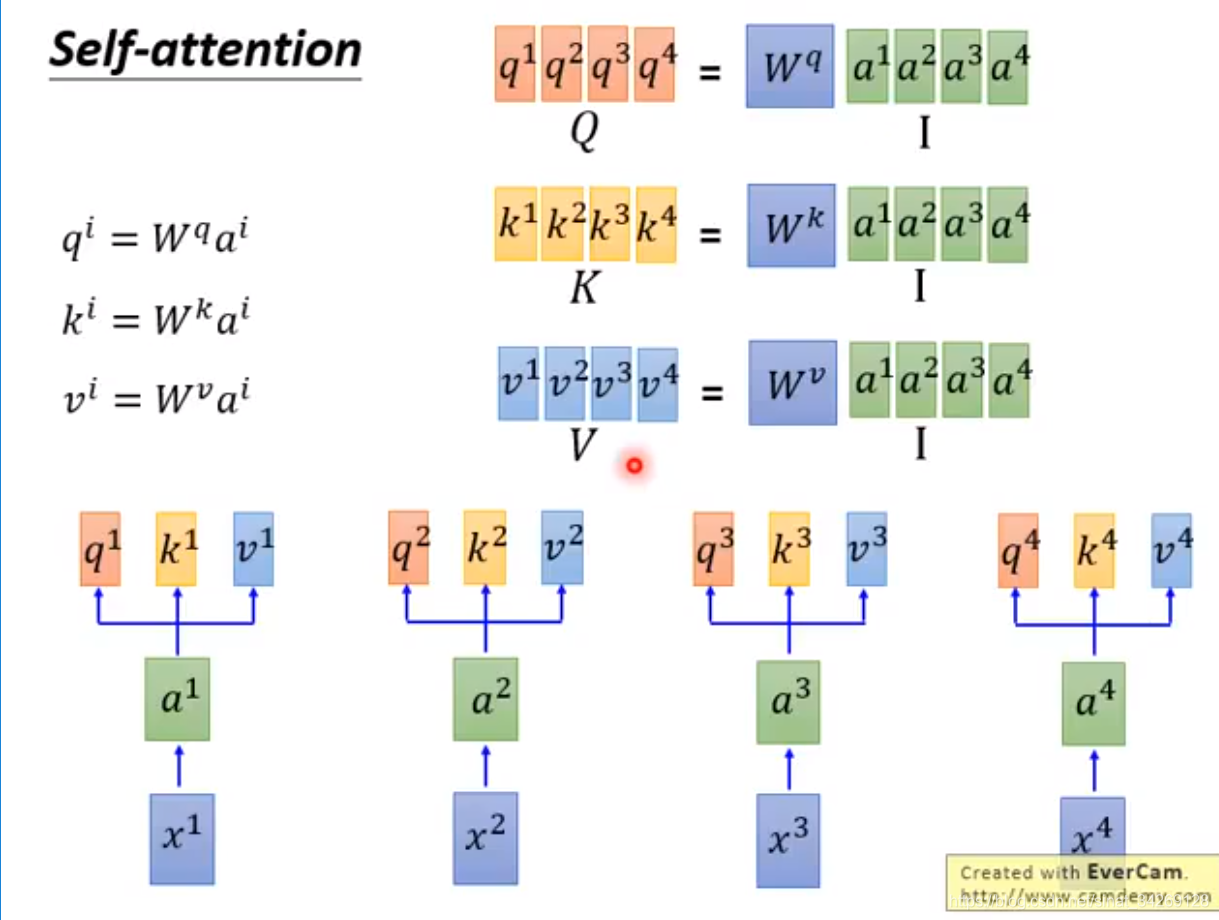
下面是一个self-attention内部计算过程(q,k,v 分别是a与不同的权重矩阵相乘得到的。)
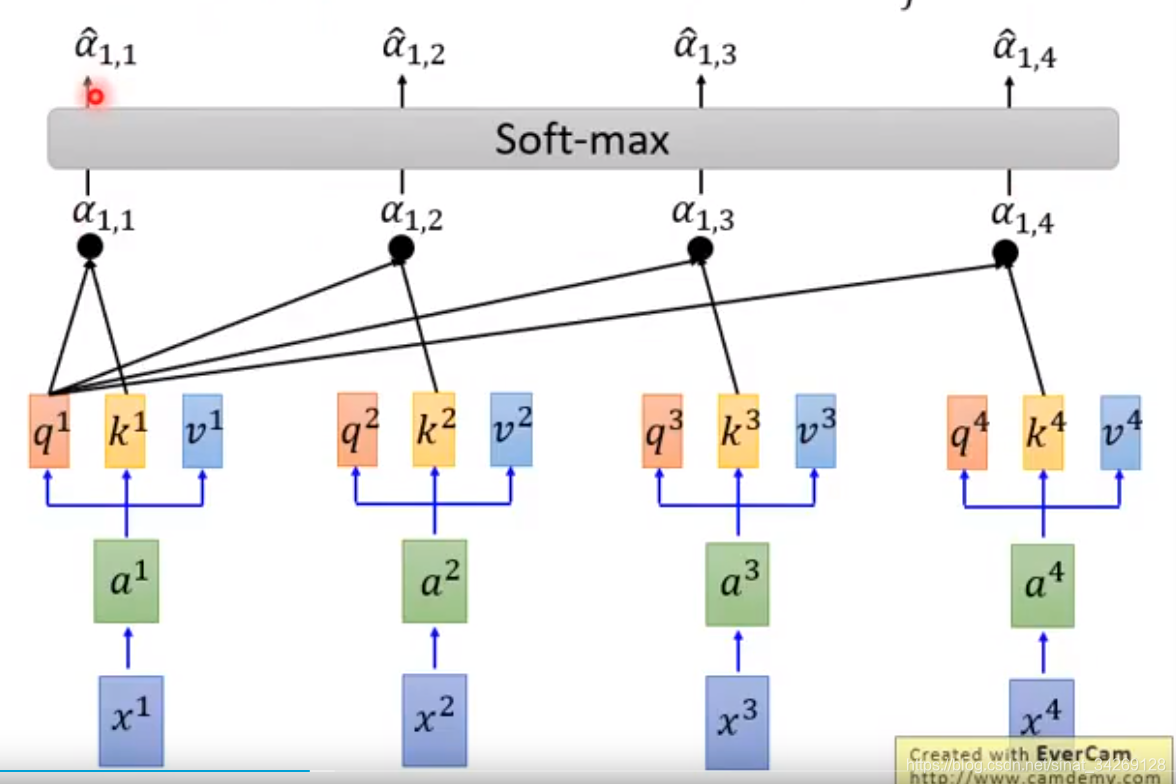
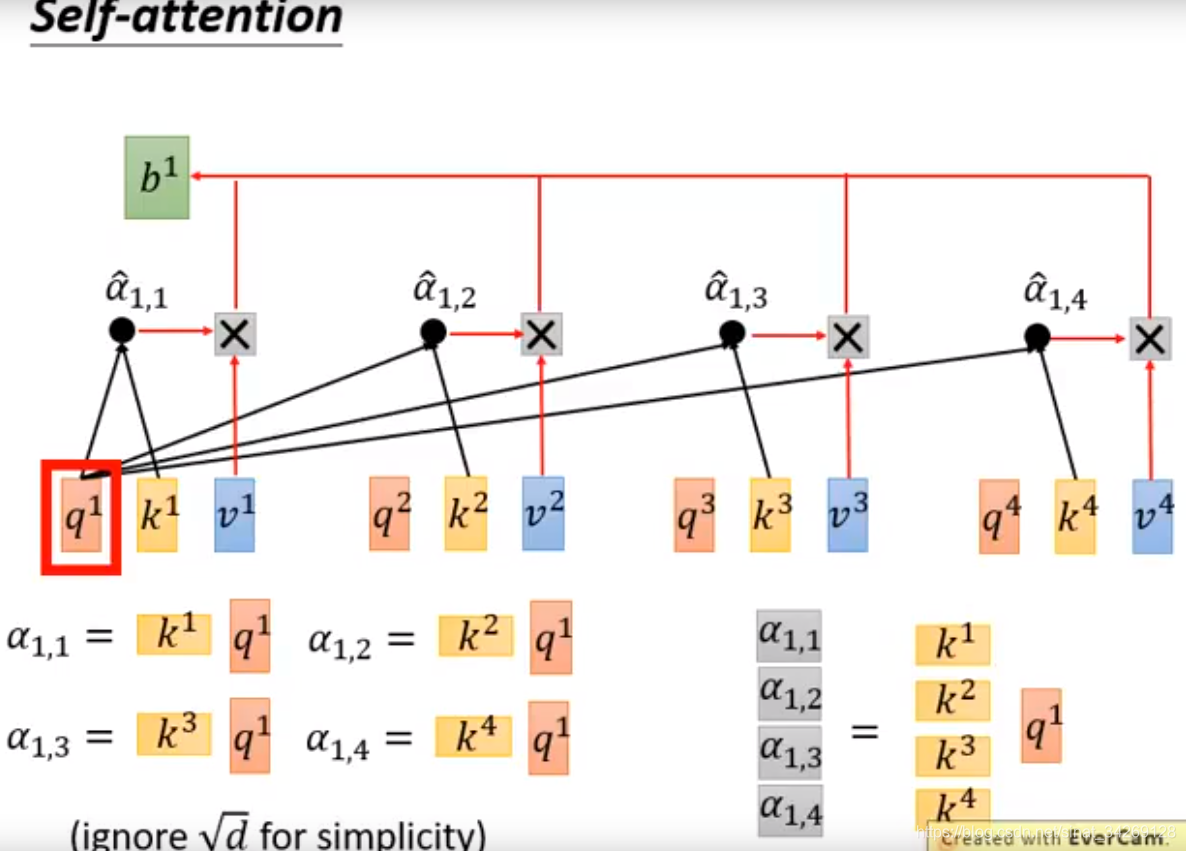
