






本篇文章记录本人对实验中各个板块的理解以及踩坑, 如果您发现我过多的涉及到了实验的内容, 有违学术诚信, 请告诉我!
正文
project4整体实现了一个OCC版本的MVCC, 即乐观版本的多版本并发控制为事务提供支持。
- Task1要求实现时间戳和水印;
- Task2要求元组重构方法和撤销日志收集方法, 以及重构project3中实现的SeqScan执行器。
- Task3要求实现MVCC执行器, 分成一个个小任务就是:重构insert、delete、Update执行器, 实现Commit提交操作, Undolog生成和更新函数、 垃圾回收机制。
- Task4引入主键, 并实现主键更新和插入
- Bonus1为abort事务回滚, Bonus2为Serializable Verification序列化验证。
Task1
首先要看一下读取时间戳到底怎么工作。 对于事务来说, 事务有一个事务id, 一个读取时间戳, 一个提交时间戳。 事务被创建时, 会被事务管理器分配一个递增的事务id,用来唯一标记事务, 这个事务管理器就是DBMS里面管理所有事物的对象。 事务启动时, 也会被分配一个读取时间戳,这个读取时间戳是整个全局中, 上一个事务的提交时间戳。 而提交时间戳, 同样是由事务管理器分配, 并且每次事务提交都会递增, 保证全局唯一。
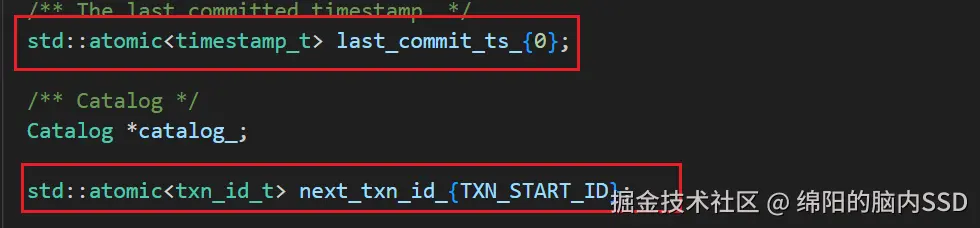
如上图, 每一次有事务提交, 那么last_commits_ts_就会加一, 同时一个事务启动, next_txn_id也会加一。 然后读取时间戳就可以在启动的时候直接赋值last_commit_ts即可。
Task1中需要理解的是watermark水位线。水位线用来判断DBMS中有哪些数据版本不再被所有活跃事务需要。其中current_reads里面包括了当前活跃事务中,读取时间戳与读取时间戳个数的对应关系。如果获取水位线, 那么就返回current_reads中的最小值, 如果current_reads中没有数据, 直接返回。
我需要做的就是, 在Commit函数中, 提交时间戳加一,并将事务的提交时间戳设置为该时间戳。然后更新水位线中的commits设置为提交时间戳。最后要移除水位线中的该事务read_ds计数。在Begin函数中设置read_ds即可。
Task2
Task2的主要任务有两个, 一个是元组重构方法Reconstruct、一个是重构顺序扫描方法SeqScan。
Reconstruct
理解元组重构就要先理解undolog。undolog就是将元组改变前和改变后的“差异“保存下来, 比如当T1将A的四列元组改变了两列, 则将:改变了哪些列、改变之前该列的值、该槽位的版本链、当前事务的事务ID保存为一个undolog(撤销日志), 然后将这个撤销日志保存到当前的事务里面, 并将该撤销日志添加到对应槽位的版本链中。注意该版本连由当前DBMS的事务管理器维护。就是下图中的version_map:
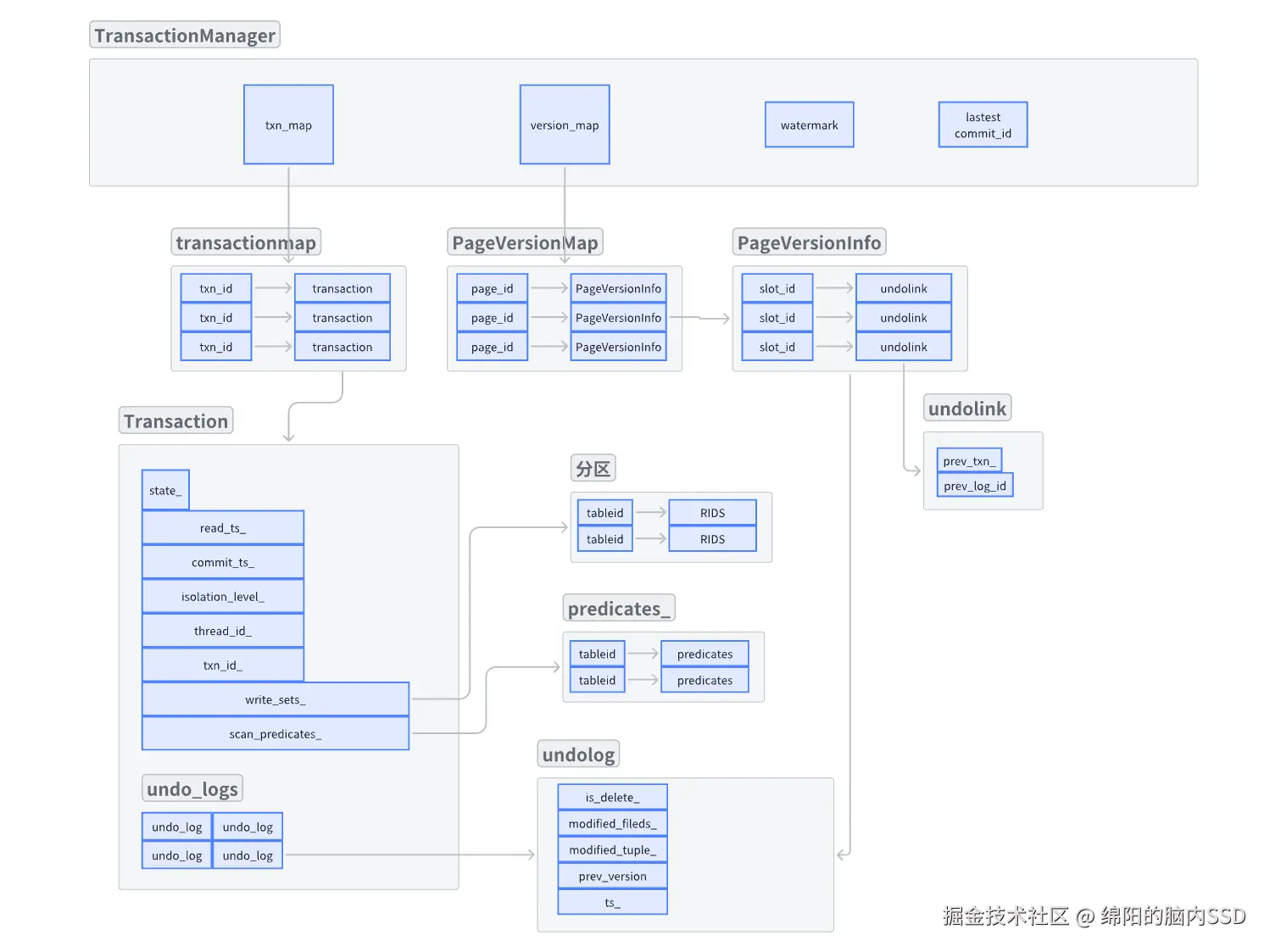
Reconstruct就是拿到一组撤销日志(undolog), 根据undolog中的差异, 将basetuple恢复成旧元组并返回。
具体实现细节就是:
