




目录
传统机器学习方法一般分为:1.准备数据(略);2.数据预处理方法;3.特征工程方法;4.建立模型方法;5.模型评估方法;6.模型优化方法;7.模型的保存和调用
Step1:数据预处理
1.1:将非数值型数据转化为数值型数据
1.文本类:TF-IDF(数字)
2.嵌入表示:word2vec(向量)
3.频率编码:按照类别出现的频率编码(数字)
4.独热编码:容易出现维度过高(向量)
5.词袋模型(n-gram)(向量)
6.标签编码:["差","良","中等","优秀"]等有顺序的编码为[1,2,3,4](数字)
1.2:数据集成以及数据的缺失值、重复值处理
将不同来源的数据集成到一起组成新的数据集合
1.3:特征数据归一化
1.最小-最大归一化:
2.Z-score归一化:
1.4:Box-Cox变换,变换函数分布
Box-Cox变换是Box和Cox在1964年提出的一种广义幂变换方法,是统计建模中常用的一种数据变换,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。Box-Cox变换的主要特点是引入一个参数,通过数据本身估计该参数进而确定应采取的数据变换形式,Box-Cox变换可以明显地改善数据的正态性、对称性和方差相等性,对许多实际数据都是行之有效的
1.5:处理类别不平衡的问题
类别不平衡是一个常见的问题,例如在一个分类问题中,90%的类别属于A,10%的类别属于B,那么样本A,B的类别就是不平衡的。
常见的方法:
1.过采样(增加少数类别样本的数量)和欠采样(减少多数类别样本的数量)
详细介绍:
过采样:SMOTE:选择少数类别样本的K个最相近邻,然后在这些邻居之间插值生成新的样本;ADASYN:类似于SMOTE,但是更关注于生成那些距离决策边界较近的少数类别样本。
欠采样:聚类欠采样:对多数类别样本进行聚类,使用聚类中心为代表,从而减少样本数;随机欠采样:随机删除多数类别的样本,使其数量减少与少数类别相当。
2.数据合成数据
3.模型选择 等等
1.6:训练数据划分:交叉验证
step1:如下图所示,将数据集划分为四份之后(1,2,3,4)
step2:将模型按照下列方式训练和预测:1 2 3训练去预测4;1 2 4训练去预测3;1 3 4训练去预测2;2 3 4训练去预测1step3:将1 2 3 4的预测结果堆叠起来就是最终结果
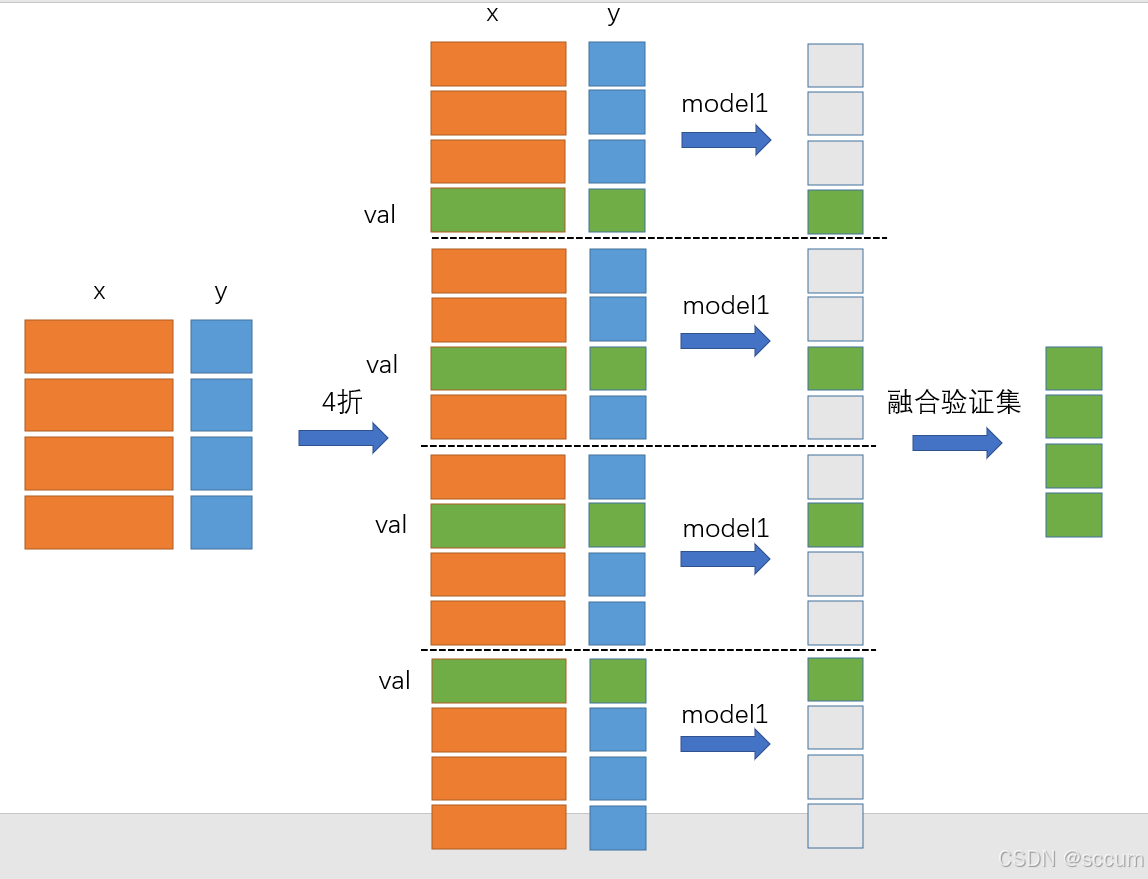
'''一直都能听说到这个概念,重要性不用多说,交叉验证就是假设现在将整个训练集分割成了10组数据,拿其中的9组来训练,其中的一组来验证'''
#k折交叉验证 分为5折来进行交叉验证
from sklearn.model_selection import StratifiedKFold, KFold
import numpy as np
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
y = np.array([0, 1, 0, 1, 0])
folds = 5
seed = 1
kf = KFold(n_splits=5, shuffle=True, random_state=0)
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
#这里kf.split(x)会返回一个生成器,每次都生成一个 (train_index, test_index) 对
'''
result:
TRAIN: [0 1 3 4] TEST: [2]
TRAIN: [1 2 3 4] TEST: [0]
TRAIN: [0 2 3 4] TEST: [1]
TRAIN: [0 1 2 4] TEST: [3]
TRAIN: [0 1 2 3] TEST: [4]
'''
'''
在进行交叉验证之后,对检验的结果取平均值来观察整体的模型性能评价
'''1.7:数据集过少的问题
1.数据增强:
####注意:数据增强(Data Augmentation)是一种技术,通过对原始数据进行各种变换和扩展来生成更多的训练数据。这可以帮助提高机器学习模型的泛化能力,尤其是在数据量不足的情况下。数据增强的目标是通过人为地增加训练数据的多样性,来使模型更好地学习数据的本质特征,并提升其在新数据上的表现。
1.1、如果是图像数据类型,通过对图像的旋转,翻转,调整亮度来生成新的数据
1.2、如果是文本型数据类型,通过对同义词替换,文本插入等生成新的数据
2.使用预训练模型:用小数据集在预训练模型上进行微调
3.合成数据等
Step2:特征工程
2.1:特征运算构造新的特征(特征的加减乘除等)
1.在house-pricing的竞赛例题,可以利用 陈旧度 = (出售年份 - 建筑年份)来构造新的特征
2.在kaggle主页,特征工程学习的一栏中,比率=某一个特征/某一个特征 来构造新的特征
2.2:筛选特征:
2.2.1:根据互信息筛选
互信息(Mutual Information, MI)是信息论中的一个基本概念,用于度量两个随机变量之间的依赖关系。具体来说,互信息量化了一个变量的知识减少另一个变量的不确定性的程度。它是一种非参数化的方法,能够捕捉非线性关系。
