







HJ101 输入整型数组和排序标识,对其元素按照升序或降序进行排序
描述
输入整型数组和排序标识,对其元素按照升序或降序进行排序
数据范围: 1≤n≤1000 ,元素大小满足 0≤val≤100000
输入描述:
第一行输入数组元素个数
第二行输入待排序的数组,每个数用空格隔开
第三行输入一个整数0或1。0代表升序排序,1代表降序排序
输出描述:
输出排好序的数字
方法一:数组法
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
//数组法
//升序排序或降序排序的函数接口
void Ascending_Descending_Sorting(int num)
{
int number; //输入整数
int pIntegerArray[num]; //存储整数的数组
int iSortFlag; //排序标识
for (int i = 0; i < num; i++)
{
cin >> number;
pIntegerArray[i] = number;
}
cin >> iSortFlag;
//数组的元素排序(从小到大)
sort(pIntegerArray, pIntegerArray + num);
//排序标识为 0,顺序输出
if (iSortFlag == 0)
{
for (int i = 0; i < num; i++)
{
cout << pIntegerArray[i] << ' ';
}
cout << endl;
}
//排序标识为 1,逆序输出
else if (iSortFlag == 1)
{
for (int i = num - 1; i >= 0; i--)
{
cout << pIntegerArray[i] << ' ';
}
cout << endl;
}
return;
}
//主函数
int main()
{
int num;
while (cin >> num)
{
Ascending_Descending_Sorting(num);
}
return 0;
}方法二:向量法
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
//向量法
//升序排序或降序排序的函数接口
void Ascending_Descending_Sorting(int num)
{
