







本次课程设计课题为北美数据集可视化,数据来源为爱数科。数据集部分截图及字段说明如下:

图1. 1数据集部分截图
数据集字段名称解释如下:
图1.2 数据集字段名称
数据量:共4751条数据,包含30个字段
(1)首先使用Python查看数据是否存在空值,将数据导入Python中,使用pd读取数据,然后根据函数isnull().sum()计算数据的缺失值。代码如图2.1所示。
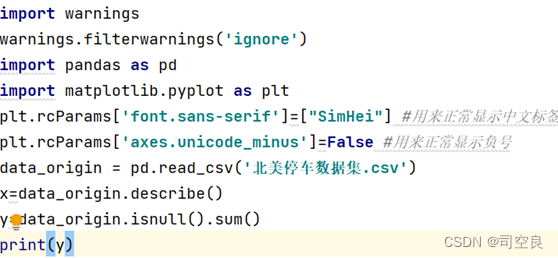
图2.1 计算空值的代码
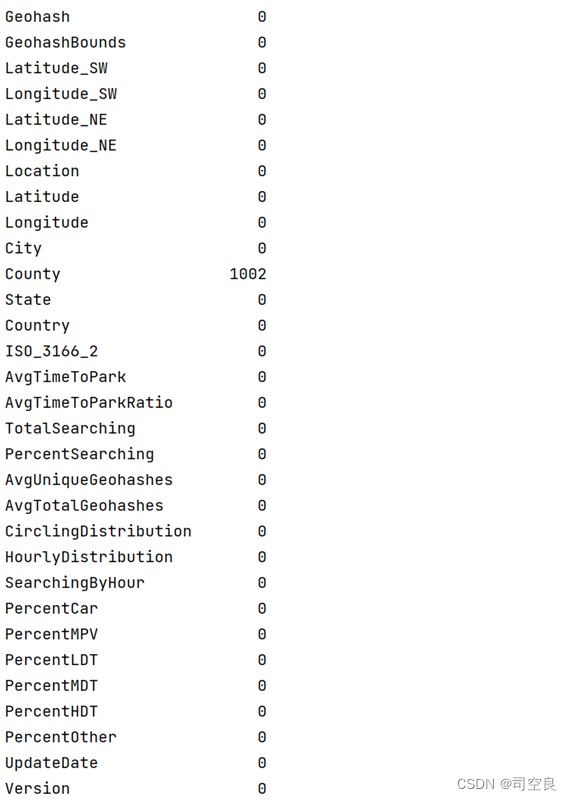
图2.2 存在空值的数据
(2)利用kettle将不需要的字段删除,使用计算器计算出北美洲各维度所有的车辆,通过Excel输出保存到F:\可视化大作业\北美数据集干净版,具体流程见图2—3所示。
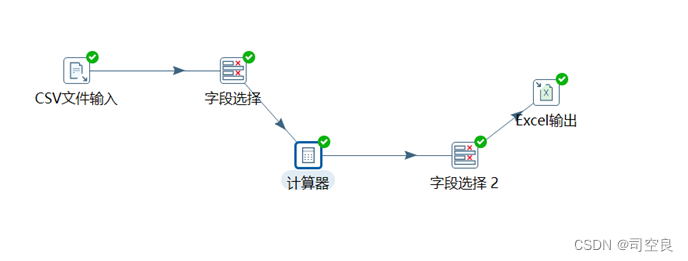
图2.3 kettle操作流程
(3)使用Excel表格中的内置函数将各种类型车难以停车的比例计算,结果为1的保留1,结果不为1的保留0,将计算结果保存到干净数据4.1csv文件中。处理后的数据如图2-4所示。
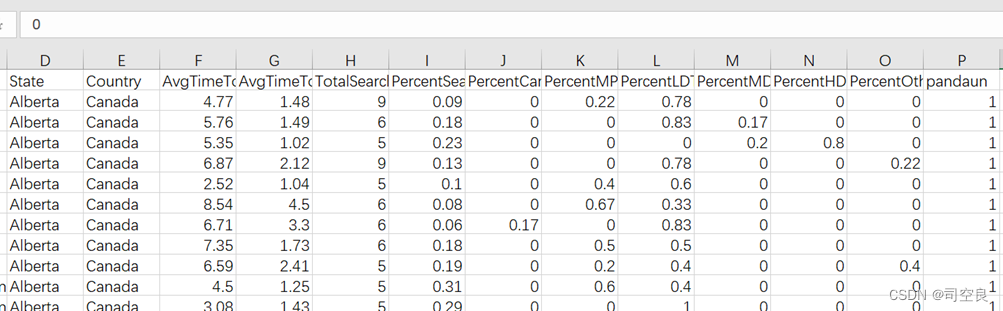
图2.4 干净数据4.1csv文件
(4)使用kettle软件将字段pandaun为1的结果保留,将字段为0的删除,剩余数据为3500条,同时通过Excel输出将文件保存到F:\可视化大作业\ile.xls中,具体操作流程如图2-5所示。
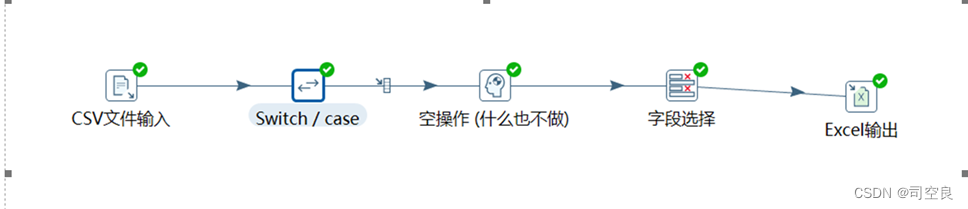
图2.5 kettle操作流程