使用每个query对每个k做attention,然后将输出通过soft-max层得到就是当前query与每个key之间的相关度。也就是当前词与其他词的关系程度。
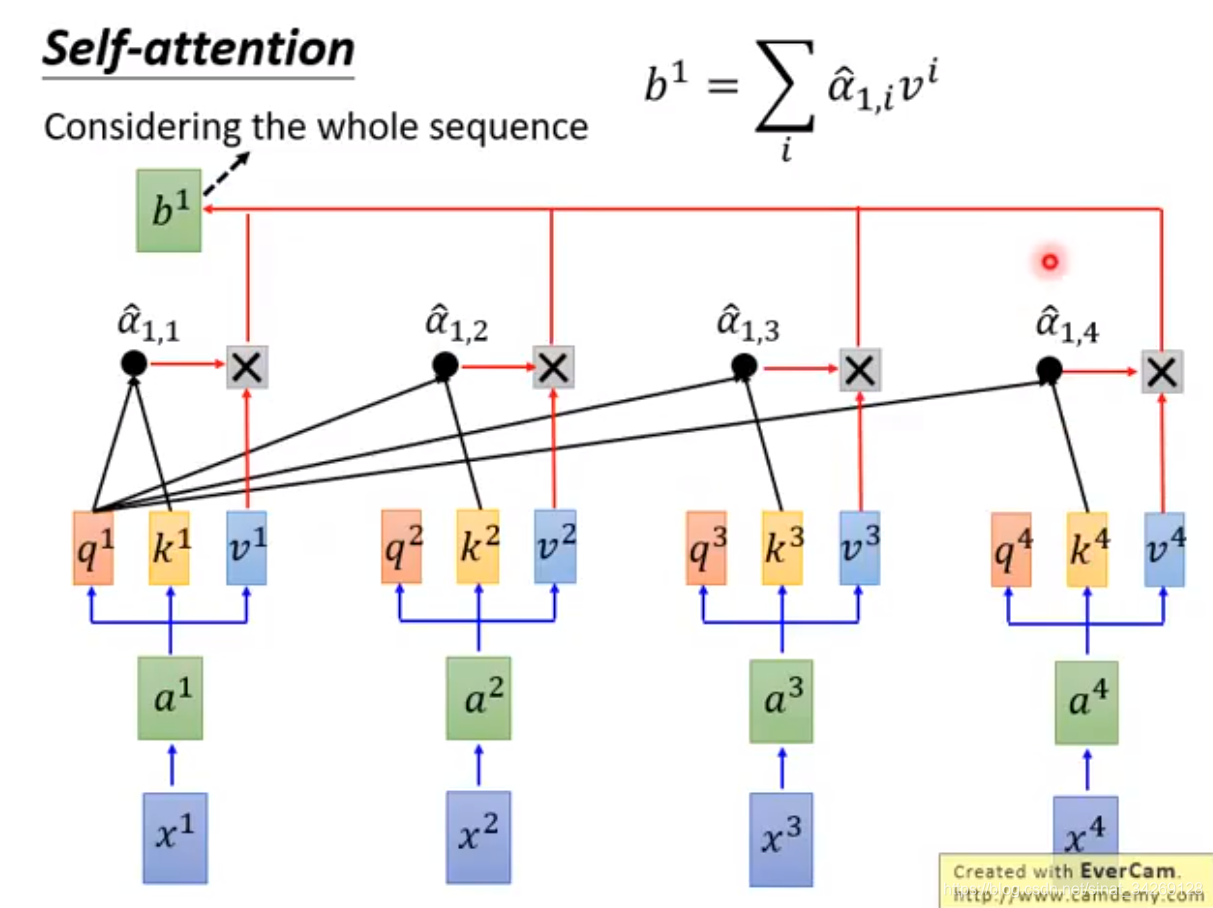
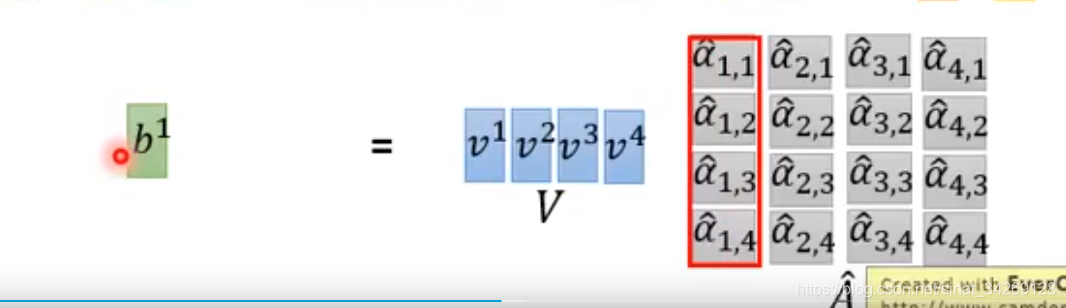
