



网络亲和性感知的节能虚拟机放置算法
摘要
将虚拟机请求高效地映射到可用的物理机上是数据中心中的一项优化问题。该问题通过最小化物理机数量并将其利用率最大化来解决。数据中心中的另一优化方向是能耗。对于给定的一组虚拟机请求,使用较少的物理机可以降低能耗。本文尝试提出一种节能且网络亲和性感知的虚拟机放置算法。在放置过程中考虑虚拟机之间的亲和关系,可减少通信开销和网络负载。所提出的算法通过云模拟工具包进行评估,并在能耗、通信开销和活动的PM数量方面与标准的首次适应贪心算法进行了性能比较。
关键词 :虚拟化;亲和性感知;云计算;虚拟机部署;网络亲和性。
1 引言
云计算利用大规模的虚拟化服务器,因其按需提供各种服务以及按使用付费的模式,已成为最受欢迎的计算范式。云计算及相关服务的使用趋势不断上升,导致企业需要维护昂贵且节能的技术来支持数据中心应用程序。据估计,平均数据中心利用率约为10%。甘地等人(2009年)指出,即使在较低利用率的情况下,功耗仍达到数据中心峰值功耗的50%,其原因是数据中心中空闲服务器的静态功耗。这明显意味着必须减少空闲服务器的数量,并应发展出高效利用处于峰值利用率运行的服务器的技术。
在虚拟化数据中心中,许多应用程序(包括多媒体流应用)通过多个虚拟机执行,并动态分配到物理机(PMs)上(Kim 等人,2013;泰元姆等人,2014)。该过程称为虚拟机(VM)放置。研究人员(贝洛格拉佐夫和阿巴维,2011)已将能量感知的虚拟机部署确定为数据中心能源管理的一个有前景的领域。对于三层Web应用等应用程序,承载各层的虚拟机之间存在数据交换。对于此类应用程序,数据传输量和可用网络带宽会影响性能(Sudevalayam 和 Kulkarni,2011)。
如果通信虚拟机被放置在同一物理机上,则它们可以通过内存共享方式进行通信。因此,将通信虚拟机放置在同一物理机上可以减少通信开销。但在大多数现有研究中,虚拟机放置过程中未考虑虚拟机之间的通信依赖(Hermenier 等人,2009;Stillwell 等人,2010;Wood 等人,2009;Vasic 等人,2012)。
本工作在虚拟机放置过程中考虑了虚拟机之间的通信依赖。此外,通过尽量使用最少数量的物理机来满足给定的虚拟机请求,从而降低数据中心的能耗。
本文的主要贡献如下:
- 提出了一种通过定制K均值算法设计的新型物理机分类算法(PMCA)。PMCA算法在分类过程中考虑了物理机的CPU和带宽。
- 提出了一种基于CPU和带宽两个维度的基于工作负载的虚拟机分组方法。通过将虚拟机分配给所需维度上具有高资源容量的物理机,可以最小化应用程序的总执行时间。
- 提出了一种能效优先的网络亲和性感知虚拟机放置算法。
本文组织如下:第2节描述了问题建模。第3节详细阐述了提出的算法。第4节介绍了仿真环境,接着在第5节进行了性能评估。第6节讨论了相关工作。最后,在第7节给出了一些结论。
2 问题建模
设 $ V = {v_1, v_2, v_3, …, v_n} $ 为虚拟机集合,托管于物理机集合 $ P = {p_1, p_2, p_3, …, p_m} $ 中。每台物理机在CPU核心、内存和带宽方面具有不同的资源容量。虚拟机 $ V_i \in V $ 的资源需求表示为 $ V_{r,i} = (V_i^{cpu}, V_i^{mem}, V_i^{bw}) $。物理机 $ P_i \in P $ 的物理容量表示为 $ P_{cap,i} = (P_i^{cpu}, P_i^{mem}, P_i^{bw}) $。在任意时间 $ T $,当且仅当 $ V_{r,i} \leq P_{cap,j} $ 时,虚拟机 $ V_i \in V $ 才能托管于物理机 $ P_j \in P $,其中 $ \forall V_i \in V $ 且 $ P_j \in P $。
