







搭建Hadoop集群
一、实验目的与要求
学习和掌握Hadoop的相关应用,首先必须得学会搭建Hadoop集群。本次实验将针对Hadoop集群的搭建内容进行演练。学会虚拟机的安装和克隆,Linux系统的网络配置和SSH配置,Hadoop集群的搭建和配置,Hadoop集群测试,熟悉Hadoop集群基本的操作。
要求:1、认真理解集群搭建过程,通过实践成功搭建Hadoop集群。
2、结合实践内容和教材的相关章节完成实验报告。
二、实验内容
1、虚拟机安装
2、虚拟机克隆
3、Linux系统网络配置
4、SSH服务配置
5、JDK安装
6、Hadoop安装
7、Hadoop集群配置
8、格式化文件系统
9、启动和关闭Hadoop集群
10、通过UI界面查看Hadoop运行状态
三、实验环境
虚拟机软件:VMware Workstation 14
操作系统:Center OS 6.9
终端仿真程序:SecureCRT 8.3
Java版本:jdk 1.8.0_161
Hadoop版本:Hadoop 2.7.4
- 实验过程记录
- 虚拟机安装
(1)、简易安装信息
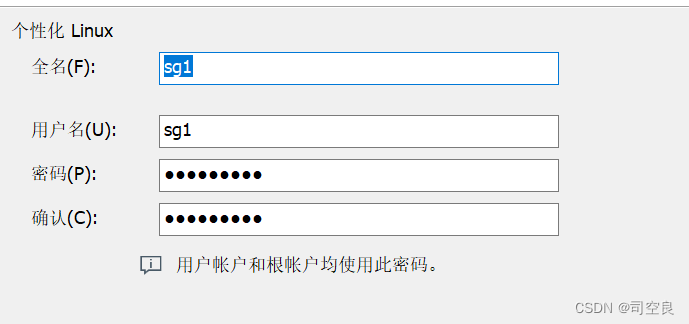
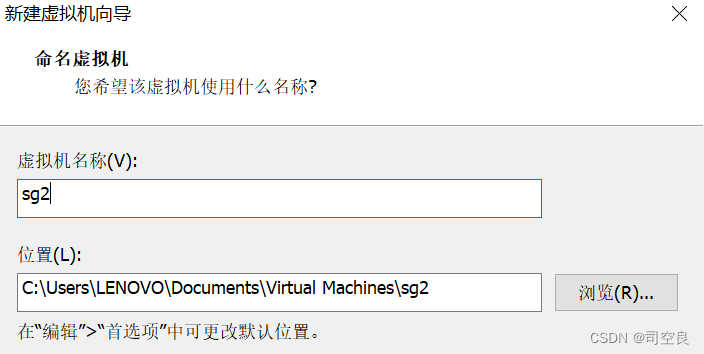
(2)虚拟机的安装命名
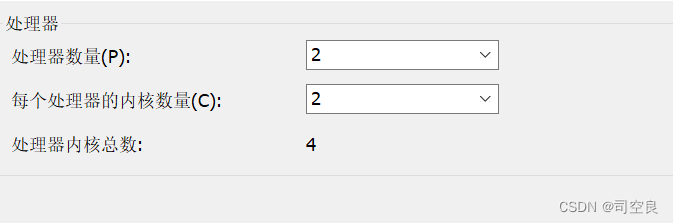
(3)处理器的配置
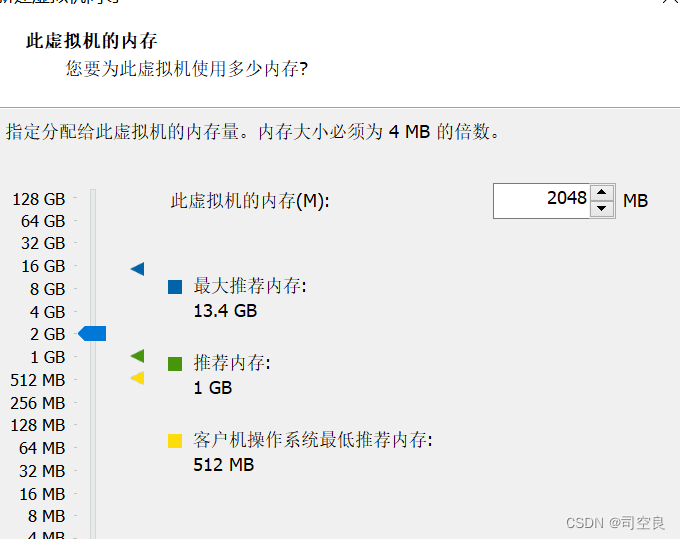
(4)内存大小的配置
(5)网络类型

