




 本文介绍了Word2Vec的原理,包括词嵌入、Skip-gram模型、分层Softmax和负采样等关键概念。通过词向量的训练,可以捕捉词与词之间的关系,实现类比操作。文章还讨论了在大规模数据下优化训练的策略,如分层Softmax和负采样方法。
本文介绍了Word2Vec的原理,包括词嵌入、Skip-gram模型、分层Softmax和负采样等关键概念。通过词向量的训练,可以捕捉词与词之间的关系,实现类比操作。文章还讨论了在大规模数据下优化训练的策略,如分层Softmax和负采样方法。
什么是Word2Vec
目录
- 词嵌入(word(word(word embedding)embedding)embedding)
- 词嵌入的特点
- 嵌入矩阵
- Skip−gramSkip-gramSkip−gram模型
- 分层SoftmaxSoftmaxSoftmax (Hierarchical(Hierarchical(Hierarchical Softmax)Softmax)Softmax)
- 负采样
- 其他细节
词嵌入(word(word(word embedding)embedding)embedding)
简单来说,embeddingembeddingembedding就是用一个低维的向量表示一个词。在词向量提出之前,人们经常采用oneoneone hothothot encodingencodingencoding对词语进行编码。但由于oneoneone hothothot encodingencodingencoding的维度等于词语的总数,比如阿里的商品oneoneone hothothot encodingencodingencoding的维度就至少是千万量级的。这样的编码方式对于商品来说是极端稀疏的,而深度学习的特点以及工程方面的原因使其不利于稀疏特征向量的处理,因此,如果能把物体编码为一个低维稠密向量再喂给神经网络,自然是一个高效的基本操作,词嵌入应运而生。
词嵌入的特点
词向量中的值并不是随意给出的而是经过训练得到的,是可以表示一定特征的,所以两个词向量之间的距离可以表示两个词相似的程度;词向量还可以进行类比操作。比如已知manmanman类比于womanwomanwoman,问kingkingking类比于什么,显然我们知道是queen(王后)queen(王后)queen(王后),如果用词向量,manmanman与womanwomanwoman是向量空间的两个点,两者连成一个向量应该和kingkingking这个点与未知点所连向量是相等向量(或者相差很小),我们可以遍历一下,便最终可以得到queenqueenqueen这个点。这就是词向量的类比操作。
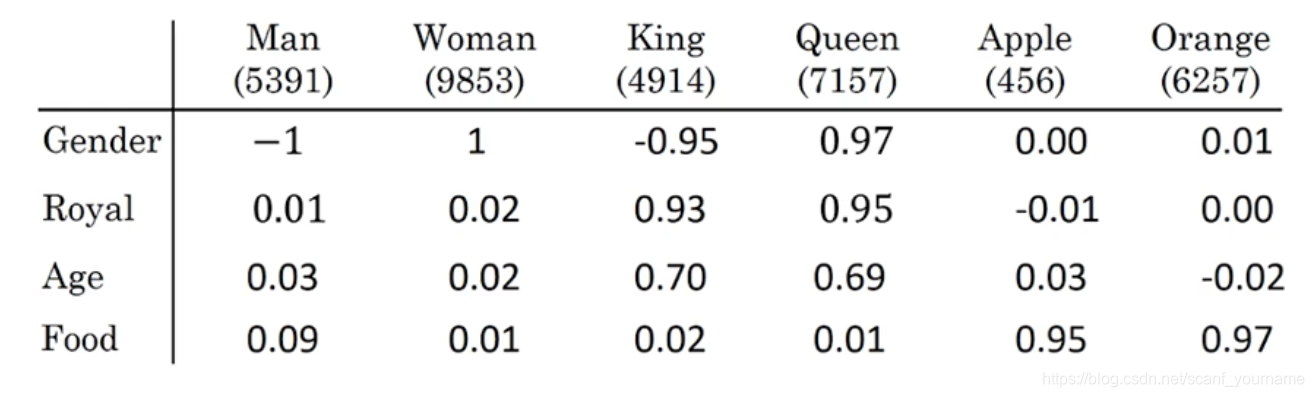
如上图所示,我们假设上面的六个单词经过词嵌入得到了4维向量,词向量每一个维度都可以表现出一定的具体意义,在上图中分别是性别,王室信息,年龄和食物属性。我们对男人女人两个向量做差得到的向量和皇帝与皇后两个向量做差得到向量,相差很小,这就是一种类比关系。
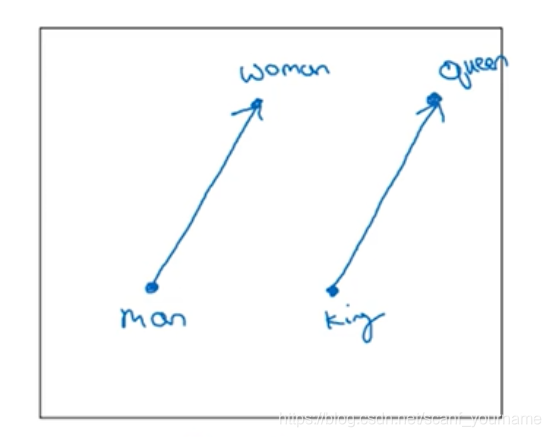
在向量空间中两个向量是平行的。
嵌入矩阵
那么用什么来表示词向量呢?答案是嵌入矩阵。
我们假设在字典中有100001000010000个单词,每一个单词都有一个oneoneone hothothot vectorvectorvector与之对应,这样就有100001000010000个向量与字典中的单词构成一一映射。我们假设我们要经过词嵌入,将这些oneoneone hothothot vectorvectorvector转化成300300300维词向量,那么我们就定义一个10000∗30010000 * 30010000∗300的嵌入矩阵W:
e=xW e =xW e=xW
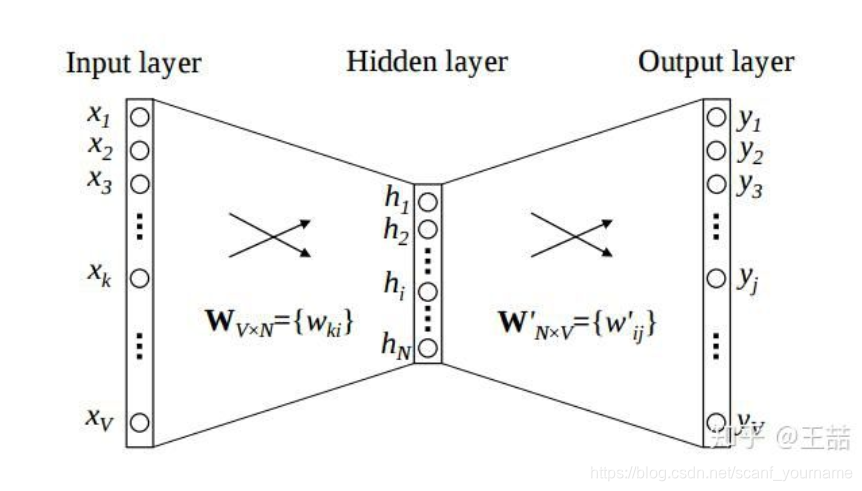
上图神经网络模型中InputInputInput layerlayerlayer代表的是oneoneone hothothot vectorvectorvector而隐藏层(Hidden(Hidden(Hidden layer)layer)layer)则代表词向量,WV∗NW_{V*N}WV∗N则是嵌入矩阵,所以获得词向量的过程就是通过一个神经网络定义损失函数,训练嵌入矩阵的过程。
Skip−gramSkip-gramSkip−gram模型
- Skip−gramSkip-gramS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









