



1. Llama3 简介
4月19日,Meta在官方博客官宣了Llama3,标志着人工智能领域迈向了一个重要的飞跃。Llama 3 在超过 15 万亿个标记上进行训练,比 Llama 2 的数据集大 7 倍多。它大大降低了错误拒绝率,并提供了更高的响应一致性和多样性。此外,它还集成了新的信任和安全工具,如 Llama Guard 2、Code Shield 和 CyberSec Eval 2。
Llama 3 是Meta开源的大型语言模型的最新迭代版本,具有出色的性能和可访问性。Llama 3 的模型大小从 80 亿(8B)到 700 亿(70B)参数不等,为自然语言处理任务提供了强大的工具。然而,本地运行如此庞大的模型可能具有挑战性,需要大量的计算资源和技术专业知识。
在接下来的月份里,Meta 期望推出新的功能、更长的上下文窗口、额外的模型尺寸以及提升的性能,并且Meta 将分享Llama 3的研究论文。 以Llama 3技术构建的Meta AI现已成为世界领先的AI助手之一,能够增强您的智慧并减轻您的负担——帮助您学习、完成任务、创作内容以及连接,以充分利用每一刻。
2. Llama3的性能
在Llama 3项目中,Meta致力于打造最佳的开源模型,使其能够与当今可用的最优质的私有模型相媲美。Meta希望解决开发者的反馈,以提高Llama 3的整体帮助度,同时继续在大规模语言模型(LLMs)的负责任使用和部署方面发挥领导作用。Meta拥抱开源精神,即尽早并经常发布中间产品,以便社区能够在这些模型仍然在开发中时获得访问权限。今天Meta发布的基于文本的模型是Llama 3集合中的第一批模型。在不远的将来,Meta的目标是使Llama 3成为一个多语言和多模态的模型,具有更长的上下文记忆力,并在核心LLM能力(如推理和编程)上继续提高整体性能。
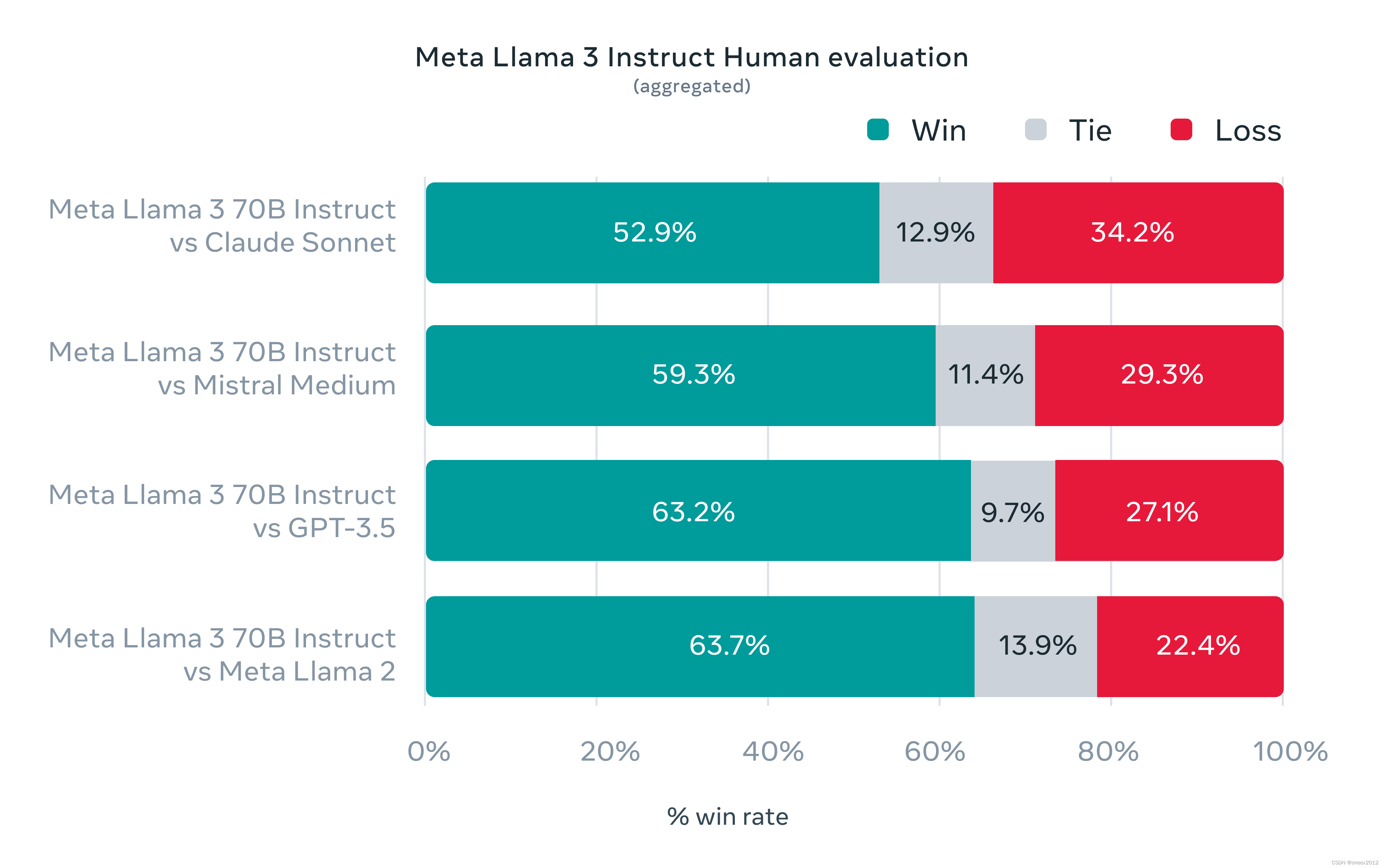
在开发Llama 3的过程中,Meta不仅考察了模型在标准基准测试上的表现,还致力于优化真实场景下的性能。为此,Meta开发了一个新的高质量的人工评估数据集。这个评估数据集包含1800个提示,涵盖了12个关键使用案例:寻求建议、头脑风暴、分类、封闭性问题解答、编程、创意写作、信息提取、扮演角色/人格、开放性问题解答、推理、改写和摘要。为了防止Meta的模型在这个评估数据集上无意中过度拟合,即使是Meta自己的建模团队也没有访问权限。