(6)IO控制器

(7)虚拟磁盘类型
![]()
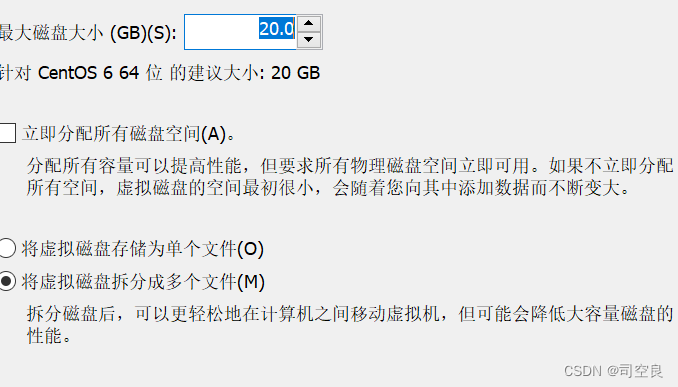
(8)磁盘容量
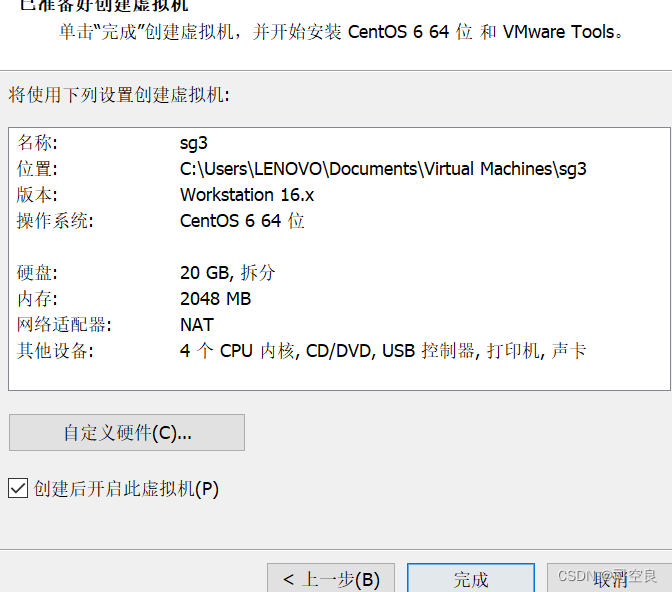
(9)完成创建
- 虚拟机克隆
- 克隆位置
- 克隆向导
- 克隆源
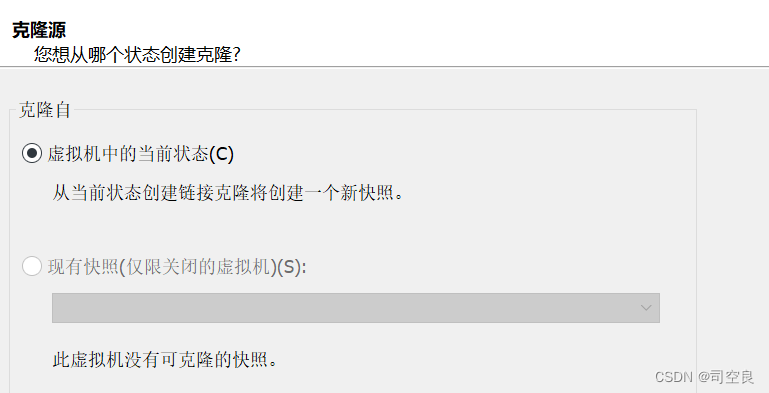
- 克隆类型

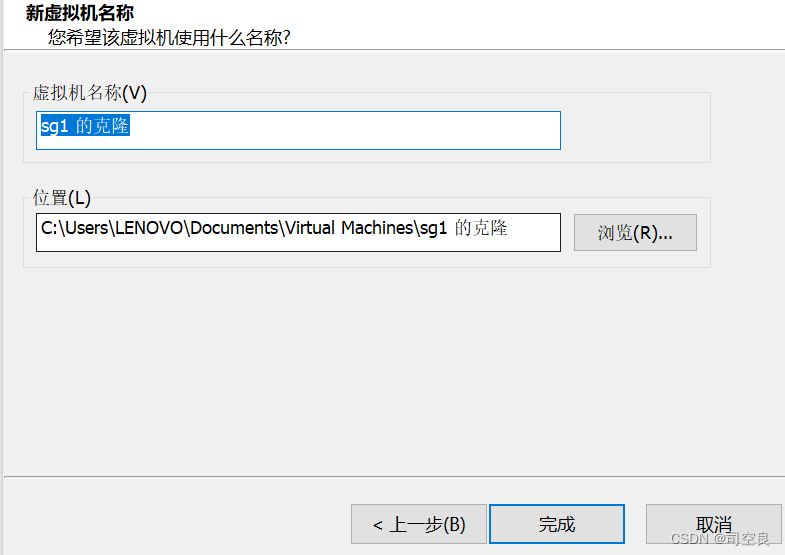
- 新虚拟机名字,完成克隆
- Linux系统网络配置
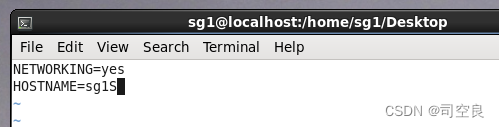
- 配置主机名
![]()
- 对HOSTNAME选项重新编辑
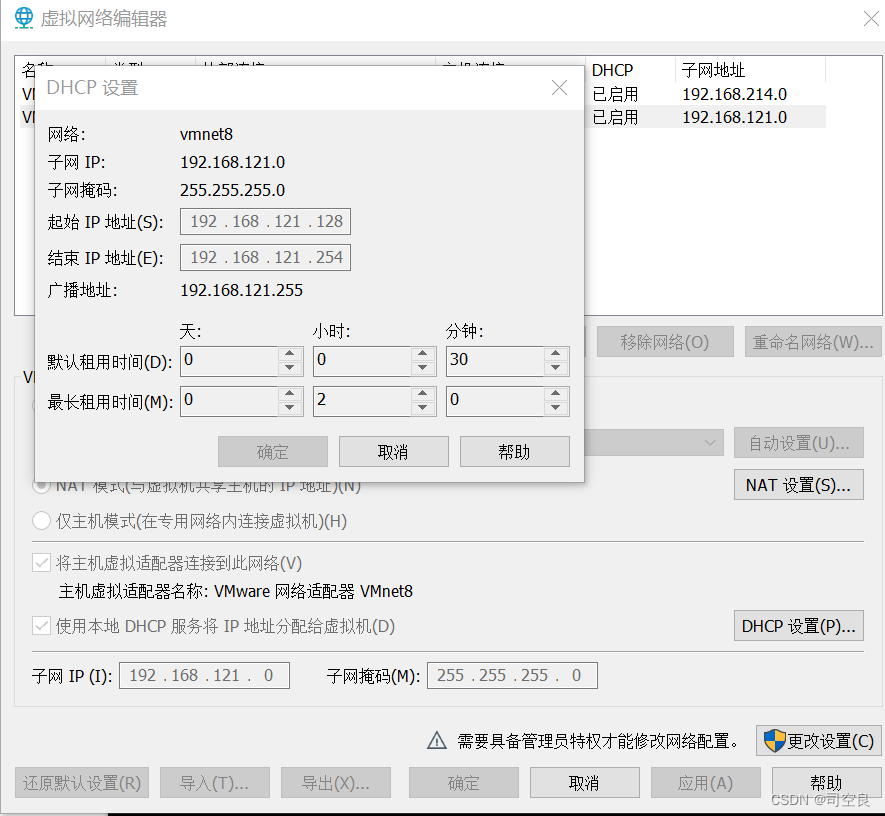
- 配置IP映射
- 选择编辑菜单下的虚拟网络编辑,打开虚拟网络编辑器,选中NAT模式下的VMnet8,单击DHCP设置出现窗口
- 对hosts进行编辑,进行IP映射
![]()
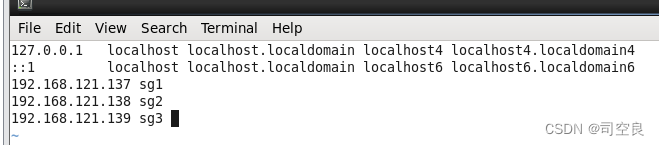
- 网络参数配置
- 修改虚拟机网卡配置文件,具体命令如下

