




一、Pulsar 简要介绍
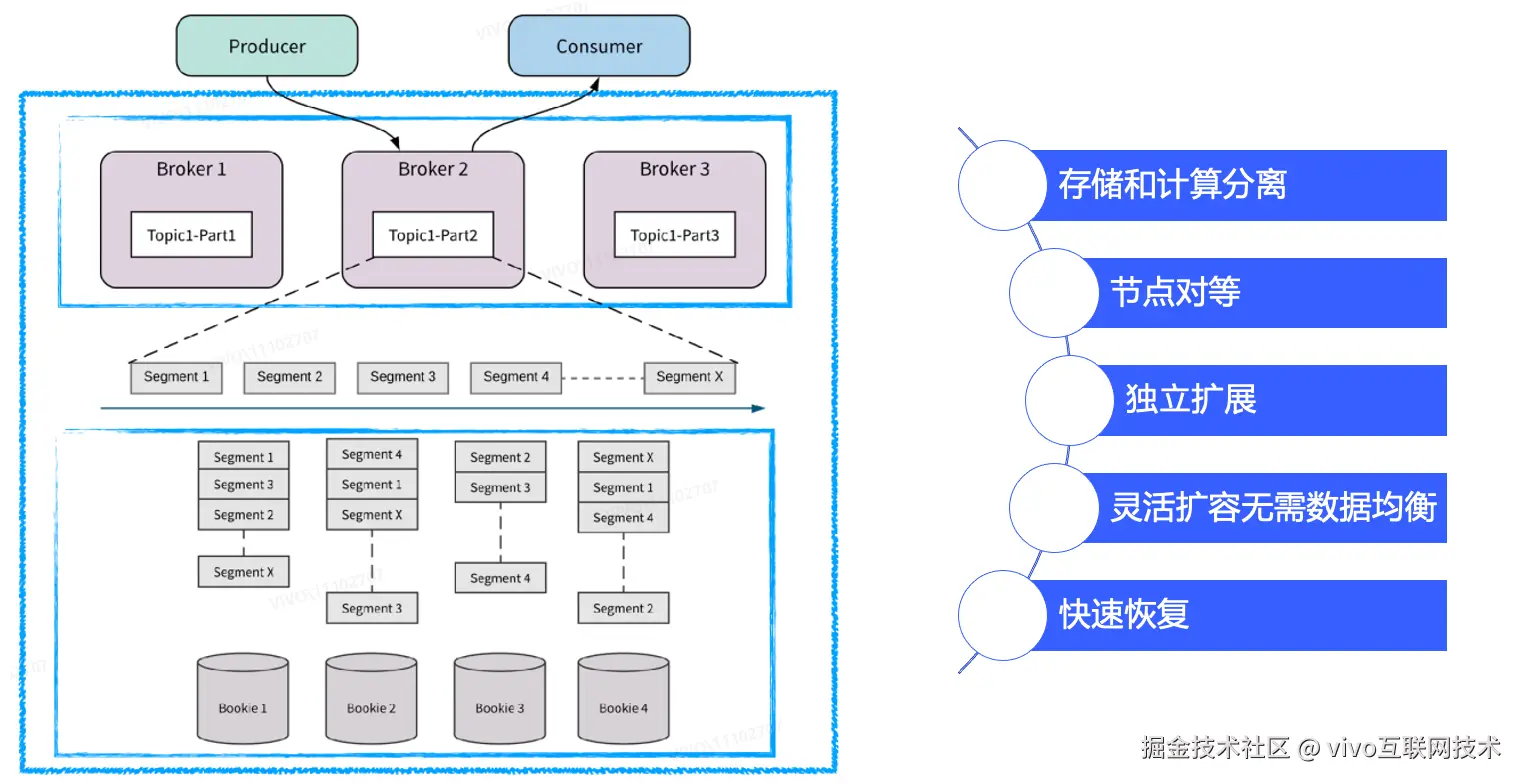
Pulsar是新一代的云原生消息中间件,由Apache软件基金会孵化和开源。它的设计目的是为了满足现代数据处理和计算应用程序对可扩展性、可靠性和高性能的需求,具备存储与计算分离、节点对等、独立扩展、实时均衡、节点故障快速恢复等特性。
Pulsar由四个核心模块组成:broker、bookKeeper和client(Producer和Consumer)、zk(元数据管理和节点协调)。broker接受来自Producer的消息,将消息路由到对应的topic;bookKeeper用于数据持久化存储和数据复制;Consumer消费topic上的数据。Pulsar支持多种编程语言和协议(如Java、C++、Go、Python等),可以运行在云、本地和混合环境中,扩展性好,支持多租户和跨数据中心复制等特性。因此,Pulsar被广泛应用于云计算、大数据、物联网等领域的实时消息传递和处理应用中。
二、Pulsar Producer解析
首先需要了解Producer的数据发送流程,这里以“开启压缩、batch发送消息给partitioned topic“这样的一个线上常规场景为例,解析数据的发送的关键环节。
tips:
在Pulsar中有无分区(Non-Partitioned)Topic 和有分区 (Partitioned) 的 Topic之分,Partitioned topic最小分区数为1,为满足任务的拓展性,在线上一般使用Partitioned topic。
2.1 消息生产与发送的详细流程

Producer发送数据主要分为12个步骤:
① 创建Producer:
partitioned topic创建的是一个Partitioned-
ProducerImpl对象,该对象包含了所有分区及其对应的ProducerImpl对象,ProducerImpl对象负责所对应分区数据的维护和发送。
② 构造消息:
一条消息被发送前首先会被封装成为一个Message对象,对象中包含了所发送的topic name、消息体、消息大小、schema类型、metadata(是否指定key等)等信息。
③ 确定目标分区:
在发送消息前需要通过路由策略决定发往哪一个分区,选择对应分区的ProducerImpl对象进行进一步处理。
④ 拦截器:
Producer可以设置自定义的拦截器,拦截器需要实现producerInterceptor接口,在消息发送前可对消息进行拦截修改。
⑤ 消息堆积控制:
Producer可以处理的消息是有限的,接收新的消息时会分别进行信号量和内存使用率校验,控制接收消息的速率,防止消息无限在本地堆积。
⑥ batch容器管理:
默认情况下分好区的消息不是直接被发送,而是放入了生产者的一个batch缓存容器中里面。在这个缓存里面,多条消息会被封装成为一个批次(batch)。
⑦ 消息序列化:
Pulsar 的消息需要从客户端传到服务端,涉及到网络传输,因此Producer将batch缓冲区中的所有消息逐一进行序列化。
