




 本文详细介绍了硬间隔支持向量机的基本概念、模型构建过程、SMO算法原理及其实现,并提供了Python代码示例。
本文详细介绍了硬间隔支持向量机的基本概念、模型构建过程、SMO算法原理及其实现,并提供了Python代码示例。
阅读本文需要的背景知识点:拉格朗日乘子法、KKT条件、一丢丢编程知识
一、引言
前面一节我们介绍了一种分类算法——朴素贝叶斯分类器算法,从概率分布的角度进行分类。下面我们会花几节来介绍另一种在分类问题中有着重要地位的算法——支持向量机1 (Support Vector Machine/SVM)。
SVM从基础到复杂可以分成三种分别为线性可分支持向量机(也就是硬间隔支持向量机)、线性支持向量机(软间隔支持向量机)、非线性支持向量机(核函数支持向量机),这一节先来介绍第一种最基础的算法——硬间隔支持向量机算法(Hard-margin Support Vector Machine)。
二、模型介绍
原始模型
先来看下图,展示了一组线性可分的数据集,其中红点表示 -1、蓝叉表示 1 ,可以看到将该数据集分开的直线有无限多条,那么如何选择一条相对合适的直线呢?如下图中的两条直线 A、B,直观上似乎直线 A 比直线 B 更适合作为决策边界,因为对于直线 B,离某些样本点过于近,虽然依然能正确分类样本点,但当在该样本点附近预测时,会得到完全不同的结果,似乎不符合直觉,其泛化能力更差一些,而反观直线 A,其更具有鲁棒性。
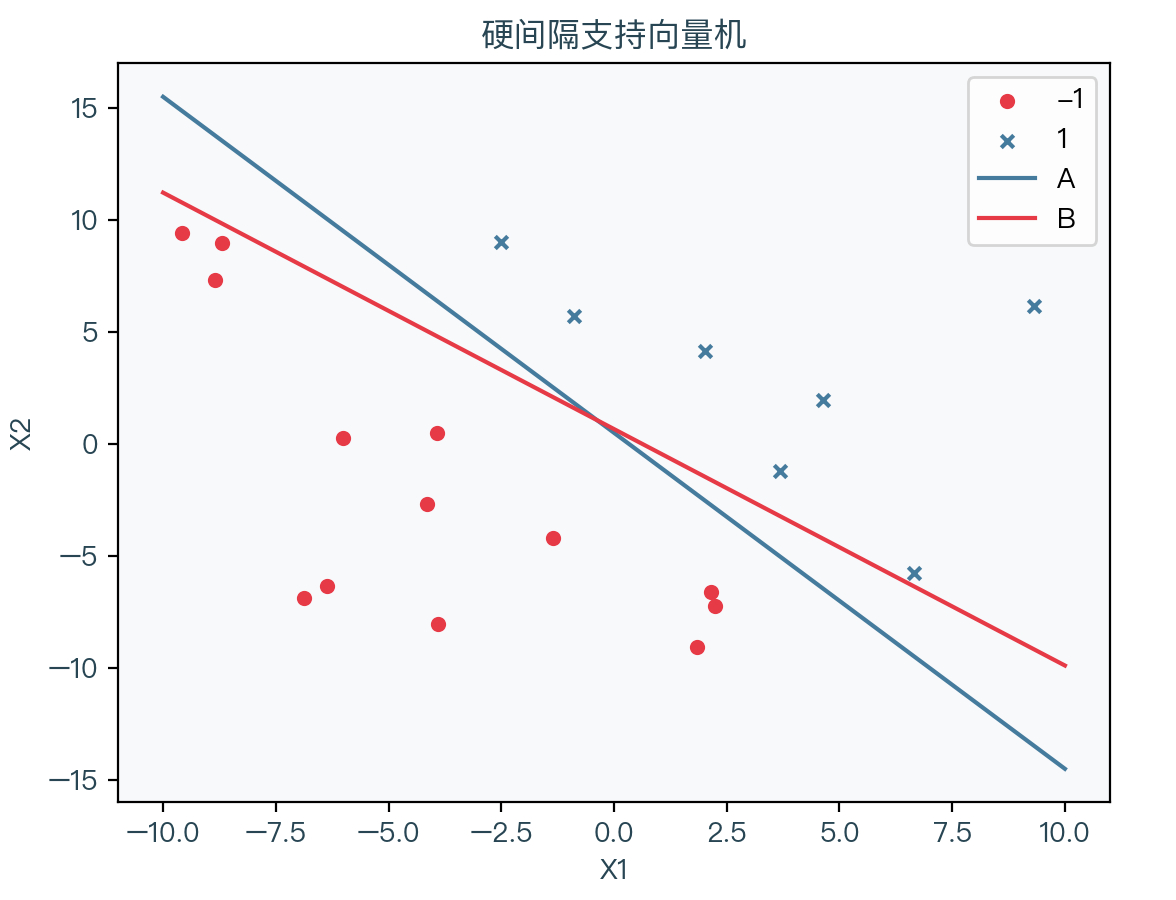
根据上面的推断,我们的目标为找到一条直线(多维时为超平面),使得任意样本点到该超平面的距离的最小值最大。超平面表达式如下:
w T x + b = 0 w^Tx + b = 0 wTx+b=0
同时使得每个样本点都在正确的分类下面,即满足下式:
{ w T x i + b > 0 y i = + 1 w T x i + b < 0 y i = − 1 ⇒ y i ( w T x i + b ) > 0 \left\{\begin{array}{c} w^{T} x_{i}+b>0 & y_{i}=+1 \\ w^{T} x_{i}+b<0 & y_{i}=-1 \end{array} \quad \Rightarrow \quad y_{i}\left(w^{T} x_{i}+b\right)>0\right. {
wTxi+b>0wTxi+b<0yi=+1yi=−1⇒yi(wTxi+b)>0
观察下图,可以将问题转化为找到两个超平面 A、C,使得两个超平面之间的距离最大,同时每个样本点分类正确。
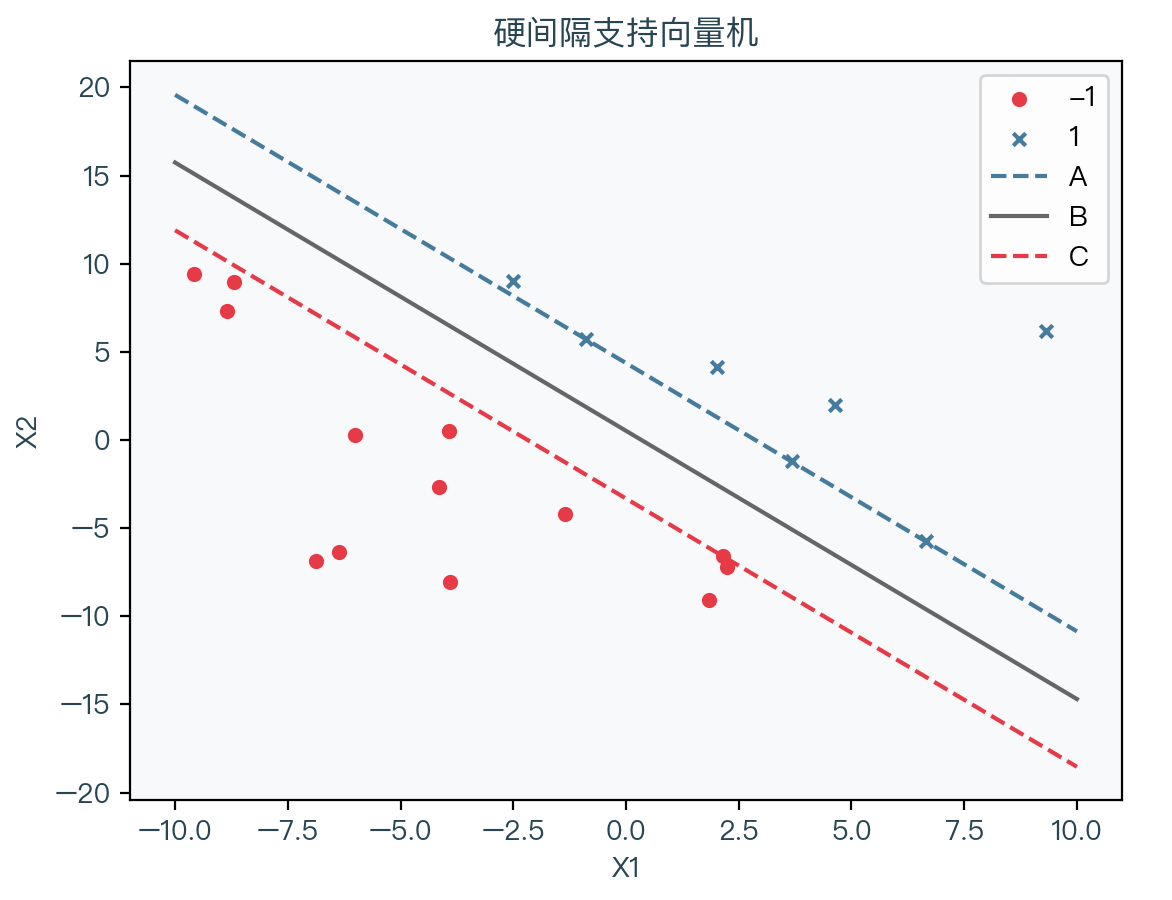
不妨假设超平面 A 为 w x + b = 1 wx + b = 1 wx+b=1,超平面 B 为 w x + b = − 1 wx + b = -1 wx+b=−1(由于 w 、 b w、b w、b 都可以成比例缩放,所以必然可以找到对应的值使得上式成立),同时分类正确的条件如下:
{ w T x i + b ≥ 1 y i = + 1 w T x i + b ≤ − 1 y i = − 1 ⇒ y i ( w T x i + b ) ≥ 1 \left\{\begin{array}{c} w^{T} x_{i}+b \ge 1 & y_{i}=+1 \\ w^{T} x_{i}+b \le -1 & y_{i}=-1 \end{array} \quad \Rightarrow \quad y_{i}\left(w^{T} x_{i}+b\right) \ge 1\right. {
