




1 并行智算云容器实例使用
1.1 创建
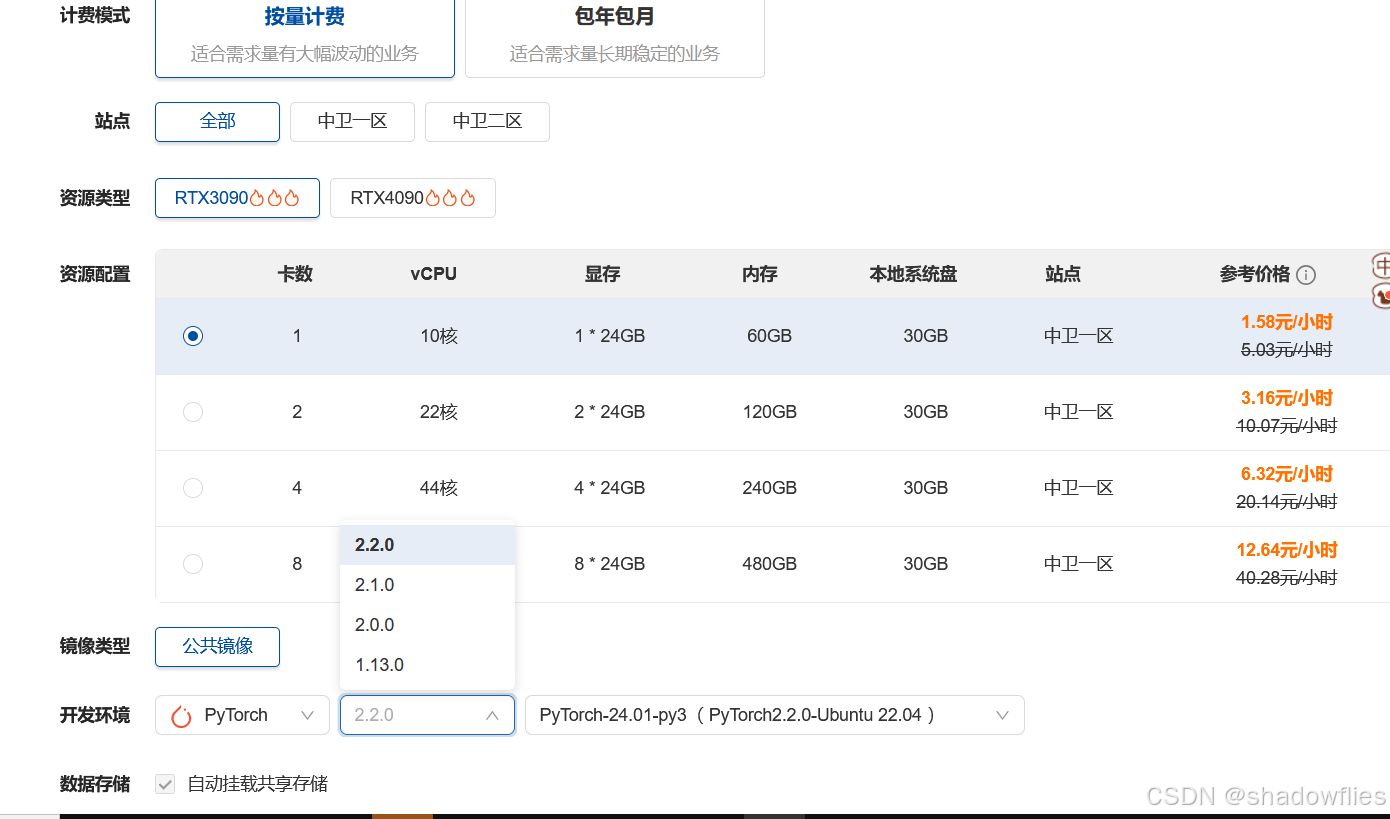
自己选择想要的配置
1.2 文件传输
文件传输比较慢,在线会计时,推荐创建完容器实例后再容器存储那里开始传输,可以离线传输

文件上传过程不稳定,加上不能断点续传,建议切分成几个200M左右的文件,到时再解压
然后最好上传根目录,上传后再连接vscode或ssh时再来操作文件夹创建和文件存放的问题,不然会有权限限制问题。