int number; //输入整数
vector <int> vec; //存储整数的向量
int iSortFlag; //排序标识:0 表示按升序,1 表示按降序
for (int i = 0; i < num; i++)
{
cin >> number;
vec.push_back(number);
}
cin >> iSortFlag;
//向量的元素排序(从小到大)
sort(vec.begin(), vec.end());
//排序标识为 0,顺序输出
if (iSortFlag == 0)
{
for (int i = 0; i < num; i++)
{
cout << vec[i] << ' ';
}
cout << endl;
}
//排序标识为 1,逆序输出
else if (iSortFlag == 1)
{
for (int i = num - 1; i >= 0; i--)
{
cout << vec[i] << ' ';
}
cout << endl;
}
return;
}
//主函数
int main()
{
int num;
while (cin >> num)
{
Ascending_Descending_Sorting(num);
}
return 0;
}HJ102 字符统计
描述
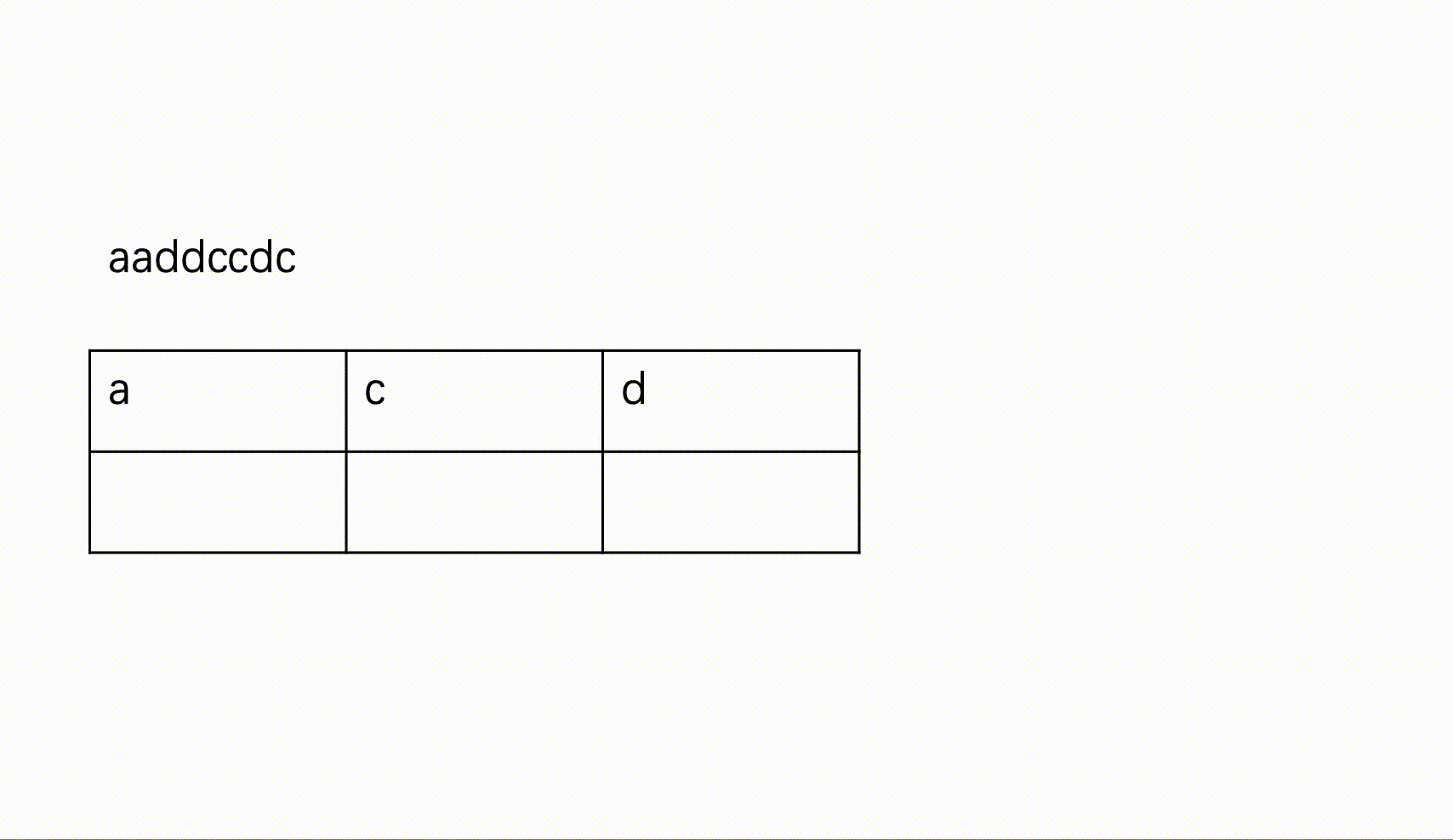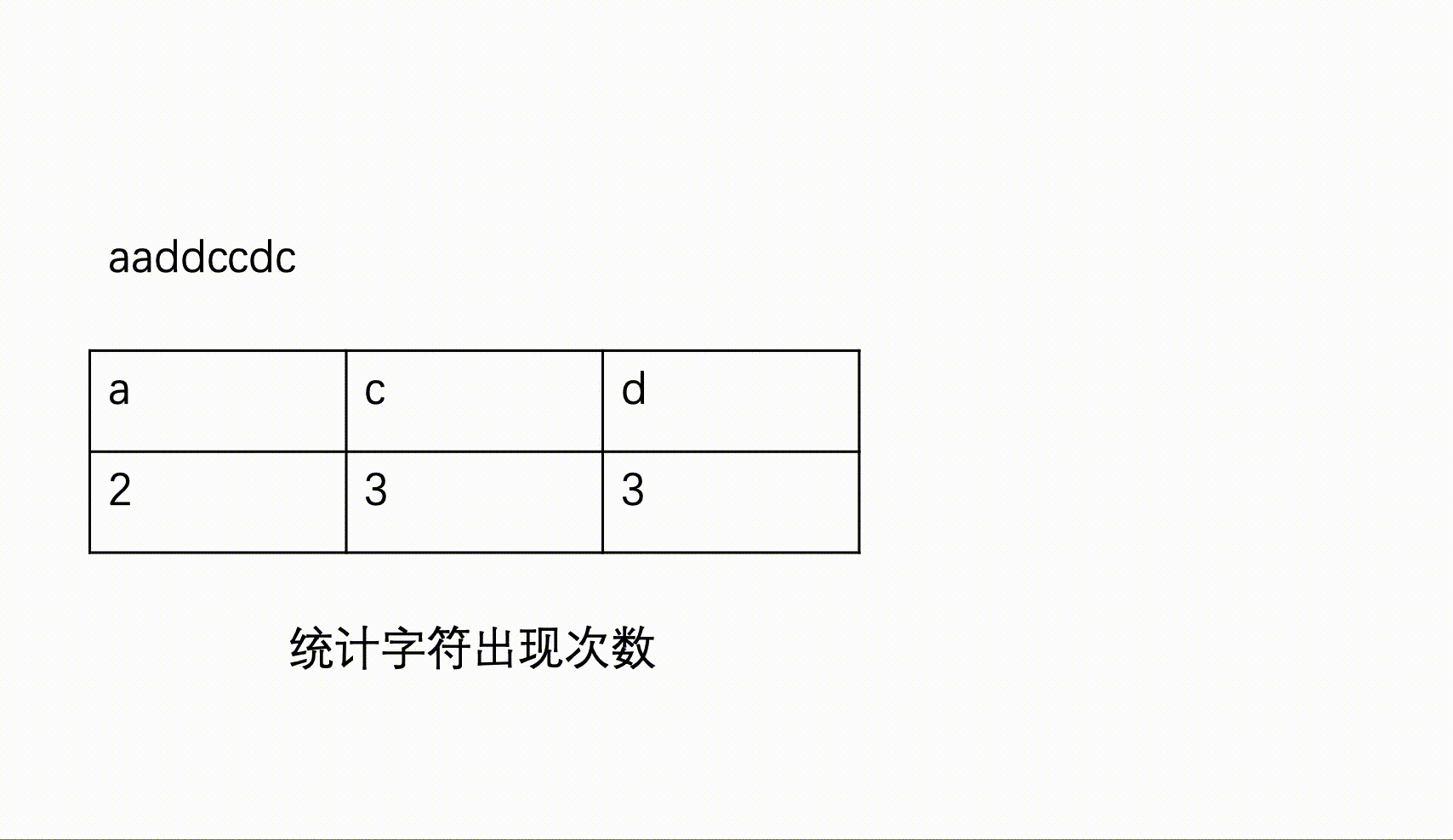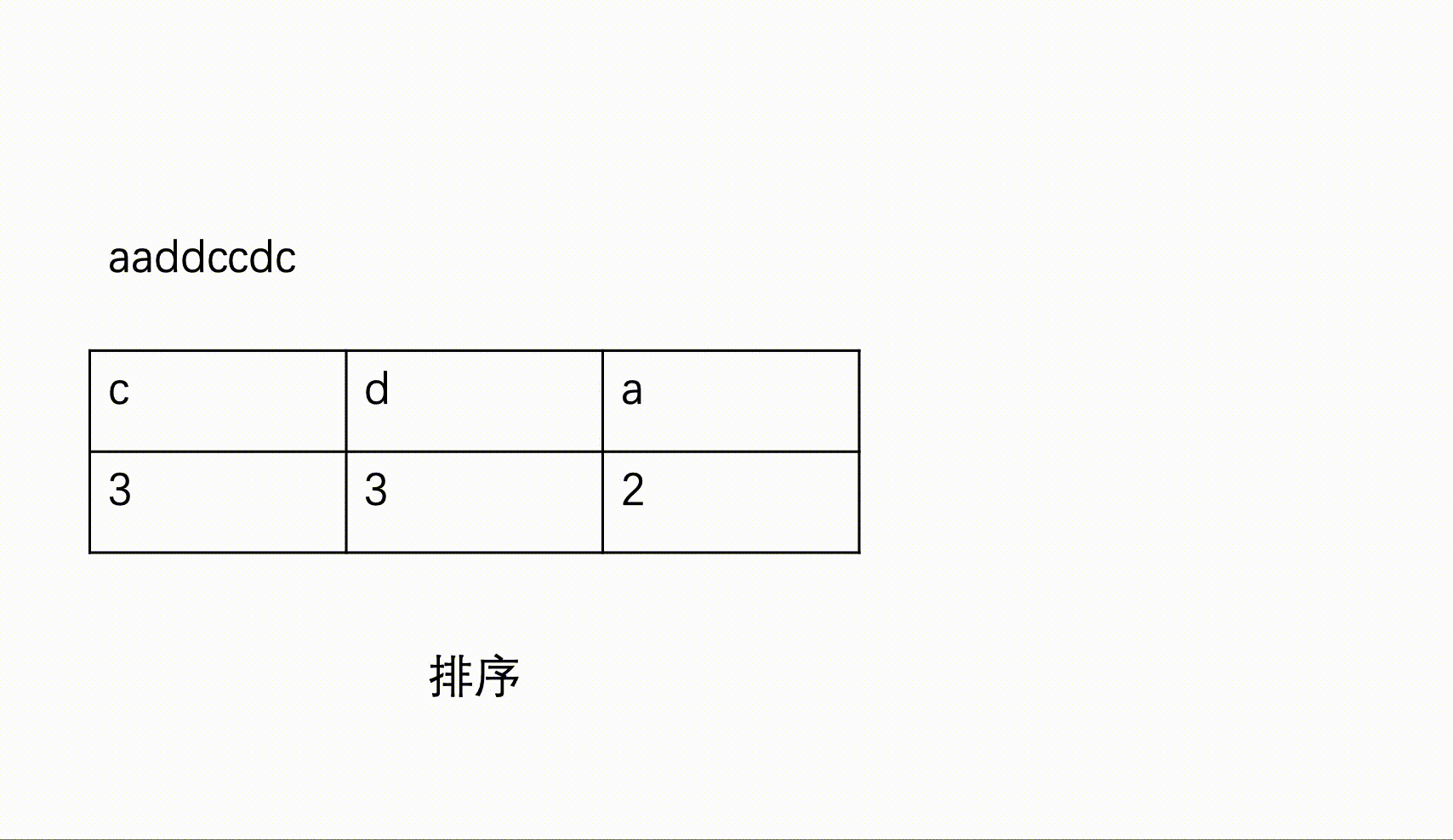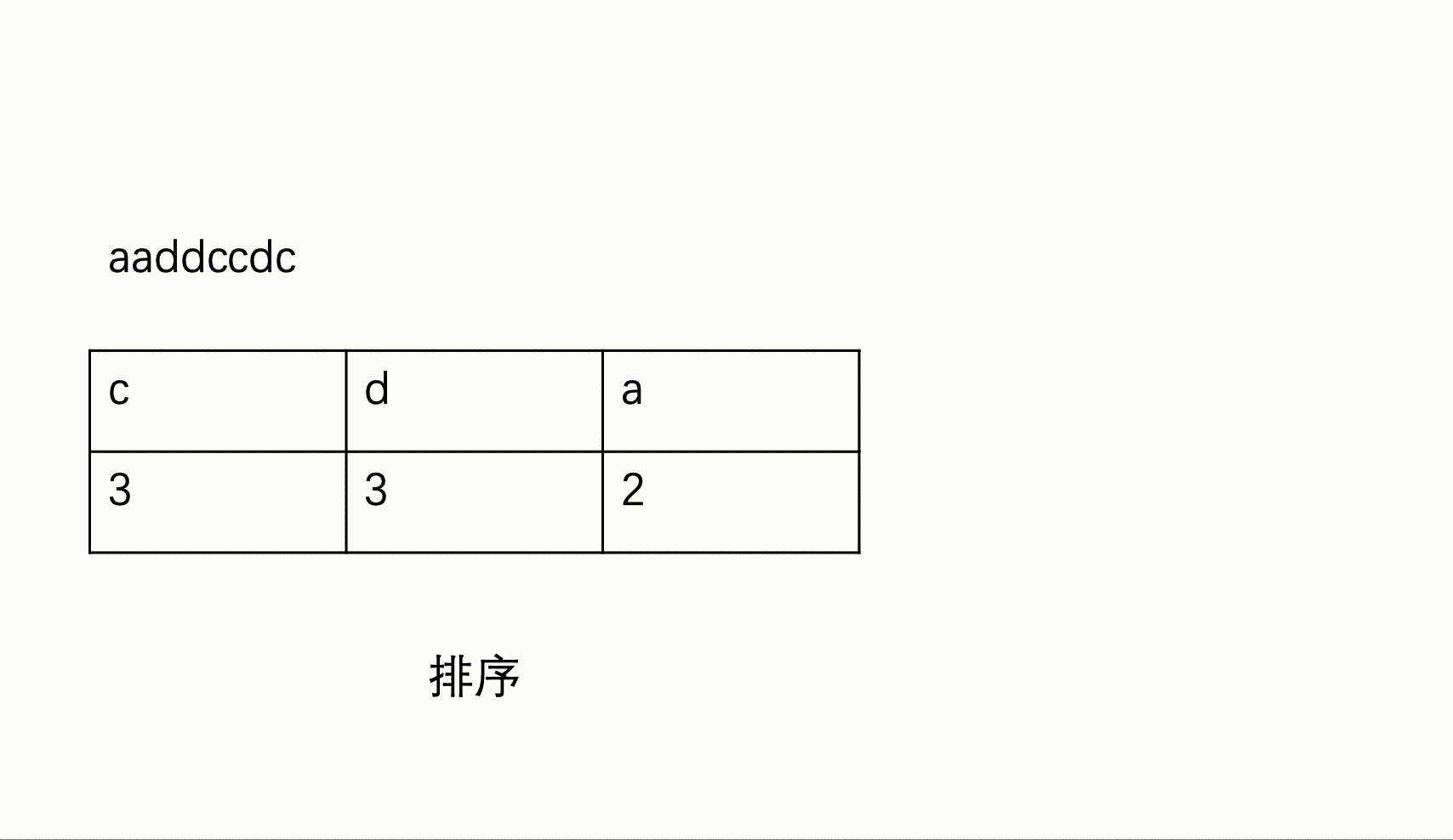
输入一个只包含小写英文字母和数字的字符串,按照不同字符统计个数由多到少输出统计结果,如果统计的个数相同,则按照ASCII码由小到大排序输出。
数据范围:字符串长度满足 1≤len(str)≤1000
输入描述:
一个只包含小写英文字母和数字的字符串。
输出描述:
一个字符串,为不同字母出现次数的降序表示。若出现次数相同,则按ASCII码的升序输出。
方法一:map
#include<iostream>
#include<map>
#include<string>
#include<algorithm>
using namespace std;
int main()
{
string str;
map<char,int> mp;
