







OneAPI需要你自建大模型,仍需到各大模型官网获取付费的API-Key。
所以Linux.do社区大佬们放出了多个公益API网站,如下所示。
这些网站的功能类似OneAPI平台,集成了多家大模型。
本篇以“DEV API”站为例,给大家介绍下如何使用。
1.注册
链接看知乎这里 https://zhuanlan.zhihu.com/p/6612720658
| API站点 | 注册链接(填AFF有福利) |
|---|---|
| DEV API | [aff=4v9b] |
| Let‘s API | [aff=5rkG] |
| gala API | [aff=sWhK] |
| EAI API | [aff=ieag] |
| EulerAI | [aff=gRqG] |
| ShelltenAPI | [aff=Omk4] |
第1个支持GitHub登录,且福利最大,首推DEV API
部分站点只有Linux.do社区成员才能注册。
2.平台介绍
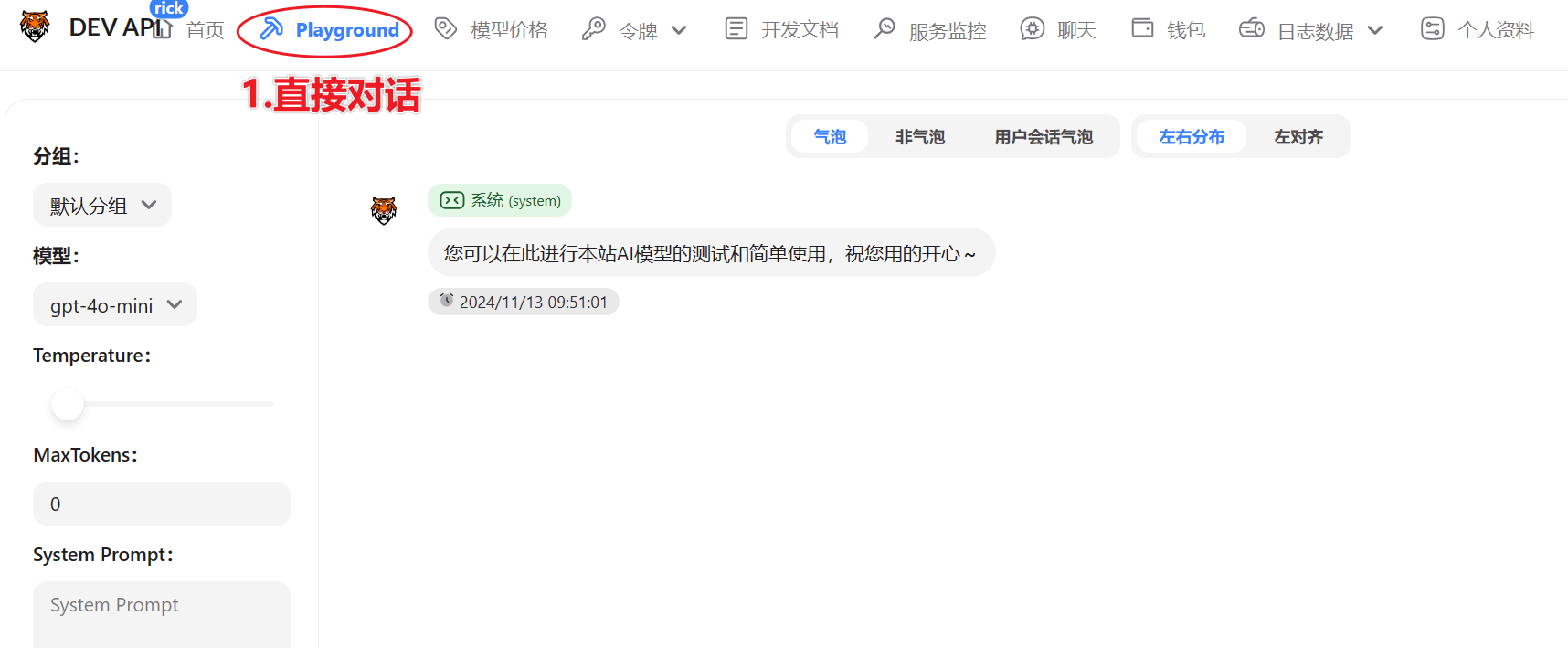
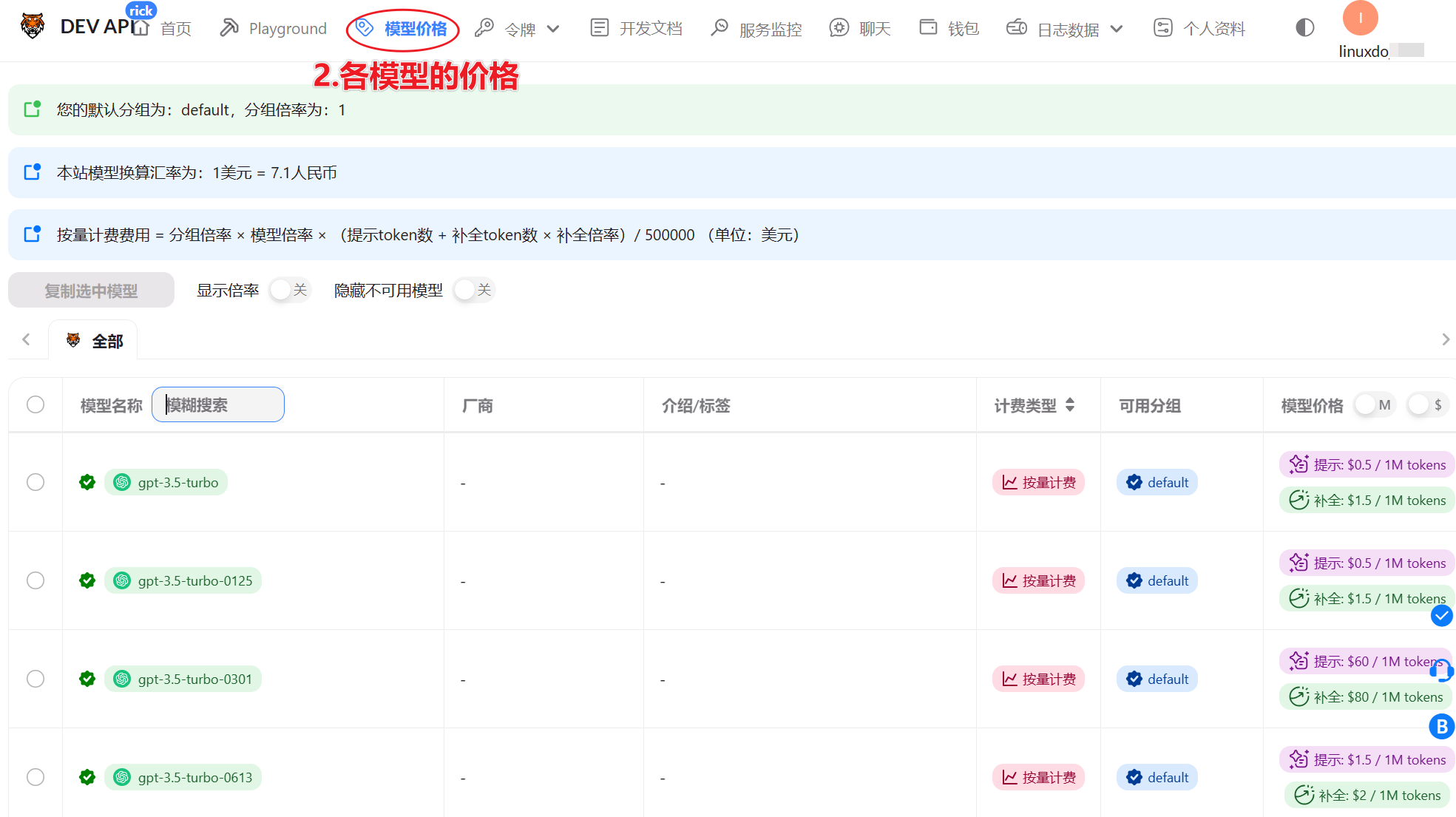