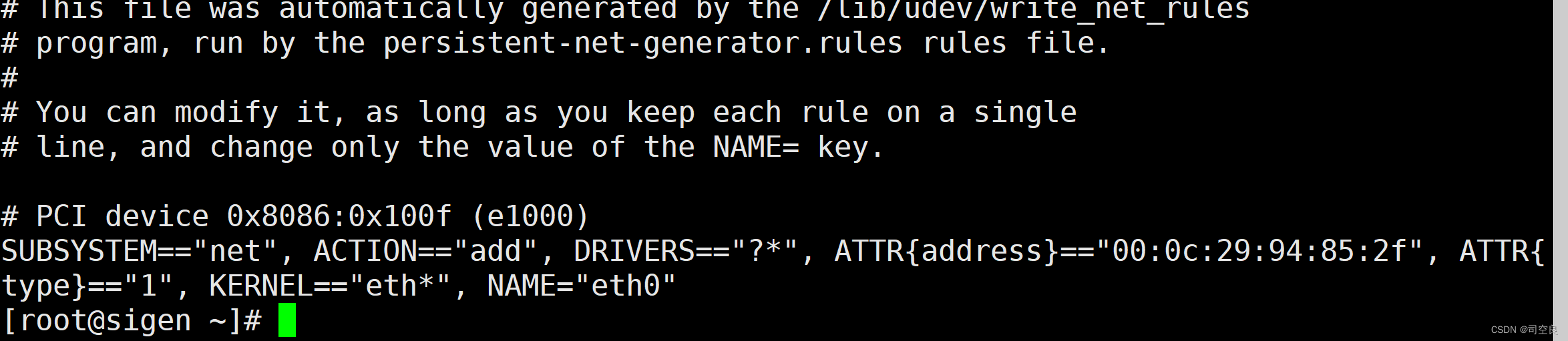
网卡配置
- 修改IP地址文件,设置静态IP,命令如下

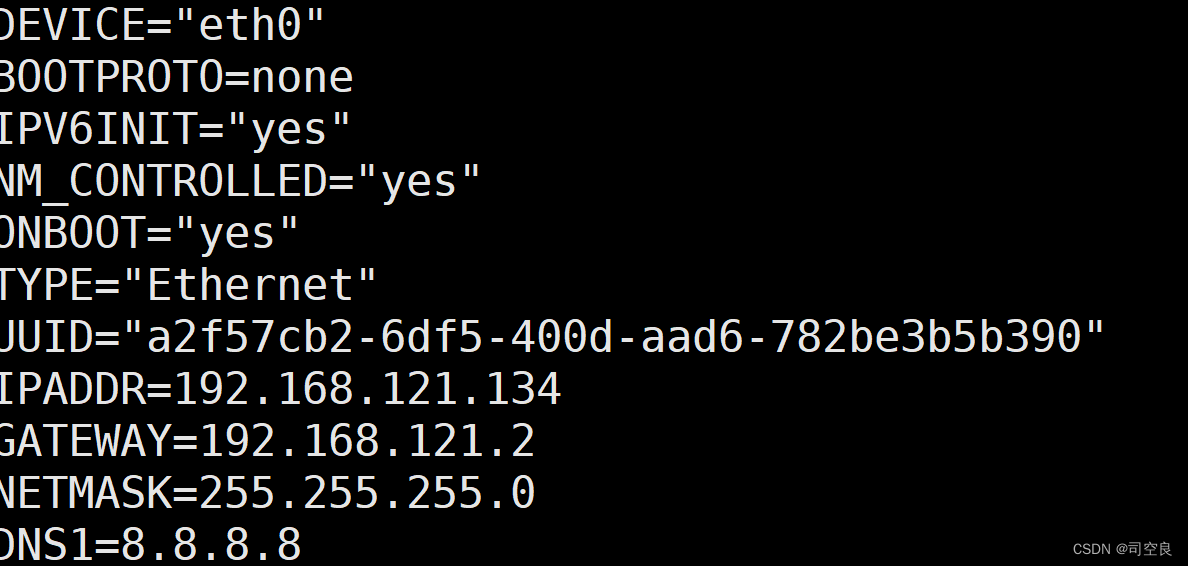
IP地址配置
- 配置效果验证
- 系统重启,通过ifconfig指令查看IP配置是否生效
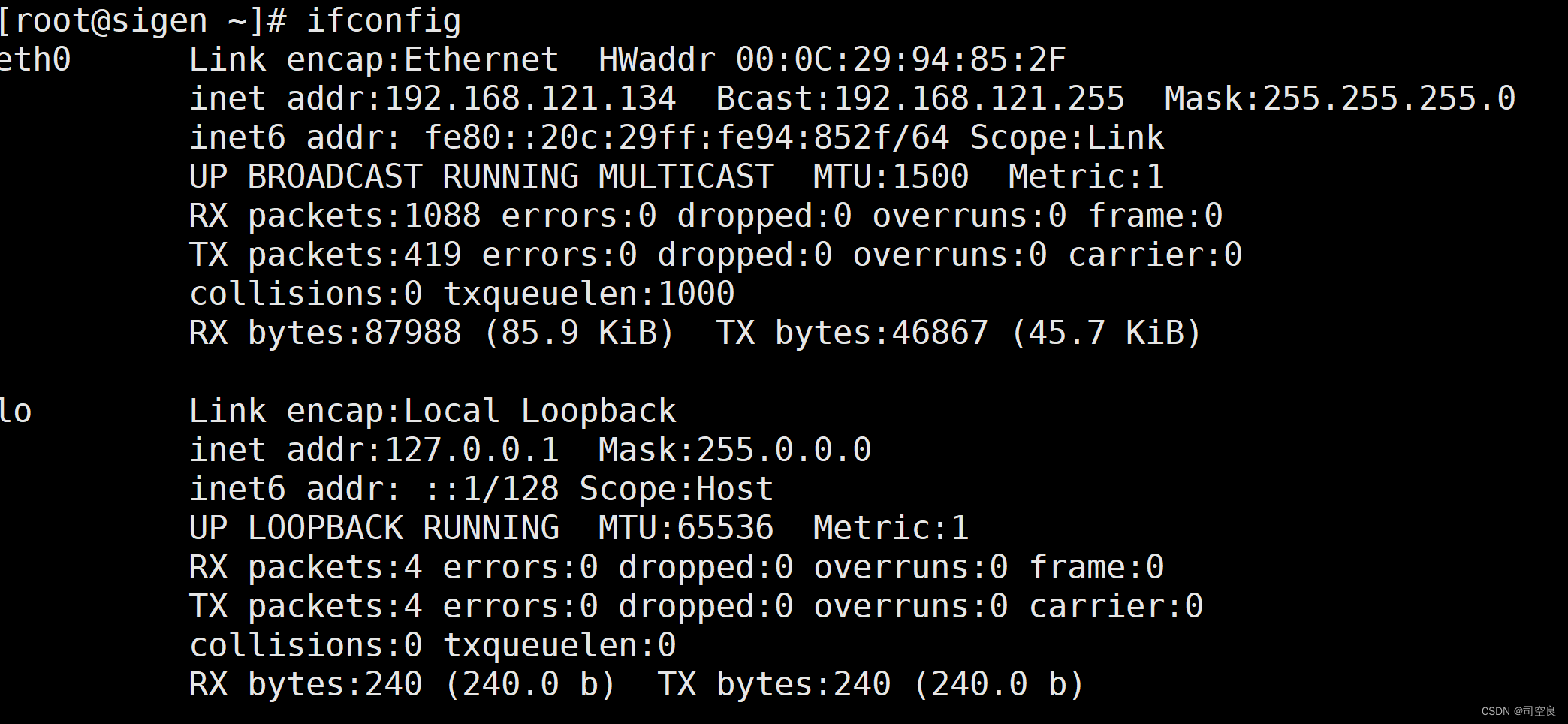
- 检查网络连接是否正常