- 如果undolog的is_delete标记为true, 说明旧元组为空,那么就构建一个空tuple。
- 否则依次根据拿到undolog中的差异列的值, 和无差异列的值。 构建出一个旧元组。 最后遍历整个”undo_logs", 直到遍历完为止。
SeqScan
我认为SeqScan是所有的算子的基础, 因为除了Insert, 其他的算子的最底层都是SeqScan或者IndexScan。 大部分算子都是从SeqScan拉取数据。 SeqScan中要处理:哪些元组看的见、哪些元组看不见。
因为我之前p3实现的是无MVCC的扫描, 扫描每一个槽位时, 该槽位是什么拿到什么就可以了, 如果为空, 则继续遍历下一个槽位即可。 但是对于MVCC控制的SeqScan, 同样是遍历每一个槽位, 但是每个槽位还要深入遍历它的版本链, 即undolog链。
具体实现细节如下:
-
对于每一个槽位, 先看当前tuple能否看到
- 能看到并且不为空, 就返回; 能看到但是为空, 检查下一个槽位。
-
如果看不到, 那么就检查undolog。
-
一边回溯版本链, 一遍收集undolog, 直到当前undolog能够看到。
- 如果最旧的undolog也看不到, 那么就检查下一个元组。
-
利用收集到的undolog构建旧元组, 返回即可。
这里要注意的是, 文档中说解释了CollectUndolog,并要求实现了。

所以我可以实现该函数,方便SeqScan的编写。
实现流程就是
- 从DBMS的事务管理器中拿到整个该槽位的版本链。
- 遍历整个版本链, 如果看不到, 则加入到“return_undologs(返回undolog数组)”中, 如果能看到,则返回该数组就可。
Task3
Task3要求实现MVCC版本的执行器, 前面实现的SeqScan也是MVCC版本的执行器的一部分, Task3中要求实现Insert、Update、Delete的MVCC版本执行器。 并且要实现一下垃圾回收机制以及提交。
Insert
Insert不需要构建undolog, 因为Insert只是在一个新的槽位插入新元组。 与p3不同的是, 要注意设置该槽位的时间戳为事务ID, 并且要把该槽位的修改记录添加到事务中。
这里不需要注意并发, 因为InsertTuple是在一个新槽位插入数据。 并发冲突只存在一种情况: 多个事务同时向内部插入数据。而InsertTuple本身为原子的, 所以无需注意并发控制。
Commit
关于Commit, 要注意一点就是要先更新事务以及更新元组的提交实践戳。 然后才能更新全局的提交时间戳以及watermark里面的最新提交时间戳commit_ts。 因为对于一个事务,如果先更新了全局提交时间戳, 那么此时另一个事务就会获得这个全局提交时间戳作为read_ts。
另外,Commit一定是原子的, 并且更新元组的提交时间戳一定是原子的。当前一个事务修改了元组后,假如一共修改了几个元组, 但是只更新了一个元组的提交时间戳。 那么另一个新事物, 就永远不能读取这些没有更新提交时间戳的元组了。所以要么Commit完成, 要么没有Commit, 不存在Commit一半的情况。
TxnMgrDbg
TxnMgrDbg就是回溯整个版本链, 对于版本连上的每一个版本, 都要打印出对应的元组。 一直到版本链结束。该函数为辅助调试函数,可以不实现, 但是建议实现, 方便调试。