送5刀,使用 GPT-3.5 Turbo 模型的价格是每 1,000,000 个 token 0.5 刀,所以可以白嫖GPT3.5的 1千万Token
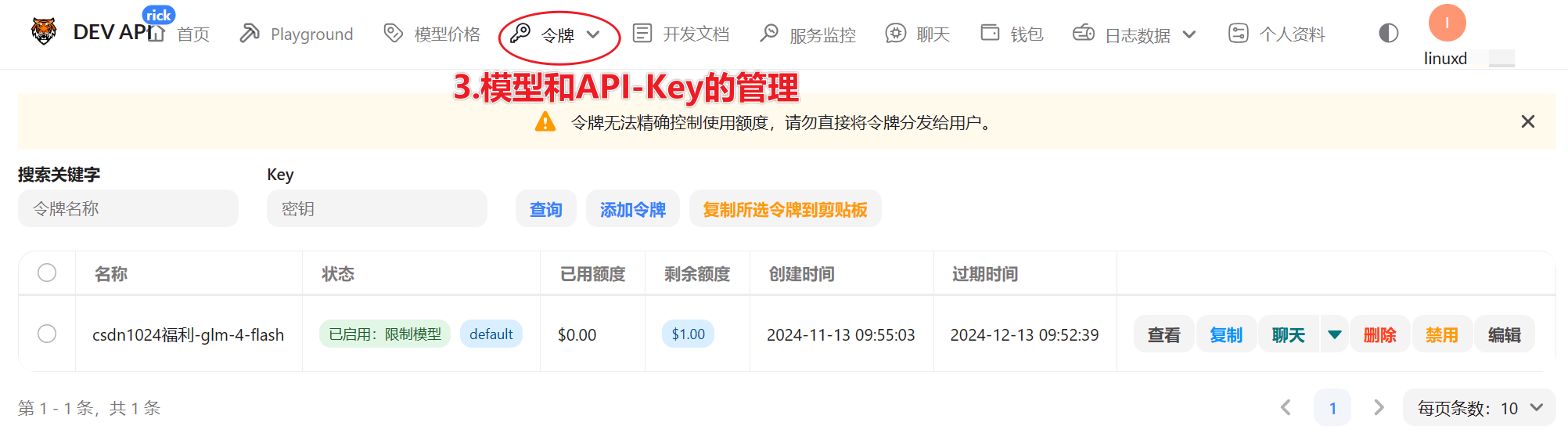
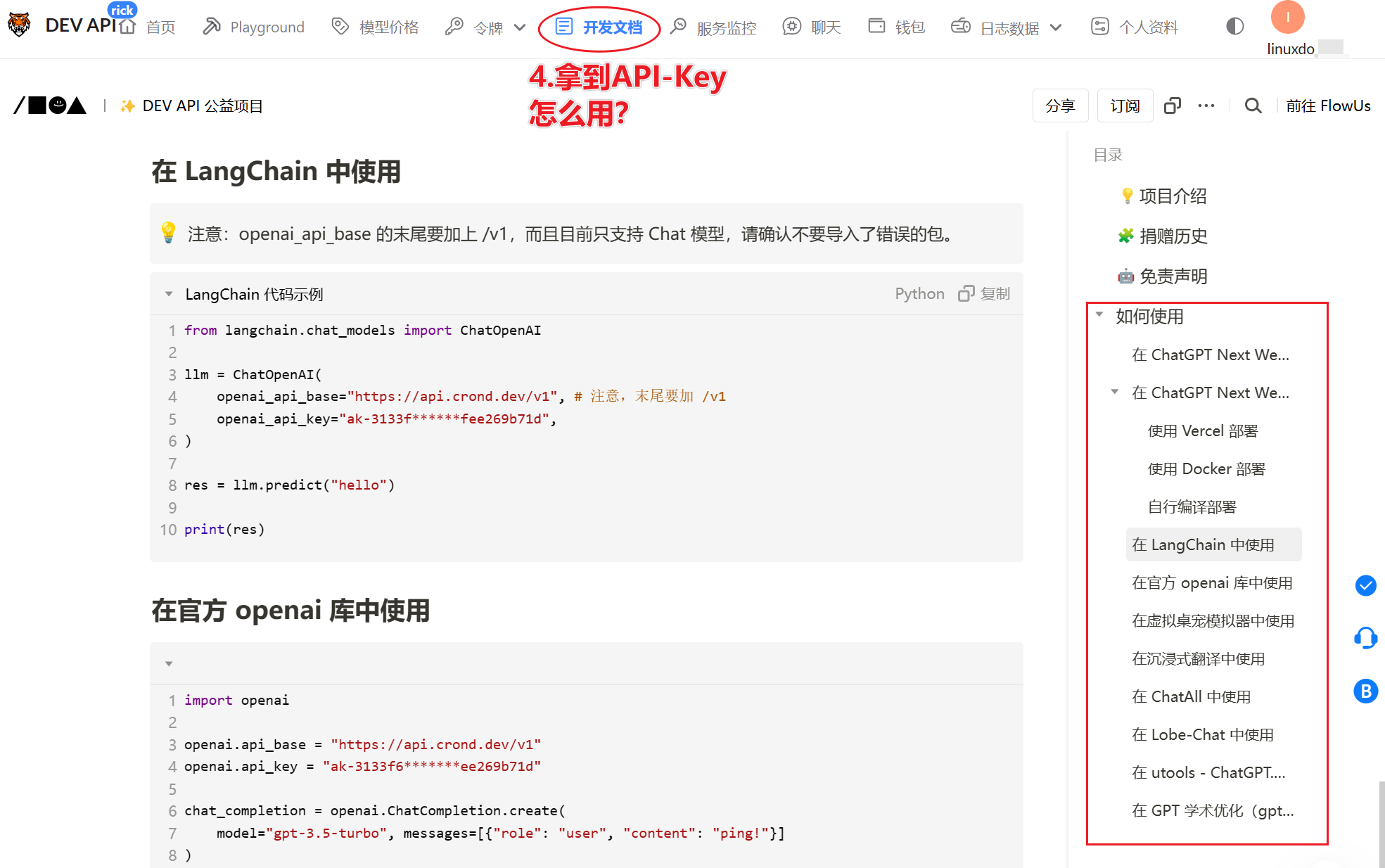