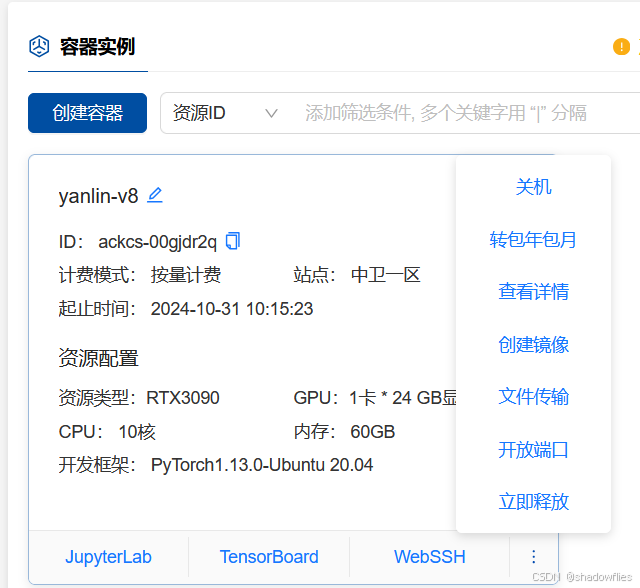
1.3 vscode连接
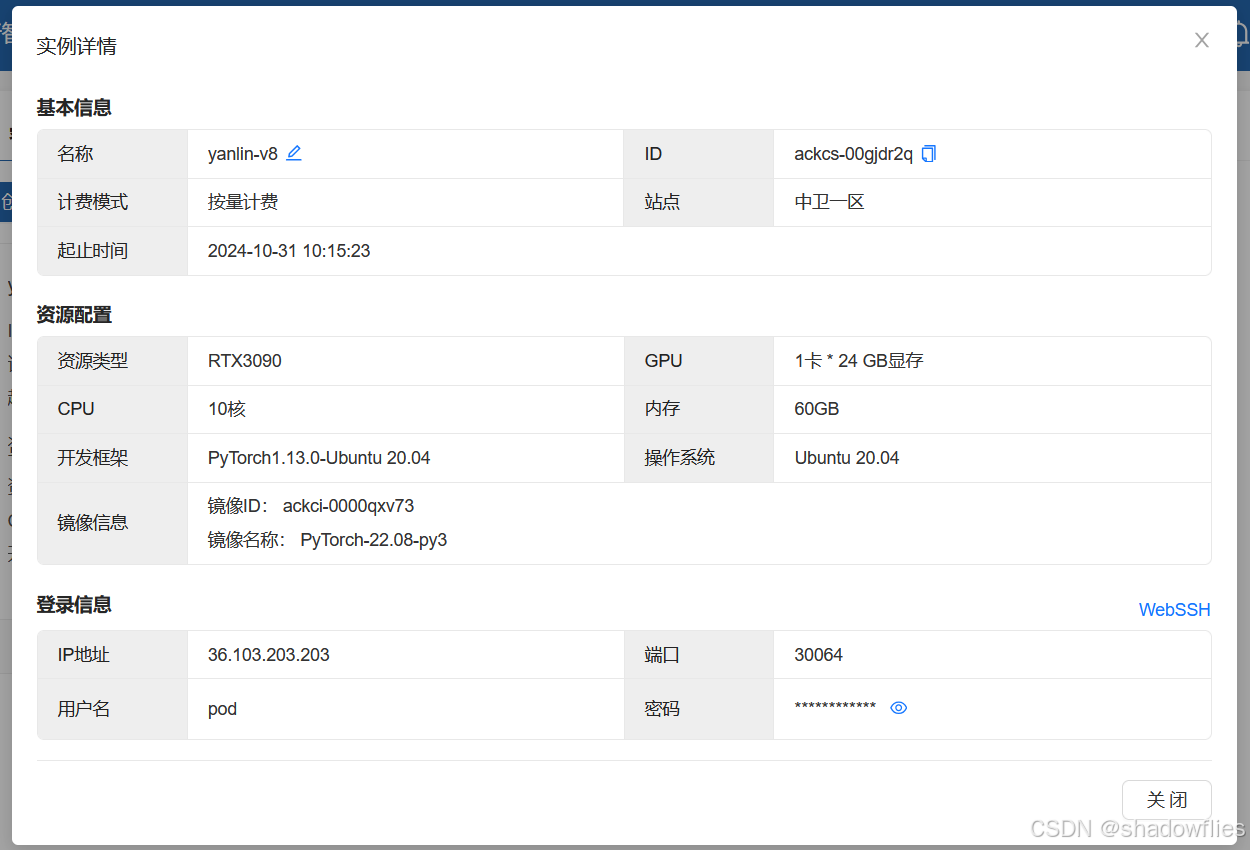
ssh的话在线连接就行,vscode的话就配置端口,用户名,然后密码填写(两次,连接时一次,定位到文件夹又一次),密码在查看详情那里看

1.4 环境创建
连接后可以再vscode扩展那里安装个python(官方文档写,但是不知道有啥用)
然后可以自己创建环节,里面有conda配置
conda create --name 名字 python=3.9