while(getline(cin,str))
{
map<char,int> mp;
for(int i=str.size()-1;i>=0;i--){//统计出现次数
mp[str[i]]++;
}
string res;
for(int i=str.size();i>=0;i--)//按照大小排序
{
for(auto x:mp)//按照ASCII码的大小遍历一遍mp
{
if(x.second==i){//如果有字符次数为i的则把该字符添加到res中
res += x.first;
}
}
}
cout<<res<<endl;
}
return 0;
}
方法二:
#include<bits/stdc++.h>
using namespace std;
bool cmp(pair<char,int> a,pair<char,int> b){
if(a.second==b.second){//当出现次数相同时
return a.first<b.first;//输出ASCII码较小的字符
}
return a.second>b.second;//输出出现次数较多的字符
}
int main(){
string s;
while(cin>>s){
map<char,int> mp;
for(int i=0;i<s.size();i++){//逐个统计字符出现次数
mp[s[i]]++;
}
vector<pair<char,int> > v(mp.begin(),mp.end());
sort(v.begin(),v.end(),cmp);//按照出现次数进行排序
for(auto it:v){
cout<<it.first;//按照次数大小输出
}
cout<<endl;
}
}
方法三:哈希表统计+sort排序
#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
#include<unordered_map>
using namespace std;
bool cmp(const pair<char, int>& a, const pair<char, int>& b){ //重载大小比较
if(a.second != b.second) //优先是个数降序
return a.second > b.second;
else //再是ASCⅡ升序
return a.first < b.first;