结论:互信息越强,变量和target的依赖越强
from sklearn.feature_selection import mutual_info_classif
mi = mutual_info_classif(X, Y, discrete_features=True)
####discrete_features=True表示输出特征是离散的,默认值是False2.2.2:剔除训练数据集和测试数据集中分布不一致的特征
2.2.3:PCA降维
PCA降维是一项重要的技术:
得到的特征向量就是
的系数,将特征值按照从大到小排序之后,单个特征值占整体比例就是各个解释变量
的占比
from sklearn.decomposition import PCA #主成分分析法
pca = PCA(n_components=0.9)
pca.fit(train_df_update6)
train_df_update6_pca = pca.transform(train_df_update6)
test_df_update6_pca = pca.transform(test_df_update6)
'''注意:对于训练集和测试集的转换,要用同一个fit的pca,train_df_update6_pca和test_df_update6_pca就是转换后的数据,也就是特征向量拟合好了'''Step3:建立模型
from sklearn.ensemble import BaggingClassifier,GradientBoostingClassifier,StackingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np3.1:Bagging
Bagging 是一种通过并行训练多个模型来减少模型的方差。每个模型在从训练数据的随机子集中训练,最终通过平均(回归问题)或投票(分类问题)来获得预测结果
工作原理:
1.从原始训练数据集中通过自助抽样(bootstrap sampling)生成多个子集。
2.在每个子集上训练一个模型。
3.对所有模型的预测结果进行平均(回归)或投票(分类)以得到最终预测。
#### 加载数据集
data = datasets.load_wine()
X,y = data.data,data.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)
#### 模型评估方法:准确率
def accuracy(y_test,y_pred):
result = (np.array(y_pred) == y_test).sum() / len(y_test)
return result
#分类问题
bagging_clf = BaggingClassifier(
estimator=DecisionTreeClassifier(), # 基础模型
n_estimators=10, # 基础模型的数量
max_samples=0.5, # 每个基础模型的样本数量(比例)
max_features=0.5, # 每个基础模型的特征数量(比例)
bootstrap=True, # 是否有放回抽样
bootstrap_features=False, # 是否对特征进行有放回抽样
)
bagging_clf.fit(X_train, y_train)
y_pred = bagging_clf.predict(X_test)
result = accuracy(y_test,y_pred)
print(result)3.2:Boosting
Boosting 是一种串行训练模型的方法,通过逐步训练模型并调整每个模型的权重来降低模型的偏差。每个模型在前一个模型错误的基础上进行训练,从而逐步提升整体性能。
1.首先训练一个基模型。
2.对于每个后续模型,增加前一个模型错误样本的权重。
3.最终将所有模型的预测结果加权平均。
# 创建 Gradient Boosting 模型
boosting = GradientBoostingClassifier(n_estimators=100, random_state=42)
# 训练模型
boosting.fit(X_train, y_train)
# 预测
y_pred = boosting.predict(X_test)
# 模型评估
result = accuracy(y_test,y_pred)
print(result)3.3:Stacking
Stacking 是一种集成学习方法,通过将多个模型的预测结果作为特征输入到一个新的模型中,结合了多个模型的优点。
step1:用(x0,y0)训练多个基模型(第一层模型)。
step2:使用这些基模型的预测结果作为新特征(x1),用(x1,y0)训练一个二级模型(元模型或融合模型)。
step3:按照step1和step2的顺序就可以构造一个model
# 创建基础模型
base_models = [
('svc', SVC(probability=True, kernel='linear')),
('lr', LogisticRegression())
]