(5)使用kettle软件,利用计算器分别计算出三个国家的在各个维度难以停车类型的数据,加拿大的数据保存在干净数据4.1csv中,美国的数据保存在美国数据.csv中,墨西哥的数据保存在墨西哥1.0csv中。具体操作流程如图2-6所示。
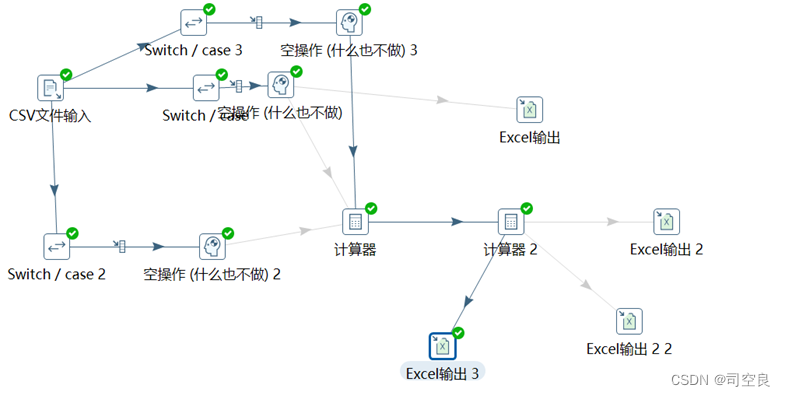
图2.6 kettle流程图
(6)使用Excel内置函数计算出三个国家各种类型难以停车的数量和。将计算结果保留在各个数据文件中。如图2-6所示
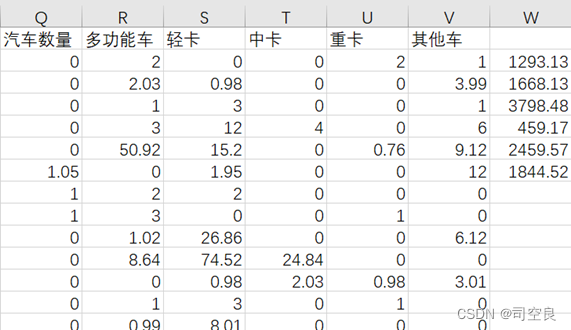
图2.7 美国数据.csv文件
三、数据分析及可视化
本次课程设计课题为北美数据集可视化,对北美洲难以停车的车辆类型进行分析,同时以经纬度对北美洲存在的车辆数目使用气泡图可视化,使用线性相关图查看各个字段是否存在相关关系,以及对北美洲三个国家的难以停车的车辆数目做条形可视化,分别查看三个国家最难以停车的类型,以及对北美洲三个国家所拥有的车辆使用环形图查看比例,对其中比例最大的国家进行进一步分析,对其各种难以停车的车辆类型使用经纬度进行地图可视化分析,使用k-mens聚类算法对经纬度分析,北美洲有三个国家所以类别为三,k-means 算法是首先从含有n个数据对象的数据集中随机选择K个数据对象作为初始中心。然后计算每个数据对象到各中心的距离,根据最近邻原则,所有数据对象将会被划分到离它最近的那个中心所代表的簇中。接着分别计算新生成的各个簇中数据对象的均值作为各簇新的中心,比较新的中心和上一次得到的中心,如果没有发生变化,则算法收敛,输出结果。
(1)以经纬度为横纵坐标将平均停车时间以散点图的形式展示出来,以此查看北美洲各个区域是否存在数据,代码如3-1所示:
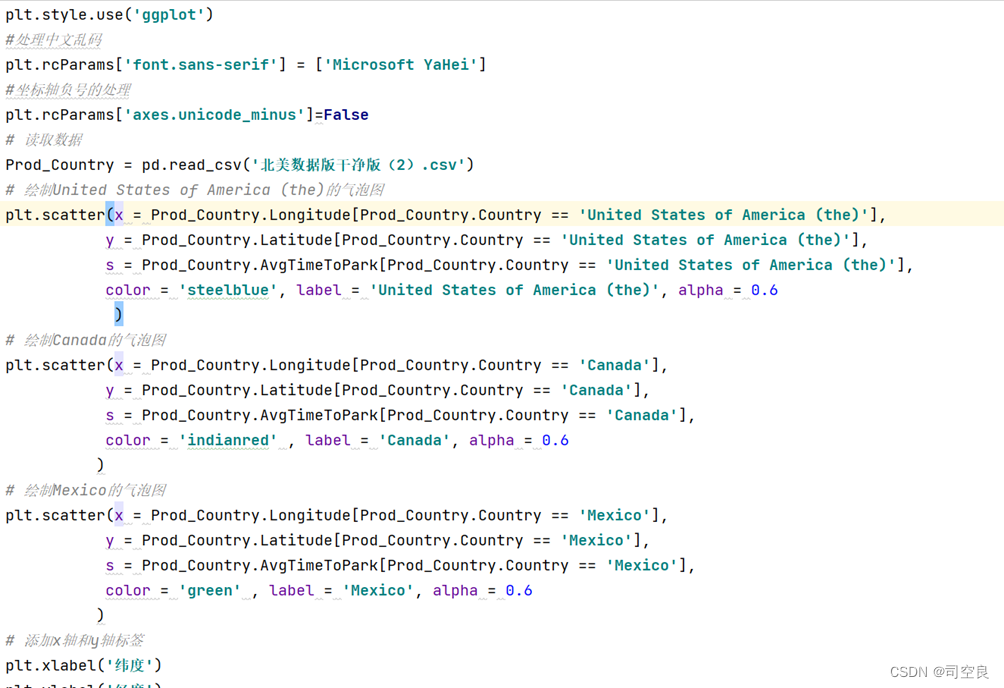