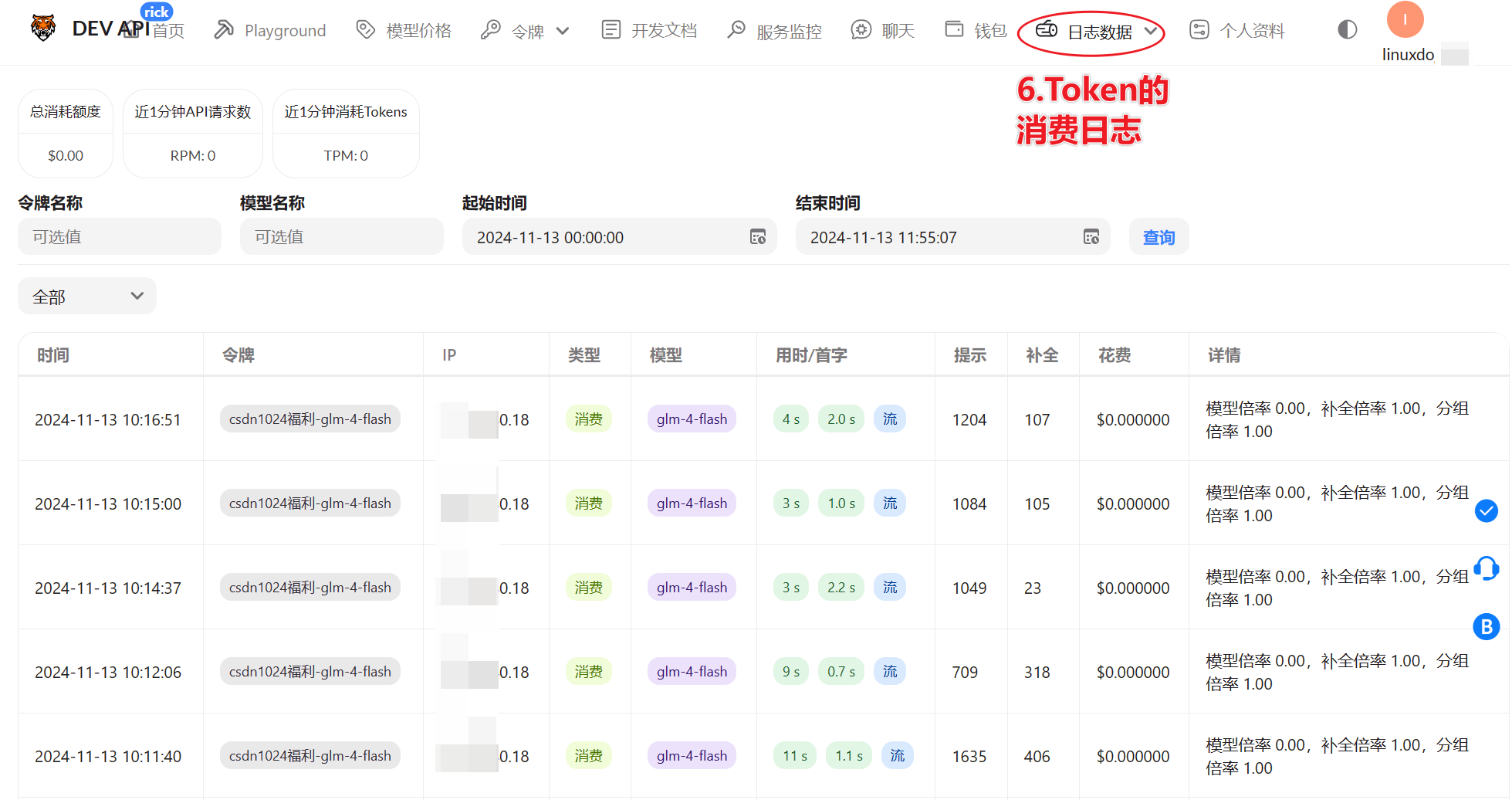
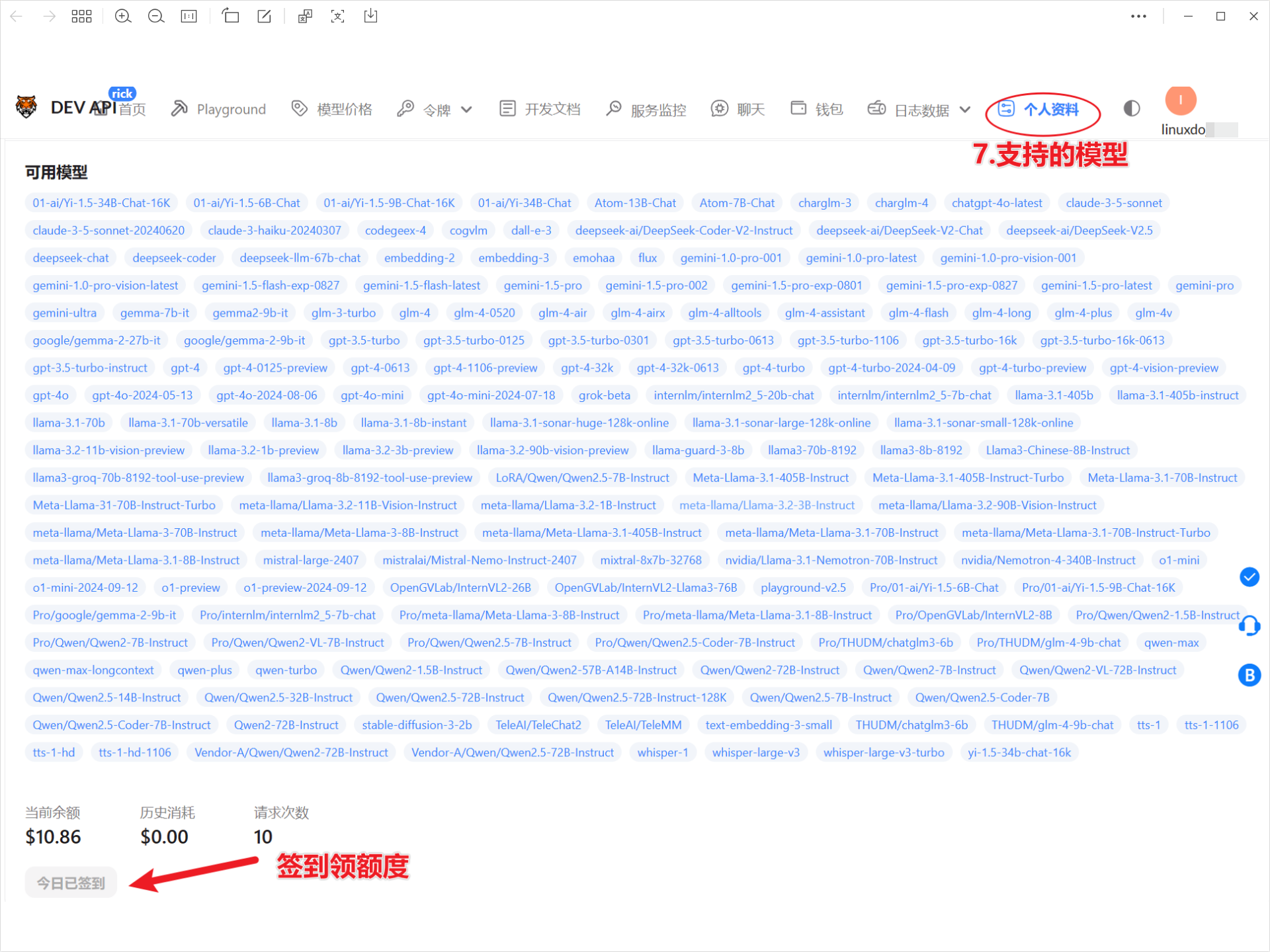
3.配置令牌
- 先在“模型价格”页面,看下需要的模型和价格
- 配置令牌,启用模型是指你让这个
API-Key可以用哪些模型,别写多了,除非你有钞能力!