接下来与v相乘求和即得到结果b,每个b是可以同时得到的
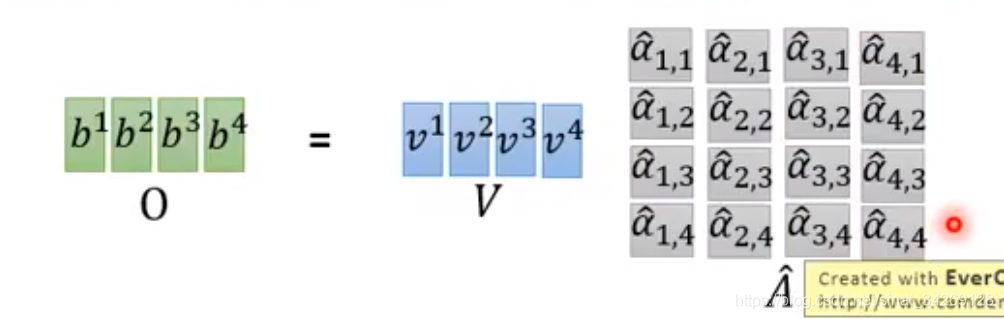
下面是使用矩阵相乘的形式解释q,k,v的计算。
下面介绍的是矩阵如何相乘计算得到b,计算q1与k1之间如何得到α1
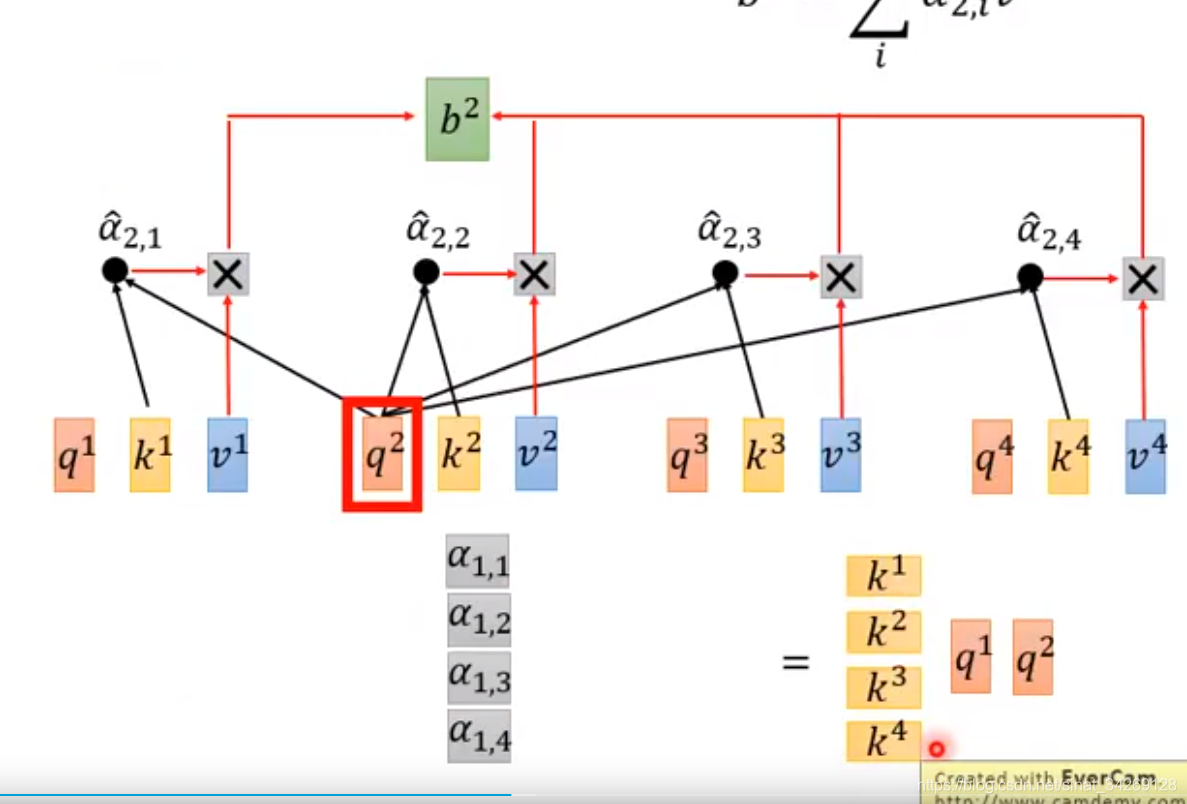