2.1 数据中心网络模型
描述数据中心网络拓扑时,在三层多根层次化数据中心中,物理机通常连接到边缘交换机。三个通信层分别为边缘、汇聚和核心。包含多个服务器或物理机的机架服务器连接到边缘层交换机。边缘层连接到下一层的两个汇聚交换机。每个汇聚交换机连接到下一层的一组核心交换机。数据中心通过核心交换机连接到外部网络。链接服务器与边缘交换机的链路被标记为一级链路 L1,边缘交换机与汇聚层之间的链路为二级链路 L2,汇聚层与核心层之间的链路为三级链路 L3。
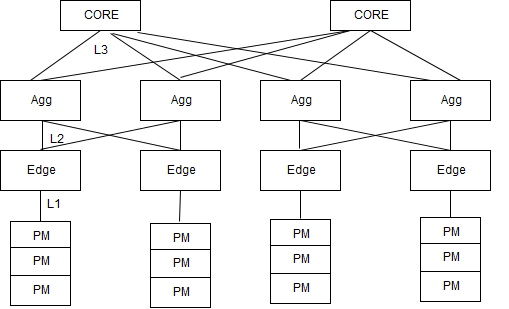
2.2 建模通信开销
任意两个虚拟机 $ V_i $ 和 $ V_j $ 之间的通信依赖,也称为亲和关系,表示为一个依赖图 $ G = (V, E) $,其中 $ V $ 是虚拟机集合,$ E $ 是边集合。如果 $ E = (V_i, V_j) $,则表示 $ V_i $ 和 $ V_j $ 之间存在通信依赖。设 $ T(V_i, V_j) $ 表示 $ V_i $ 和 $ V_j $ 之间的数据流量,使得 $ T(V_i, V_j) $ 与在 $ V_i $ 和 $ V_j $ 之间传输的字节数成正比。任意两台物理机 $ P_i $ 和 $ P_j $ 之间的距离用 $ D(P_i, P_j) $ 表示,即沿最短路径遍历 L1、L2、L3 等链路时,$ P_i $ 和 $ P_j $ 之间的跳数。
虚拟机 $ V_i $ 和 $ V_j $ 之间的通信开销 $ C(V_i, V_j) $,当它们分别托管于 $ P_i $ 和 $ P_j $ 时,定义如公式(1)所示。
$$
C(V_i, V_j) = \sum_{l=1}^{n} D(P_i, P_j) \times T(V_i, V_j) \times L_i
\tag{1}
$$
如果 $ V_i $ 和 $ V_j $ 托管于同一物理机,则 $ C(V_i, V_j) = 0 $。
2.3 能耗模型
多项研究已经表明,处理器消耗的能量与其利用率之间存在线性关系(范等人,2007)。因此,在本研究中,我们考虑服务器的功耗,该服务器可运行在两种模式下:活动模式和空闲模式。活动服务器消耗的功率根据其利用率以及空闲服务器的静态功耗进行测量。这通过贝洛格拉佐夫和阿巴瓦伊(2012)提出的公式计算,如公式(2)所示。
$$
P(u) = k \cdot P_{max} + (1 - k) \cdot P_{max} \cdot u
\tag{2}
$$
其中 $ P_{max} $ 为满利用率时的功耗,$ k $ 为空闲物理机消耗的静态功耗比例,$ u $ 为 CPU 利用率。
目标函数是找到一种虚拟机到物理机映射方式,以最小化:
1. 虚拟机 $ V_i $ 和 $ V_j $ 之间的通信开销 $ C(V_i, V_j) $;
2. 数据中心的能耗;
3. 托管虚拟机请求所需的活动物理机数量。
3 提出的算法
3.1 物理机分类算法