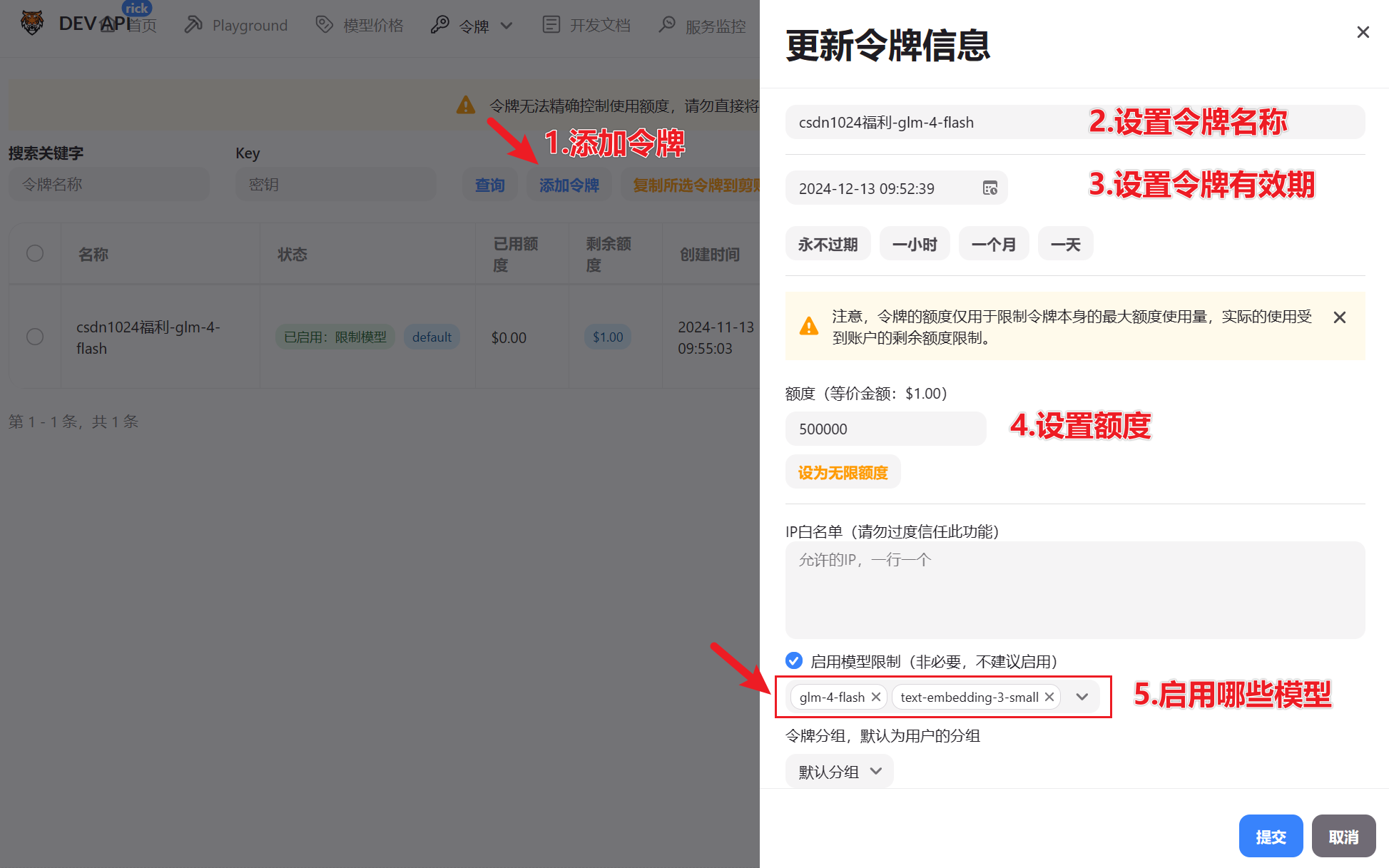
- 点查看/复制,就出现API-Key了。
这是我的API-Key,有效期一个月。
sk-imPBx64LT9WjxVaOii0BWJQWLqD1RLw4Rn0XVU1k3q7HgvPE
4.使用令牌
4.1 在LangChain中使用
用的是OpenAI格式,实际调用的是你令牌中启用的大模型glm-4-flash
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="https://api.crond.dev/v1", # 注意,末尾要加 /v1
openai_api_key="sk-imPBx64LT9WjxVaOii0BWJQWLqD1RLw4Rn0XVU1k3q7HgvPE",
model="glm-4-flash"
)
res = llm.predict("hello")
print(res)
4.2 在ChatBox中使用
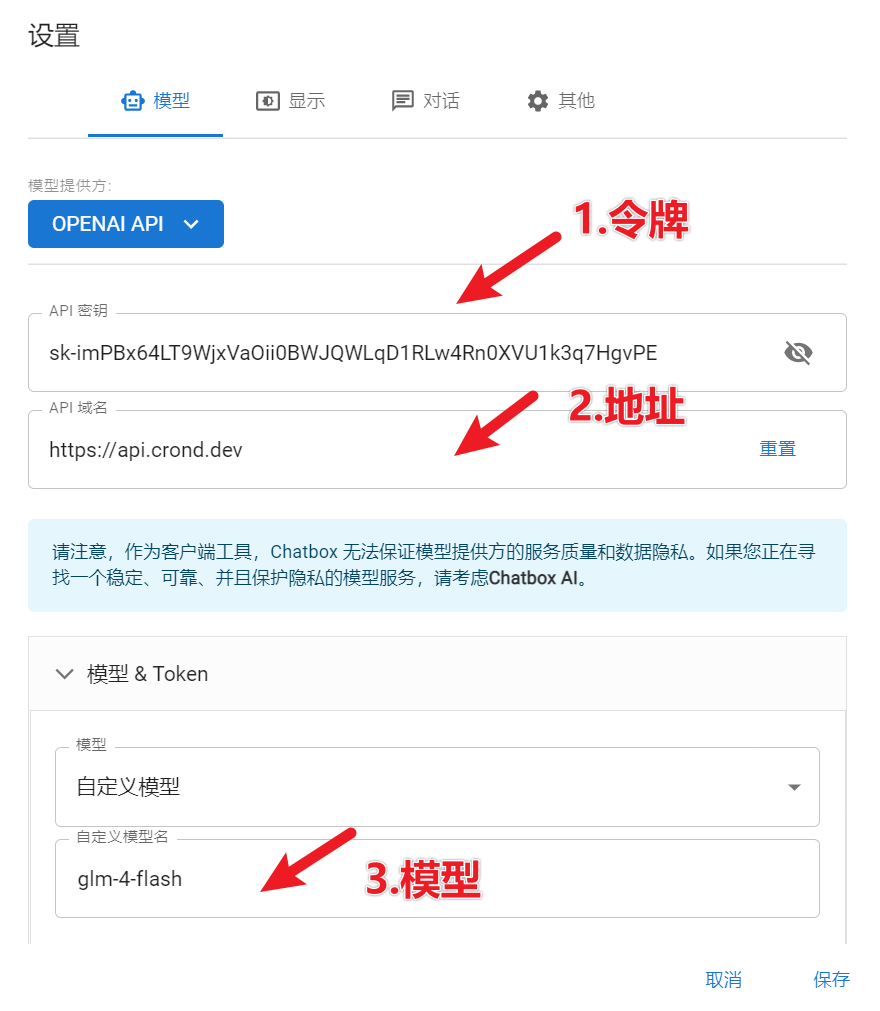

4.3 在FastGPT中使用
