







 本文介绍了BiSeNet,一种结合空间路径和上下文路径的双边分割网络,用于实时语义分割。文章详细阐述了BiSeNet的结构,包括空间路径的细节、上下文路径的设计以及特征融合和注意力细化模块。实验结果表明,BiSeNet在Cityscapes、CamVid和COCO-Stuff等数据集上表现出色,并通过消融实验验证了其组件的有效性。
本文介绍了BiSeNet,一种结合空间路径和上下文路径的双边分割网络,用于实时语义分割。文章详细阐述了BiSeNet的结构,包括空间路径的细节、上下文路径的设计以及特征融合和注意力细化模块。实验结果表明,BiSeNet在Cityscapes、CamVid和COCO-Stuff等数据集上表现出色,并通过消融实验验证了其组件的有效性。
实时语义分割网络 BiSeNet
BiSeNet
Contributions
- 提出了一种包含空间路径(SP)和上下文路径(CP)的双边分割网络(BiSeNet), 将空间信息保存和接受域提供的功能解耦成两条路径。
- 提出了特征融合模块(FFM)和注意细化模块(ARM),以在可接受的成本下进一步提高精度。
- 在cityscape、CamVid和COCO-Stuff的基准上取得了令人印象深刻的成绩。具体来说,在105fps的城市景观测试数据集上,我们得到了68.4%的结果
BackGround
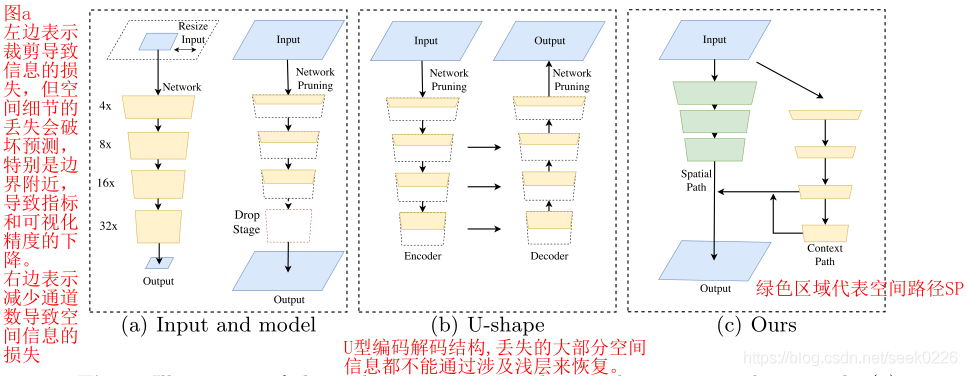
作者对比了当前用于三种用于加速模型的实时语义分割算法:
- 图(a)左侧所示,通过裁剪图片降低尺寸和计算量,但是会丢失大量边界信息和可视化精度。
- 图(a)右侧所示,通过修建/减少卷积过程中的通道数目,提高推理速度。其中的红色方框部分,是作者提及的ENet建议放弃模型的最后阶段(downsample操作),模型的接受域不足以覆盖较大的对象导致的识别能力较差。
- 图形(b)所示为U型的编码,解码结构,通过融合骨干网的细节,u型结构提高了空间分辨率,填补了一些缺失的细节,但是作者认为在u型结构中,一些丢失的空间信息无法轻易回复,不是根本的解决方案。
BiSeNet 结构

Spatial Path
绿色部分表示空间路径,每一层包括一个stride = 2的卷积,接着是批处理归一化和ReLU激活函数,总共三层,故而提取的特征图尺寸是原始图像的1/8。
'''code'''
class SpatialPath(nn.Module):
def __init__(self, *args, **kwargs):
super(SpatialPath, self).__init__()
self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
feat = self.conv1(x) # (N, 3, H, W)
feat = self.conv2(feat) # (N, 64, H/2, W/2)
feat = self.conv3(feat) # (N, 64, H/4, W/4)
feat = self.conv_out(feat) # (N, 128, H/8, W/8)
return feat
Context Path
第二个虚线框部分是上下文路径,用于提取上下文信息,利用轻量级模型和全局平均池进行下采样。作者在轻量级模型的尾部添加一个全局平均池,提供具有全局上下文信息的最大接收字段, 并且使用U型结构来融合最后两个阶段的特征,这是一种不完整的U型结构。作者使用了Xception作为上下文路径的主干。
'''code'''
class ContextPath(nn.Module):
def __init__(self, *args, **kwargs):
super(ContextPath, self).__init__()
self.resnet = Resnet18()
self.arm16 = AttentionRefinementModule(256, 128) # 先看下面的ARM的代码
self.arm32 = AttentionRefinementModule(512 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