所有的k与q相乘,得到α矩阵,然后输入softmax层,每个输入x与其他x的关系比重。

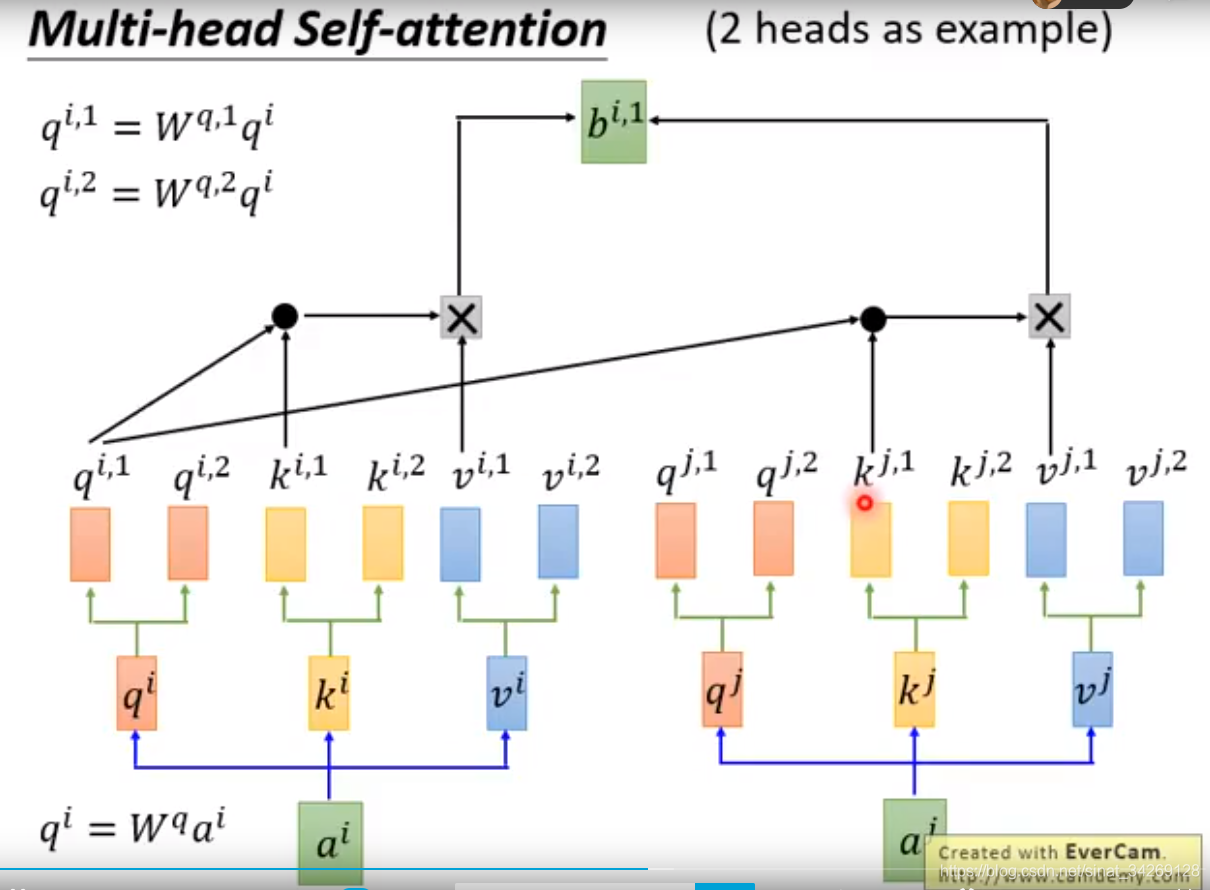
下面讲的是一个多头self-attention思路,其实就是将q继续分解,几个头,就分解成几个q。k,v同理。使用多头注意力的想解决的问题是:注意到向量之间的不同关系,可以是global关系,也可以local关系。