- 重命名Centos6默认的yum源文件
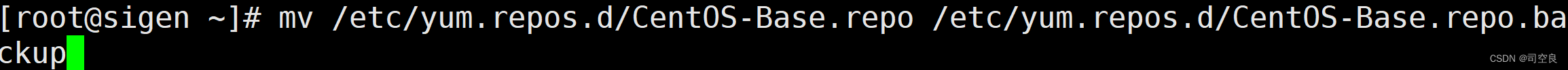
- 创建yum源文件Centos-Base.repo

- 将官方yum源更改为valut的yum源

- SSH服务配置
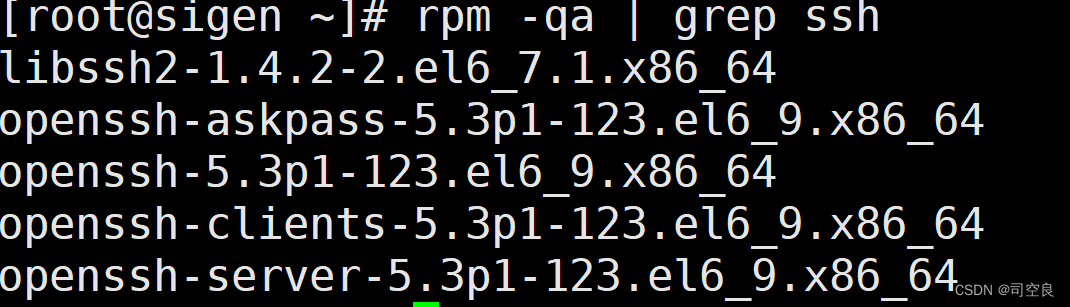
- 使用rpm -qa | grep ssh 命令查看当前是否安装ssh服务
- 使用ps -e | grep sshd 查看ssh服务是否启动

- JDK安装
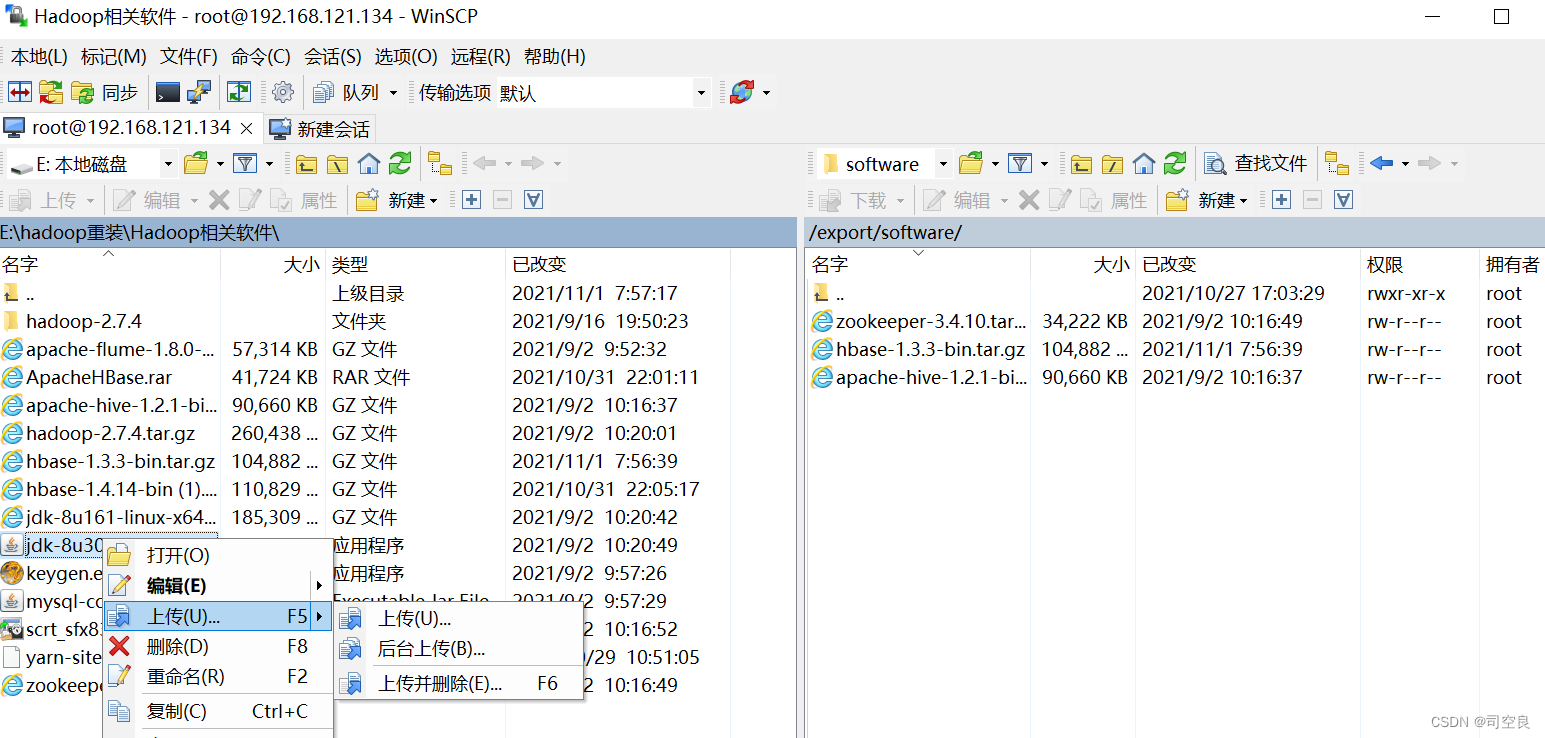
- 下载jdk安装包并且上传到/export/software/目录下
- 将安装包解压到/export/servers/目录下,具体指令如下
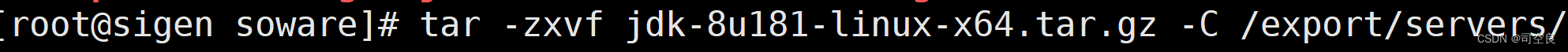
- 配置jdk环境变量