下面的图表展示了Meta的人工评估结果在这些类别和提示 across of these categories and prompts (越过这些类别和提示) aggregated results(汇总结果),与Claude Sonnet、Mistral Medium和GPT-3.5的对比。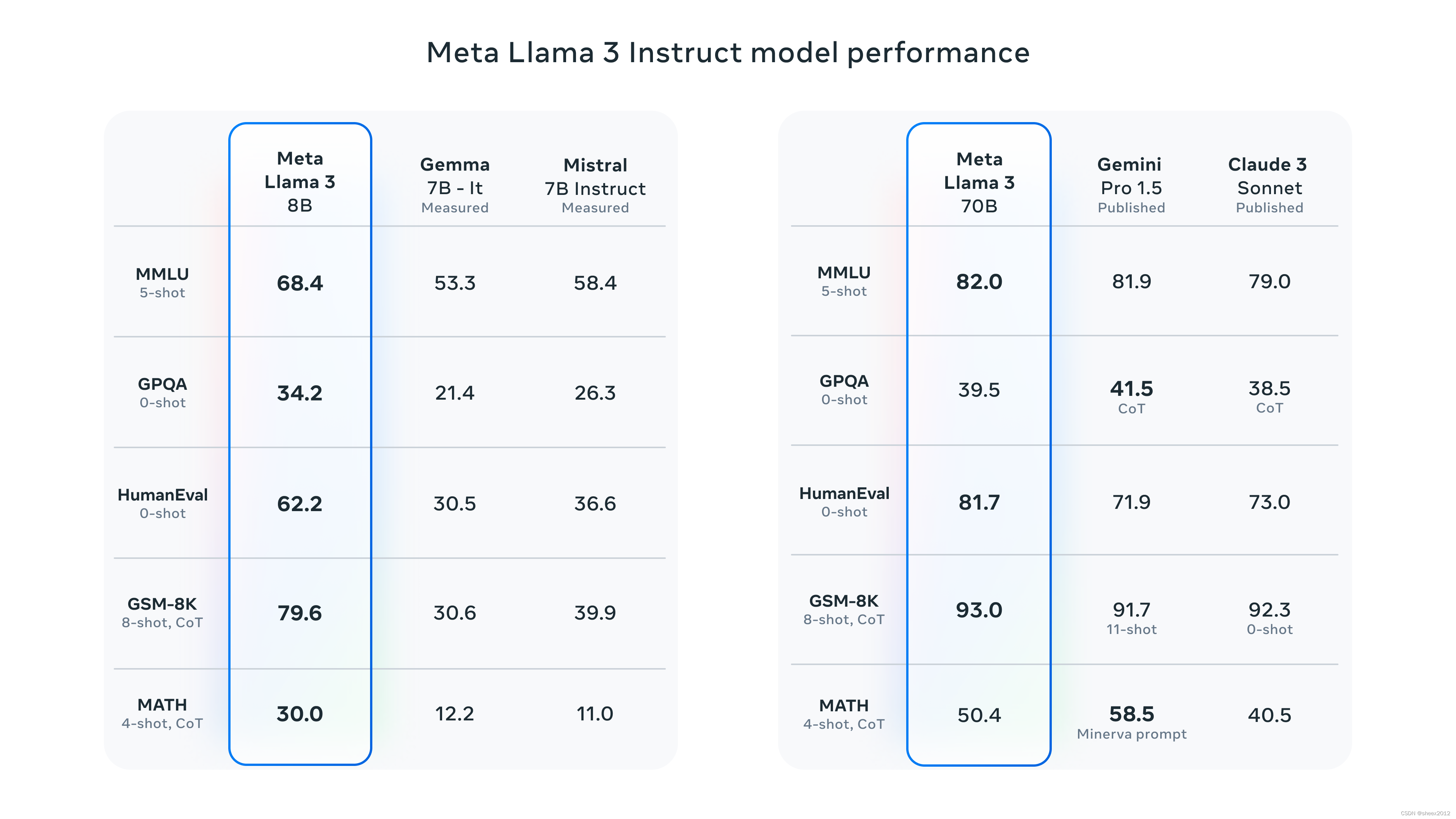
3. 安装 Ollama
本地运行如此庞大的模型可能具有挑战性,需要大量的计算资源和技术专业知识。幸运的是,很多厂商和开源社区纷纷开发了非常高效的大模型部署和应用工具。 Ollama 就是其中一个用户友好的解决方案,它优化了设置和配置细节,包括 GPU 使用情况,使开发人员和研究人员更容易在本地运行大型语言模型。Ollama 支持各种模型,包括 Llama 3,让用户能够探索和实验这些尖端的语言模型,而无需复杂的设置过程。
我们打开官方网站https://ollama.com/download,下载Ollama.
然后,双击OllamaSetup.exe,一路无脑点击,Ollama很快就安装好了。
