



1. 简介
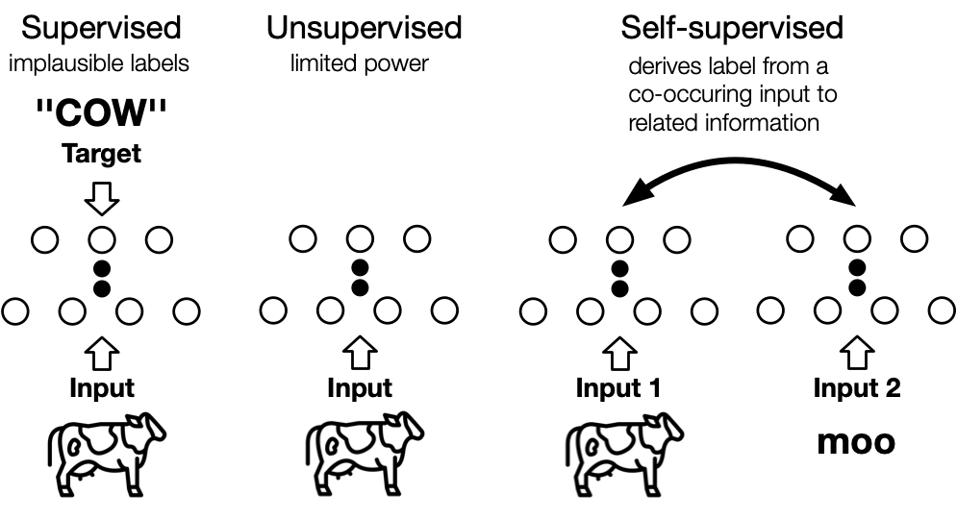
深度学习被分为:监督学习,无监督学习和自监督学习。
监督学习近些年获得了巨大的成功,但是有如下的缺点:
1.人工标签相对数据来说本身是稀疏的,蕴含的信息不如数据内容丰富;
2.监督学习只能学到特定任务的知识,不是通用知识,一般难以直接迁移到其他任务中。
无监督学习算法的结果可能不太准确,因为输入数据没有标记,并且算法事先不知道确切的输出。
由于这些原因,自监督学习的发展被给予厚望。自监督学习(Self-Supervised Learning)是无监督学习里面的一种,也被称作(pretext task)。自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
2. 技术路线
Unsupervised Pre-train, Supervised Fine-tune.
预训练模型使用自监督方法,下游任务使用监督方法微调
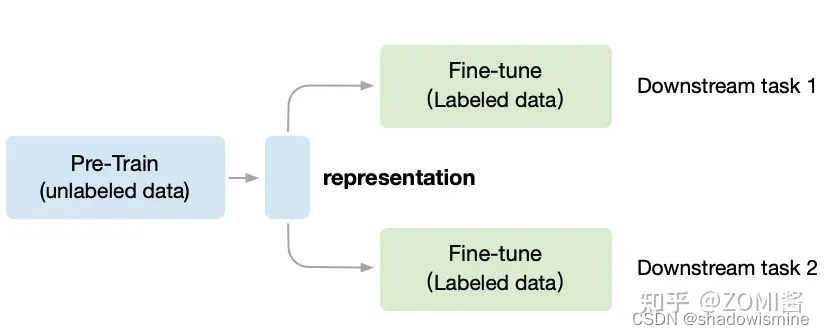
在无监督CV领域,第一阶段叫做in a task-agnostic way,在训练模型参数的时候,Self-Supervised Learning 就想不用带标签的数据,先把初始化网络模型的权重参数训练到基本可用,得到一个中间权重参数结果,我们把它叫做 Visual Representation。
第二阶段叫做in a task-specific way,根据下游任务 (Downstream Tasks) 使用带标签的数据集把参数训练到精度达标,这时使用的数据集量就不用太多了,因为参数经过了阶段一的预训练啦。
自监督学习又可以分为对比学习(contrastive learning) 和 生成学习(generative learning) 两条主要的技术路线。
2.1 对比学习
第一种是对比学习模型,核心思想是将正样本和负样本在特征空间进行对比,学习样本的特征表示,难点在于如何构造正负样本。代表作的 Kaiming 的 MoCo 引发一波热议, Yann Lecun 也在 AAAI 上讲自监督学习是未来的大势所趋。
对比学习首先学习未标记数据集上图像的通用表示形式,然后可以使用少量标记图像对其进行微调,以提升在给定任务(例如分类)的性能。对比表示学习可以被认为是通过比较来学习样本的表示。而生成学习(generative learning)是学习某些(伪)标签的映射的判别模型然后重构输入样本。在对比学习中,通过在输入样本之间进行比较来学习表示。对比学习不是一次从单个数据样本中学习信号,而是通过在不同样本之间进行比较来学习。可以在“相似”输入的正对和“不同”输入的负对之间进行比较。
对比学习通过同时最大化同一类样本的表示之间的相似性,以及最小化不同类样本之间的相似性来学习的。 简单来说,就是对比学习要做到相同类别的样本的表示要相近,所以要最大化同一类样本的表示之间的相似性。相反,如果是不同类别的样本,就要最小化它们之间的相似度。通过这样的对比训练,编码器(encoder)能学习到样本的更高层次的通用特征 (sample-level representations),而不是属性(像素)级别的生成模型(attribute-level generation)。