GenerateNewUndoLog And GenerateUpdateUndoLog
GenerateNewUndoLog和GeenerateUpdateUndoLog用来当Update和delete对元组进行改变时, 保存旧元组与新元组的差异。 保存的方法就是创建undolog, 并将undolog连接到版本链中。
GenerateNewUndolog的参数为basetuple和targettuple, 根据两者构建一个undolog。
GenerateUpdateUndoLog的参数为basetuple、targettuple、undolog。 需要先利用undolog和basetuple构建出旧元组, 然后根据旧元组和targettuple生成新undolog并返回。
具体实现细节如下:
-
GenerateNewUndoLog
- 如果basetuple为空, 那么创建一个undolog的is_delete为true, 并且modifys_filed为schema.columns.size()。 并且每个列对应的modify_value为空。链接版本链后返回即可。
- 如果targettuple为空, 那么创建undolog的is_delete为false, 并且modify_filed为schema.columns.size()。 并且每个对应的modify_value为basetuple对应列的值, 链接版本链后返回。
- 如果两者都不为空, 则遍历两tuple的每一列,标记每一列是否有差异, 并将有差异的列的basetuple对应的列收集起来,构造undolog。
-
GenerateUpdateUndoLog
-
先构造旧元组。
-
然后调用重复一遍GenerateNewUndoLog的逻辑即可。
-
Update And Delete
update和delete在执行主逻辑之前, 我们要检查一下 写写 冲突。

判断条件就是当前要修改的元组的提交时间戳大于自己的读取时间戳, 并且提交时间戳不为自己的事务ID。 那么就说明这个元组要么正在被其他事务修改, 要么已经被其他事务修改并且事务已经提交了。 发生了写写冲突。
- Delete: 当槽位处的提交时间戳为当前的事务ID, 那么更新undolog,直接更新槽位处的元组即可。如果槽位处的提交时间戳为某个已经提交的事务的提交时间戳, 那么就以target为nullptr, 原元组为basetuple构建undolog, 注意要添加写集合与将undolog添加到当前事务中。最后更新当前槽位处元组。
- Update:当槽位处的提交时间戳为当前的事务ID, 那么更新undolog, 并且更新槽位处的元组即可。 如果槽位处的提交时间戳为某个已经提交的事务的提交时间戳, 那么以target为newtuple, 原元组为basetuple创建undolog, 并且更新undolog。然后更新当前槽位元组即可。
需要注意的是更新元组的函数中Check参数填成nullptr即可。 OCC的并发控制不需要加锁, 只需要在需要并发控制时添加一个Check函数即可。
垃圾回收
对于垃圾回收就是回收某个不需要的事务。 如果该事务内部所有的undolog都不会被当前活跃事务看到, 那么该事务以及内部所有的undolog就可以被回收了。
实现策略为:
- 遍历DBMS中所有的已经提交事务, 并将事务修改的table和rid保存下来。
- 遍历所有table以及rid,拿到对应槽位的版本连上面的提交时间戳ts。 查看watermark, 如果存在watermark > ts, 则该时间戳对应的已提交事务不应被回收, 进行标记。
最后回收所有未被标记为不可回收的提交事务。
Task4
Task4引入主键, 并且引入并发控制。
Index Insert
如果存在主键,此时进行插入要考虑插入数据的主键列所对应的Value(以后叫作Key)是否已经存在索引中。 如果已经存在索引中, 则要拿到索引中Key指向的槽位,看看是否槽位处为delete, 如果为delete,则更新该槽位的数据和元数据即可。同时要注意并发控制。如果不为delete, 说明有数据, 那么就是 写写 冲突。
如果不在索引中, 则类似于无主键索引的插入。
并发控制
OCC的并发控制是在提交阶段之前进行验证,验证是否与之前已经提交的事务有 写写冲突。这里要做的就是先拿到该槽位原本的元数据, 将这个元数据作为Check的固定参数。 Check函数就是检查原本的元数据是否与新拿到的元数据是否相同。
Index Scan
Index Scan和SeqScan实现的逻辑相同, 对于每一个元组要检查版本链。
- 如果版本可见并且不为delete, 则返回, 如果版本可见但是delete, 检查下一个槽位。
- 如果版本不可见, 遍历到版本链的下一个位置, 当版本连为末位, 则检查下一个槽位。
Delete、Update并发控制
Task4中我需要重构Delete、Update, 将两者设计为支持并发控制的版本。 我需要改动的地方很少, 只需要类似于Insert设计一个绑定了元组元数据的可调用对象作为Check即可。 并且Check内部逻辑为比较新的元数据是否与旧的元数据是否相同。
我这里理解的意思就是, 当前事务在修改该槽位的过程中, 如果其他事务已经对该槽位进行了修改, 即便没有提交。此时就类似于当前事务正在修改一个已经被修改的元组,该元组不应该被当前事务可见, 相当于刚刚进入函数时写写冲突的判断, 直接设置abort退出即可。
主键更新
主键更新分为三种情况, insert、delete、update。
- insert时如果新元组的索引列对应的Value不存在主键索引中,还需要将Value添加到索引中。 并指向新的RID。
- delete时对于主键列不进行删除。
- update时, 如果主键更改, 那么要先将所有更改的元组删除, 然后再将所有新元组添加。这里删一个插入一个的话, 会导致新插入的元组与已经存在的元组索引列冲突, 出现逻辑错误。
Bonus 1
发生写写冲突后, 调用abort函数回滚。
遍历该事务的写集合, 拿到每个槽位。 拿到槽位对应的元组。 此时会有三种情况:
-
如果槽位没有版本链, 说明该事务在该槽位进行了插入, 则将该位置设置为delete。
- 否则为delete或者update。 拿到undolog, 重构tuple并进行滚滚即可。 即利用tuple更新槽位即可。
Bonus 2
检查每一个槽位, 以及槽位对应的版本链; 对于序列化来说, 要保证事务读取元组的顺序和事务按照启动顺序序列化执行结果相同。快照隔离的实现中已经处理 写 - 写冲突 。 所以要保证序列化, 就要处理 写倾斜 。