}
int main(){
string s;
while(cin >> s){
unordered_map<char, int> mp;
for(int i = 0; i < s.length(); i++) //哈希表统计每个字符出现的次数
mp[s[i]]++;
vector<pair<char, int> > record(mp.begin(), mp.end());
sort(record.begin(), record.end(), cmp); //排序
for(int i = 0; i < record.size(); i++) //输出
cout << record[i].first;
cout << endl;
}
return 0;
}
方法二:桶排序思想
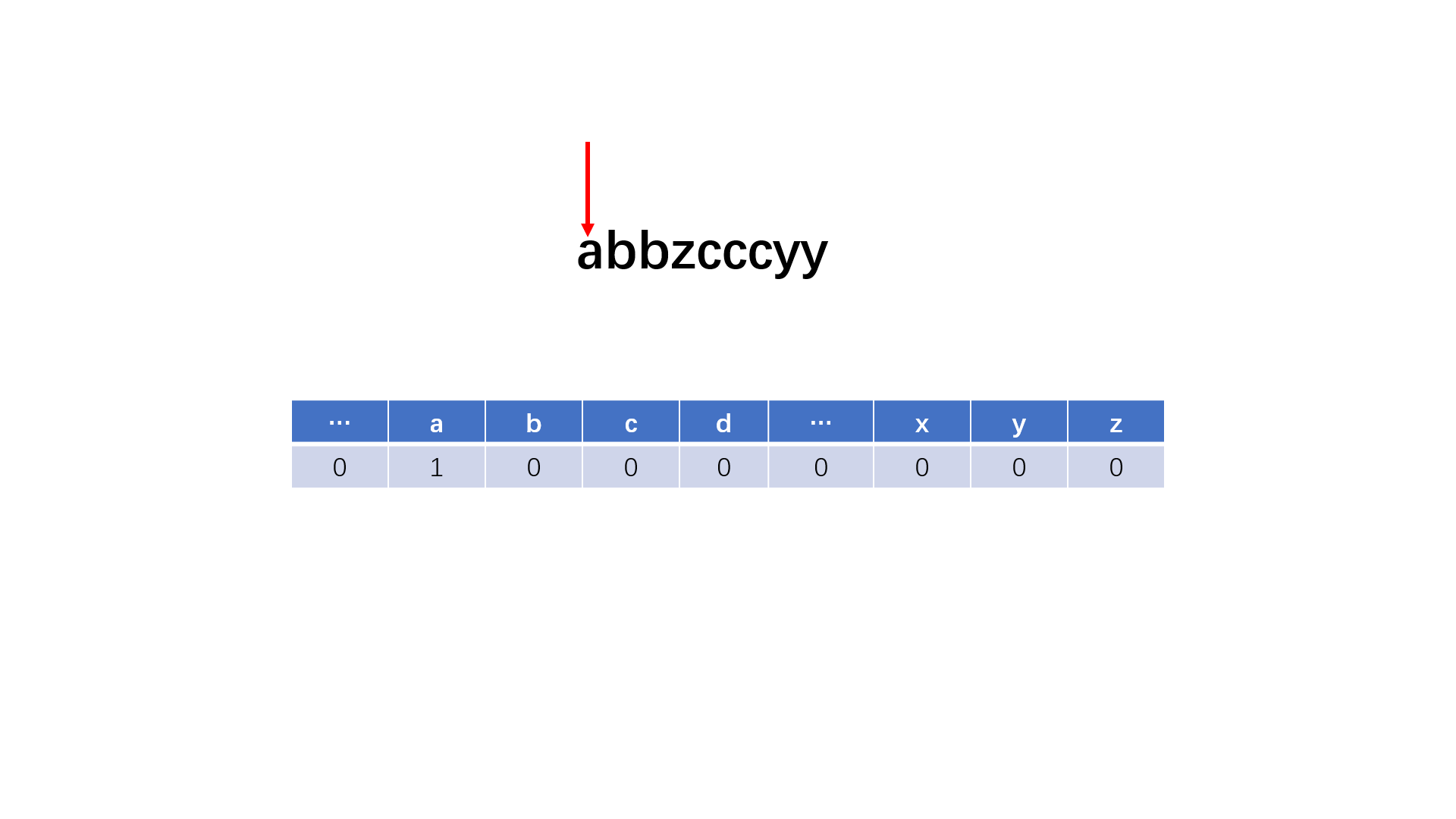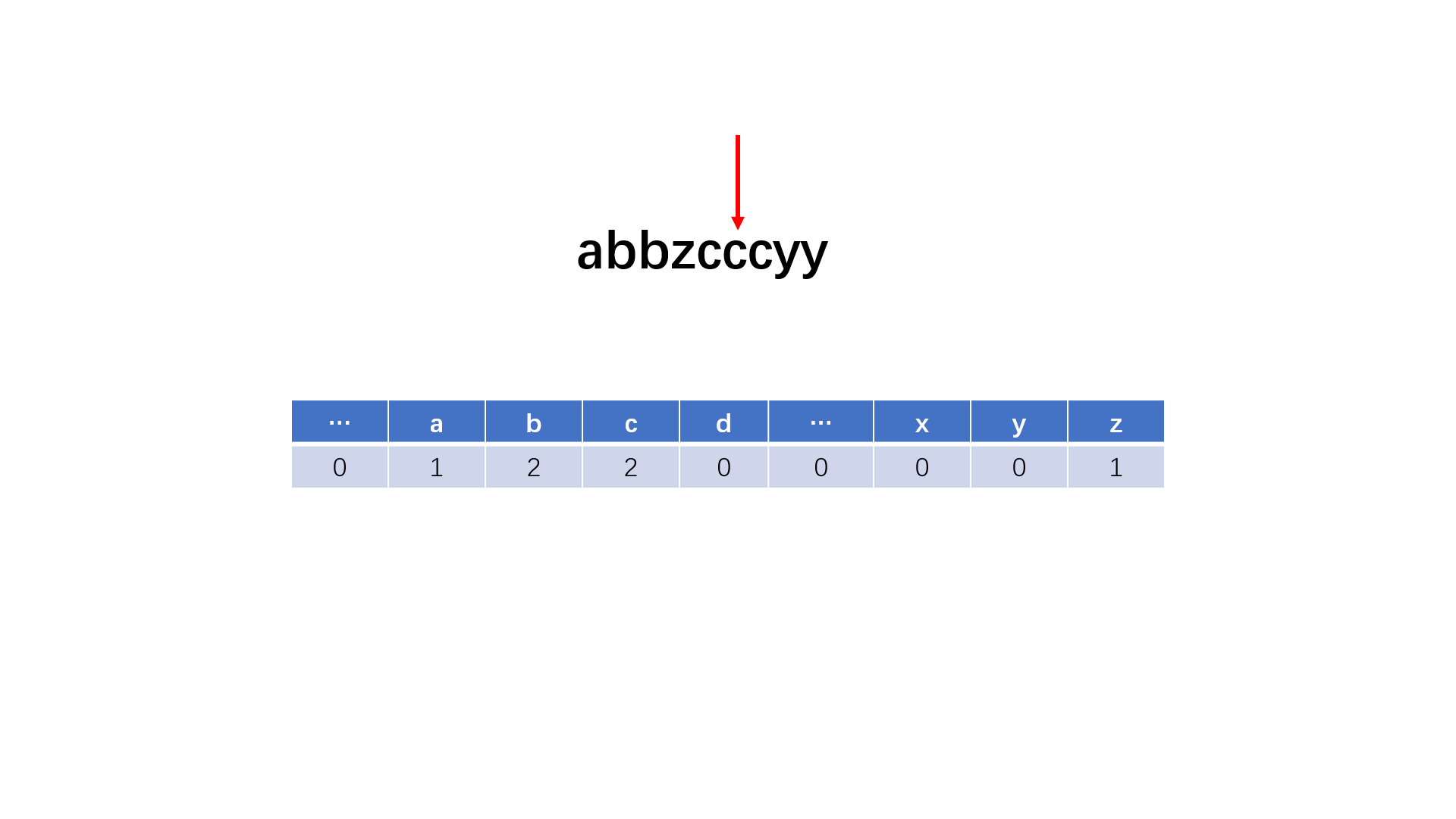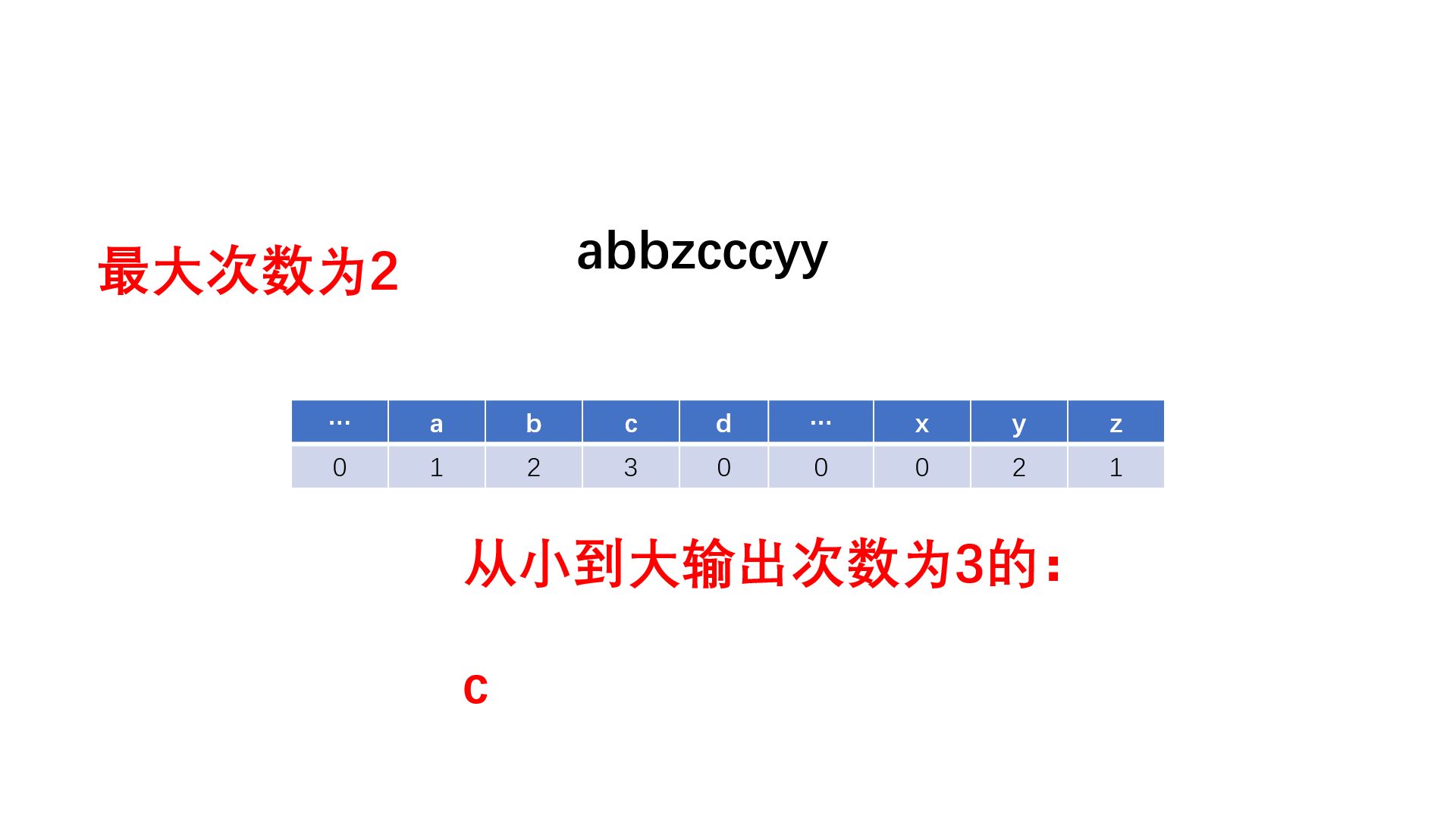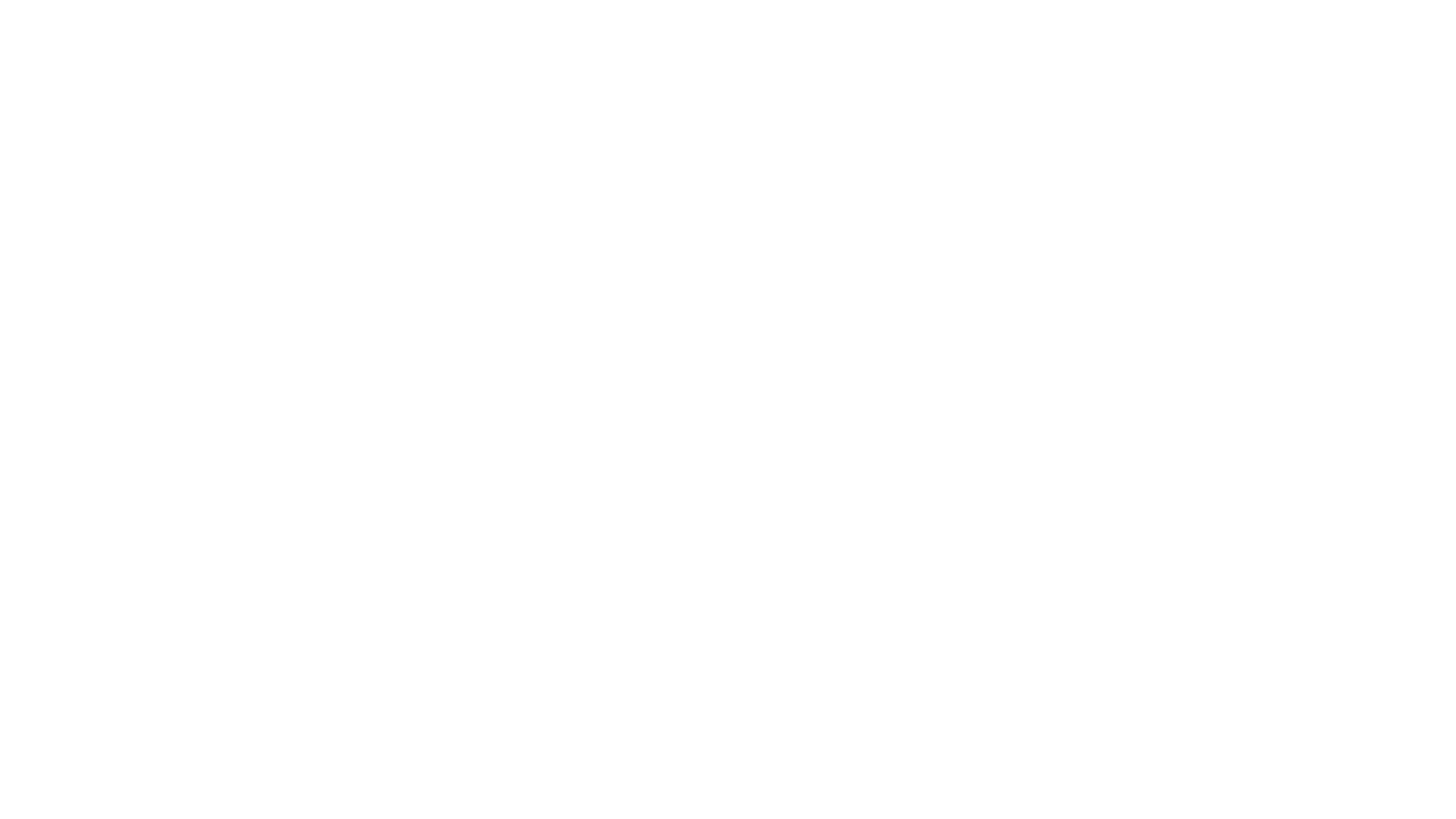
#include<iostream>
#include<string>
#include<vector>
using namespace std;
int main(){
string s;
while(cin >> s){
vector<int> hash(123, 0); //统计字母和数字出现的次数
int count = 0; //记录最高次数
for(int i = 0; i < s.length(); i++){
hash[s[i]]++;
count = max(count, hash[s[i]]);
}
while(count){ //遍历所有的次数
for(int i = 0; i < 123; i++) //从ASCⅡ码低到高找符合的输出
if(hash[i] == count)
cout << (char)i;
count--;
}
cout << endl;
}
return 0;
}
HJ103 Redraiment的走法
描述
Redraiment是走梅花桩的高手。Redraiment可以选择任意一个起点,从前到后,但只能从低处往高处的桩子走。他希望走的步数最多,你能替Redraiment研究他最多走的步数吗?