在数据中心中放置虚拟机的问题是 NP 难问题,无法在多项式时间内求解(陈等人,2015年)。一种缩短放置决策时间的方法是限制算法在进行潜在放置时所检查的目标物理机数量。本文提出的基于 K 均值聚类的新型 PMCA 可实现这一目标。该聚类方法基于服务器的 CPU 和带宽容量,将可用的物理服务器划分为 k 个具有相似容量的集合。在虚拟机放置过程中,仅选择其中一个物理集合作为目标,从而缩小搜索空间。PMCA 的伪代码如下所示。
算法 1 PMCA
输入
:物理机集合和 k 值
输出
:已分类的物理主机集合
- 找到用于选择最优聚类数量的 k 个点
- $ K = \text{classify}(物理机) $
- 根据主机 CPU 和带宽选择初始聚类中心
- 质心列表 = 查找初始质心 (PM列表)
- 集群列表 = 返回集群(PM集合)
3.2 工作负载感知的虚拟机分组
根据虚拟机执行的应用程序,可将它们分为三类:计算密集型、网络密集型和均衡型。为了提高效率,应将计算密集型虚拟机放置在具有较高计算能力的物理机上。类似地,网络密集型虚拟机必须放置在具有较高带宽能力的物理机上。均衡型虚拟机则应利用活动的物理机上的剩余资源进行部署,以最小化活动物理机数量。
3.3 能效优先的网络亲和性感知虚拟机放置(EENAAVMP)
如前一节所述,根据虚拟机所承载的应用程序的性质,将虚拟机分为计算密集型、网络密集型和均衡型。所提出的能效优先的网络亲和性感知虚拟机放置(EENAAVMP)该算法考虑了网络密集型虚拟机的亲和关系。相应地,将计算密集型虚拟机放置在具有高 CPU 容量的物理机上。在放置网络密集型虚拟机时,会考虑其亲和关系。均衡型虚拟机则被放置在密集的集群中,以便将物理机的未利用容量分配给这些虚拟机。所提出的算法的伪代码如下所示。
算法 2 EENAAVMP算法
输入
:分类的虚拟机请求集合 $ V = {v_1, v_2, …, v_n} $,物理机集群集合
输出
:虚拟机-物理机映射
对于每个 $ V_i $ 在 $ V $ 中
检查 $ V_i $ 的类别
如果 $ V_i $ 是计算密集型
对于每个计算型物理机集群
对集群中的每个 $ P_i $ 执行
如果 $ V_{r,i} \leq P_{cap,i} $,则分配 $ (V_i, P_i) $
结束如果
否则如果 $ V_i $ 是网络密集型
如果 $ \exists V_j $ 且 $ E = (V_i, V_j) $
识别集群中每个 $ P_i $ 的依赖 $ V_j $ 集群
如果 $ V_{r,i} \leq P_{cap,i} $ 那么
分配 $ (V_i, P_i) $
Else
识别最近的集群
对于集群中的每个 $ P_i $
如果 $ V_{r,i} \leq P_{cap,i} $,则
分配 $ (V_i, P_i) $
结束如果
否则 /
$ V_i $ 具有均衡的工作负载
/
识别密集的集群
对每个 $ P_i $ 执行
如果 $ V_{r,i} \leq P_{cap,i} $ 成立,则
分配 $ (V_i, P_i) $
结束如果
4 仿真环境
为了评估所提出算法的性能,使用了 cloudsim(Calheirose 等,2011)工具包。通过扩展现有类并添加新类来实现提出的算法。同时增加了模拟具有不同资源容量的物理机以及生成多个虚拟机请求的功能。
使用 cloudsim 工具包,PM 配置的创建类似于亚马逊 EC2 实例(在线),如表1所示。每次实验运行的物理机数量随机生成,如表2所示。
| 表1 数据中心中可用的物理机类型 | ||||
|---|---|---|---|---|
| 主机类型 | CPUs | 内存(GB) | 带宽(Mbps) | 功率(W) |