# 创建 Stacking 模型
stacking = StackingClassifier(estimators=base_models, final_estimator=LogisticRegression(), cv=5)
# 训练模型
stacking.fit(X_train, y_train)
# 预测
y_pred = stacking.predict(X_test)
# 模型评估
result = accuracy(y_test,y_pred)Step4:模型评估
4.1:选择不同的损失函数来合理地评估模型
Step5:模型调优
from sklearn.datasets import load_wine
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from scipy.stats import randint5.1:网格法搜索调参
'''
网格搜索算法:**网格搜索(Grid Search)**是一种超参数优化技术,用于找到机器学习模型的最佳超参数组合。
它通过系统地遍历给定的参数值范围,评估每个参数组合在验证集上的性能,最终选择表现最好的参数组合。
网格搜索的基本思想是构建一个"网格",其中每个格子代表一种参数组合,然后逐个尝试这些组合以找到最优解
'''
# 加载数据集
wine = load_wine()
X, y = wine.data, wine.target
# 创建一个支持向量机分类器
model = SVC()
# 定义超参数网格
param_grid = {
'C': [0.1, 1, 10, 100],
'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],
'gamma': [0.001, 0.01, 0.1, 1]
}
# 使用GridSearchCV进行网格搜索
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
# 输出最佳参数和最佳得分
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳得分: {grid_search.best_score_}")5.2:随机搜索算法调参
随机搜索算法:
随机搜索(Random Search)是一种用于超参数优化的算法,其主要目的是在给定的超参数空间内随机地选择一组超参数组合进行模型训练,并评估模型的表现。
与网格搜索不同,随机搜索不会遍历所有可能的超参数组合,而是从指定的分布中随机抽取超参数值,这样可以在更广泛的超参数空间内找到较好的结果,并且通常比网格搜索更高效。随机搜索的基本步骤
1.定义超参数空间:确定超参数的范围和可能的值。
2.随机选择组合:从定义的超参数空间中随机选择多个超参数组合。
3.模型训练和评估:对每一个随机选择的超参数组合,训练模型并评估其性能。
4.选择最佳超参数:选择具有最佳性能的超参数组合作为最终模型的超参数。
'''
# 加载数据
wine = load_wine()
X, y = wine.data, wine.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
# 定义要优化的超参数范围
param_distributions = {
'n_estimators': randint(10, 100),
'max_depth': randint(1, 20),
'min_samples_split': randint(2, 20)
}
# 创建模型
model = RandomForestClassifier()
# 创建 RandomizedSearchCV 对象
random_search = RandomizedSearchCV(
estimator=model,
param_distributions=param_distributions,
n_iter=50, # 进行 50 次随机搜索
cv=5, # 5 折交叉验证
scoring='accuracy',
random_state=42
)
# 训练模型
random_search.fit(X_train, y_train)
# 输出最佳超参数
print(f"Best parameters: {random_search.best_params_}")
# 使用最佳模型进行预测
best_model = random_search.best_estimator_
y_pred = best_model.predict(X_test)
# 评估模型
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
5.3:正则化避免过拟合
5.4:调整归一化函数
Step6:模型保存和模型调用
模型保存:确保训练好的模型可以在需要时快速加载、重用和分享,节约计算资源,保证模型一致性,便于模型的部署和版本控制。
模型调用:提供快速预测的能力,支持实时系统、持续集成、模型更新以及模型调试等工作,使得模型能够在实际应用中发挥作用。

















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









