







 本文详细解读了ElegantRL框架的结构和使用方法,包括如何选择和初始化智能体(如DuelingDQN)、环境预处理、多进程训练与评估。在训练过程中,介绍了如何创建和更新经验回放缓冲区,以及如何收集和利用环境数据进行学习。此外,还提到了使用二叉搜索树的数据结构。
本文详细解读了ElegantRL框架的结构和使用方法,包括如何选择和初始化智能体(如DuelingDQN)、环境预处理、多进程训练与评估。在训练过程中,介绍了如何创建和更新经验回放缓冲区,以及如何收集和利用环境数据进行学习。此外,还提到了使用二叉搜索树的数据结构。
ElegantRL源码解读
-
框架结构
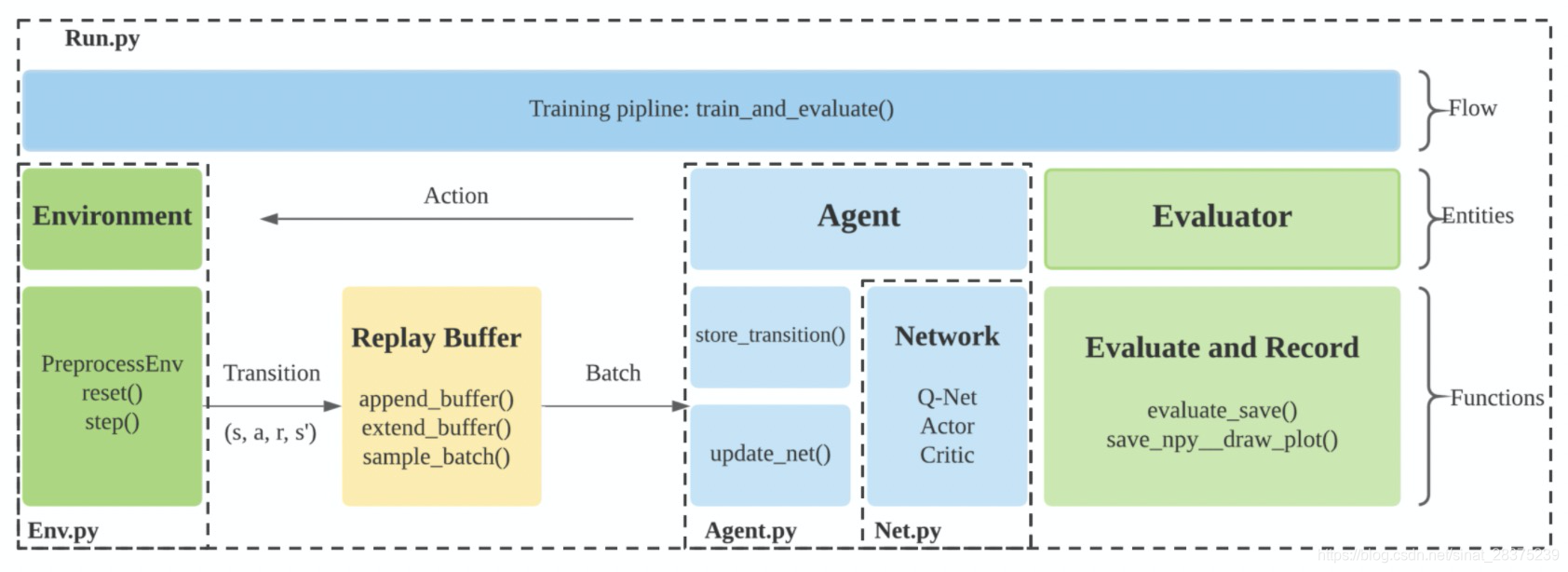
-
创造agent,各个agent已经封装好,选择算法
from elegantrl.agent import AgentDuelingDQN -
选择环境
PreprocessEnv(env=gym.make('LunarLander-v2')) # 股票环境 from envs.FinRL.StockTrading import StockTradingEnv # 在环境里加载数据,加入相关指标 self.price_ary, self.tech_ary = self.load_data(cwd, if_eval, ticker_list, tech_indicator_list, start_date, end_date, env_eval_date, ) -
训练和测试
train_and_evaluate(args) # 多进程 args.rollout_num = 4 train_and_evaluate_mp(args)- 初始化agent
agent.init(net_dim, state_dim, action_dim, if_per)- 创建网络
- 创建buffer
buffer = ReplayBuffer(max_len=max_memo + max_step, state_dim=state_dim, action_dim=1 if if_discrete else action_dim, if_on_policy=if_on_policy, if_per=if_per, if_gpu=True) 疑问:self.tree = BinarySearchTree(max_len)- 收集数据
with torch.no_grad(): # update replay buffer steps = explore_before_training(env, buffer, target_step, reward_scale, gamma) # 利用环境里的step next_state, reward, done, _ = env.step(action)

















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