| M1 | 2 | 8 | 450 | 220 |
| M2 | 4 | 16 | 750 | 260 |
| M3 | 8 | 32 | 1,000 | 300 |
| M4 | 16 | 64 | 2,000 | 380 |
| 表2 每次仿真运行所采用的总PM数 | ||||
|---|---|---|---|---|
| 总PM数 | 类型M1 | 类型-M2 | 类型-M3 | 类型-M4 |
| 600 | 150 | 150 | 150 | 150 |
| 1,200 | 300 | 300 | 300 | 300 |
| 1,800 | 450 | 450 | 450 | 450 |
具有亲和关系的虚拟机请求数量以随机方式生成,并且多个请求在随机的时间间隔内重复提交,如表3所示。虚拟机数量从100到1,800不等。请求以每批次十个的方式提交,每批次中的虚拟机数量相等。例如,对于100个虚拟机请求,每个批次将包含十个虚拟机。在同一批次内,虚拟机请求类型为计算密集型、网络密集型和均衡的工作负载的均等混合。这样做是为了映射实时的虚拟机请求,因为在实际场景中,虚拟机请求是动态的,因此包含各种不同类型的工作负载。
| 表3 每次仿真运行的总PM数和随机生成的虚拟机请求 |
|---|
| 物理机数量 |
| 600 |
| 1,200 |
| 1,800 |
5 性能分析
本节详细讨论在各种仿真实验中获得的结果。
5.1 能耗
图1、图2和图3展示了首次适应贪心算法与所提出的EENAAVMP在能耗上的对比。通过分别设置物理机数量为600、1,200和1,800来分析性能。从图中可以推断出,随着虚拟机请求数量的增加,能耗呈线性增长。这是由于物理机数量的增加所致。为满足虚拟机需求而启动。通过分析使用两种算法绘制的能耗参数可以看出,能耗差异并非恒定,且在不同的仿真运行中有所变化。当虚拟机请求数量趋于增加时,能耗差异尤为显著。这表明EENAAVMP算法在应对高峰虚拟机请求需求方面比首次适应贪心算法更高效。


5.2 物理机数量
该指标直接定义了用于承载虚拟机请求的物理机数量,反映了算法的打包效率。两种算法的性能对比图如图4、图5和图6所示。从图4可以看出,当虚拟机请求数量增加时,更多的物理机被激活。当虚拟机请求数量达到1,800时,两种算法都需要将所有可用的物理机全部激活。观察发现,首次适应贪心算法在虚拟机请求超过600时即已将所有物理机激活。而与贪心算法不同的是,提出的EENAAVMP算法随着虚拟机请求数量的增加,线性地增加活动的物理机数量。从图5和图6可见,当物理机数量为1,200和1,800时,在虚拟机请求数量较小时,活动的物理机数量差异较小。当虚拟机请求数量逐渐超过物理机数量时,贪心算法会将所有物理机全部激活,而所提出的算法则能以更少的物理机高效地打包部署虚拟机。



5.3 通信开销
所提出算法的主要目标是将具有亲和关系的虚拟机放置得更靠近,以降低通信开销。当物理机数量为600、1,200和1,800时,对应的通信开销分别如图7、图8和图9所示。可以看出,随着虚拟机请求数量的增加,通信开销呈线性增长。随着请求数量的增加,两种算法之间的开销差异逐渐减小。这可以归因于以下事实:当虚拟机数量较多时,无法将所有虚拟机都放置在物理邻近的位置。



6 相关工作
相关工作分为两大类进行讨论,一类是针对节能型虚拟机部署的研究,另一类是关注部署过程中亲和关系的研究。
6.1 能量感知的虚拟机部署
