







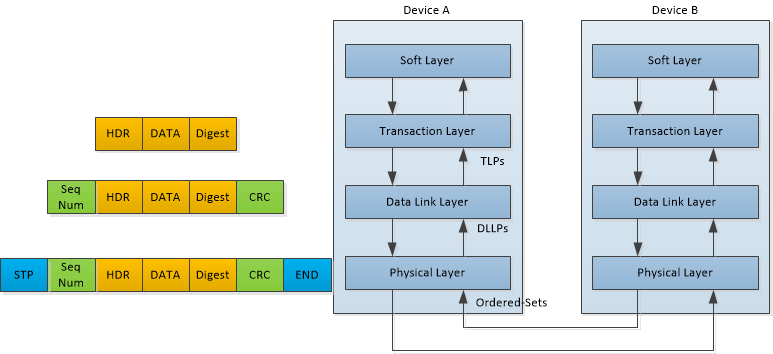
1.PCIe分层结构
PCIe 采用三层协议栈(事务层、数据链路层、物理层),每层独立处理不同功能,协同实现高性能数据传输。事务层(Transaction Layer, TL)主要负责处理高层通信协议,生成/解析数据包(TLP)。 数据链路层(Data Link Layer, DLL)负责给每个TLP的头部分配唯一SeqNum,在尾部加上LCRC(Link CRC),除此之外还有属于数据链路层的DLLP(Data Link Layer Packet),功能是通过ACK/NAK机制保证传输的可靠性以及流控数据的更新。物理层(Physical Layer)是PCIe协议栈的最底层,除了给数据链路层发送的包加上开始和结束标识符,还直接负责电气信号传输、链路初始化和时钟同步。
2.TLP包
2.1 Transaction 种类
PCIe是点对点的通信,一次传输的发起者通常称为Requester,接收者称为Completer,传输的类型分为Memory Transaction、I/O Transaction、Configuration Transaction、Message Transaction四种。
| 特性 | Memory Transaction | I/O Transaction | Configuration Transaction | Message Transaction |
|---|---|---|---|---|
| 主要用途 | 大块数据传输(如DMA、显存访问) | 传统设备寄存器访问(兼容PCI) | PCIe设备配置空间读写 | 中断、电源管理、原子操作等 |
| TLP类型字段 | MRd/MWr | IORd/IOWr | CfgRd0/CfgWr0 | Msg/MsgD/MsgA |
| 地址空间 | 内存地址空间(BAR映射) | I/O地址空间(32位) | 配置空间(Bus/Dev/Func+偏移) | 无地址,依赖消息路由(如ID) |
| TLP头长度 | 3 DW(32位地址)或4 DW(64位) | 3 DW | 3 DW | 3 DW或4 DW(含扩展路由) |
| Payload支持 | 是(最大4KB) | 否(仅1-4字节数据) | 否 | 可选(如MSI-X数据) |
| 路由方式 | 地址路由(Address Routing) | 地址路由 | ID路由(Bus/Dev/Func) | 隐式/显式路由(如广播) |
| 典型延迟 | 低(ns级,依赖TLP流水线) | 高(μs级,因协议开销) | 中(配置访问需Root Complex) | 极低(如MSI-X中断<100ns) |
2.2 Posted 和 Non-Posted
Posted和Non-Posted是事务(Transaction)的两大分类,直接影响传输效率、完成机制和死锁规避。对于Posted事务,比如发起方发送MWr TLP包给接收方,接收方无需返回Completion TLP包,发送方不确认是否成功(可靠性由数据链路层ACK/NAK保障),posted事务适用于批量数据传输(如DMA写),吞吐量高,这样可以减少链路占用。Non-Posted 事务则要求发送必须等待Completion,超时未收到会触发重试。
| 事务类型 | Posted/Non-Posted | TLP 类型 | 典型应用场景 |
|---|---|---|---|
| Memory Write (MWr) | Posted | MWr | DMA 数据传输、GPU 显存写入 |
| Memory Read (MRd) | Non-Posted | MRd | CPU 读取设备内存、SSD 数据读取 |
| I/O Write (IOWr) | Non-Posted | IOWr | 传统 PCI 设备寄存器写入 |
| I/O Read (IORd) | Non-Posted | IORd | 传统 PCI 设备寄存器读取 |
| Configuration Write | Non-Posted | CfgWr0/CfgWr1 | 设备枚举、BAR 空间配置 |
| Configuration Read | Non-Posted | CfgRd0/CfgRd1 | 设备功能检测 |