⑧ 压缩:
Pulsar内置了多种压缩算法,在发送前会根据所选择的压缩算法对batch整体进行压缩,这将优化网络传输以提高Pulsar消息传输的性能。
⑨ 构建消息发送对象:
无论是开启batch的批次消息,还是关闭batch的单条消息,都会被包装为一个OpSendMsg对象,OpSendMsg也是Producer发送和pulsar broker接收处理的最小单位。
⑩ pending队列:
所有构建好的OpSendMsg在发送前都会被放入pendingMessages队列中,消息处理完成后才会从队列中移除。
⑪ 消息传输:
Pulsar 使用netty将消息异步的从客户端发送到服务端,Broker节点将在收到消息后对其进行确认,并将其存储在指定主题的持久存储中。
⑫ 响应处理:
Pulsar Broker 在收到消息时会返回一个响应,如果写入成功,消息将会从pendingMessages队列中移除。如果写入失败,会返回一个错误,生产者在收到可重试错误之后会尝试重新发送消息,直到重试成功或超时。
2.2 关键环节原理分析
接下来会对上述流程中关键环节的设计和原理作进一步的剖析,帮助读者更好的理解Producer。
2.2.1 创建Producer
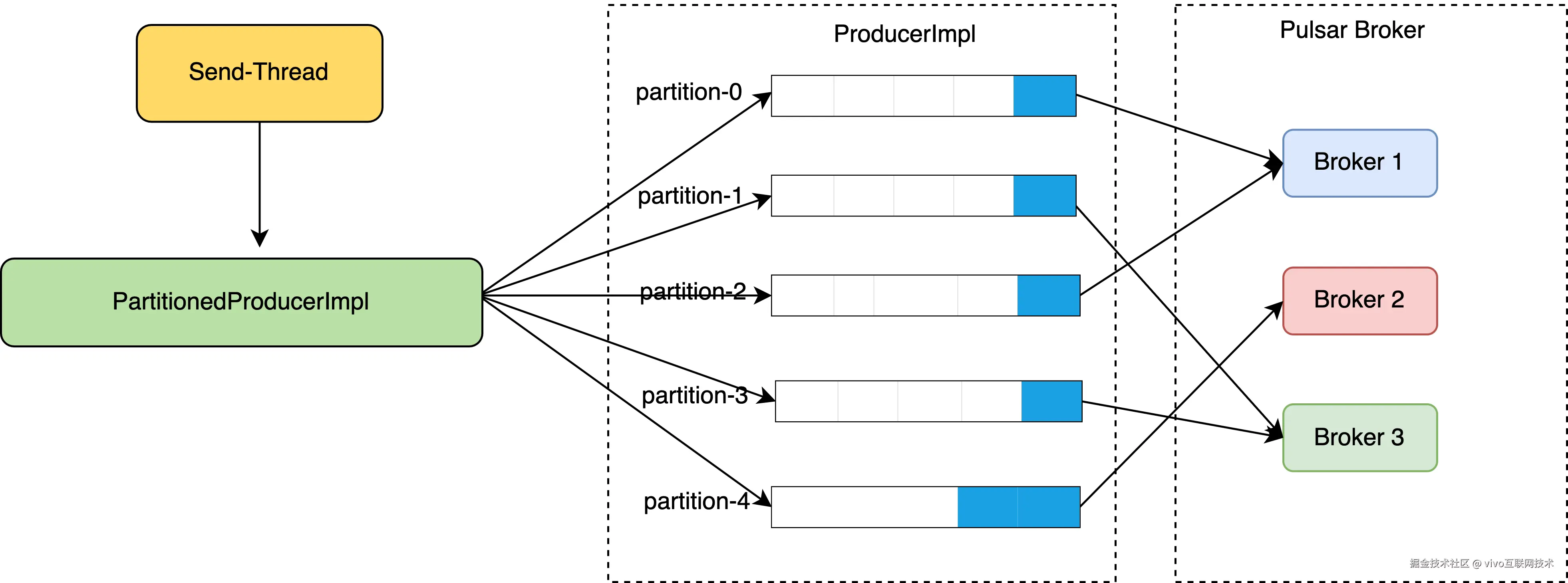
在Pulsar中,PartitionedProducerImpl用于将多个ProducerImpl对象包装成为一个逻辑生产者,以便向Partitioned Topic发送消息时能够批量操作。其中,PartitionedProducerImpl.producers成员变量维护了每个分区及其对应的ProducerImpl对象,该设计主要有以下3个好处:
① 每个分区对应一个单独的生产者:
在Pulsar中,Partitioned Topic按照分区(Partition)将多个 ProducerImpl 对象进行分配,以便能够同时发往多个 Broker 节点,因此对于每个分区,需要拥有一个单独的生产者以便进行发送操作。在 PartitionedProducerImpl 类中,需要为每个分区维护一个 ProducerImpl 对象,以便在消息被分配好“目标分区”后可以调用对应的ProducerImpl进行处理。
②简化代码逻辑:
在PartitionedProducerImpl中,将每个分区及其对应的ProducerImpl对象维护在一个HashMap中,能够更加方便的维护并管理不同分区的生产者,使得代码逻辑更加清晰简明。
③ 提高容错性:
当某个分区的ProducerImpl对象无法工作时,可以选择其他可用的ProducerImpl对象,从而保证系统整体的可用性。由于将不同分区的ProducerImpl对象分别进行维护,因此具备更加灵活的容错处理策略。
在线上实践中我们也基于该设计,在PartitionedProducerImpl层做了进一步优化,通过感知下一层每个ProducerImpl的阻塞状态(信号量的使用情况)来决定新的消息发送,避免将消息持续发往阻塞较为严重的分区,规避了topic被某一个分区阻塞而影响到整体发送性能的情况,也提高了线上系统的稳定性,具体的实现可以详见这篇文章
