







3.PyTorch模型搭建
3.1.卷积层
3.1.1.卷积-1d/2d/3d
卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加
卷积核:又称为滤波器,过滤器,可认为是某种模式,某种特征。
卷积过程类似于用一个模版去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取
例如:
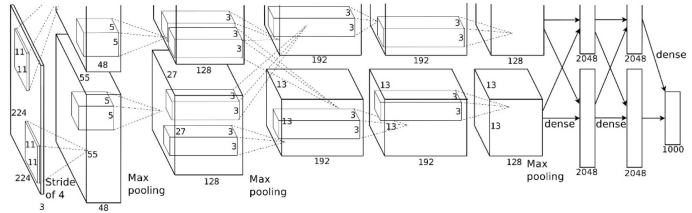
AlexNet卷积核可视化,发现卷积核学习到的是边缘,条纹,色彩这一些细节模式

卷积维度: 一般情况下,卷积核在几个维度上滑动,就是几维卷积
下面分别为一维、二维、三维卷积示意图
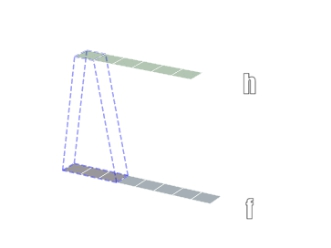
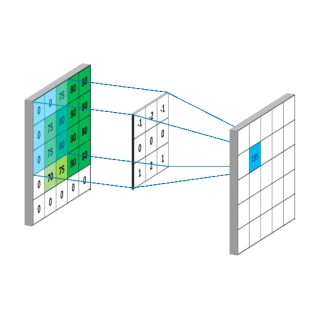

通常,我们常用的为二维卷积,如何生成二维卷积?
nn.Conv2d
功能:对多个二维信号进行二维卷积
• in_channels:输入通道数
• out_channels:输出通道数,等价于卷积核个数
• kernel_size:卷积核尺寸
• stride:步长
• padding :填充个数
• dilation:空洞卷积大小
• groups:分组卷积设置
• bias:偏置
nn.Conv2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros')
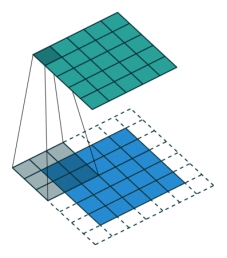
padding:

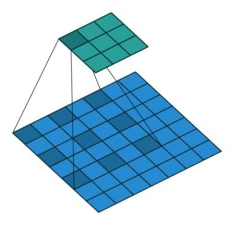
空洞卷积大小:
分组卷积:例如AlexNet,分为两组
卷积后的尺寸计算:

代码实现:
利用二维卷积提取图片特征
# -*- coding: utf-8 -*-
import os
import torch
import random
import numpy as np
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
img_ = img_.detach().numpy() * 255
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# 数据加载
# os.path.dirname(__file__)返回的是.py文件的目录
path_img = os.path.join(os.path.dirname(__file__), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255
# convert to tensor
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
img_tensor.unsqueeze_(dim=0) # C*H*W to B*C*H*W
# 创建卷积层Conv2d
# 设置卷积层输入channel为3,卷积核数量为1,卷积核大小为3
conv_layer = nn.Conv2d(3, 1, 3)
# 初始化权重,即卷积核,conv_layer.weight.data返回权重(卷积核)的shape,(卷积核数量, 深度,高, 宽)
# nn.init.xavier_normal_为Xavier正态分布初始化,参数由0均值,标准差为sqrt(2 / (fan_in + fan_out))的正态分布产生
# 其中fan_in和fan_out是分别权值张量的输入和输出元素数目. 这种初始化同样是为了保证输入输出的方差不变
# 在tanh激活函数上有很好的效果,但不适用于ReLU激活函数
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# 可视化
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
# 对卷积后的图像进行逆变换,卷积后只有一个通道
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transfor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1670
1670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









