




 本文详细介绍了偏差与方差的概念,偏差衡量学习算法的预期与真实结果的偏离,方差则反映了预测值的离散程度。通过经典示例展示了偏差和方差在过拟合和欠拟合中的角色。还探讨了泛化误差与偏差、方差的关系,并解释了集成学习如何从方差和偏差角度提高模型性能。
本文详细介绍了偏差与方差的概念,偏差衡量学习算法的预期与真实结果的偏离,方差则反映了预测值的离散程度。通过经典示例展示了偏差和方差在过拟合和欠拟合中的角色。还探讨了泛化误差与偏差、方差的关系,并解释了集成学习如何从方差和偏差角度提高模型性能。
定义
- 偏差:真实值与预测值的误差大小
- 方差:预测值的离散程度
- 学习算法的(泛化)误差=偏差+方差+噪声
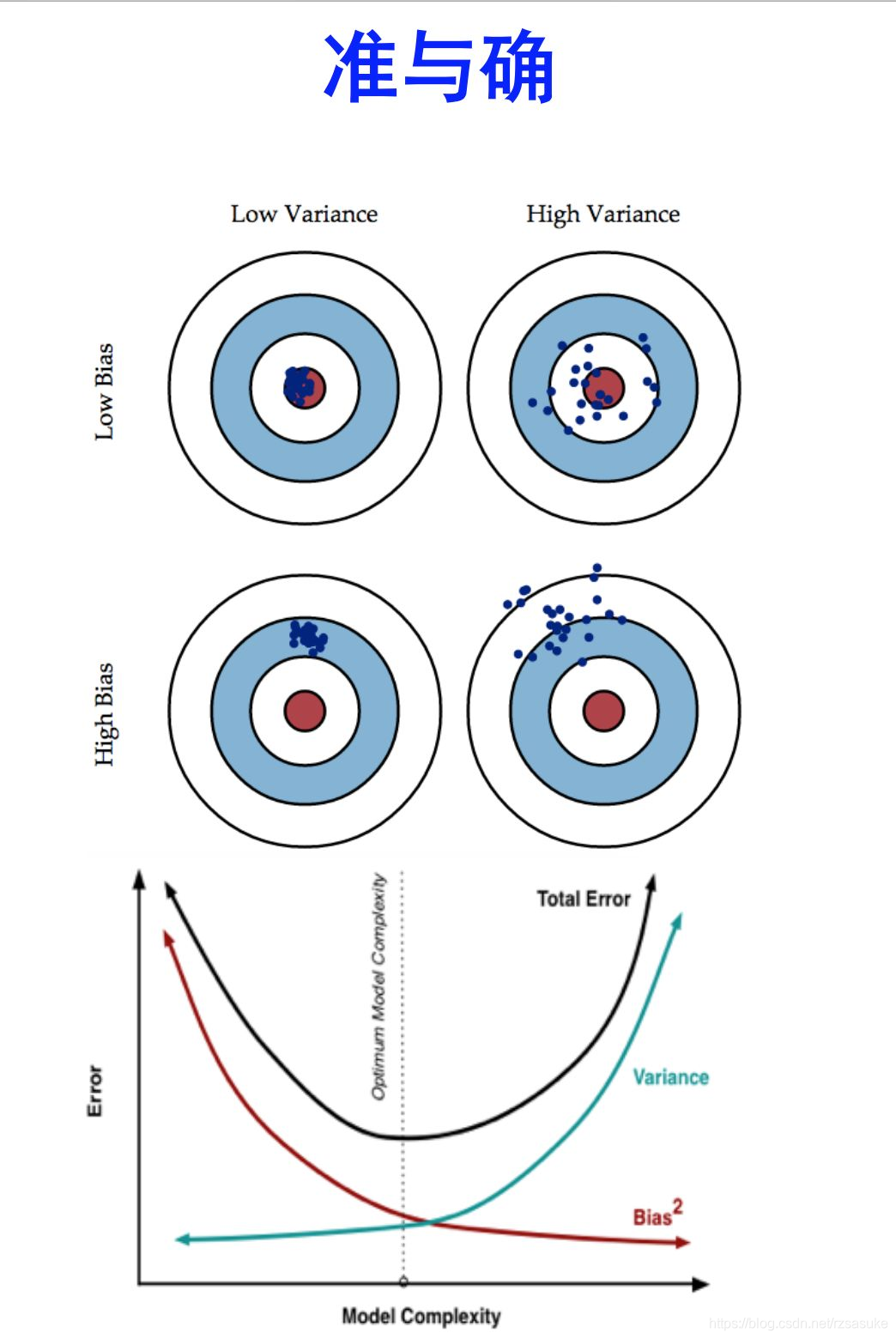
经典示意图:
注意图中所有点代表(同一个学习算法来自同一分布的不同训练数据集)不同模型对同一个样本的预测结果
- (1) Low Bias + Low Variance:理想
- (2) Low Bias + High Variance:过拟合时,往往偏差小、方差大
- (3) High Bias + Low Variance:欠拟合时,往往偏差大,方差小
- (4) High Bias + High Variance:刚开始拟合
- 随着模型复杂度的升高,偏差减小,方差增大,误差先减小后增大
原理
样本 x x x真实标签为 y y y,它在数据集 d d d中的标签为 y d y_d yd,基于数据集 d d d训练的模型为 f d ( . ) f_d(.) fd(.),对样本 x x x的预测值为 f d ( x ) f_d(x) fd(x),其中 d d d是来自同一分布的任一训练集。
记 f ( x ) ‾ = E d ( f d ( x ) ) \overline{f(x)}=E_d(f_d(x)) f(x)=Ed(fd(x)),
定义偏差为
B i a s 2 = ( f ( x ) ‾ − y ) 2 {Bias}^2=(\overline{f(x)}-y)^2 Bias2=(f(x)−y)2,
方差为
V a r i a n c e = E d [ ( f d ( x ) − f ( x ) ‾ ) 2 ] Variance=E_d[(f_d(x)-\overline{f(x)})^2] Variance=Ed[(fd(x)−f(x))2],
噪声(且假设期望为0)为
ϵ 2 = E d [ ( y − y d ) 2 ] {\epsilon}^2=E_d[(y-y_d)^2] ϵ2=Ed[(y−yd)2], E d [ ( y − y d ) ] = 0 E_d[(y-y_d)]=0 Ed[(y−yd)]=0
泛化误差为
E r r o r = E d [ ( f d ( x ) − y d ) 2 ] Error=E_d[(f_d(x)-y_d)^2] Error=Ed[(fd(x)−yd<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3462
3462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