最后一个问题,上面的过程中输出,虽然考虑了所有的输入信息,但是并没有考虑输入信息sequence的顺序信息
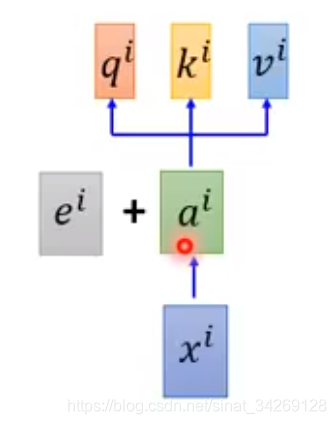
因此文章中提出了一个方法,在a上面加上了e,e表示位置信息(e不是从数据中学习来的)
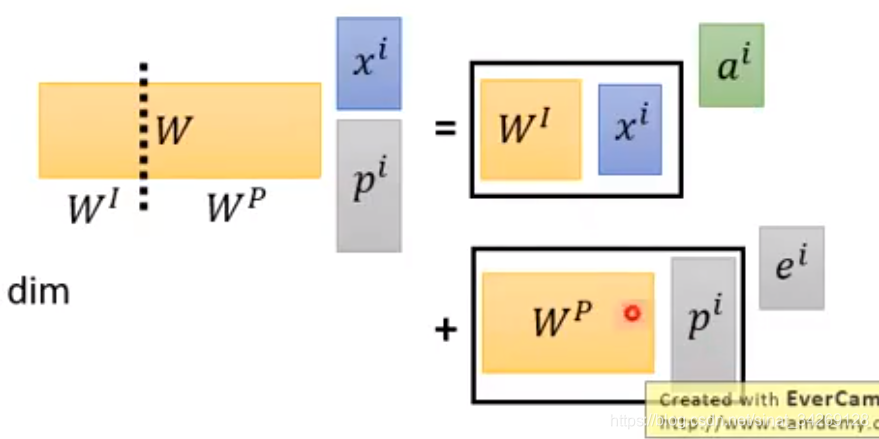