| Message (Msg) | Posted | Msg/MsgD/MsgA | MSI/MSI-X 中断、电源管理命令 |
| AtomicOp | Non-Posted | FetchAdd/CAS | 多核同步、GPU 计算任务协调 |
2.3 TLP结构
TLP(事务层数据包)是PCIe协议的核心传输单元,由3或4DW的Header(定义事务类型/地址等)、可选的1-1024DW数据负载(通过字节使能控制有效范围)及1DW的ECRC校验字段(保障数据完整性)组成,支持高效可靠的数据传输。
| TLP组成部分 | 所属协议层 | 功能说明 |
|---|---|---|
| Header(头标) | 事务层(Transaction Layer) | 3或4 DW,包含: - 事务类型(Memory/I/O/Config/Msg) - 目标地址或ID - 传输长度(DW数) - 属性(缓存一致性、RO等) - 流量类别(TC) |
| Data(数据) | 事务层 | 可选,1-1024 DW: - 通过字节使能(Byte Enable)控制有效数据范围 - 零长度需特殊处理(设1 DW且字节使能全0) |
| Digest/ECRC | 事务层 | 可选1 DW: - 端到端CRC校验(ECRC),用于检测传输错误 - 接收方验证失败会触发NAK重传 |
2.4 TLP Header
TLP Header 是 PCIe 事务层数据包(TLP)的核心控制部分,定义了事务类型、地址、数据长度和传输属性等关键信息。其长度分为3DW(32位地址)和4DW(64位地址)两种格式。
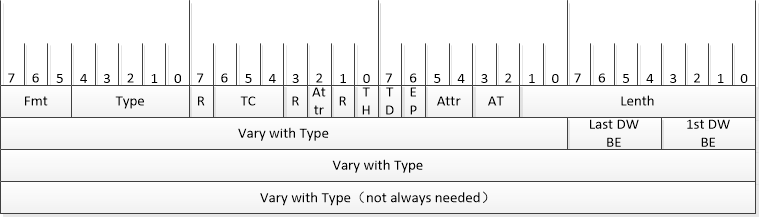
Fmt和Type
Header中比较重要的是Fmt和Type,它们共同决定了事务类型,组合如下表所示。
| Fmt[1:0] | Type[4:0] | TLP 类型 | Header 长度 | 数据负载 | 典型用途 |
|---|---|---|---|---|---|
00 | 00000 | MRd (Memory Read) | 3DW (32-bit) | 无 | 32位地址内存读请求 |
01 | 00000 | MRd (Memory Read) | 4DW (64-bit) | 无 | 64位地址内存读请求 |
00 | 00001 | MWr (Memory Write) | 3DW (32-bit) | 有 | 32位地址内存写请求 |
01 | 00001 | MWr (Memory Write) | 4DW (64-bit) | 有 | 64位地址内存写请求 |
00 | 00010 | IORd (I/O Read) | 3DW | 无 | I/O 空间读请求(Gen4+ 已弃用) |
00 | 00011 | IOWr (I/O Write) | 3DW | 有 | I/O 空间写请求(Gen4+ 已弃用) |
00 | 00100 | CfgRd0 (Config Read) | 3DW | 无 | Type 0 配置空间读(本地设备) |
00 | 00101 | CfgWr0 (Config Write) | 3DW | 有 | Type 0 配置空间写(本地设备) |
00 | 00110 | CfgRd1 (Config Read) | 3DW | 无 | Type 1 配置空间读(下游设备) |
00 | 00111 | CfgWr1 (Config Write) | 3DW | 有 | Type 1 配置空间写(下游设备) |
10 | 1xxxx | Msg (Message) | 3DW 或 4DW | 无 | 中断、电源管理、错误报告等 |
10 | 01101 | MsgD (Message w/ Data) | 3DW 或 4DW | 有 | 带数据的消息(如 Vendor Defined) |
00 | 01100 | FetchAdd (AtomicOp) | 3DW 或 4DW | 有 | 原子加操作(Gen3+) |
00 | 01101 | CAS (AtomicOp) | 3DW 或 4DW | 有 | 原子比较交换(Gen3+) |
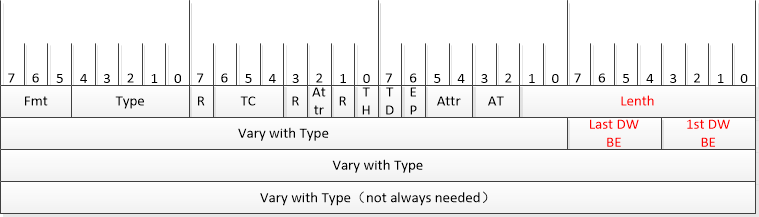
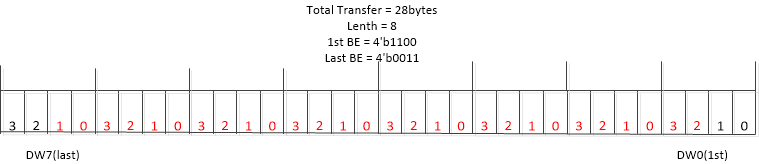
Lenth 和Byte Enable
