









介绍
- RPC框架(远程过程调用):它是一种对底层通信协议的二次封装,通过网络从远程计算机程序上请求的服务框架。可参考:RPC框架
- tensorflow中的是谷歌的gRPC框架
- 数据分析设备类型:
- 一机多卡(普通):一台服务器,多个显卡。
- 多机多卡(分布式):多台服务器,多个显卡。
- tensorflow实现分布式的结构:
- 参数服务器们(tensorflow对于其的命名规范:/job:ps/task:0/cpu:0):用于存储和更新参数W(权重)
- 工作服务器们(tensorflow对于其的命名规范:/job:worker/task:1/gpu:2):用于计算梯度下降的“变化值”
ps:工作服务器中有一个主服务器(需要指定),用于定义和运行任务,其它服务器配合计算。
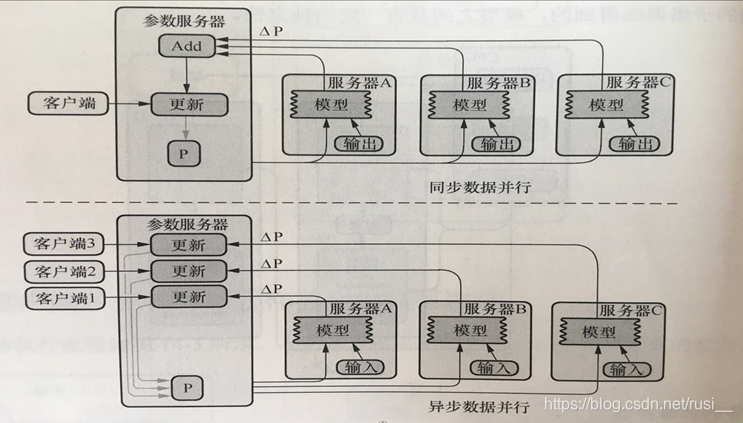
- tensorflow更新参数的方式(配合图片):
- 我们先假设参数更新的公式是 w’ = w - t;t = a(方向) — > t 为梯度下降求出来的“变化值”
- 同步模式更新:
- 过程:工作服务器计算出梯度下降的变化值:t1,t2…,并将传给参数服务器,然后参数服务器取变化值的平均值使用:w’ = w - tmean 更新权重参数,然后再将 w’ 传入各个工作服务器中。
- 特点:在这个过程中,工作服务器的计算速度是有差别的,所以计算快的工作服务器,会阻塞等待慢的,这个过程别称之为同步。
- 异步模式更新(tensorflow默认方式) :
- 过程:相对同步而言,异步是不会不等待“变化值”的,它会使用 w’ = w - t 直接计算出新的 w’ ,然后使用 w’ 和之前存储的 w 取平均值更新为参数服务器存储的 w 和当前工作服务器的新参数 Wmean。
- 特点:因为每个工作服务器计算出来的变化值都会被计算然后取平均值,所以这个过程中相对同步而言,是不受个别机器配置的影响的,但是可能会出现梯度消失的问题。
案例:分布式做一个简单的乘法运算
- 由于需要介绍的api太多,不再介绍,仅在代码做简要注释。
- 需要注意的是:当在配置参数服务器和工作服务器的时候,按顺序,依次为0,1,2…号服务器(可以参考下图)。

- code:
#!/usr/local/bin/python3 # -*- coding: utf-8 -*- # Author : rusi_ import tensorflow as tf FLAGS = tf.app.flags.FLAGS tf.app.flags.DEFINE_string("job_name", "worker", "启动服务的类型ps or worker") tf.app.flags.DEFINE_integer("task_index", 0, "指定ps或者worker当中的哪一台服务器") def main(argv): # 定义全局计数的op ,给钩子列表当中的训练步数使用 global_step = tf.contrib.framework.get_or_create_global_step() # 指定集群描述对象, ps , worker clr = tf.train.ClusterSpec({"ps": ["172.18.87.17:7000"], "worker": ["192.168.233.141:70001"]}) # 创建不同的服务, ps, worker server = tf.train.Server(clr, job_name=FLAGS.job_name, task_index=FLAGS.task_index) # 判断服务类型 if FLAGS.job_name == "ps": # 参数服务器只需要等待worker传递参数 server.join() elif FLAGS.job_name == "worker": worker_device = "/job:worker/task:0/cpu:0/" # tf.device(参数:可以指定名字或函数(固定的)指定什么设备去运行什么代码。 # 当指定函数的时候是为了同步数据的,这种方法也是分布式特有的使用方式。 # 当指定名字的时候,例如:'/cpu:0'代表的是在当前服务器上使用cpu0运行下面部分的代码 with tf.device(tf.train.replica_device_setter( worker_device=worker_device, # 用什么设备 cluster=clr # 和别的服务器建立关系 )): # 简单做一个矩阵乘法运算 x = tf.Variable([[1, 2, 3, 4]]) w = tf.Variable([[1], [1], [1], [1]]) mat = tf.matmul(x, w) # 创建分布式会话(不需要再初始化变量op了,MonitoredTrainingSession()自动帮助初始化) with tf.train.MonitoredTrainingSession( master="grpc://192.168.233.141:70001", # 指定主worker is_chief=(FLAGS.task_index == 0), # 判断是否是主worker # config=tf.ConfigProto(log_device_placement=True), # 打印设备信息 hooks=[tf.train.StopAtStepHook(last_step=200)] # 钩子实现循环多少步,当超过200步的时候会抛出异常(需要配合全局global_step(计数器)使用)。 ) as m_sess: while not m_sess.should_stop(): # should_stop() :会话是否产生了异常(异常时返回false)。 print(m_sess.run(mat)) if __name__ == "__main__": tf.app.run() # 默认调用main()函数,main函数要求必须有argv参数

















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