图3.1 平均停车时间气泡图代码
(2)对所有数据使用线性图查看存在的相关性,核心代码如3-2所示:
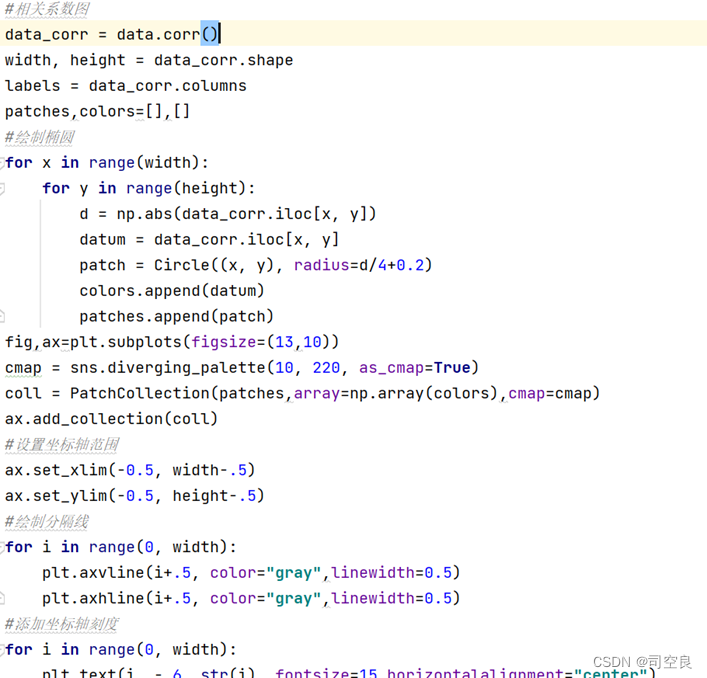
图3.2 线性关系图
(3)通过数据预处理我们得到北美洲三个国家目前拥有车辆的数量总和,对三个国家车辆的的数量做一个简单的环形图,进而查看其比例,核心代码如3-3所示:
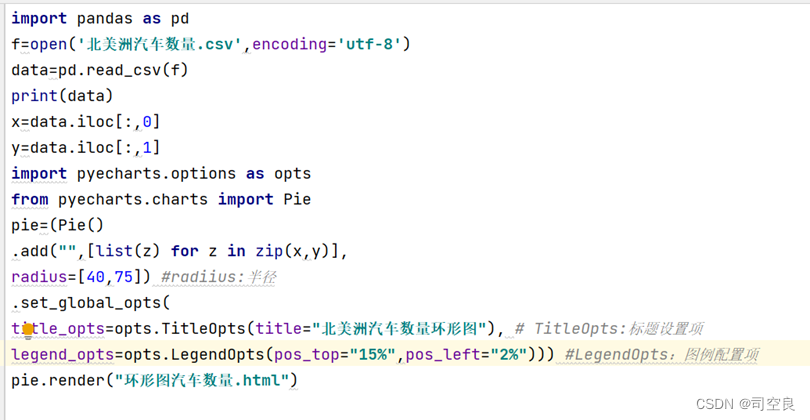
图3.3 汽车数量环形代码
(4)本文重点研究的是北美洲的停车困难问题,所以对其停车难的类型以及数量重点研究,所以使用条形图可以清晰明了的查看各个国家难以停车的种类和数量,核心代码如图3-4所示:
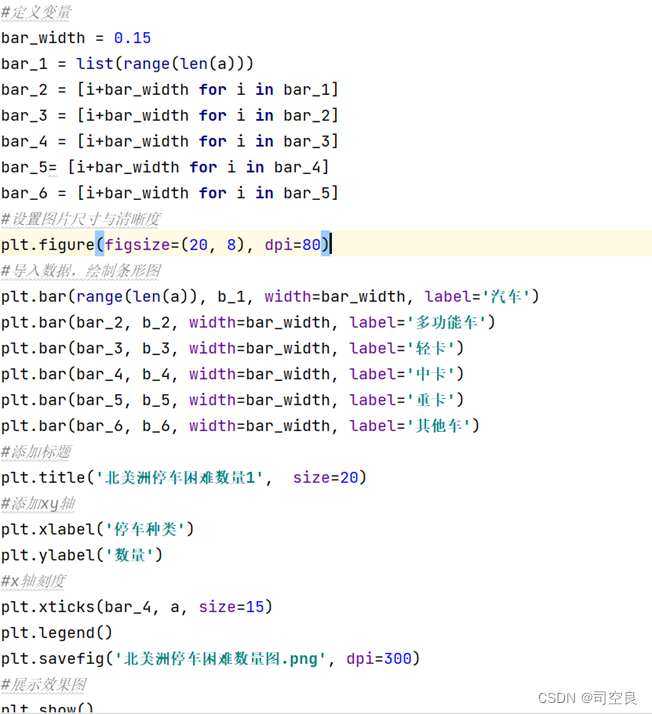
图3.4 条形图代码
(5)使用k-means算法对经纬度和汽车数量进行研究,将其分成三类,其中对数量最大的一类进行研究,核心代码如3-5所示:
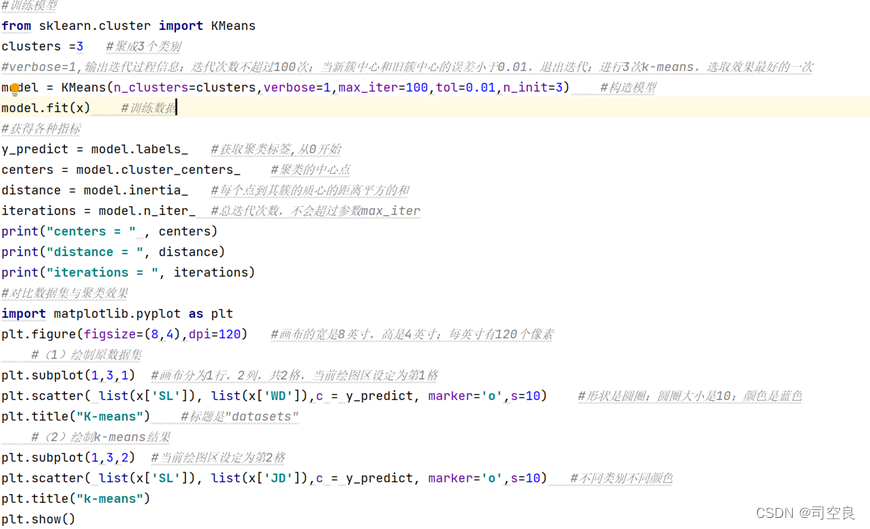
图3.5 k-means算法代码
(6)通过k-means算法将其分为三类,发现美国占比的权重远大于其他国家,所以对美国进一步研究,使用环形图查看美国各个难以停车车辆类型的数量及比重,核心代码如3-6所示:
图3.6 美国难以停车类型数量环形图代码
(7)对其难以停车类型的数量进一步分析,使用地图可视化查看美国难以停车车辆类型主要分布在哪一个地区,具体代码如3-7所示:
图3.7 地图可视化代码
可视化图表一:平均停车时间气泡图
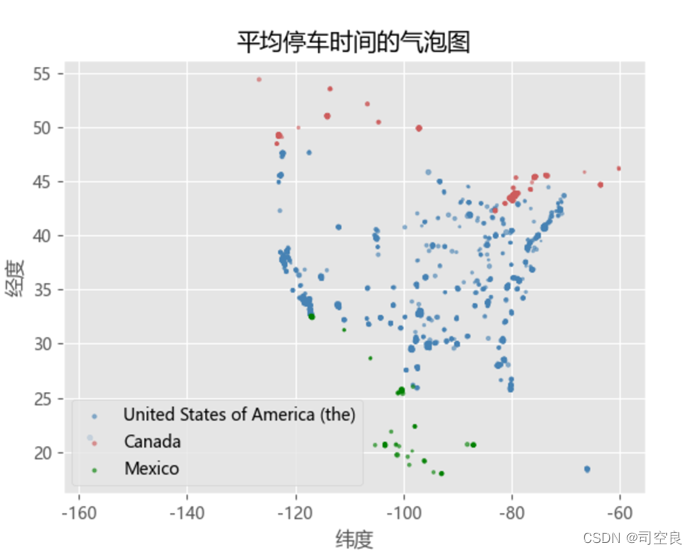
图3.8 平均停车时间气泡图