数据范围:每组数据长度满足 1≤n≤200 , 数据大小满足 1≤val≤350
输入描述:
数据共2行,第1行先输入数组的个数,第2行再输入梅花桩的高度
输出描述:
输出一个结果
方法一:暴力动态规划
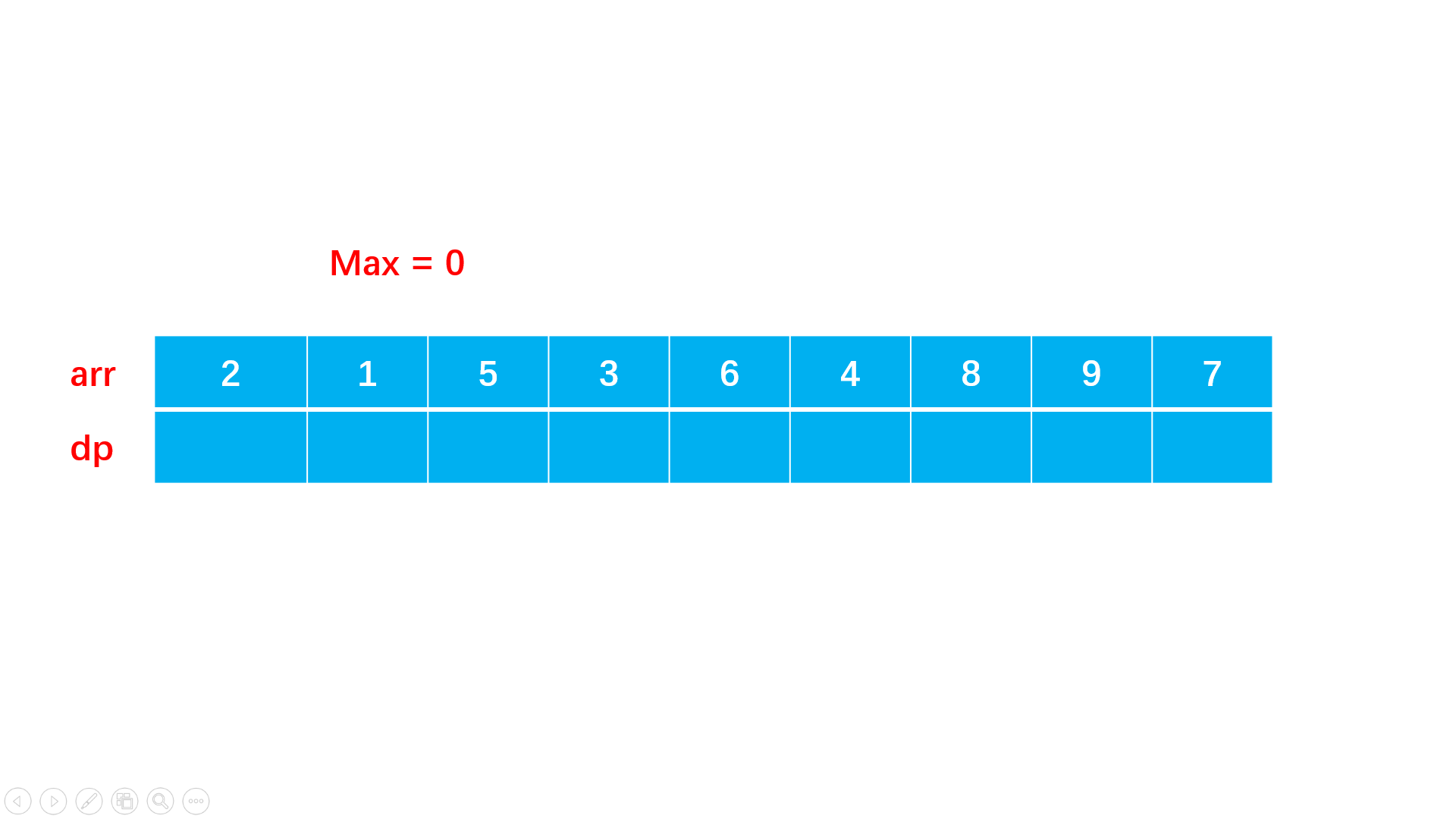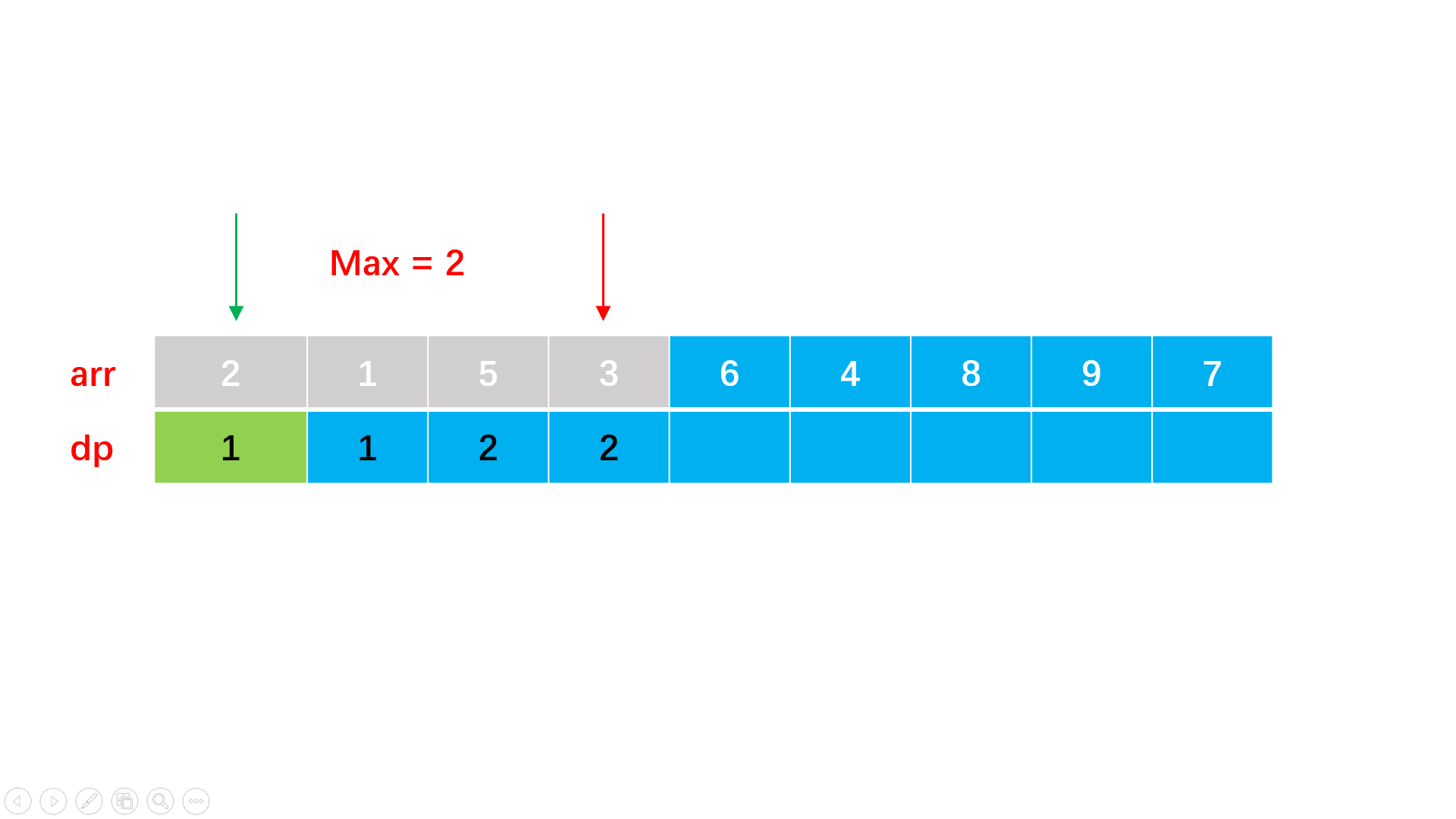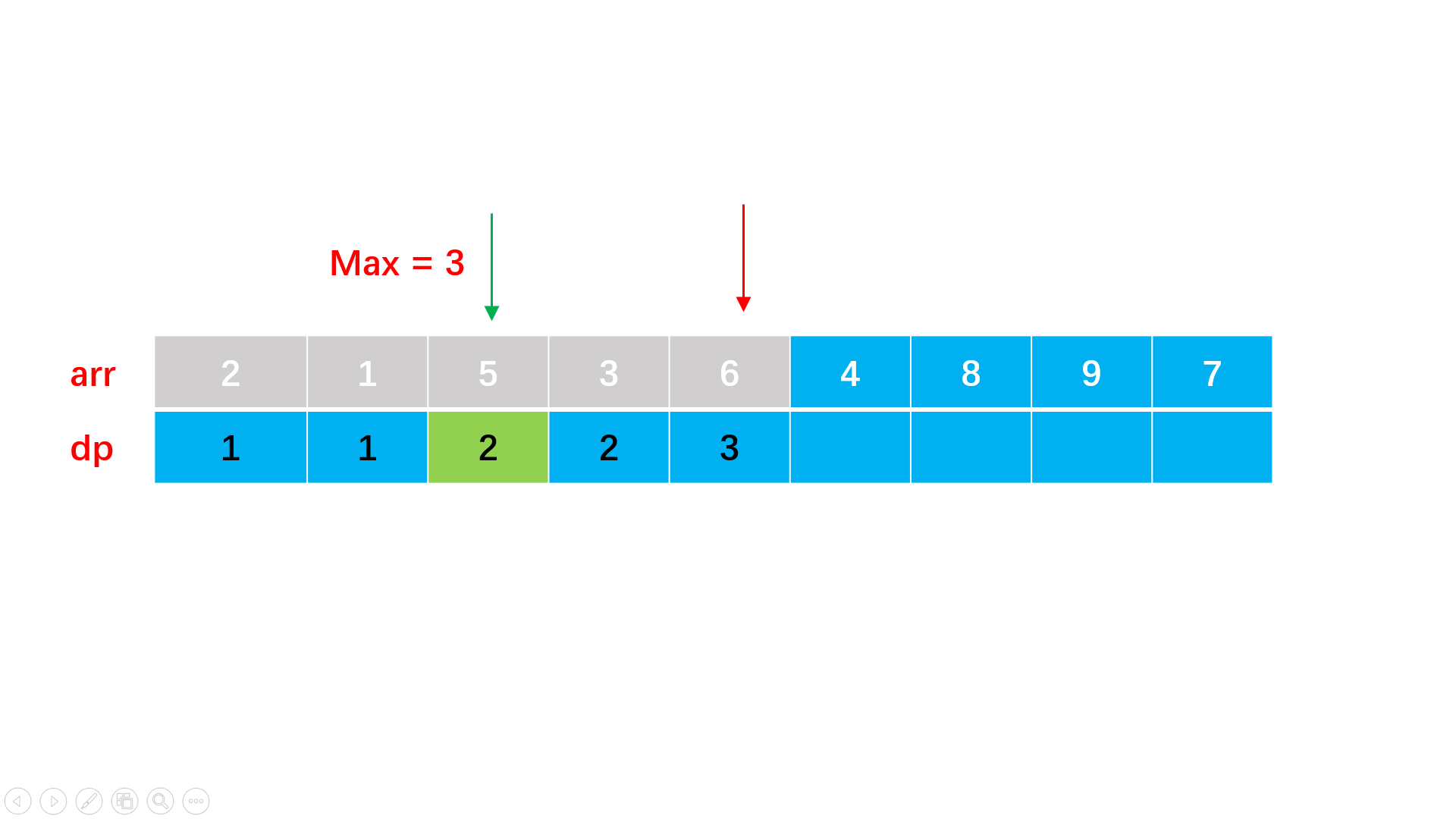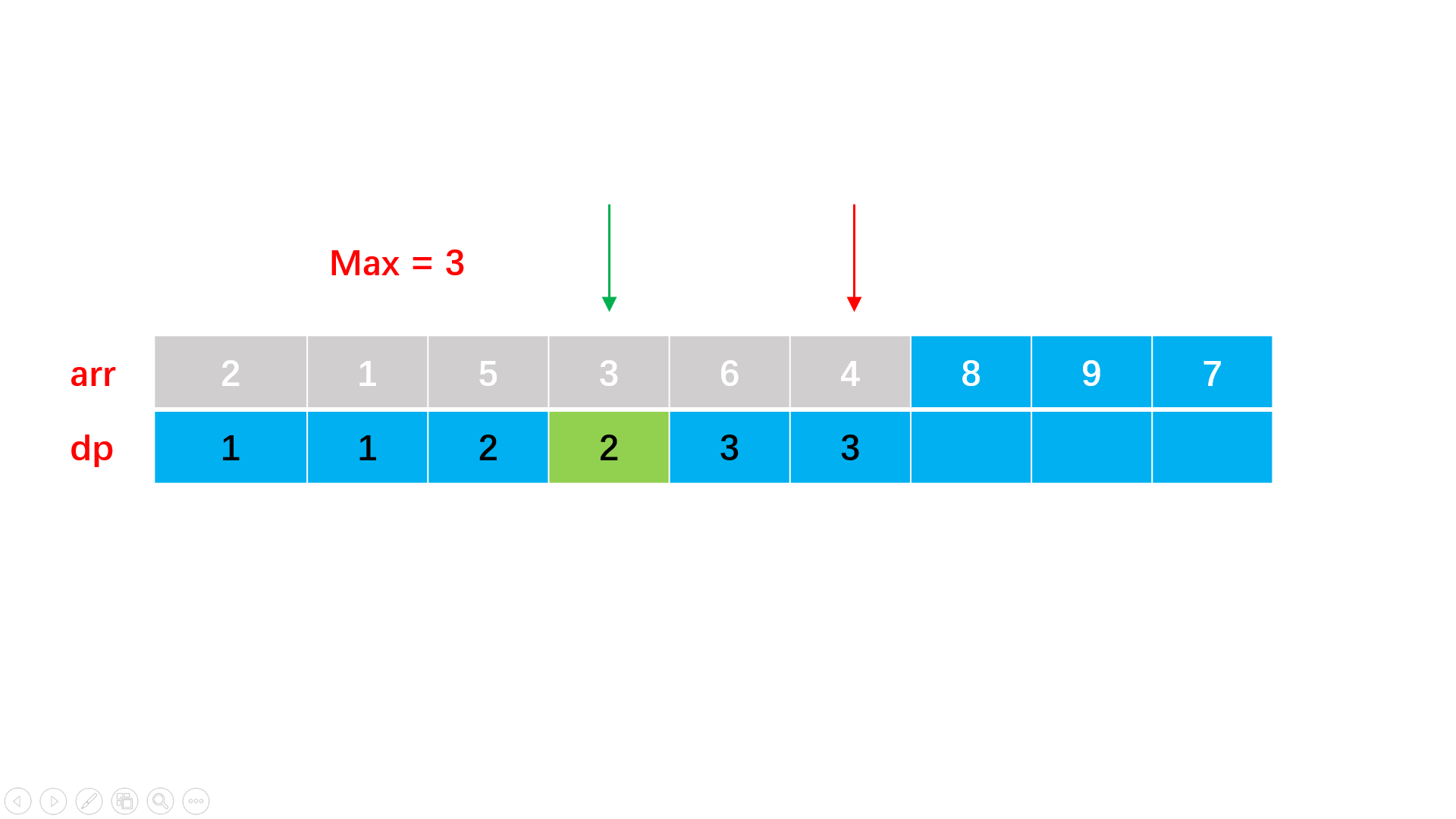
#include<iostream>
#include<vector>
using namespace std;
int lis(vector<int>& arr) {
vector<int> dp(arr.size(), 1); //设置数组长度大小的动态规划辅助数组
int max = 1;
for(int i = 1; i < arr.size(); i++){
for(int j = 0; j < i; j++){
if(arr[i] > arr[j] && dp[i] < dp[j] + 1) {
dp[i] = dp[j] + 1; //i点比j点大,理论上dp要加1
//但是可能j不是所需要的最大的,因此需要dp[i] < dp[j] + 1
max = max > dp[i] ? max : dp[i]; //找到最大长度
}
}
}
return max;
}
int main(){
int n;
while(cin >> n){
vector<int> arr(n);
for(int i = 0; i < n; i++) //输入
cin >> arr[i];
cout << lis(arr) << endl; //计算最长递增子序列长度
}
return 0;
}
方法二:二分法动态规划
#include<iostream>
#include<vector>
using namespace std;
int biSearch(int x, vector<int>& dp){ //二分查找函数
int left = 0, right = dp.size(), mid;
while(left <= right){
mid = (right + left) / 2;
if(dp[mid] >= x)
right = mid - 1;
else
left = mid + 1;
}
return left;
}
int lis(vector<int>& arr) {
vector<int> len; //设置数组长度大小的动态规划辅助数组
vector<int> dp;//用于二分划分的辅助数组
dp.push_back(arr[0]);
len.push_back(1);
for(int i = 1; i < arr.size(); i++){
if(arr[i] > dp[dp.size() - 1]) {
dp.push_back(arr[i]);