使用source /etc/profile,刷新使配置文件生效
- jdk环境验证

- Hadoop安装
- 先下载好hadoop安装包,上传到/export/soware/目录
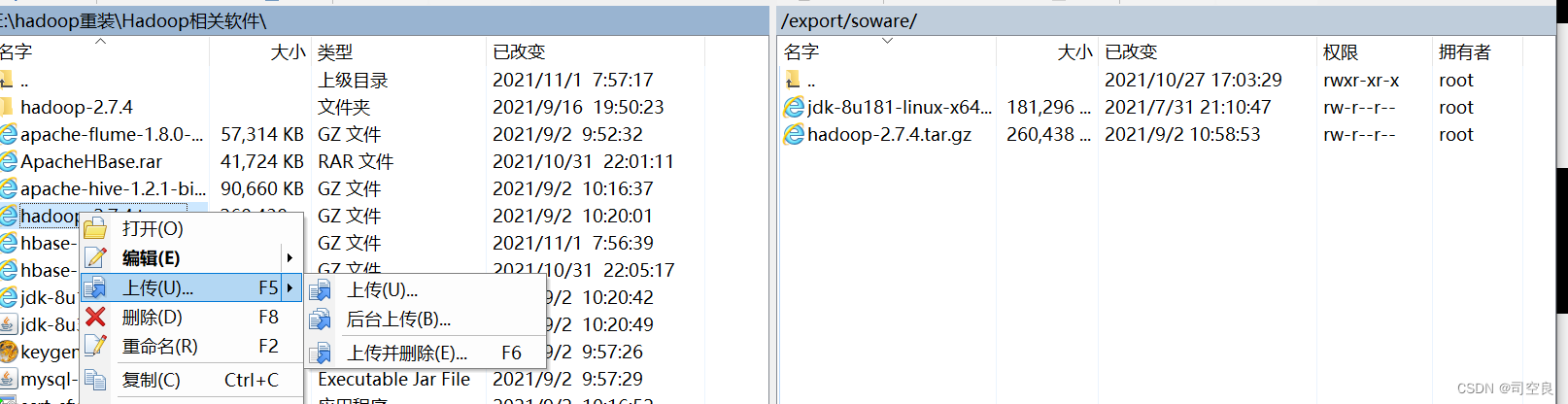
- 解压

