







假设一台 32G 内存的服务器部署了一个 Redis,内存占用了 25G,会发生什么?
此时最明显的表现是 Redis 的响应变慢,甚至非常慢。
这是因为 RDB 快照是通过 fork 子线程来实现的,fork 操作时间和 Redis 数据量成正相关,而 fork 时会阻塞主线程。
随着数据量的增加,fork 耗时也会增加。所以,当对 25G 的文件进行 fork 时,Redis 的响应就会变慢。
针对这种大数据量的存储,有什么其他的方案呢?
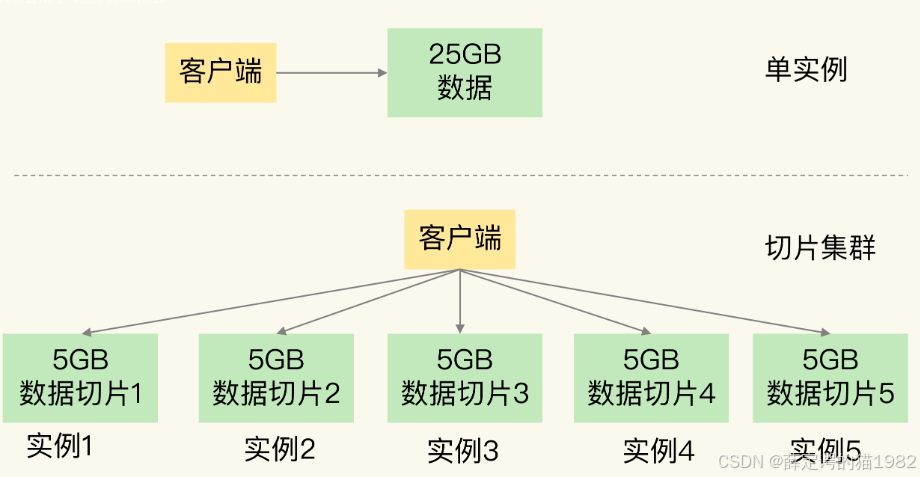
什么是切片集群?
Redis 分片集群是一种将 Redis 数据库分散到多个节点上的方式,以提供更高的性能和可伸缩性。在分片集群中,数据被分为多个片段,每个片段存储在不同的节点上,这些节点可以是物理服务器或虚拟服务器。
Redis 分片集群的主要目的是将数据分布在多个节点上,以便可以通过并行处理来提高读写吞吐量。每个节点负责处理一部分数据,并且在需要时可以进行扩展以适应更多的负载。此外,分片集群还提供了故障容错和高可用性的功能,即使其中一个节点发生故障,其他节点仍然可以继续工作。
比如我们将 25GB 的数据平均分成 5 份(当然,也可以不做均分),使用 5 个实例来保存,每个实例只需要保存 5GB 的数据。
Redis 是如何做分片的
Redis 通过一种称为哈希槽(hash slot)的机制来实现分片集群。哈希槽将整个数据集分成固定数量的槽,每个槽都有一个唯一的编号,通常是从 0 到 16383。
在 Redis 分片集群中,有多个节点(主节点和从节点),每个节点负责存储其中一部分的槽数据。节点之间通过集群间通信协议进行数据的交互和同步。
哈希切片
- 原理:通过对数据的键进行哈希运算,将哈希值映射到不同的节点上。常用的哈希算法有 CRC16、MurmurHash 等。
- 示例:假设有 3 个 Redis 节点,节点编号为 0、1、2。对键 "key1" 进行 CRC16 哈希运算,得到哈希值为 12345。用哈希值对节点数量取模,即 12345 % 3 = 0,那么 "key1" 就会被存储到节点 0 上。
范围切片
- 原理:按照数据键的范围来划分,将不同范围的键存储到不同的节点上。
- 示例:假设以字母顺序为范围划分,节点 0 存储键以 "A - G" 开头的数据,节点 1 存储以 "H - N" 开头的数据,节点 2 存储以 "O - Z" 开头的数据。当要存储键为 "hello" 的数据时,根据范围判断应存储到节点 1 上。
一致性哈希切片
- 原理:将哈希值空间组织成一个虚拟的圆环,节点和数据的键都映射到这个圆环上。数据根据其键的哈希值在圆环上顺时针找到的第一个节点,就是该数据的存储节点。
- 示例:假设有 3 个节点 NodeA、NodeB、NodeC,通过哈希算法将它们映射到一致性哈希环上。当有键 "key2" 要存储时,计算其哈希值,在环上找到顺时针方向第一个节点,若为 NodeB,则 "key2" 存储在 NodeB 上。若增加或减少节点,只会影响到该节点在环上的相邻节点,数据迁移量相对较小。
虚拟节点切片
- 原理:为每个物理节点创建多个虚拟节点,将数据映射到虚拟节点上,再由虚拟节点对应到实际的物理节点。
- 示例:假设有 2 个物理节点 Node1 和 Node2,为每个物理节点创建 3 个虚拟节点,分别为 Node1_1、Node1_2、Node1_3 和 Node2_1、Node2_2、Node2_3。对数据键进行哈希运算后映射到虚拟节点上,如键 "key3" 映射到了 Node1_2,再由 Node1_2 对应到实际的物理节点 Node1 来存储数据。这样可以更均匀地分配数据,提高集群的负载均衡能力


















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