在docker-compose.yaml 中配置URL和API-Key
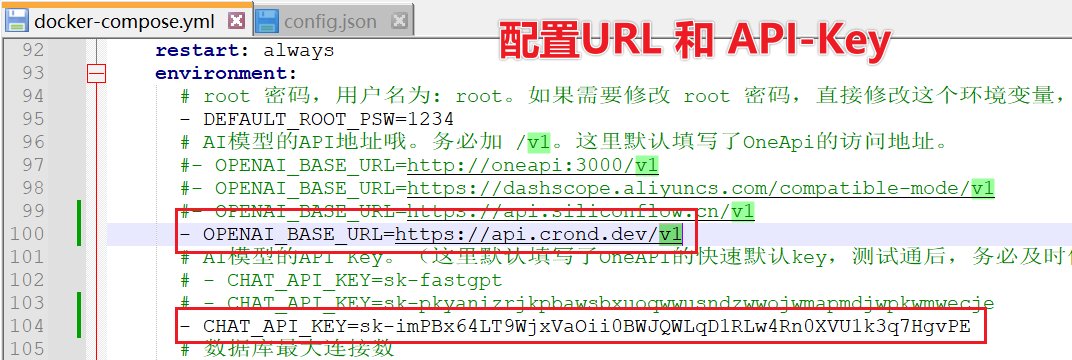
environment:
- DEFAULT_ROOT_PSW=1234
# AI模型的API地址哦。务必加 /v1。
- OPENAI_BASE_URL=https://api.crond.dev/v1
# AI模型的API Key。(这里默认填写了OneAPI的快速默认key,测试通后,务必及时修改)
- CHAT_API_KEY=sk-imPBx64LT9WjxVaOii0BWJQWLqD1RLw4Rn0XVU1k3q7HgvPE
在config.json 中配置模型和嵌入模型
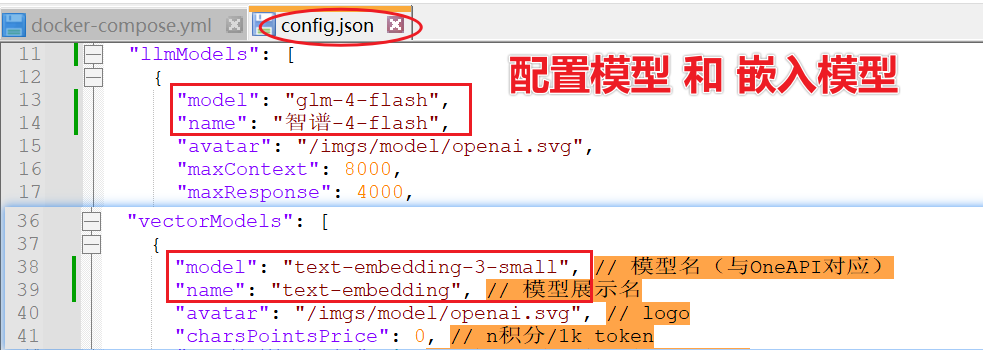
"llmModels": [
{
"model": "glm-4-flash",
"name": "智谱-4-flash",
"avatar": "/imgs/model/openai.svg",
"maxContext": 8000,
"maxResponse": 4000,
"quoteMaxToken": 20000,