2.1.1 MoCo V1
基本原理:
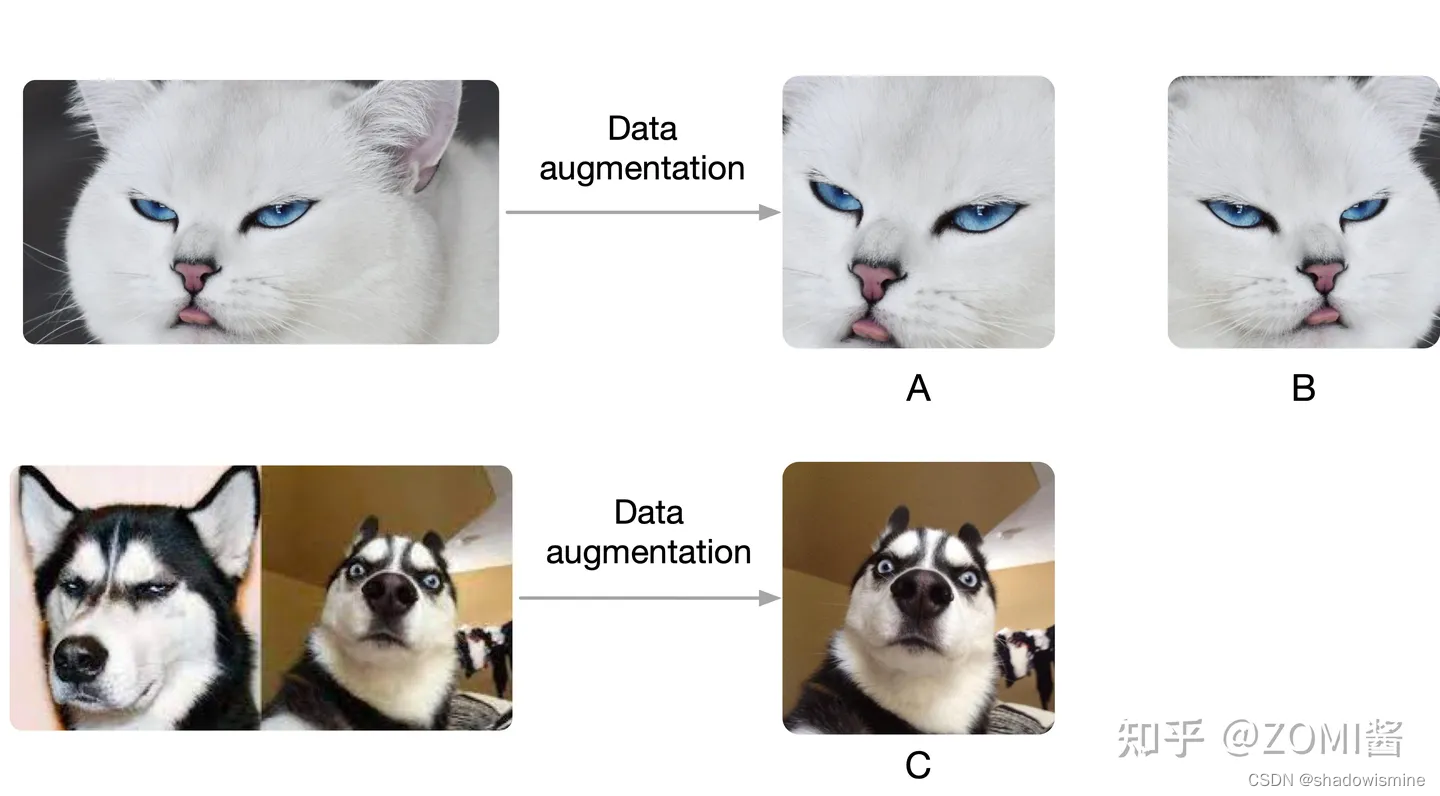
先考虑一个任务,现在有两个图片,图片1和图片2。先在图片1中通过数据增益产生两张图片,记作A,B,在图片2中截出一个patch记作C,现在把B和C放到样本库里面,样本库图片的位置随机打乱,然后以A作为查找的对象,让你从样本库中找到与A对应的图片。
假设随机裁剪了A,B, C三个图,然后将A设为被预测的对象,然后A通过encoder1编码为向量q,接着B、C经过encoder2编码为k1和k2。q和k1算相似度得到S1,q和k2算相似度得到S2。我们的目的是想要让机器学出来A和B是一类(关联性强),而A和C其它不是(关联性弱)。
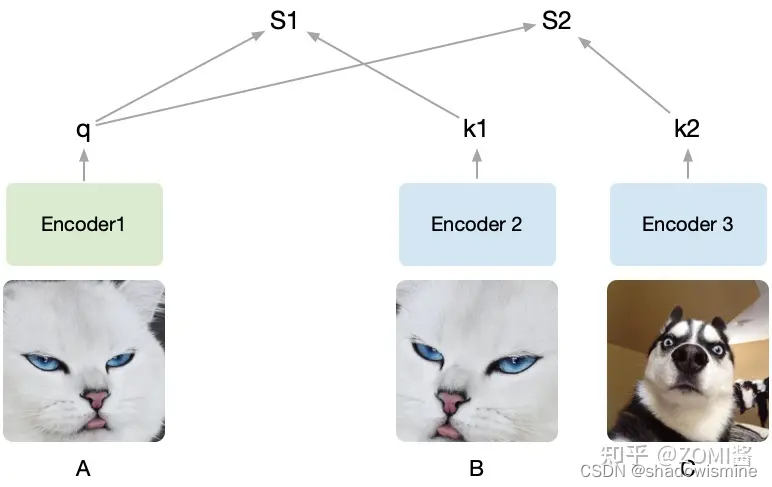
由于提前知道A和B是同一张图截出来的,而C不是,因此希望S1(A和B的相似度)尽可能高而S2(A和C的相似度)尽可能低。把B打上是正类的标签,把C打上是负类的标签,即同一张图片截出来的patch彼此为正类,不同的图片截出来的记为负类,由于这种方式只需要设定一个规则,然后让机器自动去打上标签,基于这些自动打上的标签去学习,所以也叫做自监督学习,MoCo就是通过不需要借助手工标注去学习视觉表征。
MoCo通过构建一个动态的负类队列来进行对比学习,依旧通过上面的例子来说,一般要学到好的表征需要比较多的负类样本,但是由于计算资源限制又不能加入太多的负类样本,并且我们也不希望负类样本是一成不变的,因此提出了就有了 dynamic dictionary with a queue。
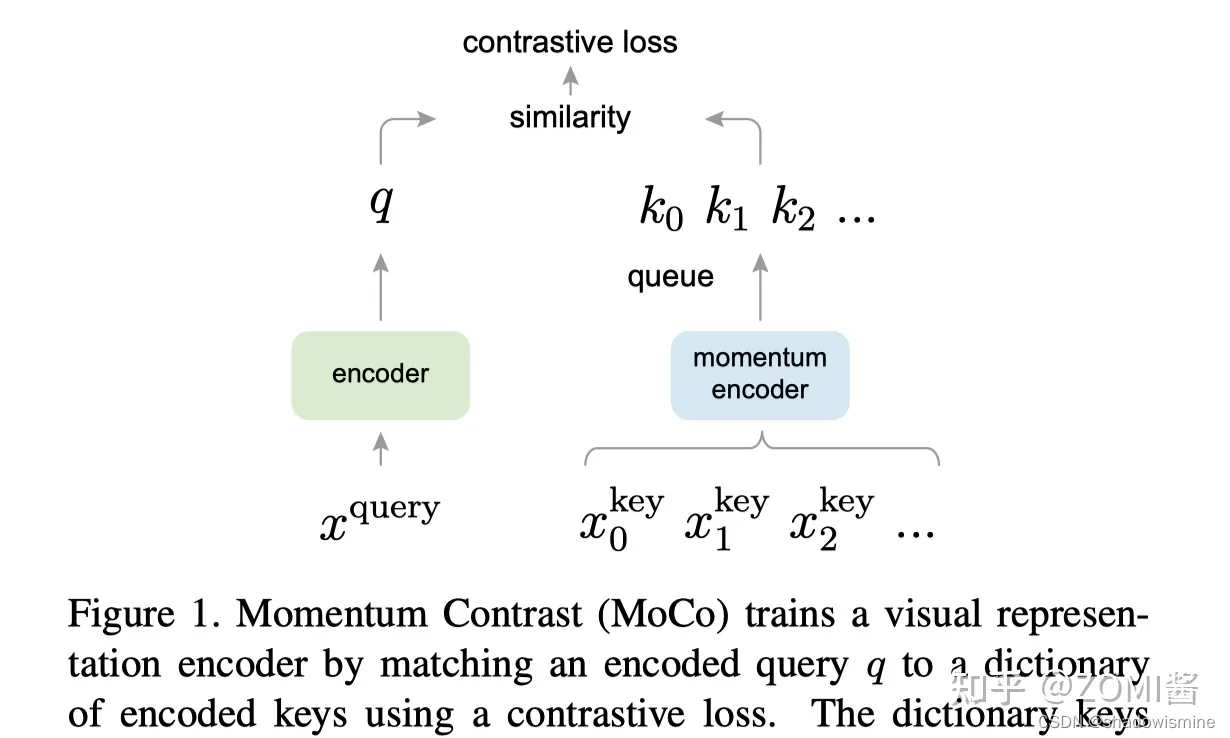
x^query可以类比上面的图A,x^key类比是图B和图C,图中的encoder可以是CNN,queue就是样本队列,剩下momentum encoder和contrastive loss。
contrastive loss:
对比学习关注的是能不能区别出同类和非同类的样本,Contrastive loss有很多不同的形式,MoCo使用的是InfoNCE,表达式如下:
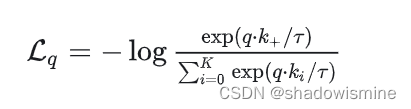
这里通过点积来计算 q 和 k 的相似度,k+ 是指正样本经过momentum encoder编码成的向量,注意的是里面对照样本里面只有一个正样本,其余都是负样本,至于分母 τ 就是softmax的温度参数,用来控制概率分布的尖锐和平滑。
momentum encoder:
原始的自监督学习方法里面的这一批负样本就相当于是有个字典 (Dictionary),字典的key就是负样本,字典的value就是负样本通过 Encoder 之后得到的特征向量。
那么现在问题来了:这一批负样本,即字典的大小是多大呢?