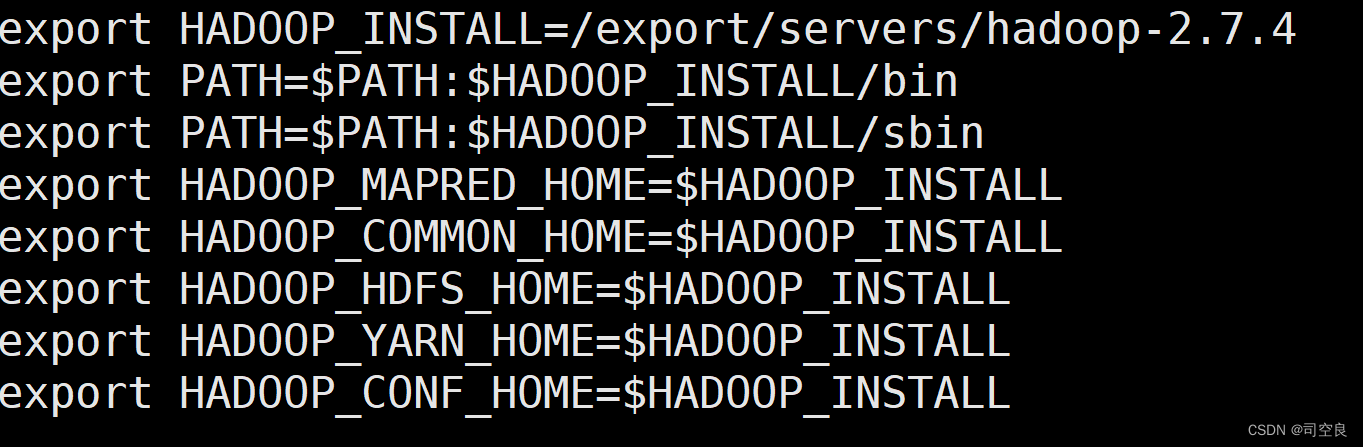
- 添加hadoop环境变量,随后使用source /etc/profile命令使配置文件生效
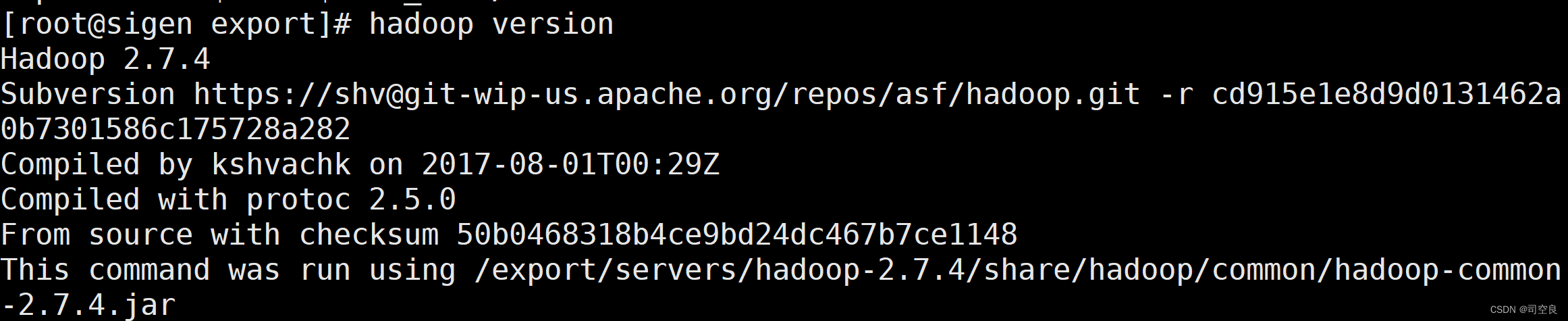
- 可以使用hadoop version查看版本号,演示如下:
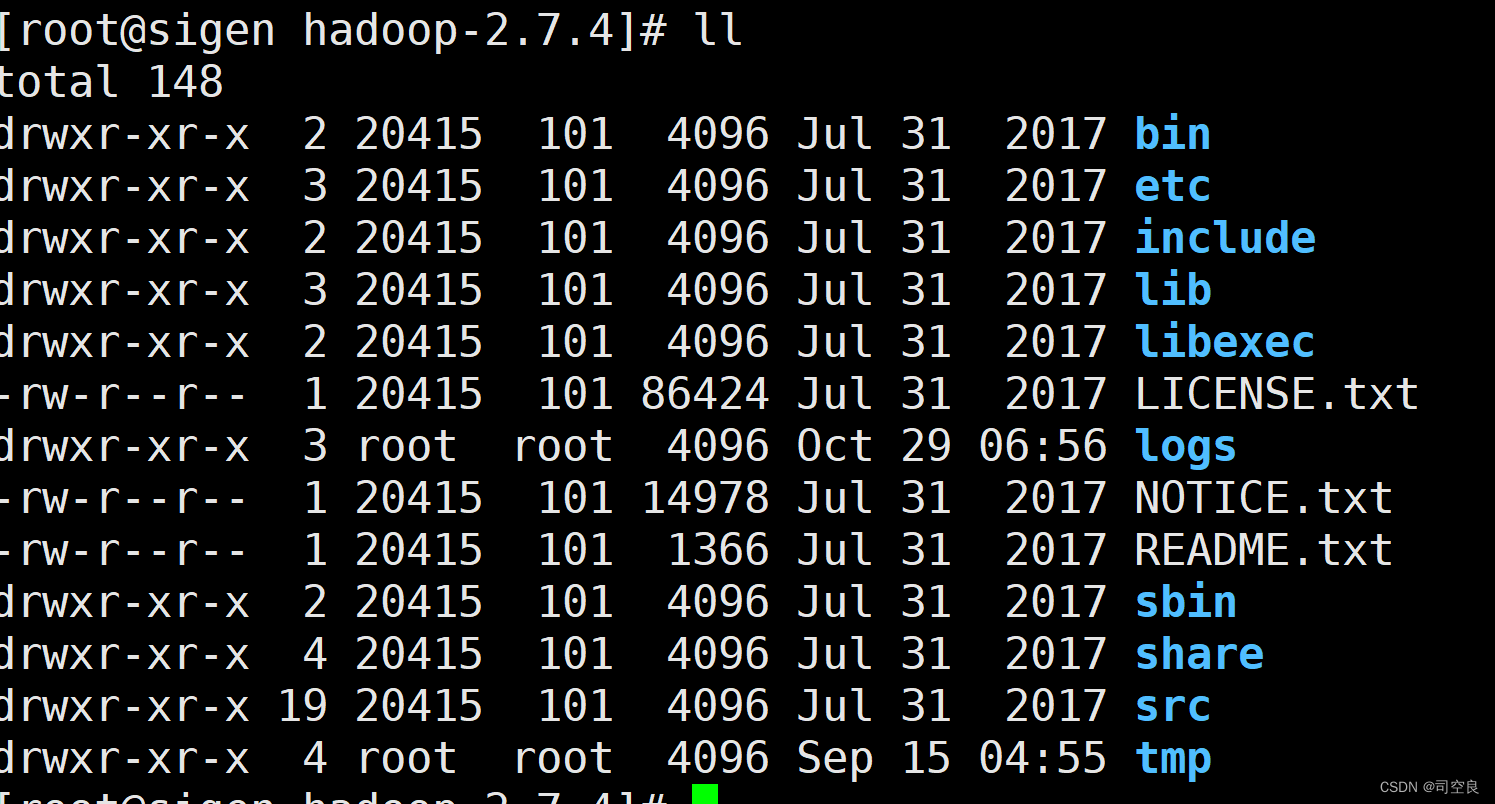
- 查看hadoop的目录结构
- Hadoop集群配置
- 配置hadoop集群主节点
- 修改hadoop-env.sh文件