len.push_back(dp.size());
}
else{
int t = biSearch(arr[i], dp); //二分查找,找到第一个大于arr[i]的dp位置
dp[t] = arr[i];
len.push_back(t + 1);
}
}
return dp.size();
}
int main(){
int n;
while(cin >> n){
vector<int> arr(n);
for(int i = 0; i < n; i++) //输入
cin >> arr[i];
cout << lis(arr) << endl; //计算最长递增子序列长度
}
return 0;
}
HJ105 记负均正II
描述
输入 n 个整型数,统计其中的负数个数并求所有非负数的平均值,结果保留一位小数,如果没有非负数,则平均值为0
本题有多组输入数据,输入到文件末尾。
数据范围:1 ≤n≤50000 ,其中每个数都满足∣val∣≤106
输入描述:
输入任意个整数,每行输入一个。
输出描述:
输出负数个数以及所有非负数的平均值
方法一:循环输入

#include<iostream>
#include<iomanip>
using namespace std;
int main(){
int val;
int count = 0; //统计负数个数
double sum = 0; // 统计非负数和
int n = 0; //统计输入的总数
while(cin >> val){
n++; //计算输入的总个数
if(val < 0)
count++; //统计负数个数
else //累加非负数和
sum += val;
}
cout << count << endl;
if(count == n) //没有非负数
cout << "0.0" << endl;
else{
cout.setf(ios::fixed); //不足位自动补齐
cout << fixed << setprecision(1) << sum / (double)(n - count) << endl; //计算均值
}
return 0;
}
方法二:递归输入
#include<iostream>
#include<iomanip>
using namespace std;
void recursion(int& num, int& count, double& sum, int& n){ //递归输入
if(scanf("%d", &num) == EOF) //直到读取遇到文件结束
return;
n++;
if(num < 0) //统计负数个数
count++;
else //非负数和累加
sum += num;
recursion(num, count, sum, n); //进入下一次读取
}
int main(){
int val;
int count = 0; //统计负数个数
double sum = 0; // 统计非负数和