负样本的规模就是 batch size,即字典的大小就是 batch size。
举个例子,假设 batch size = 256,那么对于给定的一个样本 ,选择一个正样本 (经过data augmentation的图像)。然后选择256个负样本,然后使用 loss function 来将与正样本之间的距离拉近,负样本之间的距离推开到系数m。
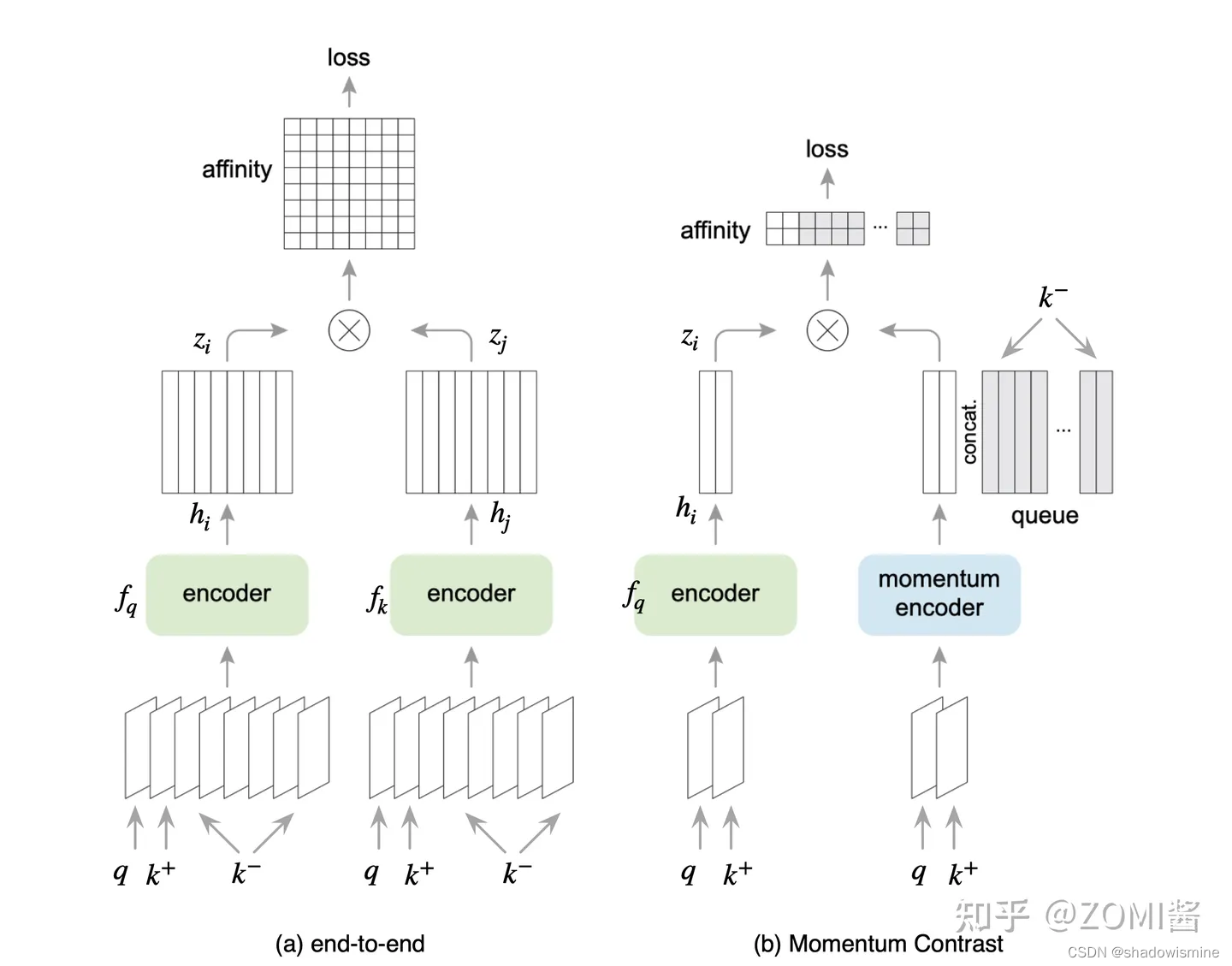
毫无疑问是 batch size 越大效果越好的,这一点在 SimCLR 中也得到了证明。但是,由于硬件的影响 batch size 不能设置过大,因此很难应用大量的负样本。因此效率较低,如图(a)。

于是图(b)采用一个较大的memory bank存储较大的字典:对于给定的一个样本 ,选择一个正样本 (经过data augmentation的图像)。采用一个较大的 memory bank 存储较大的字典,这个 memory bank 具体存储的是所有样本的表征 representation(涵盖所有的样本,比如样本一共有60000个,那么memory bank大小就是60000,字典大小也是60000)。采样其中的一部分负样本 ,然后使用Contrastive loss将 q 与正样本之间的距离拉近,负样本之间的距离推开。这次只更新 Encoder 的参数,和采样的key值 。因为这时候没有了 Encoder 的反向传播,所以支持memory bank容量很大。
但是,这一个step更新的是 Encoder 的参数,和几个采样的key值 ,下个step更新的是 Encoder 的参数,和几个采样的key值 ,Encoder 的参数每个step都更新,但是某一个 key 可能很多个step才被采样到更新一次,而且一个epoch只会更新一次。这就出现了一个问题:每个step编码器都会进行更新,这样最新的 query 采样得到的 key 可能是好多个step之前的编码器编码得到的 key,因此丧失了一致性。
从这一点来看,(a)端到端自监督学习方法的一致性最好,但是受限于batchsize的影响。而(b)采用一个memory bank存储较大的字典,一致性却较差。
(c)就是MoCo的做法,与(a)不同的是,右边的 Encoder 是不直接通过反向传播来训练的,而是优化器产生的动量更新,更新的表达式如下。
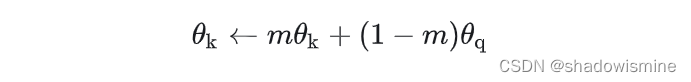
θ_k 是右边 Encoder 的参数,m默认设为0.999,θ_q 是左边编码 query 的 Encoder,θ_q 通过反向传播来更新,θ_k 则是通过 θ_q 动量更新。为什么采用这样的方式来更新?论文给出的解释是 θ_k 直接通过反向传播来更新的效果并不好,因为 θ_k 快速的变化会导致 key 的表征不稳定,但是动量更新很好地解决了这个问题。
现在的 Momentum Encoder 的更新是通过动量的方法更新的,不涉及反向传播,所以 输入的负样本 (negative samples) 的数量可以很多,具体就是 Queue 的大小可以比较大,那当然是负样本的数量越多越好了。这就是 Dictionary as a queue 的含义,即通过动量更新的形式,使得可以包含更多的负样本。而且 Momentum Encoder 的更新极其缓慢,所以Momentum Encoder 的更新相当于是看了很多的 Batch,也就是很多负样本。
MoCo的每个step都会更新Momentum Encoder,虽然更新缓慢,但是每个step都会通过更新 Momentum Encoder,这样 Encoder 和 Momentum Encoder 每个step 都有更新,就解决了一致性的问题。
2.1.2 MoCo V2
