




 本文介绍了损失函数的基本概念,包括其在评估预测准确性中的作用,并详细解释了几种常见的损失函数类型,如log对数损失函数、平方损失函数等。此外,还讨论了如何利用损失函数和正则化项来构建结构风险函数,以避免过拟合。
本文介绍了损失函数的基本概念,包括其在评估预测准确性中的作用,并详细解释了几种常见的损失函数类型,如log对数损失函数、平方损失函数等。此外,还讨论了如何利用损失函数和正则化项来构建结构风险函数,以避免过拟合。
损失函数(loss function)是用来估量你的预测试f(x)与真实值Y的差别,它是一个非负实值函数,损失函数越小,模型就越好,损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。
通过损失函数我们可以得到单个样本点的预测能力,对于训练样本中的所有数据进行预测,得到的是经验风险,结构风险是在经验风险的基础上加入表示模型复杂度的正则化项(罚项)
结构风险函数:
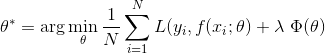
前面为经验风险函数,后面为正则化项(L1或者L2)。经验风险越小,模型决策函数越复杂,包含的参数越多,拟合效果越好,但是容易出现过拟合,所以引入正则化项来防止过拟合的出现,经验风险目的是求最小化,正则化目的也是求最小化,两者相加就是结构风险函数。
常见的损失函数
一 log对数损失函数(逻辑回归)
逻辑回归的损失函数不是平方损失,而是log损失函数。
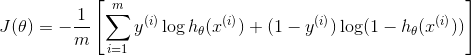
二 平方损失函数(最小二乘法)
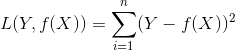
三 对数损失函数(Adaboost)
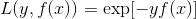
其他还有:0-1损失函数,绝对值损失函数等等

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