在视频中提出了另一种方法,在x后面加一个one-hot向量p,并不是让e与a相加,而是让两个向量拼接在一起
最后在整个seq2seq model中将所有的RNN使用self-attention代替
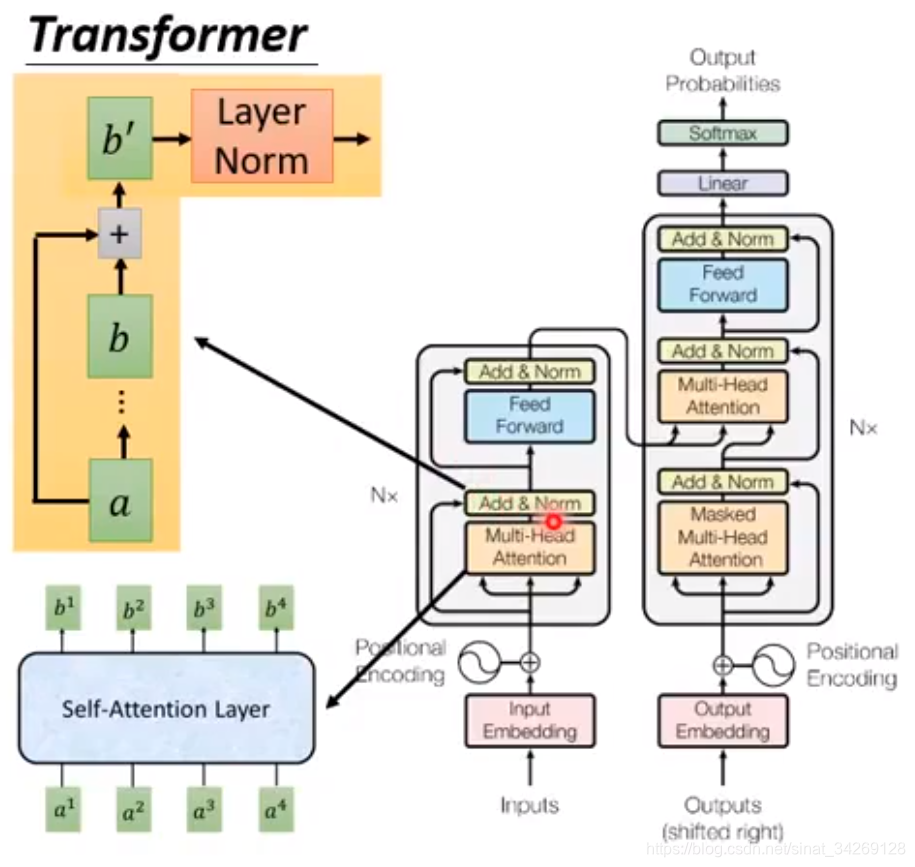
Transoformer整体框架