在 SimCLR v1 发布以后,MoCo的作者团队就迅速地将 SimCLR 的两个提点的方法移植到了 MoCo 上面,想看下性能的变化,也就是 MoCo v2。结果显示,MoCo v2 的结果取得了进一步的提升并超过了 SimCLR v1,证明 MoCo 系列方法的地位。因为 MoCo v2 文章只是移植了 SimCLR v1 的技巧而没有大的创新,所以作者就写成了一个只有2页的技术报告,还有长长的一页引用了大量文章。
SimSLR仍然采用端到端的方法,如图(a)的方式,不过在三个方面改进了实例识别的端到端变体:(i)一个更大的批(4k或8k),可以提供更多的负样本;(ii)用MLP头替换输出fc投影头;(iii)更强的数据增强。
在 SimCLR 中具体的来说,就是使用强大的数据增强策略,额外使用了 Gaussian Deblur 的策略和使用巨大的 Batch size,让自监督学习模型在训练时的每一步见到足够多的负样本 (negative samples),这样有助于自监督学习模型学到更好的 visual representations。
使用预测头 Projection head。在 SimCLR 中,Encoder 得到的2个 visual representation再通过Prediction head 进一步提特征,预测头是一个 2 层的 MLP,将 visual representation 这个 2048 维的向量 h_i, h_j 进一步映射到 128 维隐空间中,得到新的representation z_i, z_j。利用表征向量 z_i, z_j 去求 Contrastive loss 完成训练,训练完毕后扔掉预测头,保留 Encoder 用于获取 visual representation。
使用预测头
MoCo V1 的 Encoder 简单使用了 ResNet50,然后输出通过 L2-norm 处理得到最后的输出。在 MoCo V2 中把 ResNet 中输出与1000分类相关的FC层换成了两层的 FC + Relu,隐藏层为2048维。
数据增强策略
对数据增强策略,作者在 MoCo v1 的基础上又添加了 blur augmentation,发现更强的色彩干扰作用有限。只添加 blur augmentation 就可以使得 ImageNet 分类任务的性能从 60.6% 增长到 63.4%,再加上预测头 Projection head 就可以使性能进一步涨到67.3%。
2.1.3 MoCo V3
MoCo v3 的算法原理不应该是这篇论文的重点,这篇论文的重点应该是将目前无监督学习最常用的对比学习应用在 ViT 上。MoCo v3 相比 v2 去掉了 memory queue,转而像SimCLR 那样采用large batch来取得稍好一点的结果,从结构上 encoder f_q 借鉴 BYOL(Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning) 那样增加了一个 prediction head(两层FC),在ResNet上效果有稍许提升。最后通过大量的实验,去证明如何去克服自监督中引入 ViT 训练不稳定的问题。

算法原理:
影响自监督 ViT 模型训练的关键是:instability,即训练的不稳定性。这种训练的不稳定性所造成的结果并不是训练过程无法收敛 (convergence),而是性能的轻微下降 (下降1%-3%的精度)。
MoCo v3 损失函数和 v1 和 v2 相同都是使用 InfoNCE。
不一样的是 MoCo V3 在网络结构的组成 Framework 有所差异,具体如图所示。因为引入了 ViT 视觉Transformer结构,所以对数据的输入不再是一张完成的图片,而是 image Patch。另外 Transformer对于长序列具有 Attention 的 Q、K、V 结构能够存储和记忆大量的信息,因此取消了 Memory Queue,直接利用大 Batch Size 来进行学习训练。
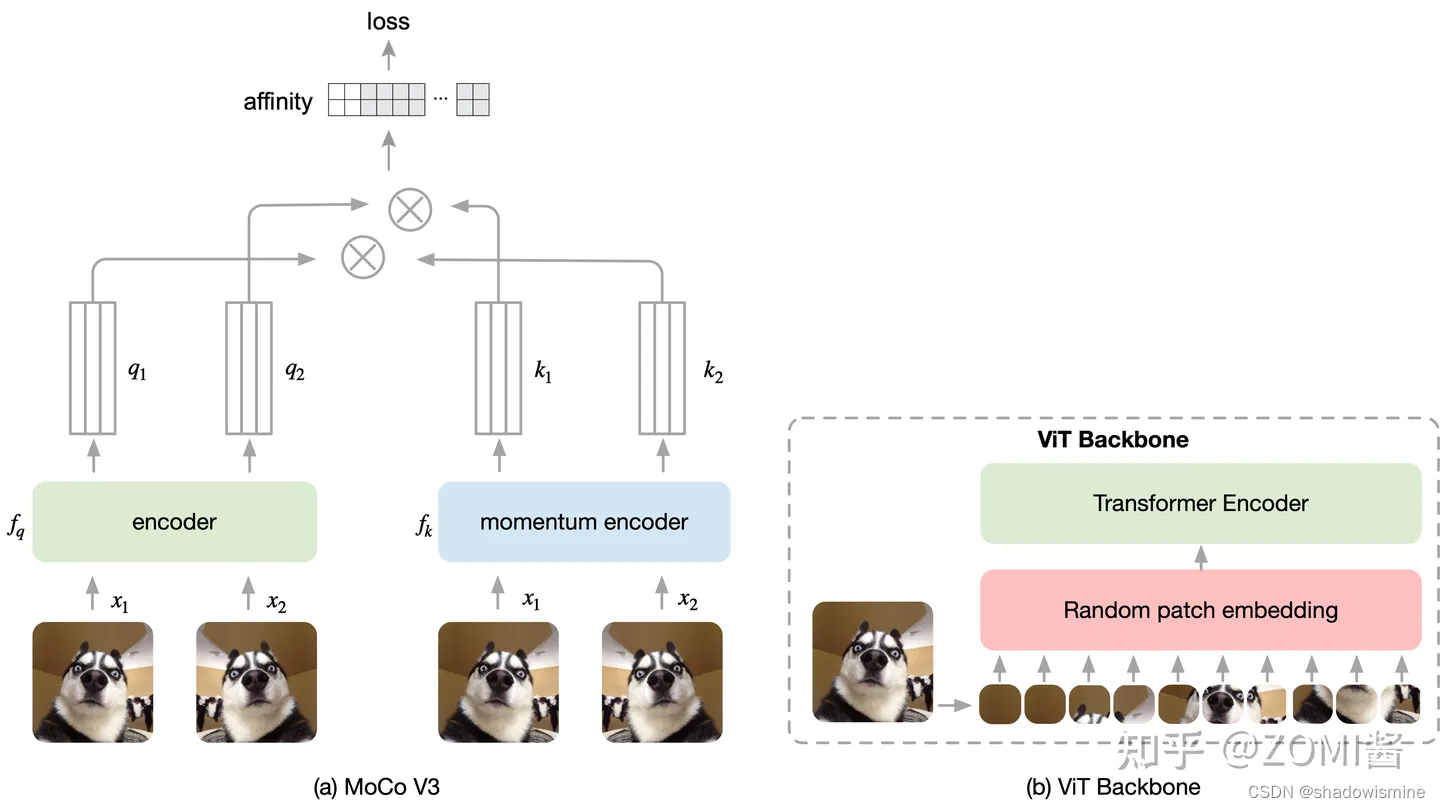
MoCo v3 的训练方法和 MoCo v1/2 的训练方法的差异是:
1. 取消 Memory Queue,用大 Batch Size:MoCo V3 的 Framework 里面没有 Memory Queue,这就意味着 MoCo v3 所观察的负样本都来自一个 Batch 的图片。换句话讲,只有当 Batch size 足够大时,模型才能看到足够的负样本,所以 MoCo v3 中 Batch size = 4096 这样一个巨大的 Batch size。
2. 学习 BYOL 添加 Prediction head:Encoder f_q 除了 Backbone 和预测头 Projection head 以外,还添加了个 Prediction head,是遵循了 BYOL 这篇论文的方法。即 Encoder f_q(ViT(BP) + Projection head + Prediction head),Encoder f_k(ViT(Momentum) + Projection head)。
3. Contrastive loss的更新方式修改:对于同一张图片的2个增强版本 x1,x2 ,分别通过 Encoder f_q 和 Momentum Encoder f_k 得到 q1,q2 和 k1,k2。让 q1,k2 通过 Contrastive loss (式 1) 进行优化 Encoder f_q的参数,让 q2,k1 通过 Contrastive loss (式 1) 进行优化 Encoder f_q的参数。Momentum Encoder f_k 则跟 MoCo V1 版本相同通过动量更新。即:
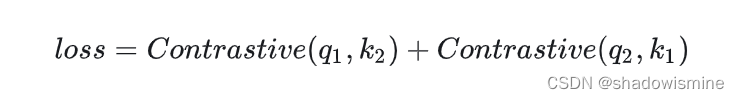
MoCo v3 的改进主要1)取消了 Memory Queue 的机制,2)添加了 Prediction head,3)更新Contrastive loss 优化 Encoder 参数方式。在 自监督学习引入 ViT 的过程中发现了训练不稳定性的问题,通过 random patch embedding 的方式暂时解决了目前问题,但是更大的 Batch Size仍然会引起 dip 问题还需要进一步研究啦。
2.2 生成学习
第二种是生成学习模型,它的目的是为了找到数据究竟是怎么生成的,它背后的机理是什么?
基于自监督学习的生成学习方法主要有AE、VAE、GAN这三大种,其中VAE是基于AE的基础上进行变形的生成模型,而GAN是近年来较为流行并有效的生成式方法。
2.2.1自编码器(AE)
AE主要由编码器和解码器组成,整个模型其实就相当于一个压缩解压的一个过程,编码器将真实数据进行压缩到低维隐空间中的隐向量,然后解码器将压缩的隐向量进行解压得到生成数据,当然在训练过程中会将生成数据和真实数据进行比较并更新参数。其实个人感觉其目的就是使得生成数据和输入的真实数据尽量相近,尽可能抓住真实数据的核心关键,如下图所示为AE的基本框架:(损失构建为x和y之间的mse_loss)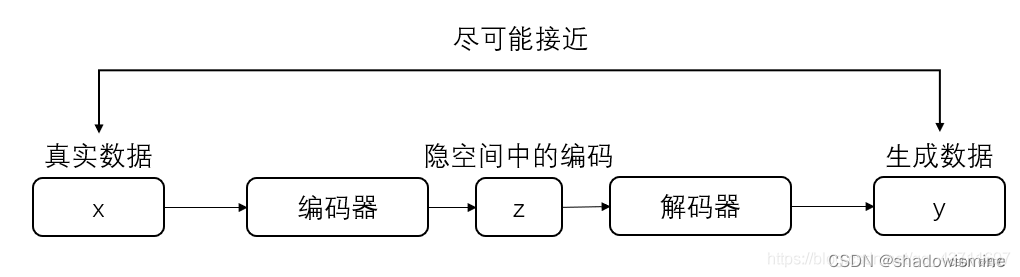
AE很好理解,最后拿Z作为模型学习的表示即可。
2.2.2 变分自编码器(VAE)
VAE就是AE的进化版本,基础结构和AE相差不大,但是在中间隐空间的编码部分并不相同。AE的主要特点是能够模仿,或者说和输入的数据尽可能接近,但缺少创新多样性;当然AE自编码器本身就是对输入数据的一个压缩编码,所以这也就是AE缺点的原因所在。再说说VAE的主要变化是,使编码器后产生的隐向量的概率分布能够尽量接近某个特定的分布(但是这个分布不太好估计),即编码器的直接输出的是所属正态分布的均值和标准差,然后根据均值和方差采样得到隐向量z,这样就可以根据采样的随机性生成具有多样性的生成图像,如下图是VAE的基本框架:(损失构建为和
之间的mse_loss)
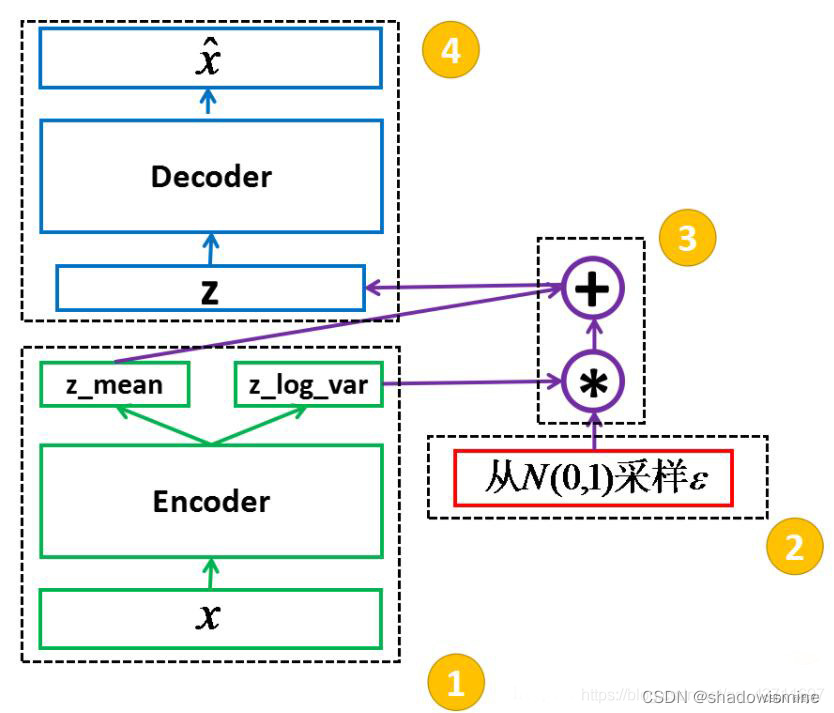
VAE也不难理解,也拿Z作为模型学到的表示。
2.2.3 生成对抗网络GAN
