




问题1:为什么要分块?
在基于 Transformer 架构的向量化模型中,每个词汇都会被映射为一个高维向量。为了表示整段文本的语义,通常采用对词向量取平均,或使用特殊标记(如 [CLS])位置的向量作为整体表示。
- 然而,当直接对过长的文本进行向量化时,会面临以下挑战:
- 语义信息稀释:长文本往往涵盖多个主题或观点,整体向量难以准确捕捉细节语义,导致语义信息被稀释,无法充分体现文本的核心内容。
- 计算开销增大:处理长文本需要更多的计算资源和存储空间,增加了模型的计算复杂度,影响系统的性能和效率。
- 检索效率降低:过长的向量在检索过程中可能会降低匹配精度,导致检索结果的相关性下降,同时也会降低检索的速度和效率。
问题2:分块前要注意什么?
分块前要做的一件事是指代消解
问题3:分块的方法有哪些?
3.1 固定大小块的分割方法
常见方法: LangChain 提供了 RecursiveCharacterTextSplitter,其中包含Overlap
使用示例:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50,
length_function=len,
separators=["\n", "。", ""]
)
text = "..." # 待处理的文本
texts = text_splitter.create_documents([text])
for doc in texts:
print(doc)原理:
- 初步切分:使用第一个分割符(如
"\n",表示段落分隔)对文本进行初步切分。 - 检查块大小:如果得到的文本块长度超过了
chunk_size,则使用下一个分割符(如"。",表示句子分隔)进一步切分。 - 递归处理:依次使用剩余的分割符,直到文本块长度符合要求或无法再切分。
- 合并块:如果相邻的文本块合并后长度不超过
chunk_size,则进行合并,确保块的长度尽可能接近chunk_size,同时保留上下文完整性。
3.2 句子级别分割方法
按照句子级别进行划分、略
3.3 Late-chunking分割方法