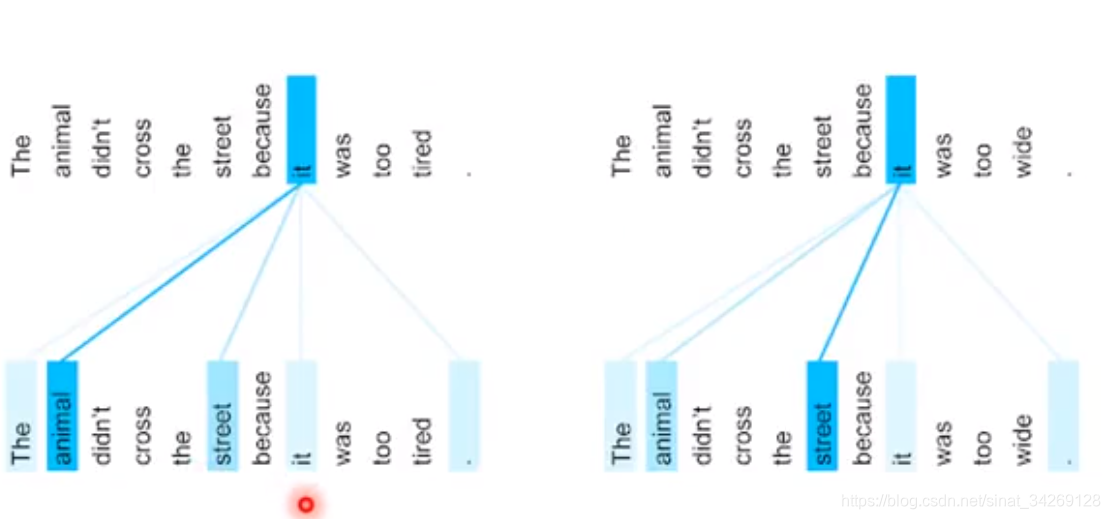
蓝色线颜色越重,表示相关性越强。
以上为个人在视频中摘取记录到可能会忘记的部分,以作为复习提示!如有错误,还请指教,谢谢!

















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