GAN主要由生成器和判别器构成,两者分别有自己的一个独立的网络结构,生成器生成图像再交给判别器进行判别,通过这样对抗训练的方式交替优化,生成器和判别器的对抗也被称为”MinMax游戏“,即判别器最大化真实样本的输出结果,最小化假样本的输出结果,而生成器则相反。如下图所示:(损失构建为最大化真实样本的输出结果(1),最小化假样本的输出结果(0))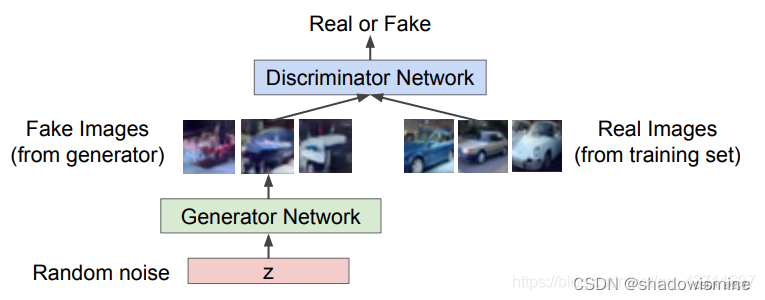
GAN是拿判别网络获得的表示来作为模型学到的表示,而生成网络起到的是辅助作用。
3. 语音-自监督学习
3.1 contrastive predictive coding (CPC)
论文链接:https://arxiv.org/abs/1807.03748
基于对比学习的思想,在视频序列上做自监督学习。在文章中,作者提出一种通用的无监督学习框架,其目的是从高维序列数据中提取有用的表征信息(Representation),将在上下文中提取到的表征信息和未来时刻样本的表征信息进行对比学习,获得最能预测未来的关键表征信息,称之为CPC (Contrastive Predictive Coding)。在文中证明了该方法能够学习有用的特征表示,并在语音、图像、文本和3D环境中的强化学习中都取得不错的效果。
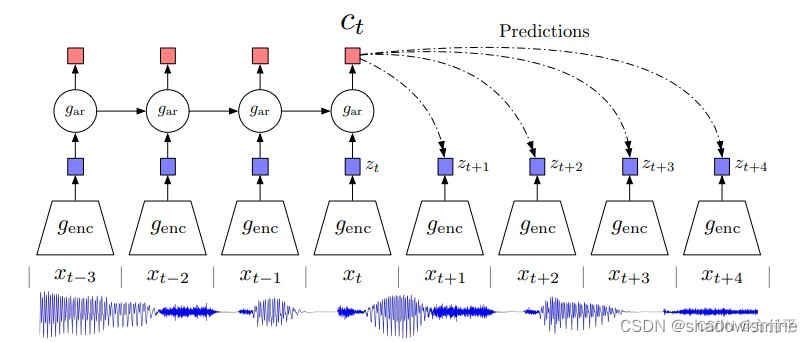
上图是本文最重要的结构图,首先将视频或者音频序列切分为合适的序列片段(下面用视频序列为例讲解),首先将视频片段用非线性编码器Auto Encoder或CNN映射到隐空间z中。
![]()
得到历史片段的编码之后,使用自回归模型GRU或者LSTM来融合历史时序信息z,得到历史信息的特征融合向量c
![]()
仔细观察互信息的表达式,可以发现互信息的表达式中含有x和c的联合分布,实际上预测样本和上下文信息c的联合分布无法获得,作者用神经网络来拟合互信息函数。
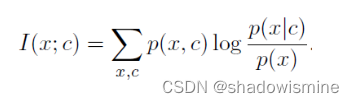
最后作者使用InfoNCE作为损失函数,来优化模型,使得x与c之间的互信息最大。
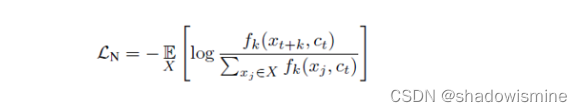
在这篇文章中,anchor为历史的时序编码经过自回归模型的输出c,正样本为该视频的未来一个采样序列的编码,负样本为随机从其他视频采样的一个序列片段的编码
。模型的目标是拉进c与
的距离,推远c与
的距离。
3.2 Transformer Encoder Representations from Alteration (TERA)
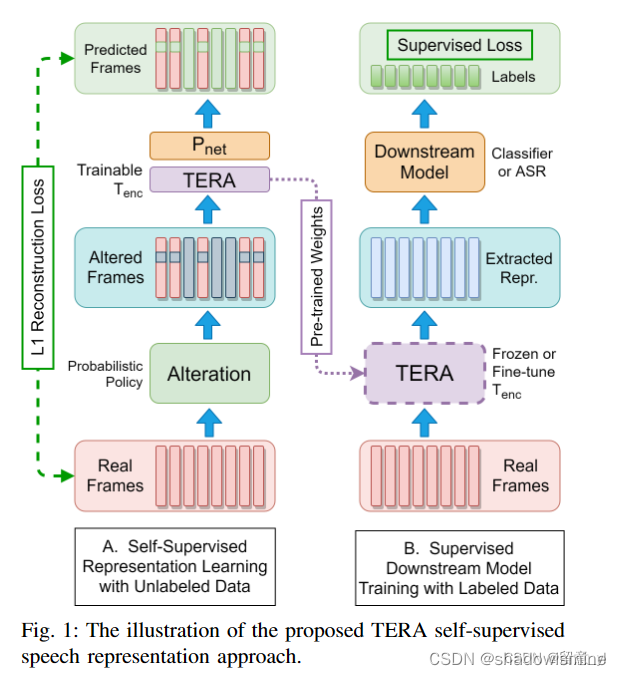
输入为log-Mel/fMLLR/MFCC/FBANK等特征,即红色矩形Real Frams。
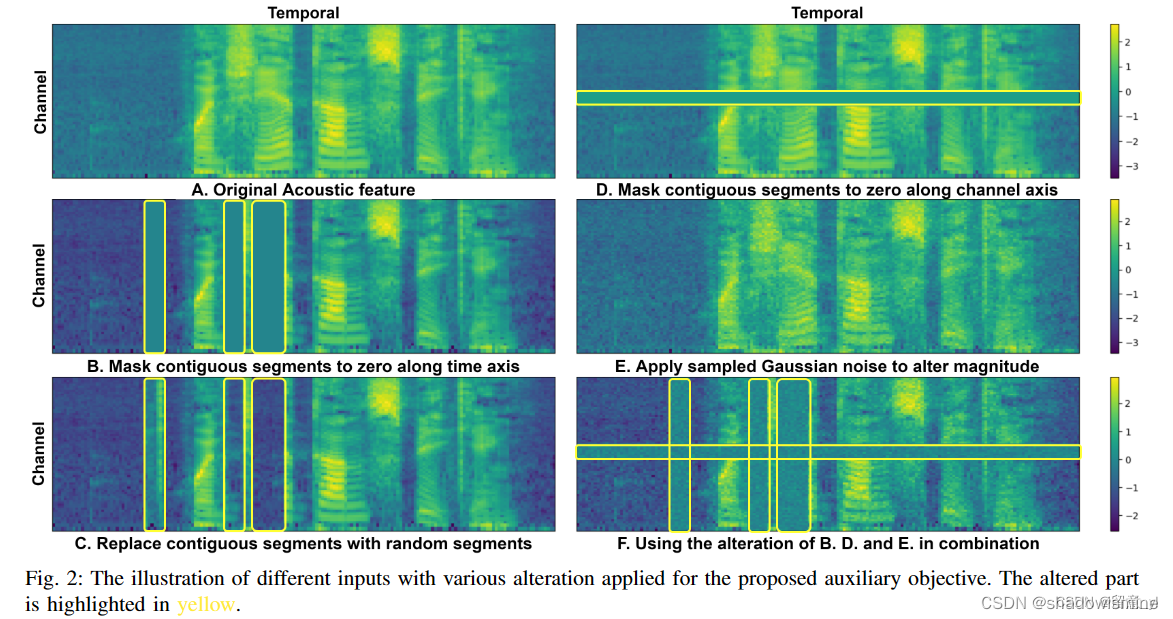
接着可以对特征进行处理,包括三种Alteration:Time Alteration(如下图B、C所示)、Frequency Alteration(D)、Magnitude Alteration(E)。三种同时使用(F)。得到altered input 。
将输入到Transformer encoder(Fig1 TERA矩形框) + Pnet(两层前馈网络)。Pnet输出为input signal的重构信号。模型获取关于损坏或更改部分周围的内容,通过重建信号使模型学到更多的上下文表征。
3.3 Wav2Vec
论文:wav2vec: Unsupervised Pre-training for Speech Recognition
本文提出一种无监督的语音预训练模型 wav2vec,可迁移到语音下游任务。模型结构如下图,分为将原始音频x编码为潜在空间z的 encoder network(5层卷积),和将z转换为contextualized representation的 context network(9层卷积),最终特征维度为512x帧数。目标是在特征层面使用当前帧预测未来帧。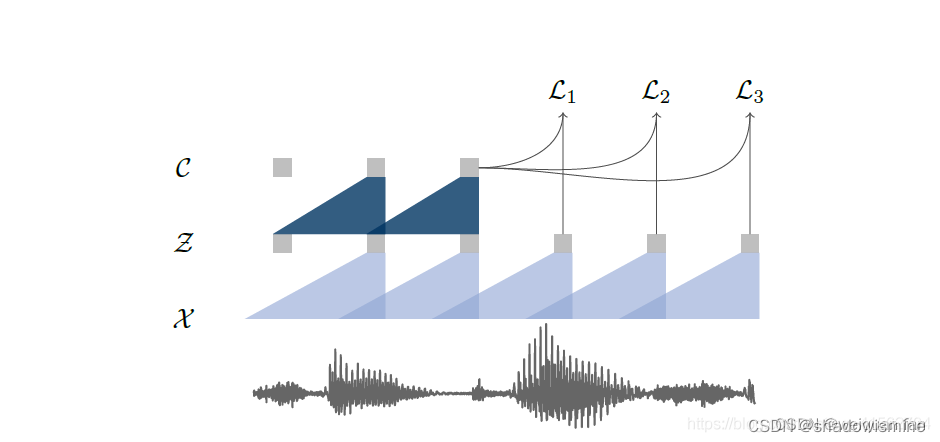
