



你是否曾期望机器学习模型能取得很好的结果,但结果却很差?你付出了努力,那么问题出在哪里?如何解决?
评估分类模型的方法有很多,但混淆矩阵(confusion matrix)是最可靠的选择之一。它显示了模型的表现如何以及在哪里出错,从而帮助你改进。
初学者经常觉得混淆矩阵令人困惑,但它实际上很简单,功能强大。本教程将解释机器学习中的混淆矩阵是什么,以及它如何提供模型性能的完整视图。
尽管名字如此,但你会发现混淆矩阵简单有效。让我们一起探索混淆矩阵吧!
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、什么是混淆矩阵?
混淆矩阵是机器学习中的一种性能评估工具,表示分类模型的准确性。它显示真阳性、真阴性、假阳性和假阴性的数量。该矩阵有助于分析模型性能、识别错误分类并提高预测准确性。
混淆矩阵是一个 N x N 矩阵,用于评估分类模型的性能,其中 N 是目标类别的总数。矩阵将实际目标值与机器学习模型预测的值进行比较。这让我们全面了解我们的分类模型的表现如何以及它犯了哪些类型的错误。
对于二元分类问题,我们将有一个 2 x 2 矩阵,如下所示,包含 4 个值:
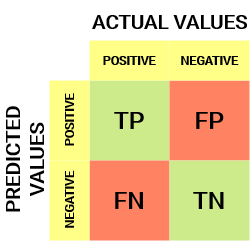
让我们来解读一下这个矩阵:
- 目标变量有两个值:正值(Positive)或负值(Negative)
- 列表示目标变量的实际值(Actual Values)
- 行表示目标变量的预测值(Predicted Values)
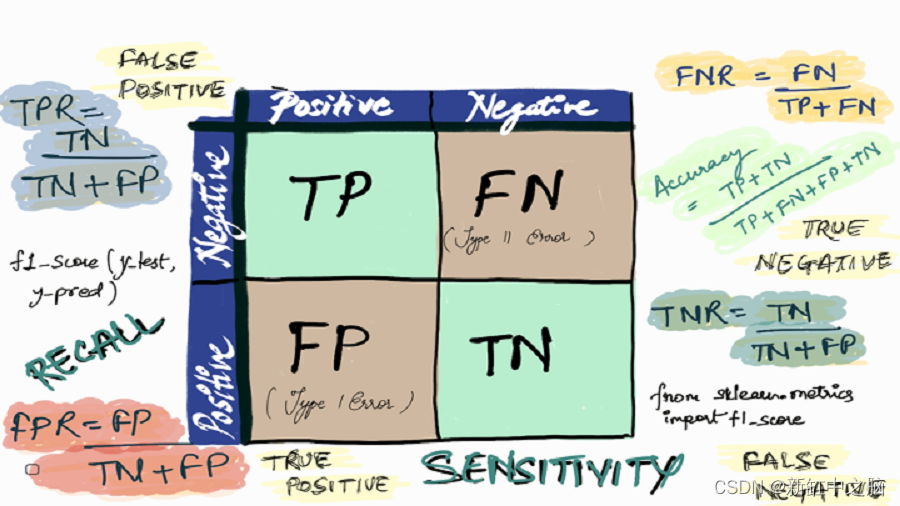
但等等——这里的 TP、FP、FN 和 TN 是什么?这是混淆矩阵的关键部分。让我们在下面理解每个术语。
2、混淆矩阵中的重要术语
真阳性 (TP - True Positive):
- 预测值与实际值匹配,或预测类别与实际类别匹配。
- 实际值为正,模型预测为正值。
真阴性 (TN - True Negative):
- 预测值与实际值匹配,或预测类别与实际类别匹配。
- 实际值为负,模型预测为负值。
假阳性 (FP - False Positive) – I 类错误
- 预测值被错误预测。
- 实际值为负,但模型预测为正值。
- 也称为 I 类错误。
假阴性 (FN - False Negative) – II 类错误
- 预测值被错误预测。
- 实际值为正,但模型预测为负值。
- 也称为 II 类错误。
让我举一个例子来更好地理解这一点。假设我们有一个包含 1000 个数据点的分类数据集。我们在其上拟合一个分类器(例如逻辑回归或决策树)并得到以下混淆矩阵:
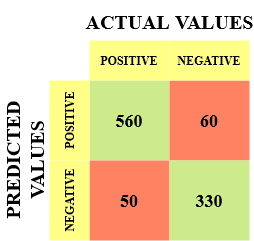
混淆矩阵的不同值如下:
- 真阳性 (TP) = 560,表示模型正确分类了 560 个正类数据点。
- 真阴性 (TN) = 330,表示模型正确分类了 330 个负类数据点。
- 假阳性 (FP) = 60,表示模型错误地将 60 个负类数据点归类为属于正类。
- 假阴性 (FN) = 50,表示模型错误地将 50 个正类数据点归类为属于负类。
考虑到真阳性和真阴性值的数量相对较大,这对于我们的数据集来说是一个相当不错的分类器。
记住 I 类和 II 类错误。面试官喜欢问这两者之间的区别!
3、为什么我们需要混淆矩阵?
在回答这个问题之前,让我们先考虑一个假设的分类问题。
假设你想预测在出现症状并将他们与健康人群隔离之前有多少人感染了传染性病毒(有没有想到什么?)。我们的目标变量的两个值将是患病和未患病。
现在,你一定想知道,既然我们有全天候的朋友——准确度(Accuracy),为什么还需要混淆矩阵。好吧,让我们看看分类准确度有什么问题。点。我们将这样计算准确度:
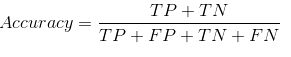
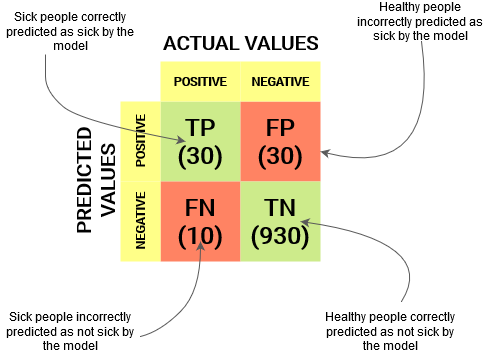
让我们看看模型表现如何:
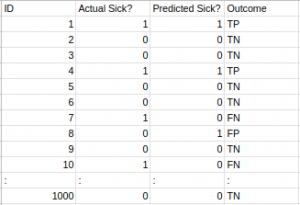
总体结果值为:
TP = 30,TN = 930,FP = 30,FN = 10
因此,我们模型的准确率结果为:
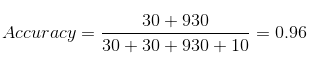
96%!还不错!
但它给出了错误的结论。想想看。
我们的模型说,“我可以 96% 的把握预测病人”。然而,它却在做相反的事情。它以 96% 的准确率预测不会生病的人,而病人却在传播病毒!
考虑到问题的严重性,你认为这是我们模型的正确指标吗?我们难道不应该衡量我们能正确预测多少阳性病例来阻止传染性病毒的传播吗?或者,在正确的预测中,有多少是阳性病例来检查我们模型的可靠性?
这就是我们遇到精确度(Precision)和召回率(Recall)的双重概念的地方。
4、如何计算 2 类分类问题的混淆矩阵?
要计算 2 类分类问题的混淆矩阵,需要了解以下内容:
- 真阳性 (TP):正确预测为阳性的样本数量。
- 真阴性 (TN):正确预测为阴性的样本数量。
- 假阳性 (FP):错误预测为阳性的样本数量。
- 假阴性 (FN):错误预测为阴性的样本数量。
获得这些值后,可以使用下表计算混淆矩阵:

以下是如何计算二类分类问题的混淆矩阵的示例:
# True positives (TP)
TP = 100
# True negatives (TN)
TN = 200
# False positives (FP)
FP = 50
# False negatives (FN)
FN = 150
# Confusion matrix
confusion_matrix = [[TP, FP], [FN, TN]]混淆矩阵可用于计算各种指标,例如准确率、精确度、召回率和 F1 分数。
5、精确度与召回率
精确度告诉我们有多少正确预测的案例实际上是阳性的。以下是如何计算精确度:
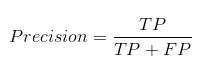
这将决定我们的模型是否可靠。
召回率告诉我们我们能够用我们的模型正确预测多少实际阳性案例。以下是我们如何计算召回率:
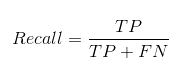
我们可以通过将值代入上述问题来轻松计算模型的精确度和召回率:
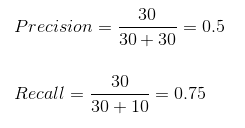
50% 的正确预测病例最终被证明是阳性病例。而我们的模型成功预测了 75% 的阳性病例。太棒了!
在FP比FN更受关注的情况下,精确度是一个有用的指标。
精确度在音乐或视频推荐系统、电子商务网站等中非常重要。错误的结果可能会导致客户流失并对业务造成损害。
在FN比FP更受关注的情况下,召回率是一个有用的指标。
在医疗案例中,召回率很重要,因为无论我们是否发出错误警报都无关紧要,但实际的阳性病例不应该被忽视!
在我们的例子中,当处理传染性病毒时,混淆矩阵变得至关重要。召回率评估捕获所有实际阳性的能力,是一个更好的指标。我们的目标是避免错误地将感染者释放到健康人群中,从而可能传播病毒。这一背景凸显了为什么准确率不足以作为我们模型评估的指标。混淆矩阵,尤其是关注召回率,在这种关键情况下提供了更有洞察力的衡量标准
但有些情况下,准确率和召回率哪个更重要并没有明显的区别。在这种情况下我们应该怎么做?我们把它们结合起来!
6、F1 分数是什么?
实际上,当我们试图提高模型的精确度时,召回率就会下降,反之亦然。F1 分数用一个值来捕捉这两种趋势:
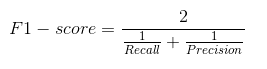
F1 分数是精确度和召回率的调和平均值,因此它给出了关于这两个指标的综合概念。当精确度等于召回率时,它最大。
但这里有一个问题。F1 分数的可解释性很差。这意味着我们不知道我们的分类器最大化的是什么——精确度还是召回率。因此,我们将它与其他评估指标结合使用,从而为我们提供结果的完整图景。
7、使用 Python 构建混淆矩阵
我们已经了解了理论,现在将其付诸实践。让我们使用 Python 中的 Scikit-learn (sklearn) 库编写一个混淆矩阵。
Sklearn 有两个很棒的函数: confusion_matrix() 和 classification_report()。
confused_matrix()返回混淆矩阵的值。但是,输出与我们迄今为止研究的略有不同。它将行作为实际值,将列作为预测值。其余概念保持不变。classification_report()输出每个目标类的精度、召回率和 f1 分数。除此之外,它还有一些额外的值:微平均值、宏平均值和加权平均值
微平均值(micro average)是针对所有类别计算的精度/召回率/f1 分数:

宏平均值(macro average)是精度/召回率/f1 分数的平均值:

加权平均值(weighted average)只是精度/召回率/f1 分数的加权平均值。
8、多类分类的混淆矩阵
机器学习中的混淆矩阵如何用于多类分类问题?好吧,别挠头了!我们在这里看看。
让我们为多类问题绘制一个混淆矩阵,我们必须预测一个人是喜欢 Facebook、Instagram 还是 Snapchat。混淆矩阵将是一个 3 x 3 矩阵,如下所示:
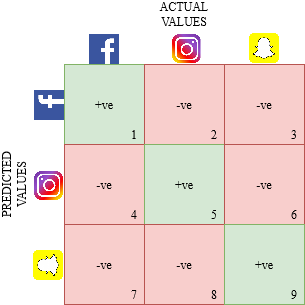
每个类别的真阳性、真阴性、假阳性和假阴性将通过将单元格值相加来计算,如下所示:
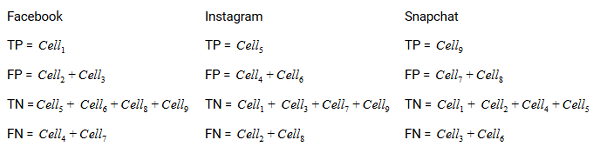
就是这样!我们已准备好解读任何 N x N 混淆矩阵!
9、结束语
混淆矩阵不再那么令人困惑了,对吧?
希望本文能为你提供有关如何解释和使用混淆矩阵进行机器学习分类算法的坚实基础。该矩阵有助于理解模型出错的地方,并提供纠正路径的指导,它是评估机器学习分类模型性能的强大且常用的工具。
原文链接:混淆矩阵简明教程 - BimAnt

















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