常规的RAG文本切块如左下图所示,先进行文本切分,分别过Transformer处理,通过meaning pooling得到每个chunk的句向量。
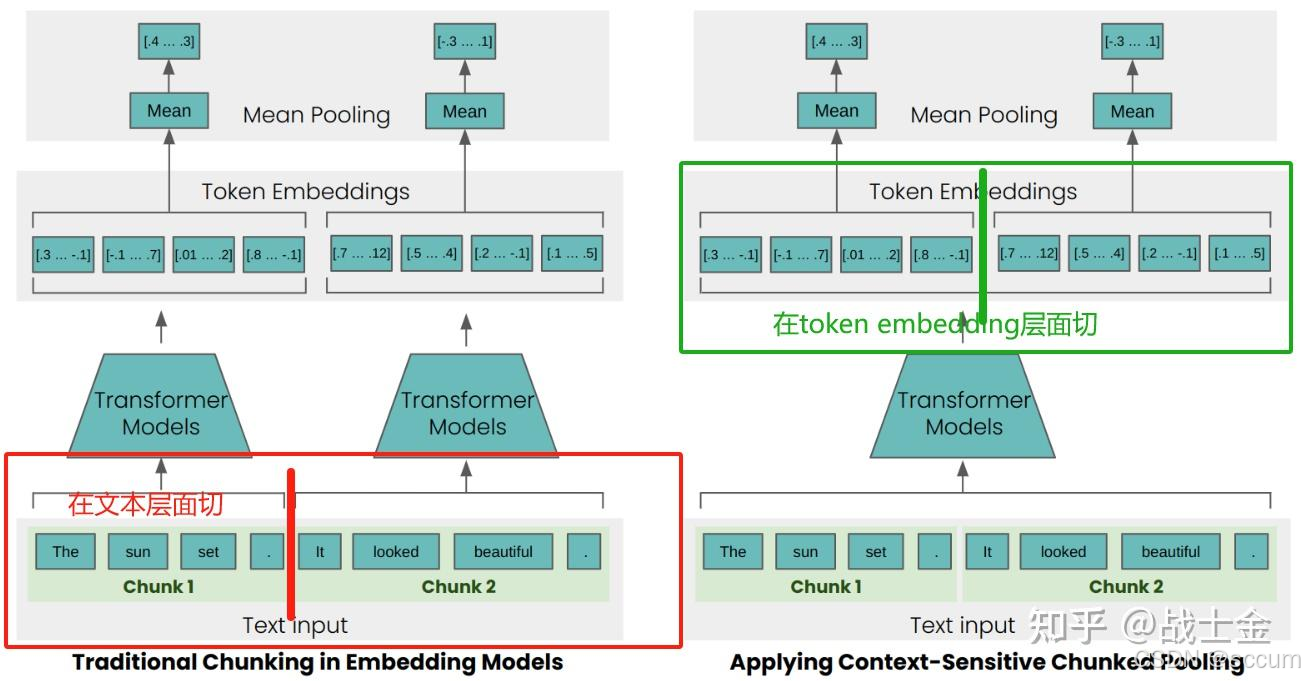
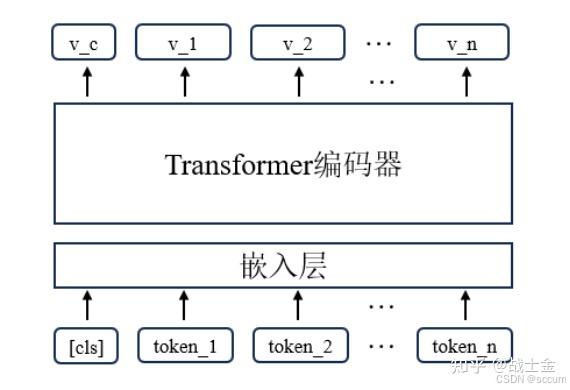
transformer最终输出的是每个token的embedding,如下所示。如果想用一个embedding对整个句子进行表征,主要有两大流派(Transformer encoder架构),一派是对所有token的embedding取平均;另一派是用[CLS]位置的token embedding表示句子,因为大部分文本向量化模型是双向注意力的,[CLS]位置的embedding能感知到全局文本信息。
某一个模型到底是用CLS embedding表示句子,还是用所有token embedding的平均值表示句子是由训练时候决定,并不能随意切换。如果一个模型在训练时用CLS embedding表示句子,那么推理时用所有token embedding平均表示句子效果会非常差。目前使用CLS embedding表示句向量的模型占大多数,比如被大家广泛使用的BGE、BCE模型等。只有少部分模型,比如GTE系列的个别模型、JINA的模型等才用mean pooling token embedding的方式表征句子。而late chunking技术只有那些用mean pooling token embeding表征句子的模型才能用。
Late Chunking技术需要先对文本进行embedding,再进行分段,因此比常规的文本向量化需要模型有更强的长文本处理能力。
3.4 自定义分隔符分割方法
在构建需求文档时手动添加分隔符,进而进行分割,略
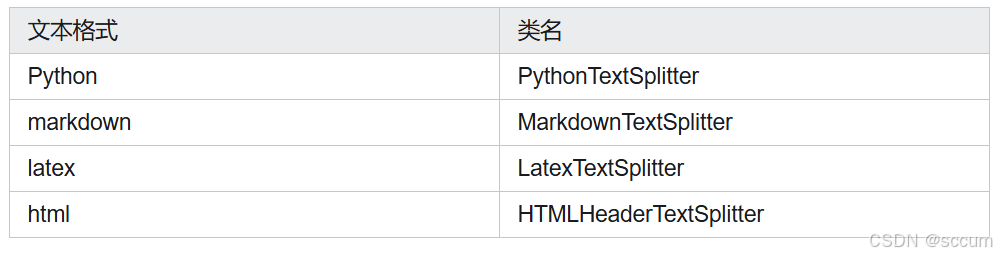
3.5 特定文档(Markdown、Word)分割
LangChain 为用户提供了针对多种特殊格式文本的切块类,方便用户处理不同类型的文本。


















 1593
1593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