此图的目的并不是查看北美洲个地区平均停车时间,而是为了查看数据集对北美洲各个地区难以停车数据是否均有收集到,由图3.8可以明显的看出收集的数据集较为完整,涵盖了北美洲大部分地区,所以由此数据集得到的结论才会有一定的科学性、准确性和完整性。
可视化图表二:线性关系图
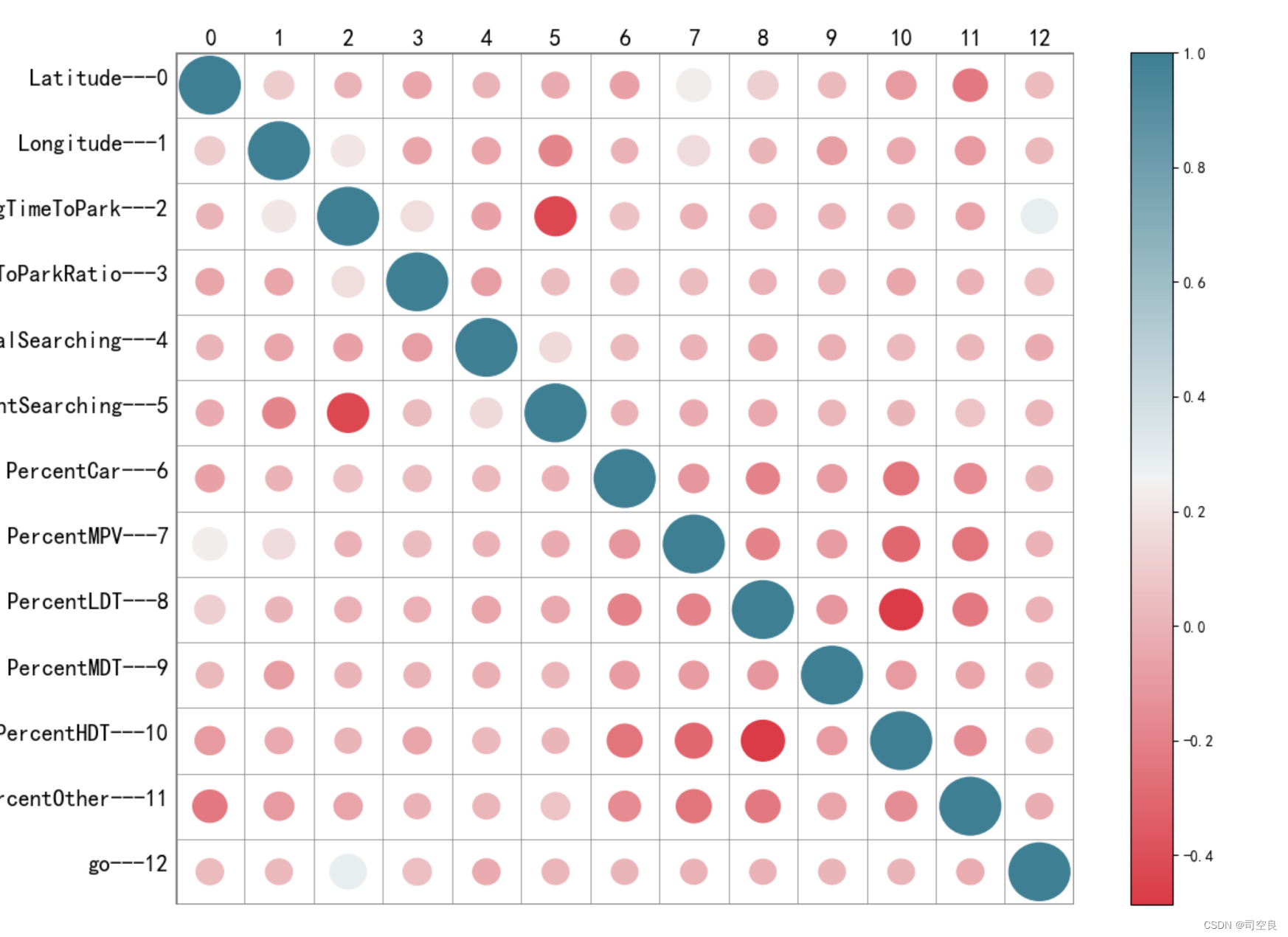
图3.9 线性关系图
对于得到的数据第一步不知道具体如何分析,可以查看其相关性,如有相关性则可以对其进一步分析得到结论,如图3.9所示,本数据集两两之间没有具体相关性,所以此图无法对本数据集提供更好的角度来进行分析以及下一步研究。
可视化图表三:汽车环形数量比例图
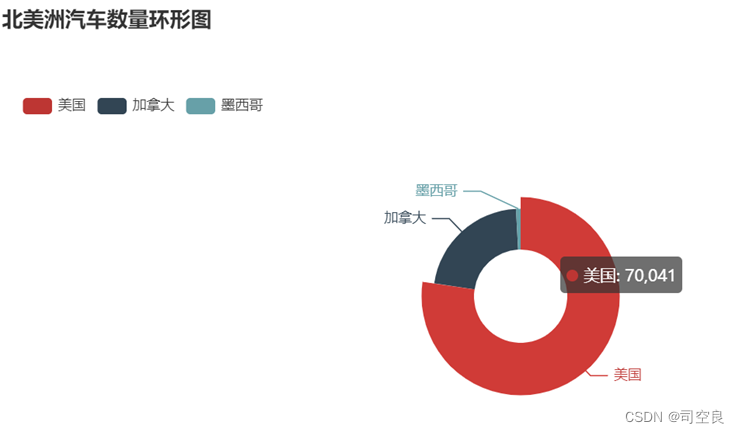
图3.10 汽车环形数量比例图
众所周知美国是世界上第一大经济体,是西方资本国家的领头羊,拥有3.3亿人口,人口数量排在世界第三位,加拿大人口数量为3800万人口,墨西哥为1.3亿,从图3.10可以明显的看出美国的汽车数量比墨西哥和加拿大汽车数量之和都要多出相当大的一部分,而墨西哥的人口数量远大于加拿大可其汽车数量在图3.10中却微乎其微,如果以此为依据,可以明显的看出墨西哥的经济实力远远低于其他两国,美国的实力在北美洲独冠(数据来源于www.dgchijin.com/16699.html)。
可视化图表四:北美洲停车困难数量图
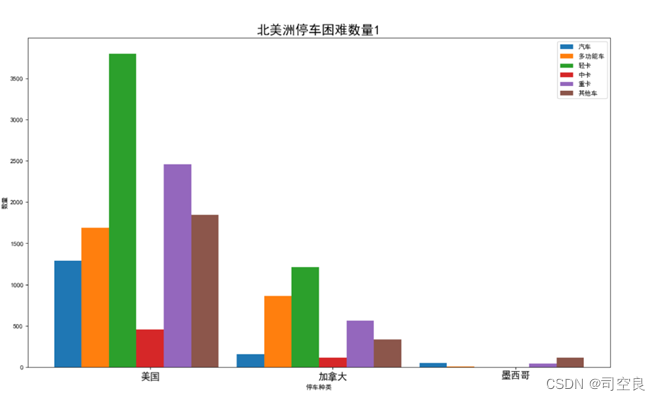
图3.11 北美洲停车困难数量条形图