关键代码:
scss
体验AI代码助手
代码解读
复制代码
//对每一个分区都创建一个ProducerImpl对象 private void start(List<Integer> indexList) { AtomicReference<Throwable> createFail = new AtomicReference<Throwable>(); AtomicInteger completed = new AtomicInteger(); for (int partitionIndex : indexList) { createProducer(partitionIndex).producerCreatedFuture().handle((prod, createException) -> { ....... }); } } private ProducerImpl<T> createProducer(final int partitionIndex) { return producers.computeIfAbsent(partitionIndex, (idx) -> { String partitionName = TopicName.get(topic).getPartition(idx).toString(); return client.newProducerImpl(partitionName, idx, conf, schema, interceptors, new CompletableFuture<>()); }); }
2.2.2 确定目标分区
在发送消息前需要决定发往哪一个分区,确定好分区后便调用对应分区的ProducerImpl对象进一步处理,目标分区的确定主要跟“路由策略”和“是否指定key”有关:
**(1)如果消息没有指定key:**则按照三种路由策略的效果选择分区进行发送,三种路由策略如下:
- SinglePartition:
如果消息没有指定Key,Producer会随机选择一个 Partition,然后把所有的消息都发送到这个 Partition上。
- RoundRobinPartition:
生产者将以轮询方式在所有 Partition之间发布消息,以实现最大吞吐量。需要注意的是如果开启了batch发送,则轮询将会以批为单位进行消息发送,批次发送时每隔partitionSwitchMs会轮询一个 Partition。如果关闭了批量发送,那么每条消息发送都会轮询一个Partition。(partitionSwitchMs至少为一个batchingMaxPublis
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2028
2028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