int n = 0; //统计输入的总数
recursion(val, count, sum, n);
cout << count << endl;
if(count == n) //没有非负数
cout << "0.0" << endl;
else{
cout.setf(ios::fixed); //不足位自动补齐
cout << fixed << setprecision(1) << sum / (double)(n - count) << endl; //计算均值
}
return 0;
}
HJ106 字符逆序
描述
将一个字符串str的内容颠倒过来,并输出。
数据范围:1≤len(str)≤10000
输入描述:
输入一个字符串,可以有空格
输出描述:
输出逆序的字符串
方法一:库函数
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int main(){
string s;
while(getline(cin, s)){
reverse(s.begin(), s.end()); //库函数逆序
cout << s << endl;
}
return 0;
}
方法二:双指针

#include<iostream>
#include<string>
using namespace std;
int main(){
string s;
while(getline(cin, s)){
int left = 0; // 首尾双指针
int right = s.length() - 1;
while(left < right) //指针中间靠
swap(s[left++], s[right--]); //相互交换位置
cout << s << endl;
}
return 0;
}
HJ107 求解立方根
描述
计算一个浮点数的立方根,不使用库函数。
保留一位小数。
数据范围:∣val∣≤20
输入描述:
待求解参数,为double类型(一个实数)
输出描述:
输出参数的立方根。保留一位小数。
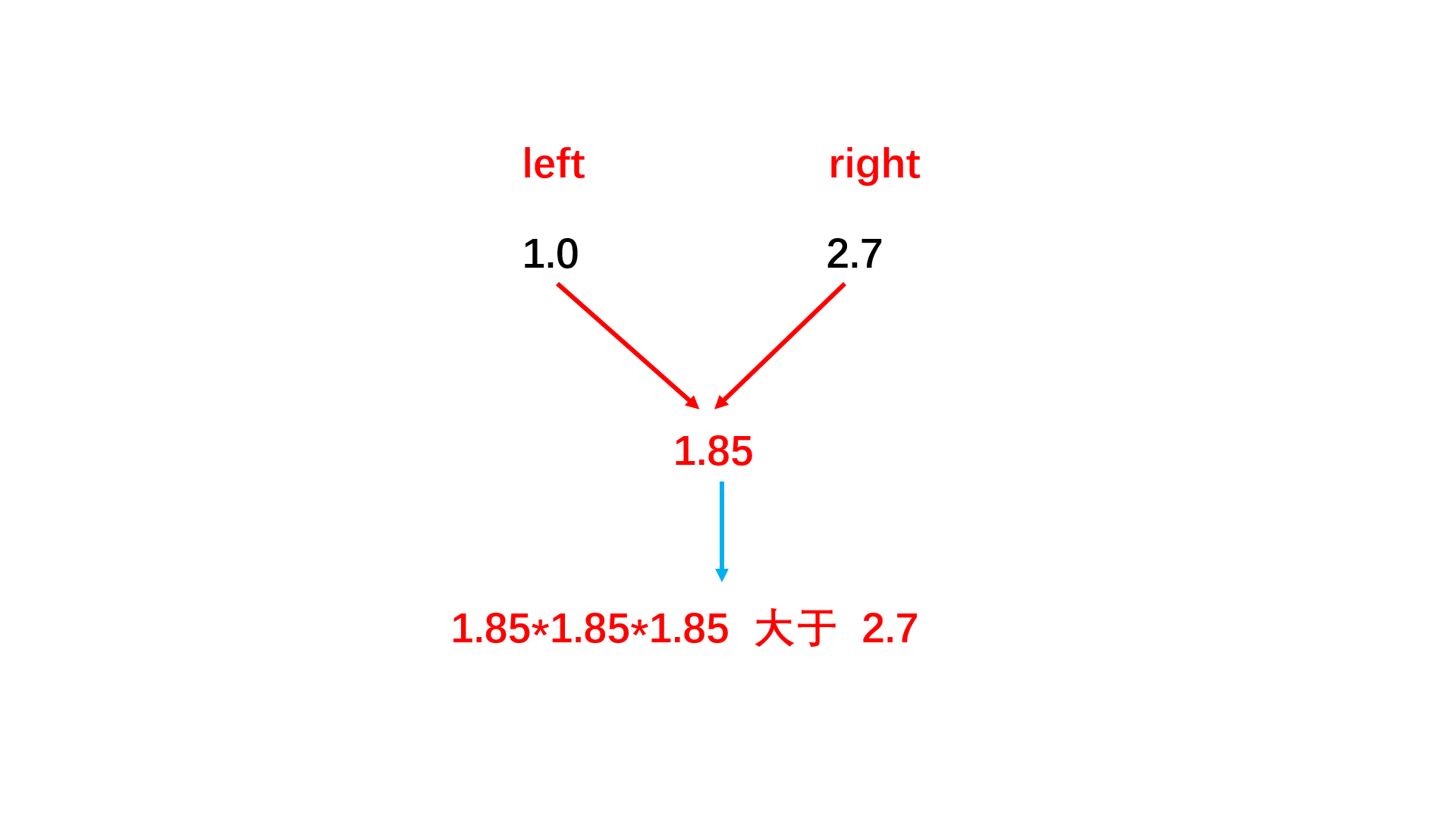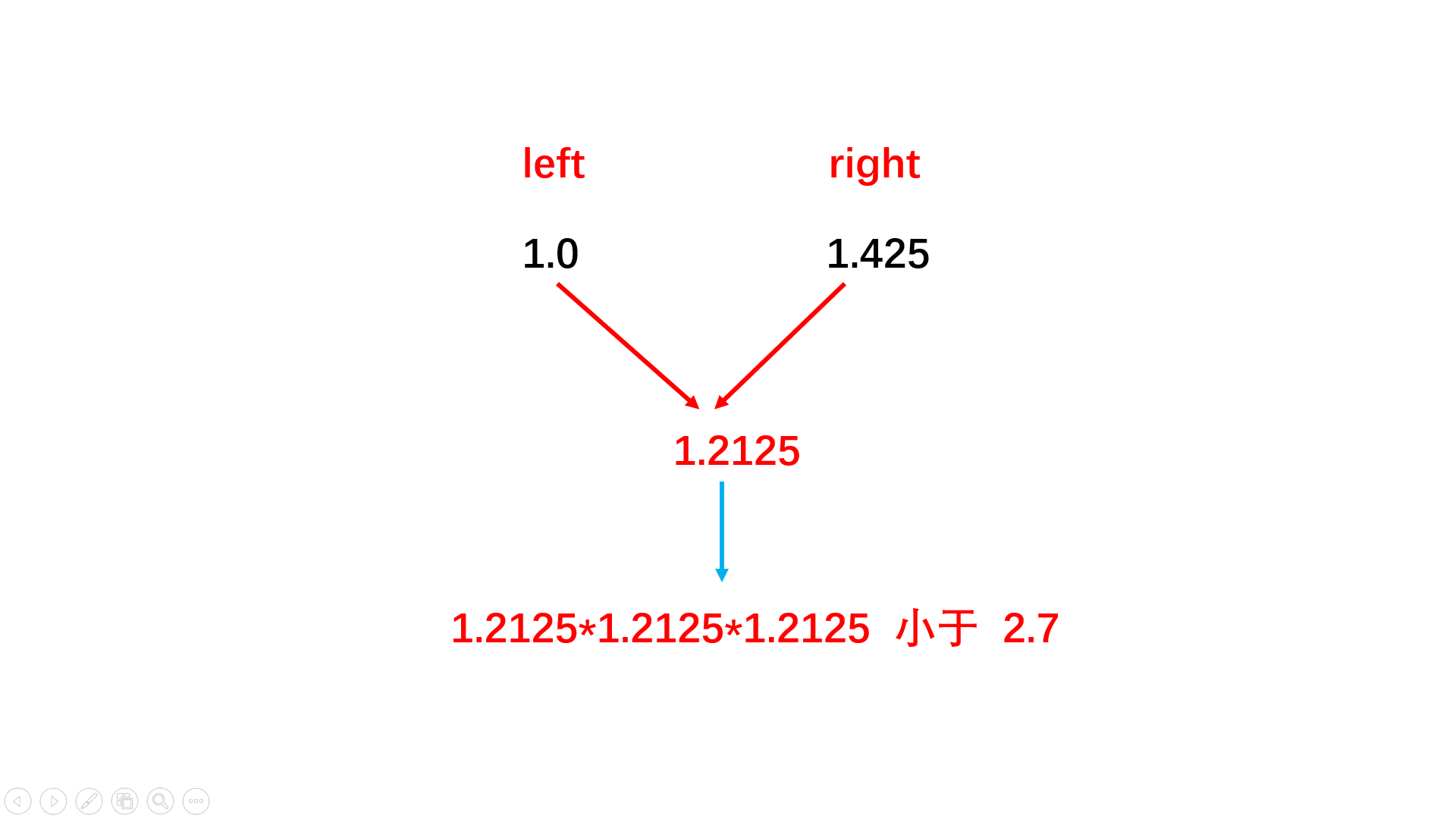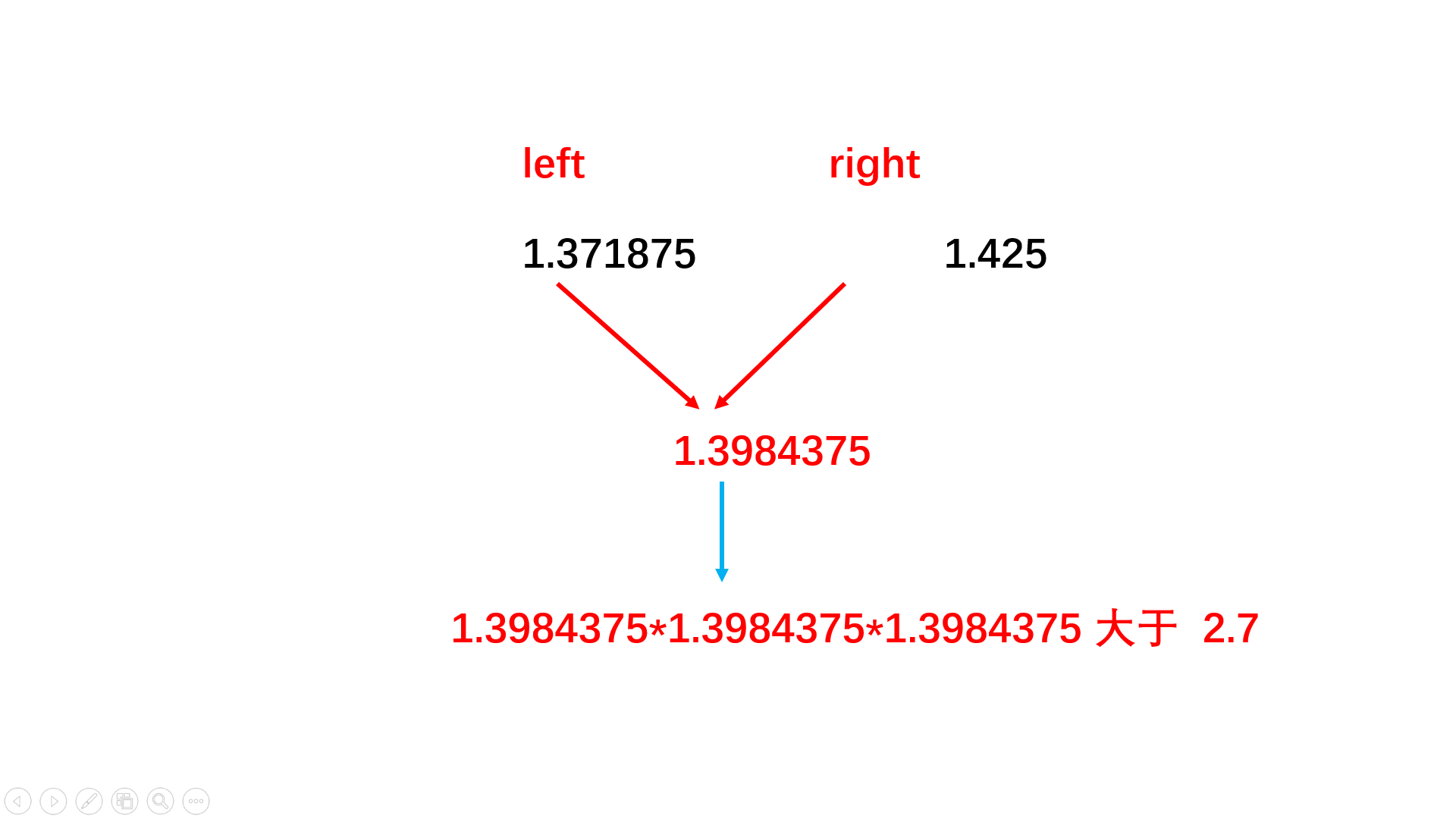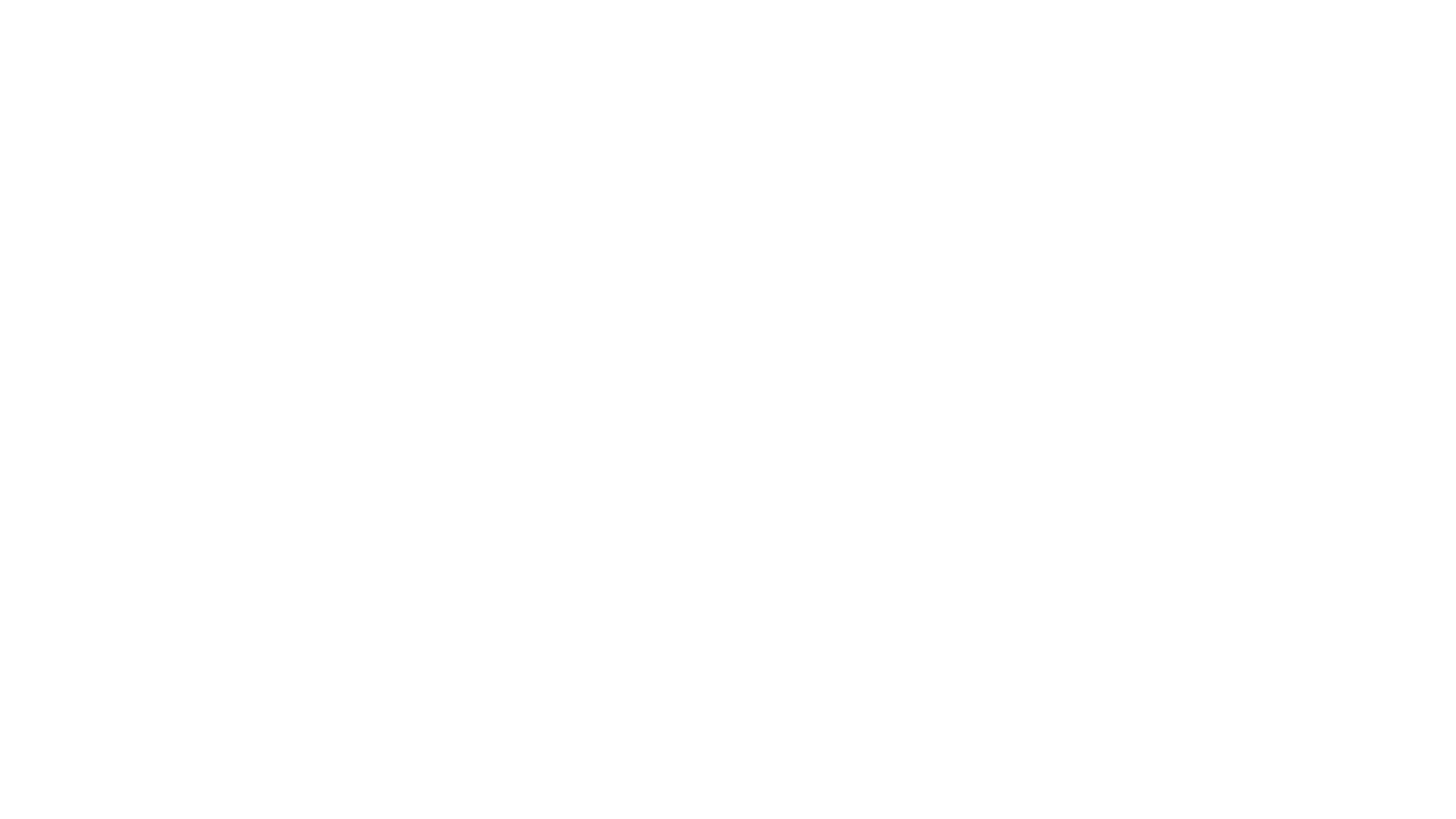
方法一:二分查找
#include<iostream>
#include<iomanip>
using namespace std;
double cal(double x){ //二分查找
double left = min(-1.0, x); //正负数都有
double right = max(1.0, x);
double y;
while(abs(right - left) > 0.01){ //立方根的精度值
y = (left + right) / 2; //二分中值
if(y * y * y > x) //比较选取二分哪一边