由图3.11可以看出,墨西哥的数量属实少无法在条形图中表达其数据,而在美国和加拿大两国家难以停车的数量中都是轻卡的数量比其他类型车辆数量多一点,中卡比其他类型车辆数量少,轻卡使用主要集中在城市及其周边,以城市物流配送为主,而城镇化是拉动城市物流配送的长期根本性因素,据此可以看出美国和加拿大两个国家城镇化明显,同样的两个国家中卡难停车数量都是最少,主要是中卡的地位属实尴尬,一些重量级货物可以由重卡运输,轻量级货物则可以使用轻卡运输,导致其位置地位比不上轻卡和重卡。
可视化图表五:K-means算法聚类图
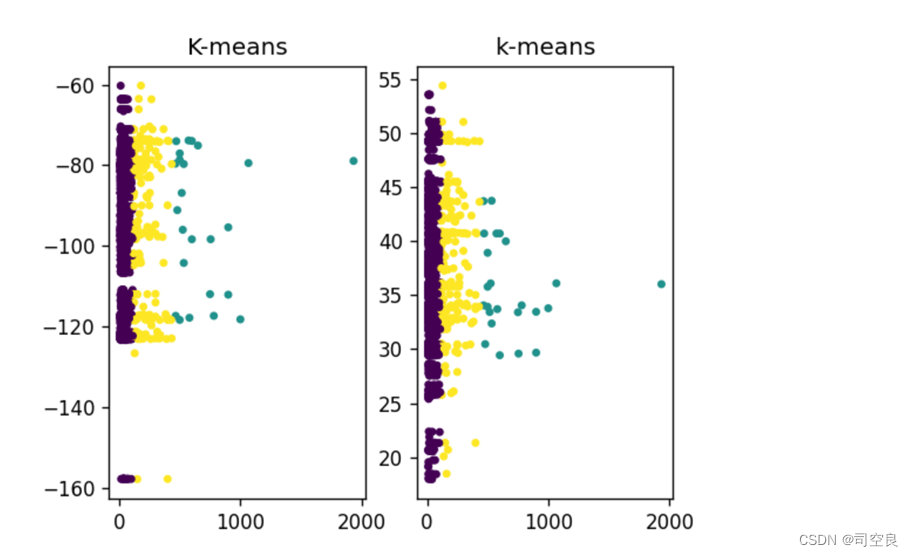
图3.12 K-means算法聚类图
由图3.12可知使用k-means算法将北美现有车辆数目聚类,将车辆数据聚为3类,我们可以明显的看出,k-means算法将车辆数量划分为低中高三等,最高等为绿色散点图,出现在经度-70到-120,纬度30到45之间,这一经纬度为美国的经纬度所在区间,选取数量大的基数进一步研究再进行仔细划分。
可视化图表六:美国难停车比例环形图
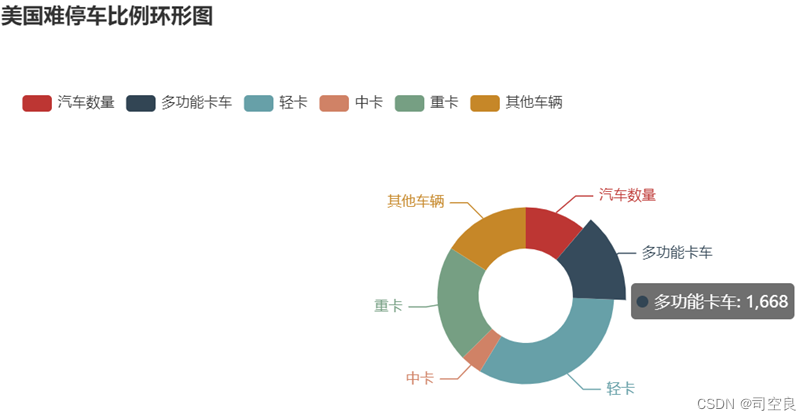
图3.13 美国难停车比例环形图
图3.13是美国地区难以停车种类数量的环形图,从图中我们可以看出轻卡占比最大,中卡占比最少,其他种类难以停车的数量相差无几,从而可以推断出美国是一个综合性大国,其没有明显的短板,轻卡难以停车说明其停车位置最少,所以需要适当的增加其停车位,但是美国的国土面积广阔,只是增加其轻卡停车位有一点过于轮廓,需要再进一步对其研究,增加停车位需要进一步精确,从而可以用最小的代价获得最大的利益。
可视化图表七:多功能车难以停车数量分布图
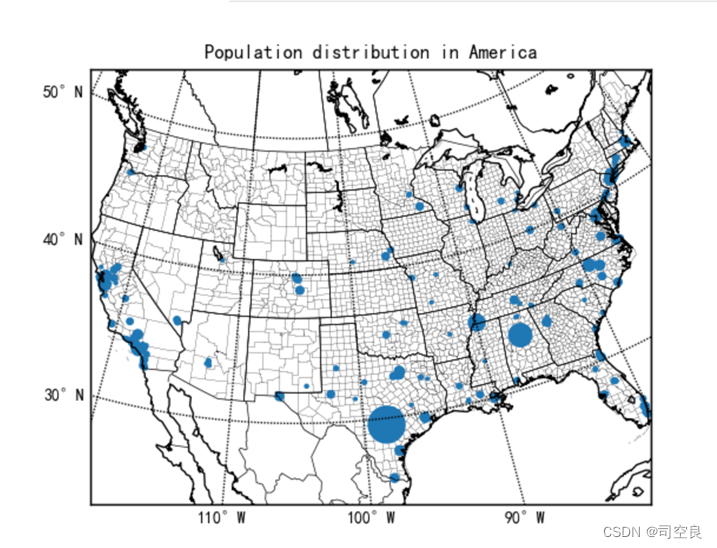
图3.14 多功能车难以停车数量分布图