wTxi+b≥1wTxi+b≤−1yi=+1yi=−1⇒yi(wTxi+b)≥1
任意一点到超平面 w x + b = 0 wx + b = 0 wx+b=0 的距离为(推导见四):
d = ∣ w T x + b ∣ ∣ w ∣ d = \frac{\mid w^Tx + b \mid}{\mid w \mid} d=∣w∣∣wTx+b∣
由上式可知超平面 A: w x + b = 1 wx + b = 1 wx+b=1,超平面 B: w x + b = − 1 wx + b = -1 wx+b=−1 之间的间距为(推导见四):
margin = 2 ∣ w ∣ \text{margin} = \frac{2}{\mid w \mid} margin=∣w∣2
那么问题转化为了如下形式:
max w , b 2 ∣ w ∣ s.t. y i ( w T x i + b ) ≥ 1 i = 1 , 2 , ⋯ , N \begin{aligned} \underset{w, b}{\max} \frac{2}{\mid w \mid} \\ \text { s.t. } \quad y_{i}\left(w^{T} x_{i}+b\right) \geq 1 & \quad i=1,2, \cdots, N \end{aligned} w,bmax∣w∣2 s.t. yi(wTxi+b)≥1i=1,2,⋯,N
对向量的取模操作可以转化为向量内积的形式,同时取倒数,将最大值问题变成求最小值的问题,得到最后的模型如下:
min w , b 1 2 w T w s.t. y i ( w T x i + b ) ≥ 1 i = 1 , 2 , ⋯ , N \begin{aligned} \underset{w, b}{\min} \frac{1}{2} w^Tw \\ \text { s.t. } \quad y_{i}\left(w^{T} x_{i}+b\right) \geq 1 & \quad i=1,2, \cdots, N \end{aligned} w,bmin21wTw s.t. yi(wTxi+b)≥1i=1,2,⋯,N
对偶模型
对原模型用拉格朗日乘子法转换一下:
(1)使用拉格朗日乘子法,即在后面加上 N 个拉格朗日乘子的条件,得到对应的拉格朗日函数
(2)拉格朗日函数对 w w w 求偏导数并令其为零
(3)得到 w w w 的解析解
(4)拉格朗日函数对 b b b 求偏导数并令其为零
(5)得到新的条件
L ( w , b , λ ) = 1 2 w T w + ∑ i = 1 N λ i ( 1 − y i ( w T x i + b ) ) ( 1 ) ∂ L ∂ w = w − ∑ i = 1 N λ i y i x i = 0 ( 2 ) w = ∑ i = 1 N λ i y i x i ( 3 ) ∂ L ∂ b = − ∑ i = 1 N λ i y i = 0 ( 4 ) ∑ i = 1 N λ i y i = 0 ( 5 ) \begin{aligned} L(w, b, \lambda) &=\frac{1}{2} w^{T} w+\sum_{i=1}^{N} \lambda_{i}\left(1-y_{i}\left(w^{T} x_{i}+b\right)\right) & (1)\\ \frac{\partial L}{\partial w} &=w-\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i}=0 & (2)\\ w &=\sum_{i=1}^{N} \lambda_{i} y_{i} x_{i} & (3)\\ \frac{\partial L}{\partial b} &=-\sum_{i=1}^{N} \lambda_{i} y_{i}=0& (4) \\ \sum_{i=1}^{N} \lambda_{i} y_{i} &=0 & (5) \end{aligned} L(w,b,λ)∂w∂Lw∂b∂Li=1∑Nλiyi=21wTw+i=1∑Nλi(1−yi(wTxi+b))=w−i=1∑Nλiyixi=0=i=1∑Nλiyixi=−i=1∑Nλiyi=0=0(1)(2)(3)(4)(5)
将上面 w 、 b w、b w、b 的解析解带回到拉格朗日函数:
(1)拉格朗日函数
(2)展开括号
(3)观察(2)式最后一项,必定为零,再带入 w w w 的解析解
(4)化简整理得到
L ( w , b , λ ) = 1 2 w T w + ∑ i = 1 N λ i ( 1 − y i ( w T x i + b ) ) ( 1 ) L ( λ ) = 1 2 w T w + ∑ i = 1 N λ i − ∑ i = 1 N λ i y i w T x i − ∑ i = 1 N λ i y i b ( 2 ) = 1 2 ∑ i = 1 N ∑ j = 1 N λ i λ j y i y j x i T x j + ∑ i = 1 N λ i − ∑ i = 1 N ∑ j = 1 N λ i λ j y i y j x i T x j ( 3 ) = ∑ i = 1 N − 1 2 ∑ i = 1 N ∑ j = 1 N λ i λ j y i y j x i T x j ( 4 ) \begin{aligned} L(w, b, \lambda) &=\frac{1}{2} w^{T} w+\sum_{i=1}^{N} \lambda_{i}\left(1-y_{i}\left(w^{T} x_{i}+b\right)\right) & (1)\\ L(\lambda) &=\frac{1}{2} w^{T} w+\sum_{i=1}^{N} \lambda_{i}-\sum_{i=1}^{N} \lambda_{i} y_{i} w^{T} x_{i}-\sum_{i=1}^{N} \lambda_{i} y_{i} b & (2)\\ &=\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j}+\sum_{i=1}^{N} \lambda_{i}-\sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j} & (3)\\ &=\sum_{i=1}^{N}-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \lambda_{i} \lambda_{j} y_{i} y_{j} x_{i}^{T} x_{j} & (4) \end{aligned} L(w,b,λ)L(λ)=21wTw+i=1∑Nλi(1−yi(wTxi+b))=21wTw+i=1∑Nλi−i=1∑NλiyiwTxi−i=1∑Nλiyib=21i=1∑Nj=1∑NλiλjyiyjxiTxj+i=1∑Nλi−i=1∑Nj=1∑NλiλjyiyjxiTxj=i=1∑N−21i=1∑Nj=1∑NλiλjyiyjxiTxj(1)(2)(3)(4)