"maxTemperature": 1,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"usedInQueryExtension": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"model": "text-embedding-3-small", // 模型名(与OneAPI对应)
"name": "text-embedding", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
],
如果修改前就启动了FastGPT,那就重启下
docker-compose down
docker-compose up -d
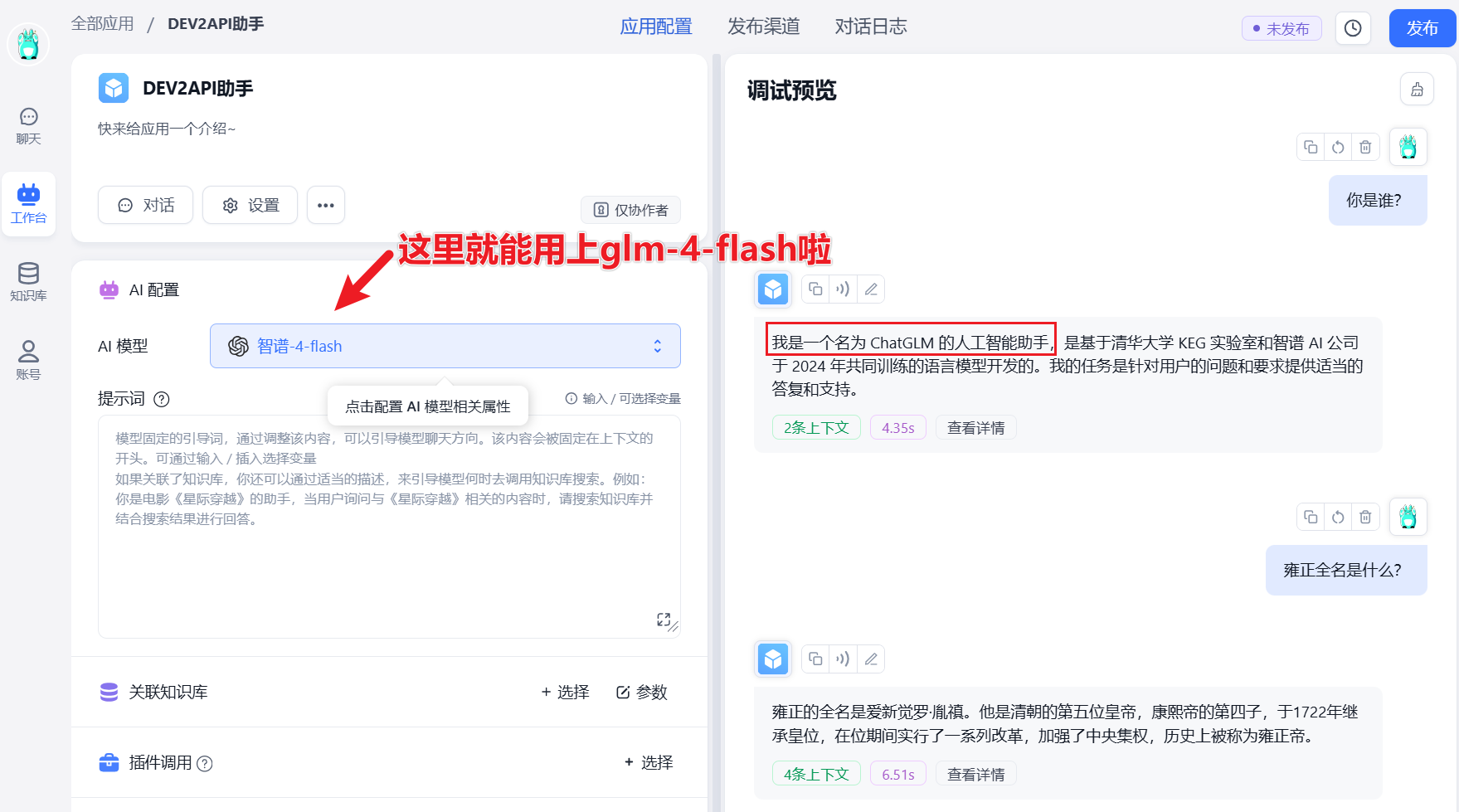
打开创建应用,即可测试模型对话啦
FastGPT更多配置看以下文章



















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