encoder network的任务是将x映射到低时频的特征,每个时间步的Zi对应10ms,音频样本为16kHz。然后将前一个网络输出的多个Zi通过Context network映射到Ci,形如Ci=g(zi…zi-v),Ci的感受野为v个时间步,context 网络的作用是通过给定的Zi来预测未来信息,强迫该表征学习上下文信息。具体见loss的计算方法: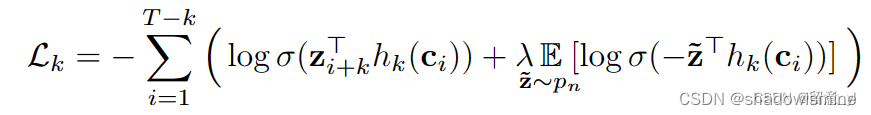
当预测第k个未来信息时,先对Ci做线性变换预测未来信息即hk(Ci), 用Zi+k当做答案,此为正样本,对两者做内积,向量越接近则绝对值越高。对于负样本,从Z中均匀地选择干扰因子,使预测的第k个时间步信息远离负样本。例如,k=1时,正样本对为Ci 和 Zi+1,k=2时,正样本对为Ci 和 Zi+2。负样本对为Ci和从encoder的所有输出Z 中随机选择的λ个样本。最后对K个时间步的损失加起来就是总损失。
![]()
3.4 vq-wav2vec
论文:vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations
本文基于wav2vec,将连续特征z通过提出的量化模块,变成离散特征z‘,实现特征空间从无限的连续到有限的离散的转换过程。文中提出了两种量化方法,Gumbel softmax和K-Means,如下图。 其中,左右两个部分中的 e1 … ev,就是码本(记录特征集,可以理解为 BERT 中的词表),Gumbel通过逻辑值最大化(回传时使用Gumbel softmax来保证可导)找对应码本条,K-Means通过计算与码本距离来找最小距离的码本条。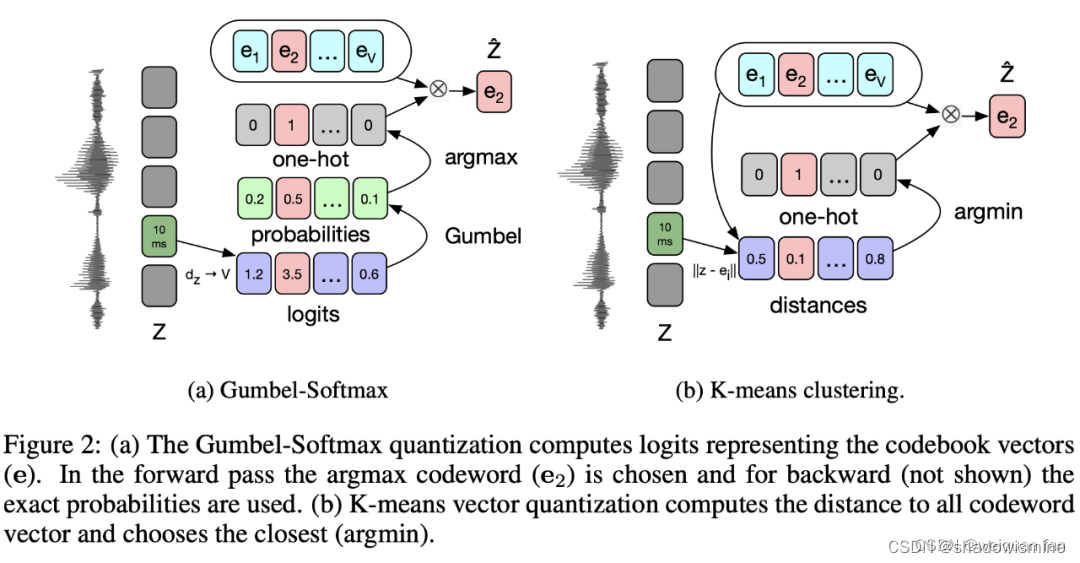
3.5 wav2vec2.0
论文:wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
本文基于wav2vec,结合了vq-wav2vec的量化模块和Transformer,提出了wav2vec2.0,如下图。其中,encoder network基于CNN,而context network基于Transformer,任务是在特征层面恢复被mask的量化的帧。
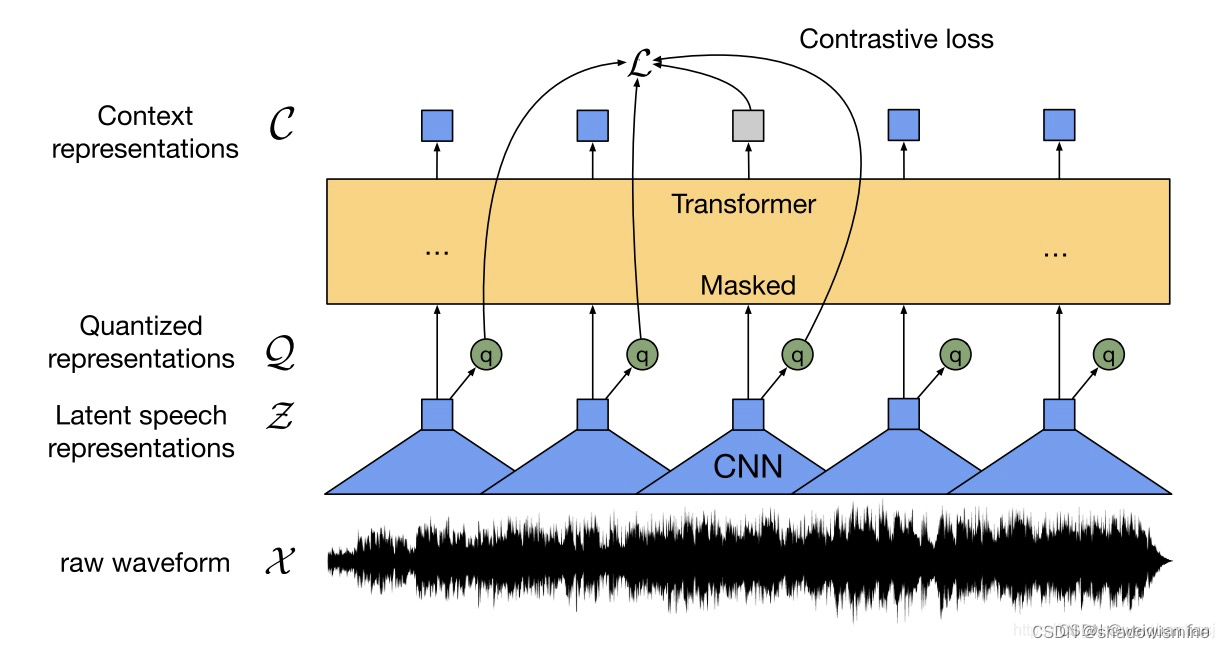
模型的整体结构如下图,以下具体讲解结构。
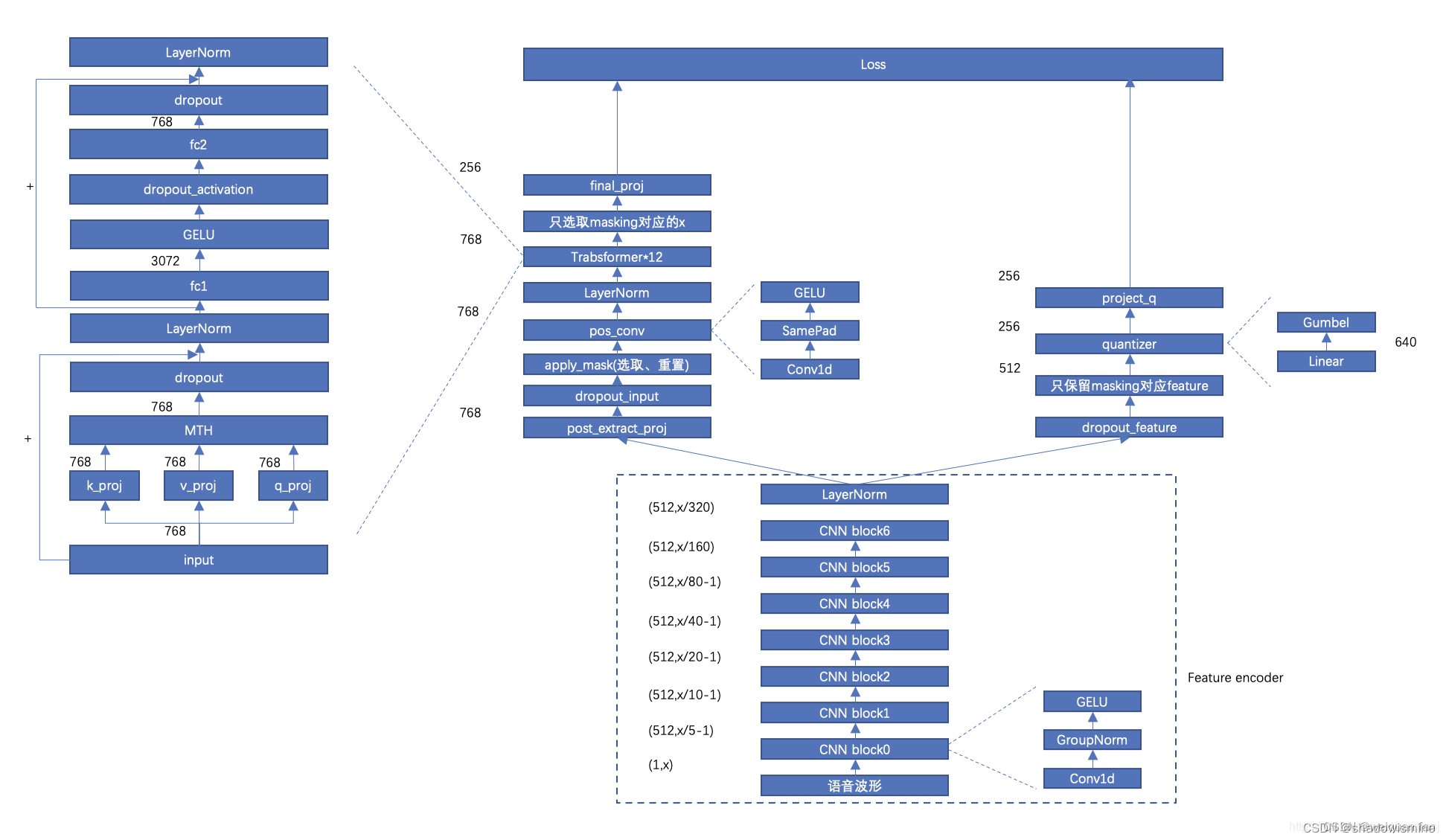
3.5.1 encoder
feature extractor 使用了7层的一维CNN,步长为(5,2,2,2,2,2,2),卷积核宽度为(10,3,3,3,3,2,2)。
对于x=16000的输入语音,各卷积层输出的时间维度为:
cnn0 (16000-10)/5+1 = 3199
cnn1 (3199-3)/2+1 = 1599
cnn2 (1599-3)/2+1 = 799
cnn3 (799-3)/2+1 = 399
cnn4 (399-3)/2+1 = 199
cnn5 (199-2)/2+1 = 99 (除法有小数,向下取整)
cnn6 (99-2)/2+1 = 49 (除法有小数,向下取整)
因此,对于16k采样率的1s的语音对应矩阵(1,16000),channels大小为512,对应的输出为 (512,49),时间维度上约相当于每20ms产生一个512维的特征向量,但实际上每一帧都经过多层卷积,可见到的时间不止20ms。
另外,在cnn0使用了GroupNorm,在cnn1-6的输出使用了GELU。
3.5.2 context
整体结构图中的context包括左右两部分,左边负责将z转换成c(对应wav2vec2特征),右边负责将z离散化以计算损失。
左边部分中,对于输入512x50的z,有:
post_extract_proj: 768x50
apply_mask->pos_conv->LN: 768x50