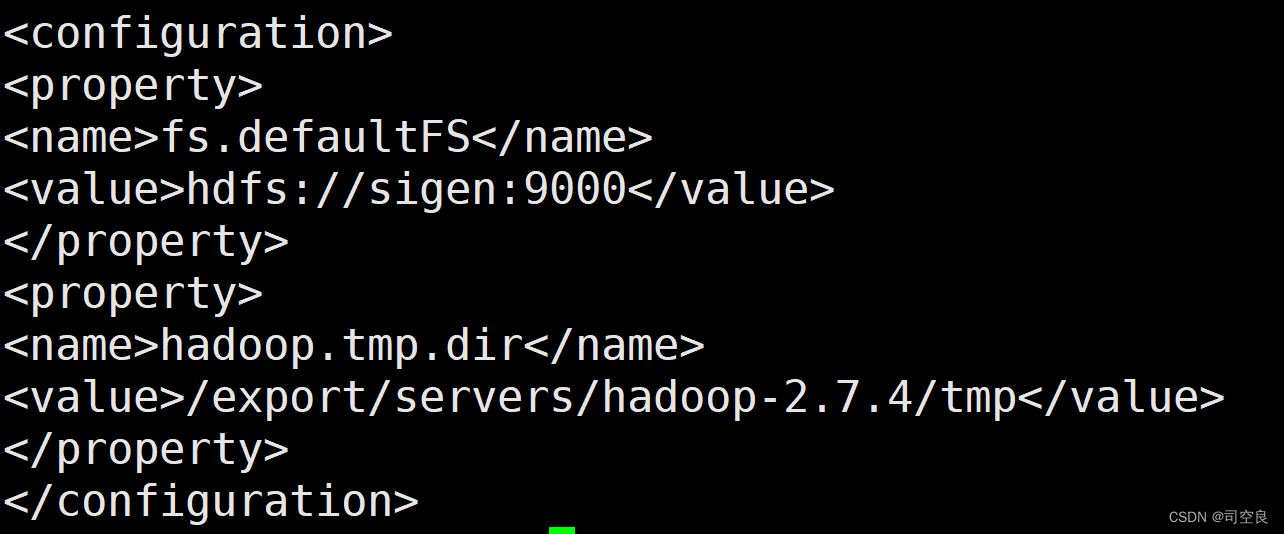
- 修改core-site.xml文件
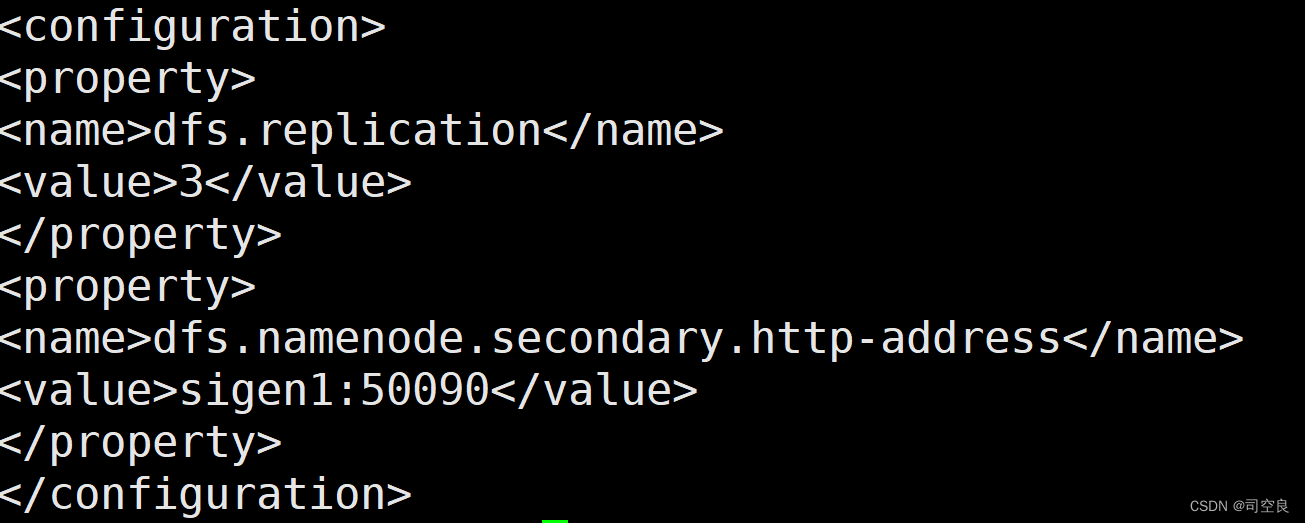
- 修改hdfs-site.xml
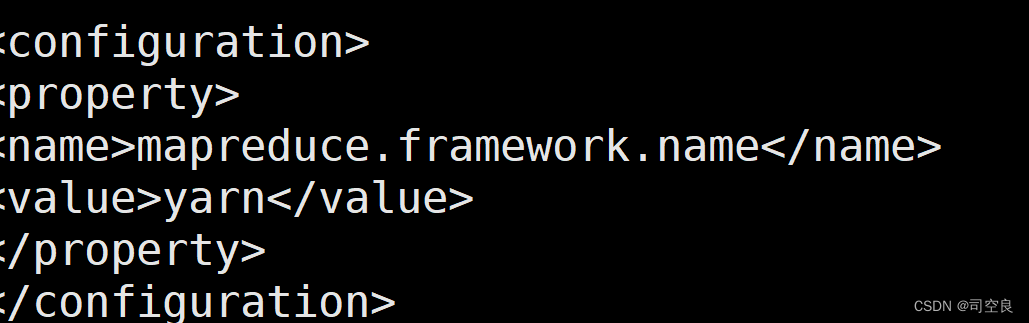
4)修改mpred-site.xml文件
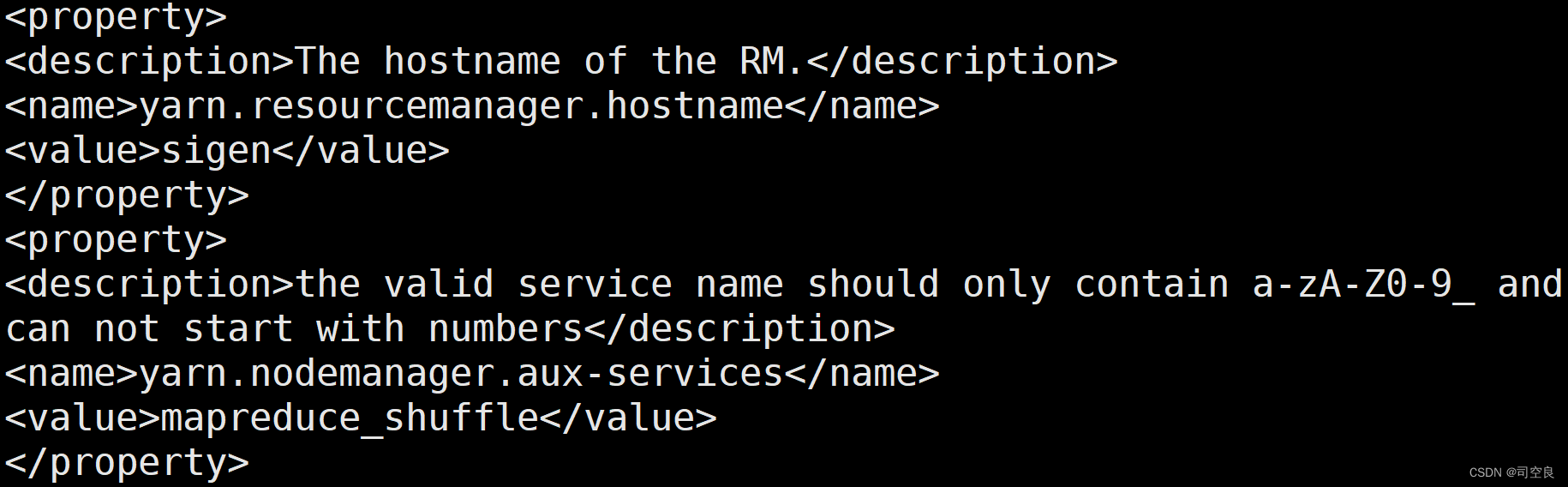
5)修改yarn-site.xml文件
6)修改slaves文件

