




n步sarsa
[!NOTE]
复习
SARSA(State–Action–Reward–State–Action)是一种 on-policy(同策略)的时序差分强化学习算法,用于学习在给定策略 π\piπ 下的动作价值函数(Q 函数)。目标是估计在当前策略 π\piπ 下,从状态 sss 采取动作 aaa 的预期累积回报,即 Qπ(s,a)Q^\pi(s, a)Qπ(s,a)。通过在线交互不断更新 QQQ 值,使得 Q(s,a)Q(s, a)Q(s,a) 逐渐逼近真实值。
SARSA 基于 TD(0) 更新规则,其更新公式如下:
Q(st,at)←Q(st,at)+α[rt+1+γQ(st+1,at+1)−Q(st,at)] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t) \right] Q(st,at)←Q(st,at)+α[rt+1+γQ(st+1,at+1)−Q(st,at)]
其中:
- sts_tst:当前状态
- ata_tat:当前采取的动作(由当前策略 π\piπ 选择)
- rt+1r_{t+1}rt+1:执行动作 ata_tat 后获得的即时奖励
- st+1s_{t+1}st+1:执行动作后进入的下一个状态
- at+1a_{t+1}at+1:在 st+1s_{t+1}st+1 下根据当前策略 π\piπ 选择的下一个动作
- α∈(0,1]\alpha \in (0,1]α∈(0,1]:学习率
- γ∈[0,1)\gamma \in [0,1)γ∈[0,1):折扣因子
SARSA 在更新时使用的是实际采取的下一个动作 at+1a_{t+1}at+1,而不是贪心选择的动作。
定义
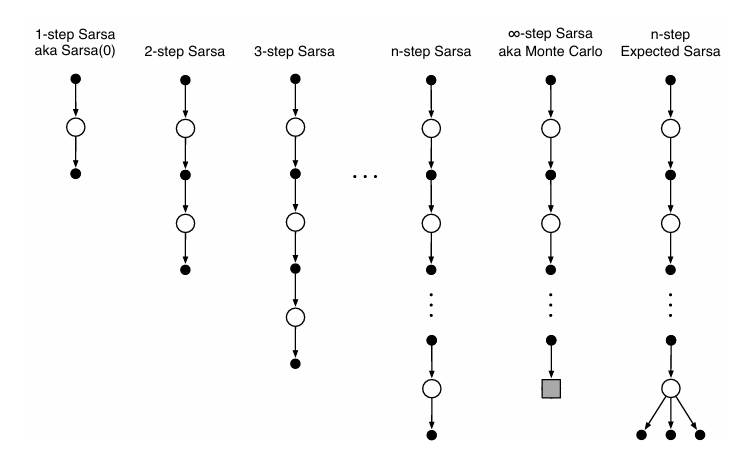
n 步 Sarsa 是将 n 步时序差分方法与 Sarsa 算法结合,形成一种同轨策略下的控制方法。它扩展了原始的单步 Sarsa(即 Sarsa(0)),通过引入多步回报来加速学习关键在于将基本单元从“状态”变为“状态-动作”二元组;使用 ε-贪心策略进行动作选择;回溯图首尾均为动作(区别于状态价值方法)
对于 $ n \geq 1 $ 且 $ 0 \leq t < T - n $,n 步回报定义为:
Gt:t+n≐Rt+1+γRt+2+⋯+γn−1Rt+n+γnQt+n−1(St+n,At+n) G_{t:t+n} \doteq R_{t+1} + \gamma R_{t+2} + \dots + \gamma^{n-1} R_{t+n} + \gamma^n Q_{t+n-1}(S_{t+n}, A_{t+n}) Gt:t+n≐Rt+1+γRt+2+⋯+γn−1Rt+n+γnQt+n−1(St+n,At+n)
当 $ t + n \geq T $ 时,使用完整回报:$ G_{t:t+n} = G_t $
仅更新当前经历的“状态-动作”对:
Qt+n(St,At)≐Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)] Q_{t+n}(S_t, A_t) \doteq Q_{t+n-1}(S_t, A_t) + \alpha \left[ G_{t:t+n} - Q_{t+n-1}(S_t, A_t) \right] Qt+n(St,At)≐Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)]
其余所有 $ (s, a) \neq (S_t, A_t) $ 的 Q 值保持不变。
算法实现
输入:无显式输入策略(策略由 Q 函数隐式定义)
参数:步长 α∈(0,1]\alpha \in (0,1]α∈(0,1],探索率 ε>0\varepsilon > 0ε>0,正整数 nnn
初始化:对所有 s∈S,a∈A(s)s \in \mathcal{S}, a \in \mathcal{A}(s)s∈S,a∈A(s),任意初始化 Q(s,a)Q(s, a)Q(s,a);策略 π\piπ 为基于当前 QQQ 的 ε-贪心策略
对每幕执行:
-
初始化并存储初始状态 S0S_0S0(非终止状态)
-
根据 π(⋅∣S0)\pi(\cdot \mid S_0)π(⋅∣S0) 选择并存储动作 A0A_0A0
-
设 T←∞T \leftarrow \inftyT←∞
-
对 t=0,1,2,…t = 0, 1, 2, \ldotst=0,1,2,… 执行:
-
若 t<Tt < Tt<T:
- 执行动作 AtA_tAt
- 观察并存储奖励 Rt+1R_{t+1}Rt+1 和下一状态 St+1S_{t+1}St+1
- 若 St+1S_{t+1}St+1 为终止状态,则 T←t+1T \leftarrow t + 1T←t+1
- 否则,根据 π(⋅∣St+1)\pi(\cdot \mid S_{t+1})π(⋅∣St+1) 选择并存储动作 At+1A_{t+1}At+1
-
计算 τ←t−n+1\tau \leftarrow t - n + 1τ←t−n+1
-
若 τ≥0\tau \geq 0τ≥0:
-
计算部分回报:
G←∑i=τ+1min(τ+n, T)γi−τ−1Ri G \leftarrow \sum_{i=\tau+1}^{\min(\tau+n,\,T)} \gamma^{i-\tau-1} R_i G←i=τ+1∑min(τ+n,T)γi−τ−1Ri -
若 τ+n<T\tau + n < Tτ+n<T,追加自举项:
G←G+γnQ(Sτ+n,Aτ+n) G \leftarrow G + \gamma^n Q(S_{\tau+n}, A_{\tau+n}) G←G+γnQ(Sτ+n,Aτ+n) -
更新动作价值函数:
Q(Sτ,Aτ)←Q(Sτ,Aτ)+α[G−Q(Sτ,Aτ)] Q(S_\tau, A_\tau) \leftarrow Q(S_\tau, A_\tau) + \alpha \big[ G - Q(S_\tau, A_\tau) \big] Q(Sτ,Aτ)←Q(S
-
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2764
2764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