根据一般规律,3B模型需要8G内存,7B模型需要16G内存,13B模型需要32G内存,笔者主机显卡是4070Ti 12G,只能选择7B模型(4bit量化版),在运行的Shell窗口中输入命令,ollma run llama3:
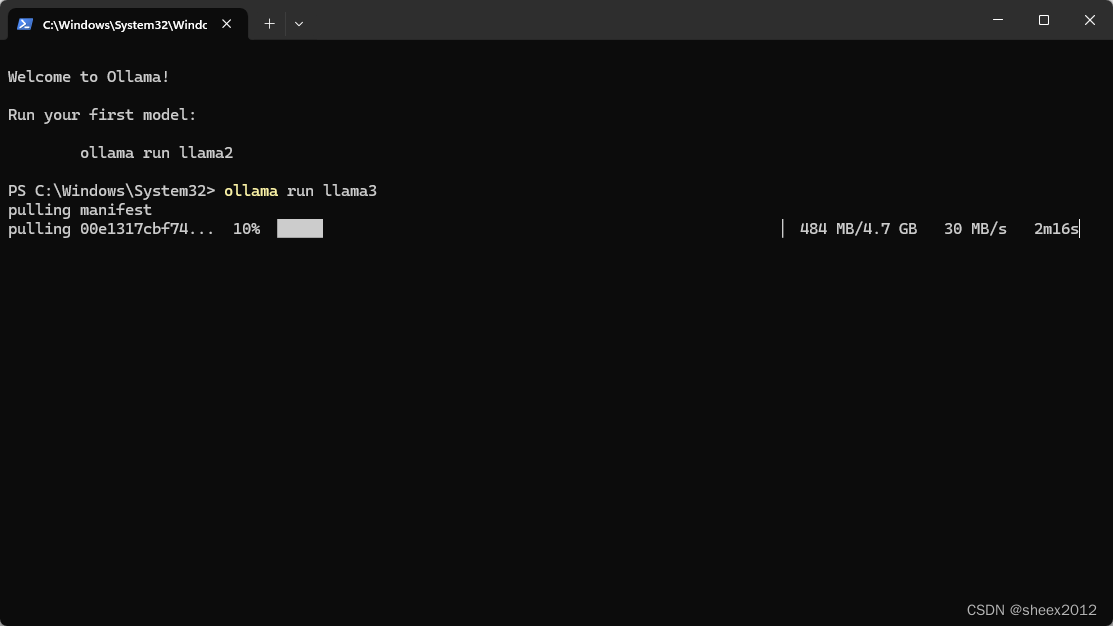
ollama将自动下载和部署llama3模型(30M的下载速度,不用科学上网,给ollama点赞),完成后,就直接可以在输入问题了:

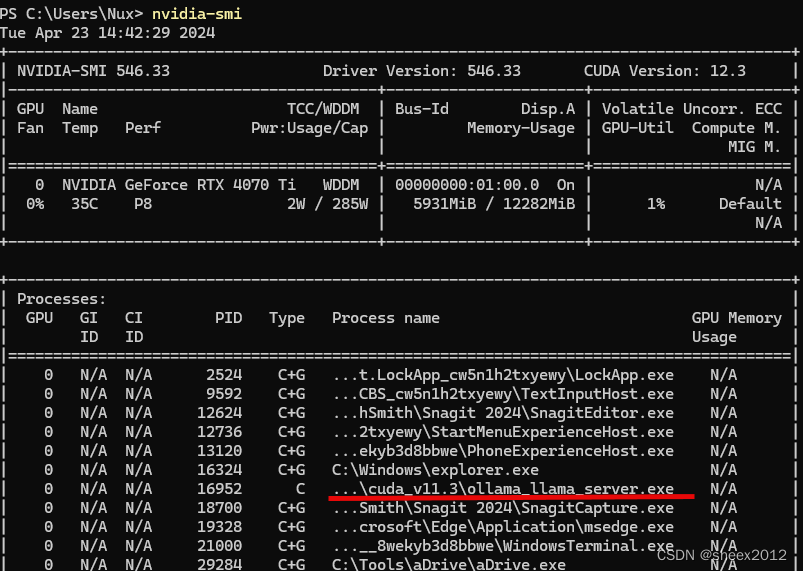
GPU内存占用不到6G:
4. WebUI接入
直接使用Shell窗口显得不够高大上,我们也接入采用浏览器接入,open-webui需要安装Docker,显得有点臃肿,这里直接使用最简单的零配置的两个开源工具:ollama-ui和saddle,下载后直接使用即可,下图分别是ollama-ui和saddle的使用界面:
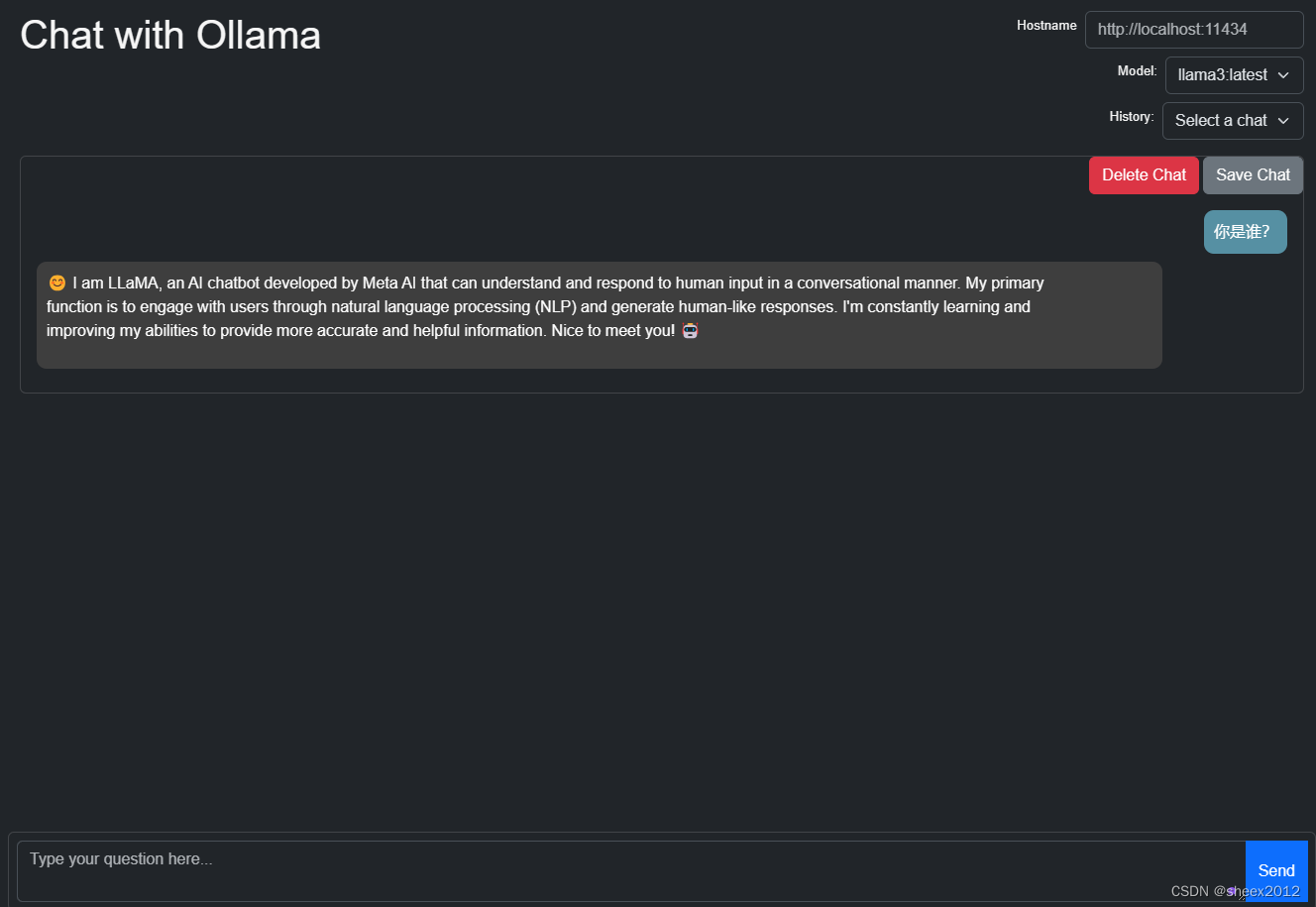
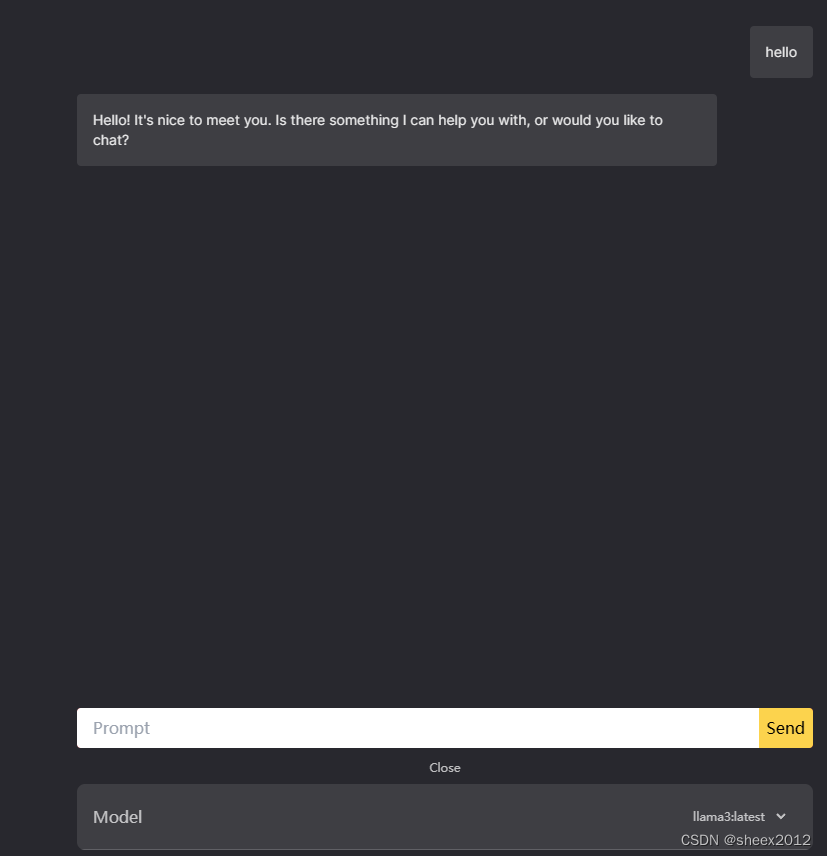
除了Web UI接入,Ollama还提供了丰富的Rest API接口来运行和管理模型,(参见https://github.com/ollama/ollama/blob/main/docs/api.md),Ollama 提供的 Python API,允许您以编程方式与模型进行交互,将模型应用到自己的应用中,实现与您的项目的无缝集成。
import ollama
# 加载模型
model = ollama.load("llama3-8b")
# 生成文本
prompt = "从前,有一次"
output = model.generate(prompt, max_new_tokens=100)
print(output)5. 小结
近年来,随着大语言模型的飞速发展,大模型的本地化部署和应用技术也得到了充分重视,各种一键式安装程序层出不穷,大大降低了大模型的部署复杂性,进一步促进了大模型的应用。这次Meta刚刚发布了Llam3模型,短短一天内,各大厂商便完成适配并将其放到仓库中,针对中文的微调版本也迅速发布。这既说明了大语言模型的热度,也表明了相关厂商和社区的快速技术跟踪能力。笔者后续也会将其与RAG结合起来,构建更加有趣的LLM应用。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