right = y;
else
left = y;
}
return y;
}
int main(){
double val;
while(cin >> val){
cout << setprecision(1) << fixed << cal(val) << endl; //控制小数位输出
}
return 0;
}
方法二:牛顿迭代法
#include<iostream>
#include<iomanip>
using namespace std;
double cal(double x){ //牛顿迭代法
double y = 1;
while(((y * y * y - x) >= 1e-2) || (x - y * y * y) >= 1e-2) //精度控制
y = (y - y / 3 + x / (3 * y * y));
return y;
}
int main(){
double val;
while(cin >> val){
cout << setprecision(1) << fixed << cal(val) << endl; //控制小数位输出
}
return 0;
}
HJ108 求最小公倍数
描述
正整数A和正整数B 的最小公倍数是指 能被A和B整除的最小的正整数值,设计一个算法,求输入A和B的最小公倍数。
数据范围:1≤a,b≤100000
输入描述:
输入两个正整数A和B。
输出描述:
输出A和B的最小公倍数。
方法一:暴力法
#include<iostream>
using namespace std;
int main(){
int a, b;
while(cin >> a >> b){
for(int i = a; ; i++){ //从a开始往后找
if(i % a == 0 && i % b == 0){ //直到遇到第一个两个数的公倍数
cout << i << endl;
break;
}
}
}
return 0;
}
方法二:最小公因数法
#include<iostream>
using namespace std;
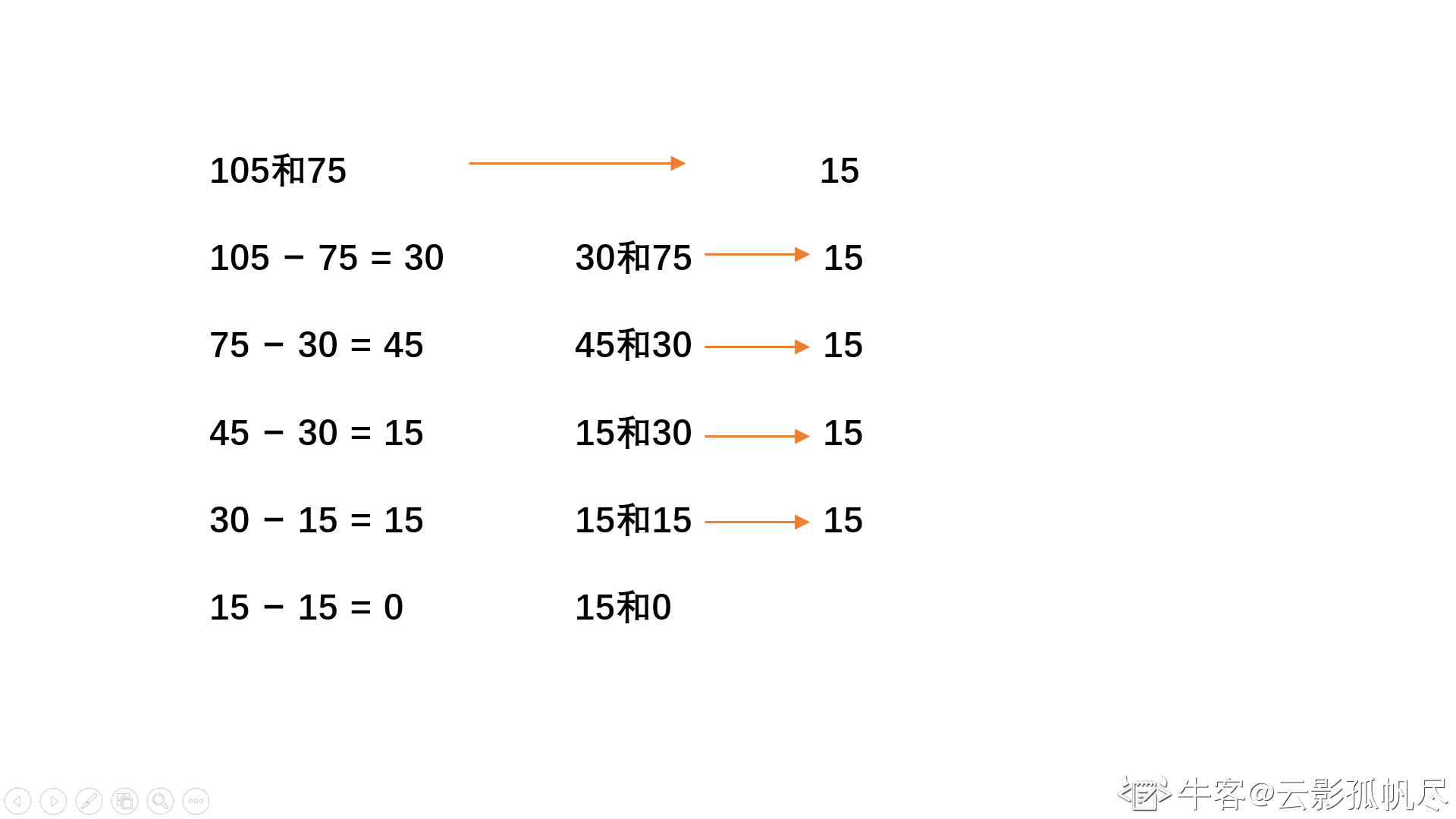
int gcd(int a, int b) { //更相减损法找最大公约数
int temp = abs(a - b); //取差的绝对值
while(temp != 0){ //不断减去差的绝对值直到为0
a = b;
b = temp;
temp = abs(a - b);
}
return b;
}
int main(){
int a, b;
while(cin >> a >> b){
cout << a * b / gcd(a, b) << endl; //乘积除以最大公因数
}
return 0;
}


















 42万+
42万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