在各种文献中,虚拟机部署期间的能耗问题已被广泛研究。能源管理可在初始虚拟机部署时进行,即在虚拟机实例化时以及虚拟机迁移过程中实施。Kumar 等人 (2009) 提出了一种基于动态虚拟机整合的能源管理方法。其思想是尽可能减少处于低功耗状态的物理机数量,从而降低整体能耗。在贝洛格拉佐夫和阿巴维(2012)中,提出了解决虚拟机部署问题时考虑多种物理维度的方法。然而,并未研究网络对算法性能的影响。贝洛格拉佐夫和布亚 (2012) 提出了多种用于最优虚拟机部署的自适应启发式算法。所提出的算法能够在线动态优化虚拟机部署,并使用真实工作负载轨迹进行评估。董等人 (2013) 在部署过程中考虑了多资源约束,即 CPU、存储、内存和带宽。他们提出了一种贪心算法,旨在提高所有维度上的资源利用率。然而,该方法未考虑应用程序之间的亲和关系。唐和潘 (2015) 提出了一种改进的遗传算法用于节能型虚拟机部署。他们选择随机初始种群并通过后续变异来获得最优解。然而,该算法具有较高的计算复杂度。宋等人 (2014) 提出了针对多目标虚拟机部署问题的凸优化理论。达什蒂和拉赫马尼 (2015) 提出了一种改进的粒子群优化算法用于负载均衡的虚拟机部署。通过关闭利用率不足的机器来实现能效提升。徐等人 (2015) 实现的另一种元启发式算法是蚁群优化 (ACO)。利用改进的 ACO,该算法旨在提高性能并最小化初始虚拟机部署期间的能耗。戴等人 (2016) 提出了用于多租户数据中心的节能型虚拟机调度方法。他们考虑了网络组件的能耗,但未考虑虚拟机之间的亲和关系。尽管已有许多新颖的方法来解决该虚拟机放置问题,从上述研究可以看出,大多数研究未考虑所提交的虚拟机请求的性质。我们提出的工作与现有文献不同,因为它考虑了所处理的虚拟机请求类型以及它们之间的亲和关系。
6.2 亲和性感知的虚拟机放置
Sonnek 等人 (2010) 提出了一种流量感知的虚拟机放置方法,该方法试图将具有亲和关系的虚拟机放置得更靠近。但它未优化能耗。Yan 等人 (2012) 提出了一种贪心算法,用于将虚拟机分组以形成紧凑集群,并考虑了集群间的亲和关系,通过距离来衡量这种关系。Vu 等人 (2014) 提出了一种流量与功耗感知的虚拟机迁移算法。该算法旨在通过放置虚拟机来实现资源利用率的均衡,主要考虑的资源是CPU利用率。但它忽略了内存和带宽的影响,而这些因素同样重要。在 Chen 等人 (2013) 中,提出了一种亲和性感知的虚拟机分组算法。该方法将虚拟机放置问题修改为分组虚拟机放置问题。然而,当物理机容量小于虚拟机组时可能出现的问题并未得到解决。Su 等人 (2015) 提出了一种亲和性与冲突感知放置算法,该算法在放置过程中考虑了虚拟机之间的亲和关系和冲突关系。但其未考虑最小化数据中心的能耗。我们的工作与现有研究的不同之处在于,在虚拟机请求放置过程中考虑了它们之间的亲和关系。本研究考虑了虚拟机在不同维度上的资源需求,并据此选择合适的物理机。此外,该工作还致力于使用较少的物理机来承载虚拟机请求,从而降低数据中心的能耗。
7 结论
研究了一种考虑虚拟机部署过程中网络亲和性的新型EENAAVMP算法。该算法还倾向于减少活动物理机数量,从而降低数据中心的能耗。通过cloudsim工具包对该算法进行了评估,并将结果与标准的首次适应贪心算法进行比较。结果表明,所提出的算法优于首次适应贪心算法,通信开销降低了15%,能耗比标准的非功耗感知贪心算法降低了5%。

















 45
45

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