Transformer*12: 768x50
choose_masking: 768xM,M为mask的帧数
final_proj: 256xM
右边部分中,对于输入512x50的z,有:
choose_masking: 512xM
quantizer: 256xM
project_q: 256xM
其中,量化的参数有:码本个数G=2,每个码本的条目个数V=320,条目的维度d/G=256/2=128。参数含义:G=latent_groups,V=latent_vars,d=vq_dim。
具体的quantizer流程如下图所示,前向的时候直接找出来最大值对应的码本中的条目,相当于是一个离散的操作,但是这个步骤不可导,无法进行反向传播,为了解决这个问题,采用了gumbel softmax操作。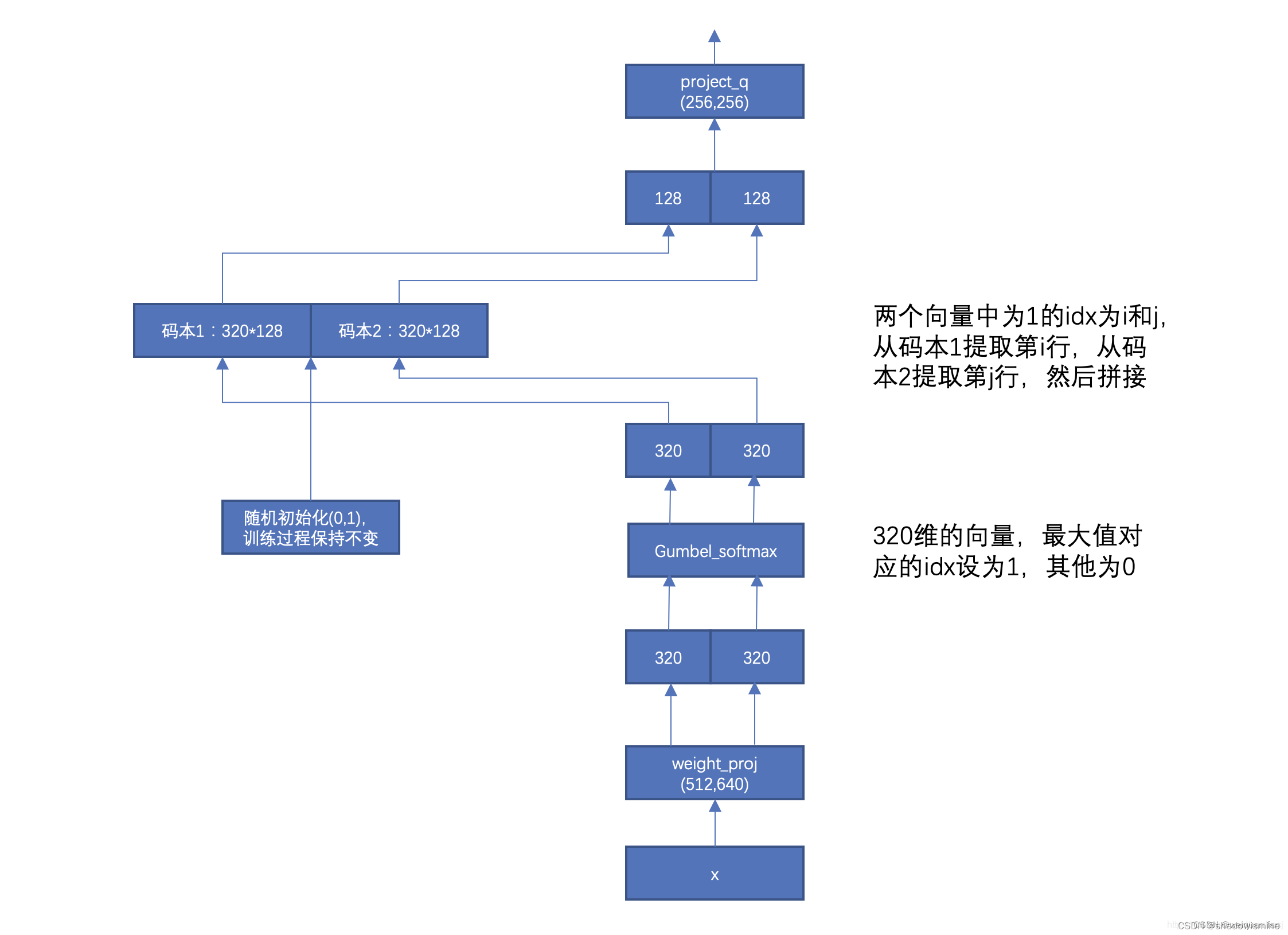
3.6 HuBert (Hidden Unit Bert)
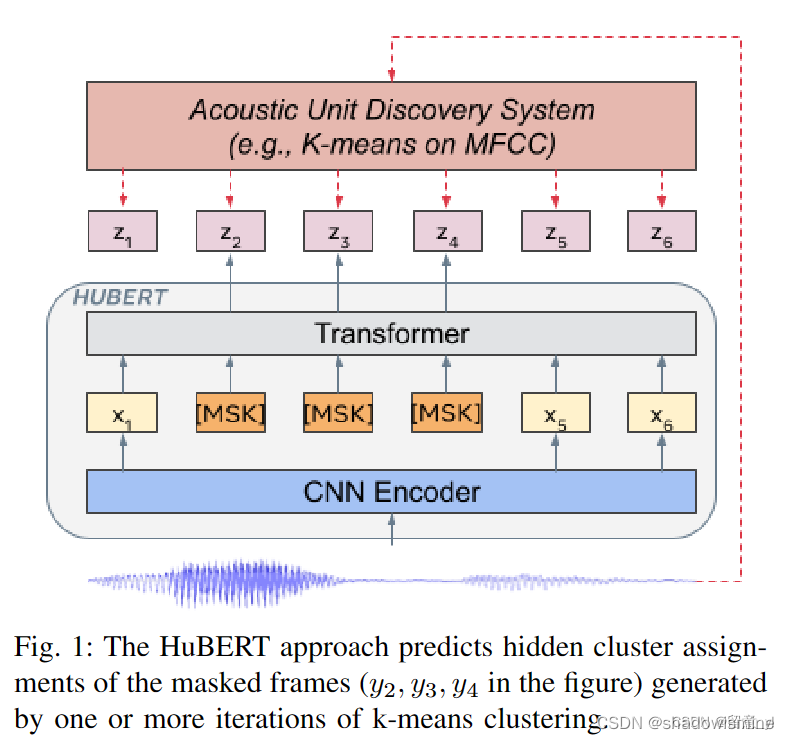
模型结构为CNN+Transformer Encoder,前者将原始语音编码到latent representation(512维),然后对其进行随机mask,每次mask连续的几帧,比如10帧,因为语音总是连续的。将被mask过的语音表征过Transformer encoder得到另一个表征(768维),此时预测出了被掩蔽的区域。另一边,对于输入的每一帧,采用K-means的方法对其进行分类,分类结果即为前述伪标签,并得到整条语音在类别上的分布,对预测结果同样做这样的操作。此时两者在时间上是对齐的,模型对这两个结果做交叉熵loss。预测损失仅用于掩蔽区域,迫使模型学习未掩蔽输入的良好高级表示,从而正确地推断掩蔽区域的内容。
参考的讲解:论文解读Hubert
3.7 WavLM
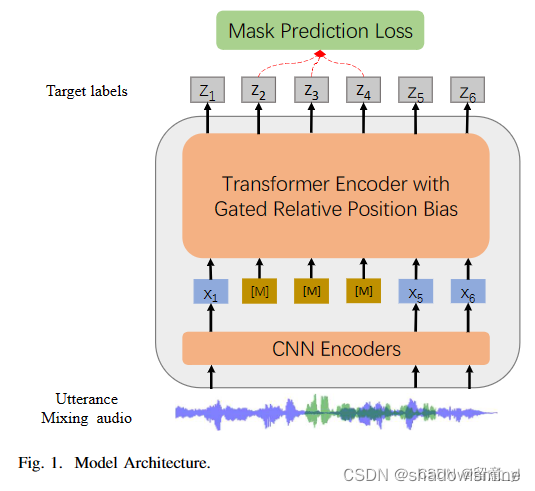
WavLM和UniSpeech-SAT都是HuBert的变体。
WavLM的改进在于:
1)一部分数据是带噪或重叠语音,从而其输出的表征能对语音分离和语音增强这一类任务起到很好的辅助作用,而不是仅针对ASR任务。其输入是带噪重叠语音,但在对预测结果做聚簇时,仍然和干净语音的簇比较。
2)模型结构也有不同,在Transformer Encoder加入了Gated Relative Position Bias,帮助网络更好的捕捉相对位置信息以及输入语音的序列顺序。
3)数据从60k增加到94k小时。
3.8 PASE+
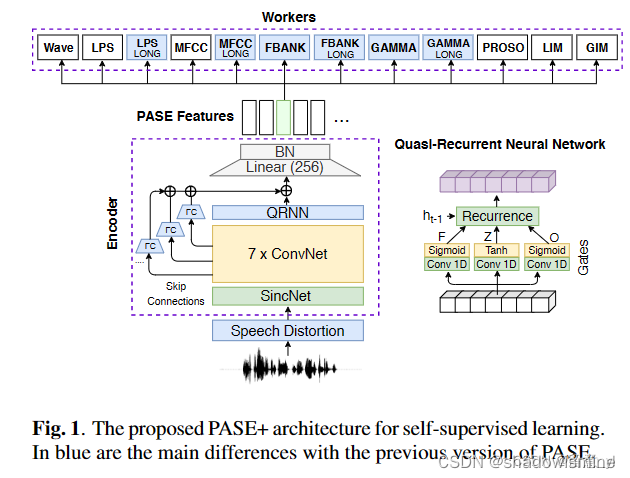
该模型由一个语音干扰模块,一个语音编码模块和12个workers构成。
语音干扰模块:通过向原始语音加入混响、噪声、频域掩蔽、时域掩蔽或裁剪等方式对其进行干扰。
12个workers是小型前馈神经网络,其任务为回归任务或二分类任务。回归任务包括估计语音特征、估计原始波形等。二分类任务包括LIM和GIM,分别有辨别不同说话人和更好地从一句输入语音中学习高维表征的能力。worker框中的LONG意味着使用了更长的analysis window(200ms),而不是其他任务常使用的25ms。
原文链接:https://blog.youkuaiyun.com/qq_51392112/article/details/128806998
论文阅读《Representation learning with contrastive predictive coding 》(CPC)对比预测编码-优快云博客
https://blog.youkuaiyun.com/qq_45048777/article/details/131710583
https://blog.youkuaiyun.com/tobefans/article/details/125434796

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