- 将集群主节点的配置文件分发到其他的子节点,具体命令如下:
1)将环境变量发送给其他两台虚拟机
Scp /etc/profile sigen1:/etc/profile
Scp /etc/profile sigen2:/etc/profile
2)将hadoop的安装目录发送到其他俩虚拟机
Scp -r /export/servers/Hadoop-2.7.4 sigen1:/export/servers
Scp -r /export/servers/Hadoop-2.7.4 sigen2:/export/servers
3)使环境配置生效
Source /etc/profile
- 格式化文件系统
- 初次启动hdfs集群时必须对主节点进行格式化处理,具体指令如下
Hdfs namenode -format 或者 Hadoop namenode -format
- 必须出现successfully formatted信息才表示格式化成功

- 启动和关闭Hadoop集群
- 单节点逐个启动和关闭
- 启动namenode进程

- 启动datenode进程
- 启动yarn ResourceManger进程

- 启动yarn nodemanger进程

5)启动SecondaryNameNode
 (2)脚本一键启动和关闭
(2)脚本一键启动和关闭
- 启动hdfs服务进程
- 启动yarn服务进程

3)通过jps查看进程启动情况
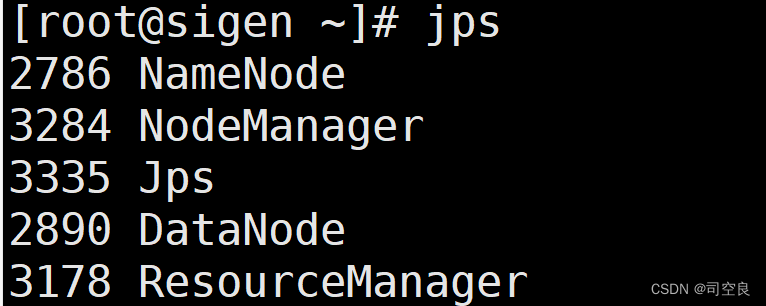
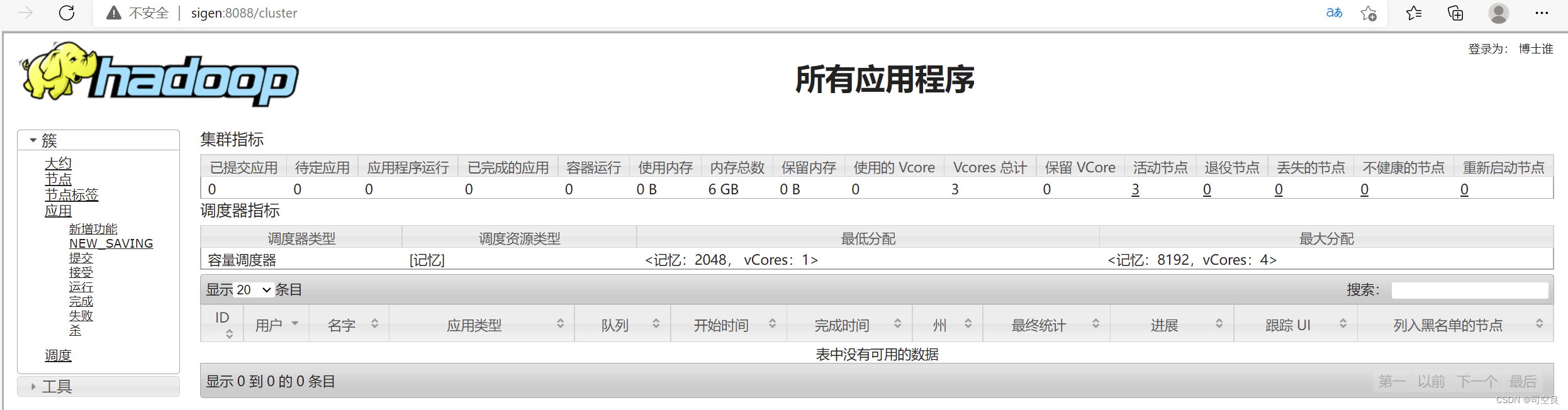
10、通过UI界面查看Hadoop运行状态
(1)yarn的ui
- hdfs的ui

五、问题及解决办法
问题一:环境变量配置好后,运行不出想要的结果
解决办法:查询课本发现,在环境变量配置好了之后需要用source刷新一下
六、实验总结
通过本次实验,学习和掌握Hadoop的相关应用,首先必须得学会搭建Hadoop集群。本次实验将针对Hadoop集群的搭建内容进行演练。学会虚拟机的安装和克隆,Linux系统的网络配置和SSH配置,Hadoop集群的搭建和配置,Hadoop集群测试,熟悉Hadoop集群基本的操作,对于hadoop的一些相关操作的运用更加得心应手,同时对于自我独立解决问题的能力得到了提高。



















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