(1)原始问题
(2)使用拉格朗日乘子法转换
(3)转换为对偶问题,要想使得原始问题与对偶问题等价,需要引入 KKT 条件
(4)带入拉格朗日函数
min w , b 1 2 w T w s.t. y ( w T x + b ) ≥ 1 ( 1 ) ⇒ min w , b max λ L ( w , b , λ ) s.t. λ ≥ 0 ( 2 ) ⇒ max λ min w , b L ( w , b , λ ) s.t. λ ≥ 0 ( 3 ) ⇒ max λ L ( λ ) s.t. λ ≥ 0 ( 4 ) \begin{aligned} & \min _{w, b} \frac{1}{2} w^{T} w \quad \text { s.t. } y\left(w^{T} x+b\right) \geq 1 & (1)\\ \Rightarrow & \min _{w, b} \max _{\lambda} L(w, b, \lambda) \quad \text { s.t. } \lambda \geq 0 & (2)\\ \Rightarrow & \max _{\lambda} \min _{w, b} L(w, b, \lambda) \quad \text { s.t. } \lambda \geq 0 & (3)\\ \Rightarrow & \max _{\lambda} L(\lambda) \quad \text { s.t. } \lambda \geq 0 & (4) \end{aligned} ⇒⇒⇒w,bmin21wTw s.t. y(wTx+b)≥1w,bminλmaxL(w,b,λ) s.t. λ≥0λmaxw,bminL(w,b,λ) s.t. λ≥0λmaxL(λ) s.t. λ≥0(1)(2)(3)(4)
KKT(Karush-Kuhn-Tucker)条件2
前面在推导原始问题的对偶问题中,使得两个问题等价的条件被称为 KKT 条件(Karush–Kuhn–Tucker conditions)。
对偶问题需满足的 KKT 条件如下:
{ ∇ w , b L ( w , b , λ ) = 0 λ i ≥ 0 y i ( w T x i + b ) − 1 ≥ 0 λ i ( y i ( w T x i + b ) − 1 ) = 0 \left\{\begin{aligned} \nabla_{w, b} L(w, b, \lambda) &=0 \\ \lambda_{i} & \geq 0 \\ y_{i}\left(w^{T} x_{i}+b\right)-1 & \geq 0 \\ \lambda_{i}\left(y_{i}\left(w^{T} x_{i}+b\right)-1\right) &=0 \end{aligned}\right. ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3529
3529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