Lenth字段指定了TLP数据负载(Payload)的DW(4字节)数量,范围从1-1024,最大4KB数据。Lenth不能取值0,当没有数据负载时,Lenth=1,且所有的Byte Enable字段都为0。对于I/O 事务,Lenth为1,且Last DW BE = 0,1st DW BE可变。Byte Enable 字段分为了Last 和1st,标记了第一个和最后一个DW中哪些字节有效。
一个跨 DW 截断的例子如图所示,实际传输的有效数据为红色部分。
2.5 TLP路由
PCIe TLP 的路由机制决定了数据包如何从发送端传递到目标设备,主要分为三种方式:基于地址的路由(用于 Memory 事务,通过物理地址匹配)、基于 ID 的路由(用于 Configuration 和 Completion 事务,通过 Bus/Dev/Func 标识逐级转发)以及隐式路由(用于 Message 事务,根据消息类型自动定向到 RC 或上游设备)。路由规则由 TLP Header 中的地址、ID 或消息编码字段控制,交换机/RC 根据这些字段实现精准转发。各种事务的路由方式如下图所示。
| 事务类型 | 路由方式 | 关键字段 | 转发规则 |
|---|---|---|---|
| Memory Read/Write (MRd/MWr) | 基于地址的路由 | 32/64位目标地址 | 交换机/RC 根据地址范围匹配: - 属于下游设备 → 向下转发 - 属于主机内存 → 向上转发 |
| I/O Read/Write (IORd/IOWr) | 基于地址的路由 | 32位I/O地址 | 仅支持32位地址空间(Gen4+已弃用): - 地址匹配 → 向下转发 - 不匹配 → 向上转发 |
| Configuration (CfgRd/CfgWr) | 基于ID的路由 | Bus/Dev/Func(目标设备ID) | 交换机逐级匹配 Bus Number: - Type 0:本地设备 - Type 1:下游设备 |
| Completion (CPL/CPLD) | 基于ID的路由 | Requester ID(原请求者Bus/Dev/Func) | 按 Requester ID 反向路径回传至发起设备 |
| Message (Msg/MsgD) | 隐式路由 | Message Code(消息类型编码) | 自动定向: - 中断/错误消息 → 上报RC - 广播消息 → 向下游所有端口转发 |
| AtomicOp (FetchAdd/CAS) | 基于地址的路由 | 64位目标地址 + Requester ID | 同 Memory 事务,但需确保原子性(可能锁定目标地址) |
3.Flow Control
PCIe Flow Control是PCIe协议中确保数据可靠传输的核心机制。主要作用是防止缓冲区溢出,确保发送方不会发送超过接收方处理能力的数据,发送方在获得足够信用时立即发送数据,无需等待ACK,提高了效率,还通过信用制保证所有TLP都能被接收方正确接收。
3.1信用值种类
信用值类型分为Posted、Non-Posted、Completion三种,然后分别对Header和Data计数,所以一共有6种类型的buffer来存储信用值,每种信用类型有独立的 Buffer,避免不同类型TLP互相阻塞。如下图所示。
| 信用类型 | 对应的 TLP 类型 | Buffer 管理方式 | 典型应用场景 |
|---|---|---|---|
| Posted Header (PH) | Memory Write (MWr)、Message (Msg) | 仅计算 TLP Header(不包含 Payload) | 无需响应的写入操作 |
| Posted Data (PD) | Memory Write with Data (MWr) | 计算 Payload 的 DW 数量 | 大数据块写入(如 DMA 传输) |
| Non-Posted Header (NPH) | Memory Read (MRd)、I/O、Config | 仅计算 TLP Header(不包含 Payload) | 需要响应的读/配置操作 |
| Non-Posted Data (NPD) | Memory Read (MRd) | 预留空间(但实际无 Payload) | 读请求(无 Data,仅预留信用) |
| Completion Header (CPLH) | Completion (CPL/CPLD) | 仅计算 Completion Header | 读返回、原子操作响应 |