对美国多功能车难以停车数量进一步研究我们发现,其分布具有明显的区域性,在美国的东西海岸线分布最广,其中西部的多功能汽车难以停车的位置偏南一点,东部则更为密集一点,整个海岸线均有分布,而在美国的南部则最明显,多功能难以停车的数量最多,所以综上所述建议可以在美国的南部可以多增加一些多功能汽车的停车位置,将其设为试点进一步推广研究,如果可以达到很好的效果则在全国范围内进一步推广。
可视化图表八:汽车难以停车数量分布图
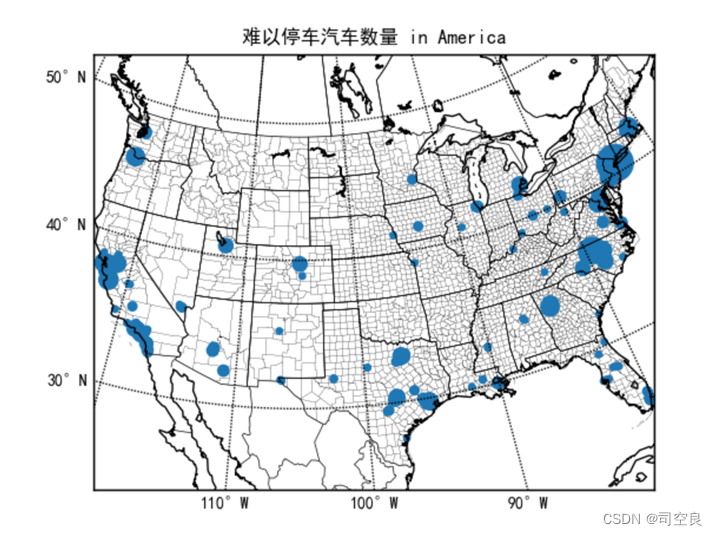
图3.15 汽车难以停车数量分布图
在美国几乎每个家庭都会有一辆车,而汽车难以停车数量越多说明当地的经济实力越雄厚或者是基础建设不够发达,从图3.15可以明显的看出,难以停车集中在美国的一些较为出名的大城市中,其中以美国的洛杉矶、华盛顿和纽约较为突出,这些地段属于寸土寸金的地方,修建大量停车位置显然有点不合经济效益,但是存在大量的汽车难以停放,会造成交通拥堵甚至更加可怕的交通事故发生,可以建议修建大量的地下车库,这些地方不缺少经济的支持,只是缺少空间,地下车库则可以更好的适应。
可视化图表九:轻卡难以停车数量分布图
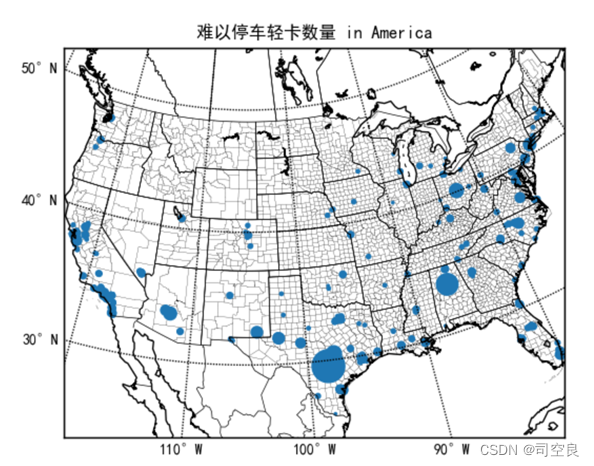
图3.16 轻卡难以停车数量分布图
轻卡的难以停车分布与多功能车的难以停车分布较为类似,都是主要集中分布在东海岸线以及西海岸线的南部,其中轻卡的难以停车分布数量最多的则是位于美国的南部,所以可以适当的增加其轻卡的停车位,如果轻卡难以停车数量得到减缓,则可以在全国范围内进行进一步推广。
可视化图标十:重卡难以停车数量分布图
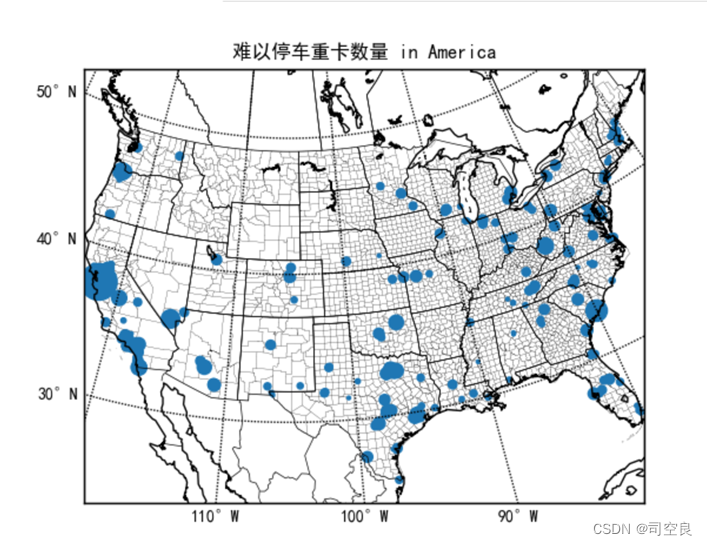
图3.17 重卡难以停车数量分布图