所以要认识什么是写倾斜, 下面是关于写倾斜的理解, 对比 写写冲突 来理解:
-
写 - 写冲突 :事务T1正在修改表1中的第三行, 事务T2稍后启动, 也想要修改表1中的第三行。 此时T1尚未提交, 或者已经提交但T1.commit_ts > T2.read_ts, T2直接abort。
-
写倾斜 :写写冲突是针对同一行, 写倾斜则是针对不同行。 假如一个表中有四行数据:
-
col1 | col2 | 1 | 0 | | 1 | 0 | | 0 | 0 | | 0 | 0 | - 现在T1想要将col1全部设置为0, T2想要将col!全部设置为1。 T1先执行 -> "update t1 set col1 = 0 where col1 != 0; 然后底层seq_scan执行器通过遍历 + 过滤读取到了第一二行元组。元组通过管道回传给上层 update执行器。然后执行器更新了表中的第一二行。 然后T2执行 -> "update t1 set col1 = 1 where col1 != 1" , 由于T1未提交, 所以表中的一二行被锁定,T2的seq_scan执行器只能读取到第三四行元组并且交给update执行器, 然后update执行器更新三四行。 最后的表中的结果就如下:
-
col1 | col2 | 0 | 0 | uncommited -> modified by T1 | 0 | 0 | uncommited -> modified by T1 | 1 | 0 | uncommited -> modified by T2 | 1 | 0 | uncommited -> modified by T2 - 但是我们想要的是什么呢? 我们想要的是先执行T1, 然后T1把表中所有数据修改为0, 然后执行T2, T2把表中所有数据修改为1, 最后表中的数据应该全都为1:
-
col1 | col2 | 1 | 0 | | 1 | 0 | | 1 | 0 | | 1 | 0 |
-
处理写倾斜
了解了实现序列化要解决写倾斜的问题。 然后下面具体谈如何处理写倾斜。
我们从上面的例子中就能看到, 其实写倾斜发生的条件就是在T1的修改的元组里面, 有些元组其实满足了T2的过滤条件, 但是由于uncommited, 所以无法被T2修改。 此时T1先执行,能够正确修改, 但是T2因为uncommited不能正确修改, 有写倾斜。 所以如何判断写倾斜? 就是判断可能冲突的事务修改的元组里面, 如果有能够被我们正在判断的事务所成功过滤的, 但是又因为uncommited, 所以没有读取到的这些元组。 那么就是发生了写倾斜。
我们处理的验证逻辑就是, 在提交的时候判断是否与序列化的结果一致。 因为如果冲突事务T2修改过某个元组, 并且这个元组符合检查事务T1的过滤条件, 又uncommited无法被检查事务T1读取, 那么就不符合序列化。
- 所以在提交阶段, 先拿到所有的冲突事务。即uncommit的事务。
- 判断每一个冲突事务的修改过的元组(写集合), 是否满足检查事务的过滤条件。
- 如果满足, 说明发生写倾斜,事务中止。 如果所有的元组都不满足, 则说明没有发生写倾斜, 可以正常提交。

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