| Completion Data (CPLD) | Completion with Data (CPLD) | 计算 Payload 的 DW 数量 | 返回读数据(如 MRd 响应) |
3.2信用值工作原理
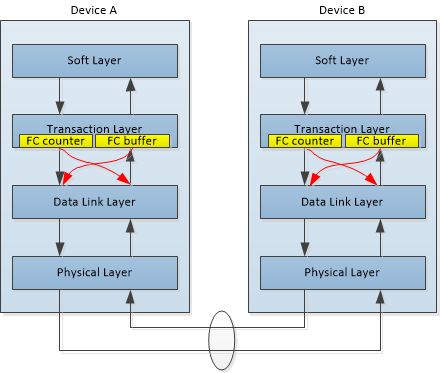
首先,每个端口的接收器以信用值(credits)为单位,FC buffer向发送端报告其流量控制缓冲区的剩余容量。信用值信息由接收端的事务层生成,并传递至链路层的发送端。链路层在适当时机生成流量控制DLLP(数据链路层协议数据单元),将信用值信息发送至对端设备的接收器。此过程针对每个流量控制缓冲区独立进行,确保数据收发速率匹配。
接收方通过解析流量控制DLLP(数据链路层协议数据单元)获取信用值信息,并将其传递至本端事务层的发送模块的FC counter。至此过程完成信用值在链路两端设备间的单向同步,该流程在链路双方向独立执行,确保两端设备的流量控制信息完全同步。当所有信用值交换完成后,链路进入稳定数据传输状态。
发送端在传输TLP(事务层数据包)前,必须核查流量控制计数器中的可用信用值,信用值充足时,TLP正常下发至链路层传输,信用值不足时,发送操作暂停,直到接收端通过DLLP更新信用值。信用值更新延迟通常控制在微秒级,且信用值采用增量更新机制,仅传输变化量。不同的事务消耗的信用值不同,如下表所示。
| 事务类型 | TLP 示例 | 消耗的信用类型 | 信用消耗计算方式 |
|---|---|---|---|
| Memory Write (MWr) | MWr 带 64B Payload | Posted Header (PH) + Posted Data (PD) | 1 PH (Header) + 16 PD (64B ÷ 4B/DW) |
| Memory Write (MWr) | MWr 不带 Payload (MWr0) | Posted Header (PH) | 1 PH (仅 Header,无 Data 消耗) |
| Memory Read (MRd) | MRd 请求 128B 数据 | Non-Posted Header (NPH) | 1 NPH (Header,无 Data 消耗) |
| Completion with Data (CPLD) | CPLD 返回 128B 读数据 | Completion Header (CPLH) + Completion Data (CPLD) | 1 CPLH + 32 CPLD (128B ÷ 4B/DW) |
| Completion without Data (CPL) | CPL 确认原子操作完成 | Completion Header (CPLH) | 1 CPLH (无 Data 消耗) |
| Configuration Read (CfgRd) | CfgRd 读取设备配置 | Non-Posted Header (NPH) | 1 NPH (Header,无 Data 消耗) |
| Configuration Write (CfgWr) | CfgWr 写入设备配置 | Posted Header (PH) | 1 PH (Header,无 Data 消耗) |
| Message (Msg/MsgD) | MsgD 带 16B 数据 | Posted Header (PH) + Posted Data (PD) | 1 PH + 4 PD (16B ÷ 4B/DW) |
| I/O Write (IOWr) | IOWr 写入 4B 数据 | Posted Header (PH) + Posted Data (PD) | 1 PH + 1 PD (固定 4B 操作) |
| I/O Read (IORd) | IORd 请求 4B 数据 | Non-Posted Header (NPH) | 1 NPH (Header,无 Data 消耗) |
| AtomicOp (FetchAdd/CAS) | FetchAdd 请求 8B 操作 | Non-Posted Header (NPH) | 1 NPH (Header,无 Data 消耗) |

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