1.5 其他
弄好后就可以终端自己安装配置了,然后解压的话是 unzip 文件名字
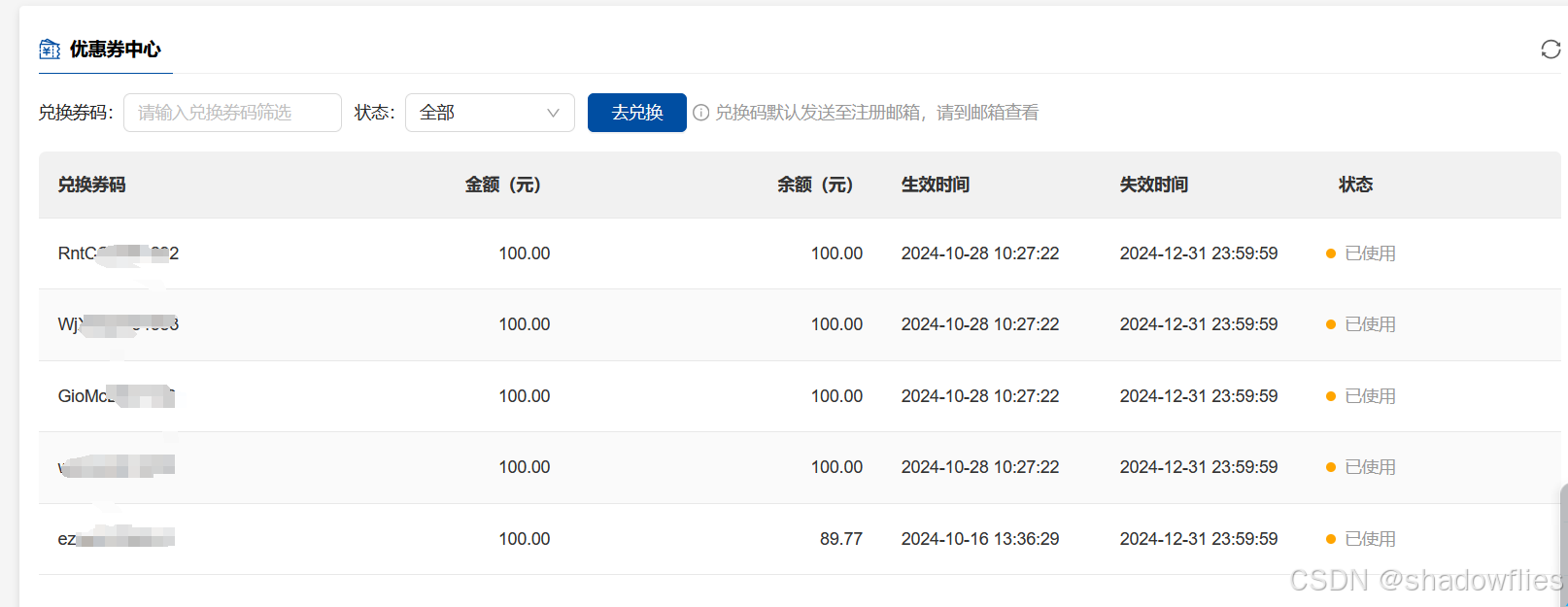
2 并行智算云获取
2024.12,31前好像都可以ccf会员(我是学生),可以领5张100元券,可以兑换,会发到邮箱,非会员的话也可以

















 2014
2014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