重卡难以停车分布在全国范围内普遍可谓遍地开花,这是因为其重卡的体积较大,相对于其他车辆难以停车,建造停车位的成本又高,其中重卡难以停车数量分布主要集中在加利福尼亚州,加利福尼亚州又是美国老牌工业强州,而重卡又是其主要运输工具,所以建议在加利福尼亚州建造大量的重卡停车位,铺助其它措施,吸引重卡车主前往加利福尼亚州,进而推动其经济建设。
可视化图标十一:中卡难以停车数量分布图
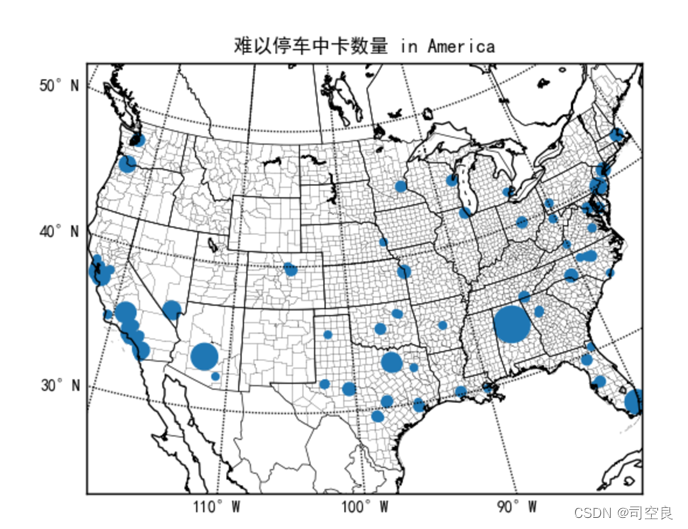
图3.18 中卡难以停车数量分布图
中卡的地位略尴尬与轻卡和重卡,但是其存在就合理,从全图范围来看,中卡难以停车数量最多的处于美国东南部的阿拉巴马州,阿拉巴马州(Alabama)是美国东南部的一个州,北与田纳西州接壤,东与佐治亚州接壤,南与佛罗里达州和墨西哥湾接壤,西与密西西比河接壤。长期以来,阿拉巴马州一直是工业化程度最高的城市之一,这也同时说明了该地区中卡难以停车的原因之一,建议在该地区加大中卡停车位的建设,持续发挥工业化优势,拉动经济的发展。
可视化图表十二:其他车难以停车数量分布图
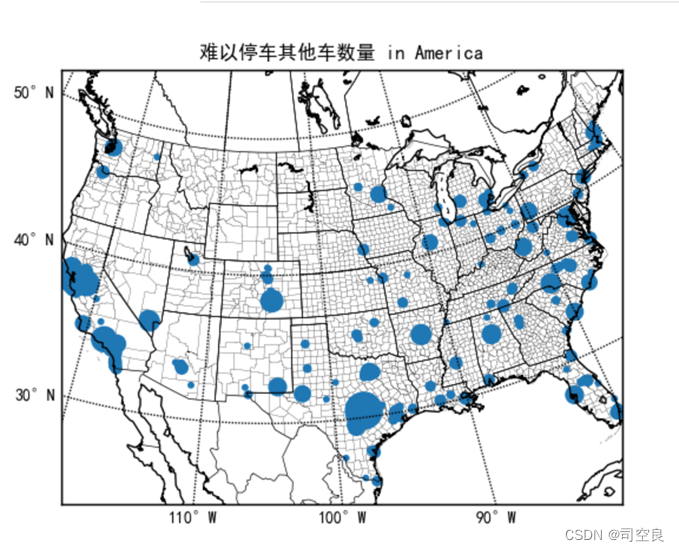
图3.19 其他车难以停车数量分布图
从图3.19可以看出其他车难以停车数量在美国地图上可谓遍地开花,其中加利福尼亚州、德克萨斯州以及东海岸线最为集中,可以选取东海岸线的佛罗里达州作为其他车辆难以停车的试点,加大其他车辆停车场的建设,同时密切关注其他地区的停车难问题,若弗罗里达州的停车问题得到改善,则可以进行下一步其他地区的建设。
四、技术难点及解决方案
问题一:在绘制条形图的时候单个条形图比较好绘制,但是复合型条形图却一直很难绘制,后一个数据框中的数据会不断覆盖前一个数据,数据效果得不到很好的展示。
解决方案:通过查询优快云得知,在绘制复合型条形图时需要设置多个条形绘图区和多个数据框,数据框和添加的数据要对应,同时数据框要与设置条形绘图区语句对应,否则后一个数据将前一个数据覆盖。
问题二:对k-means算法理解不够透彻,在使用k-means算法对数据集训练以及可视化中,代码一直不间断的报错。
解决方案:通过查询得知k-means算法(k-均值聚类算法)是一种基本的已知聚类类别数的划分算法,不同于分类算法的已知类别数据,属于无监督算法的一种。它是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。它是使用欧氏距离度量的(简单理解就是两点间直线距离,欧氏距离只是将这个距离定义更加规范化,扩展到N维而已)。它可以处理大数据集,且高效。它的输入自然是数据集和类别数。聚类结果是划分为k类的k个数据集。
五、待改进的问题
六、设计总结
本次课程设计是对北美停车数据集可视化分析,其中我选用的是k-means算法,因为数据集中没有明显的分类,所以使用k-means算法,可以通过聚类使数据集自动分类,在分类后我选择数据最高的为研究对象,同时借助地图可视化分析来对其具体研究同时提出建议,本次课程设计使我感受良多的是多门学科的交叉使用,我们收集到的第一手数据,很难直接使用进行可视化操作,需要用到数据清洗的各种方法和技术,尤其是数据清洗中kettle和excel的使用,对于数据的处理极大的方便了这次课设所需的数据处理。通过本次课设,也让我对于未来大数据分析即可视化有了简单处理的思路,在我看来初学者应该知难而上,不怕困难,每一次挫折都是我们未来的宝贵财富,当不断的面对困难直到战胜困难我们的收获不仅仅是克服了技术上的难关,更是为之后遇到再大的问题可以从容面对而不是逃避。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











