




一:准确率(Accuracy)、错误率 (Error rate)
准确率 = 正确分类的样本数 / 总样本数
错误率 = 错误分类的样本数 / 总样本数 = 1 - 准确率
Top-1准确率:预测类别按置信度从高到低排序,取排名第一的类别作为预测结果,计算准确率
Top-5准确率:取排名前五的类别作为预测结果(只要包含真实类别,就算分类正确),计算准确率
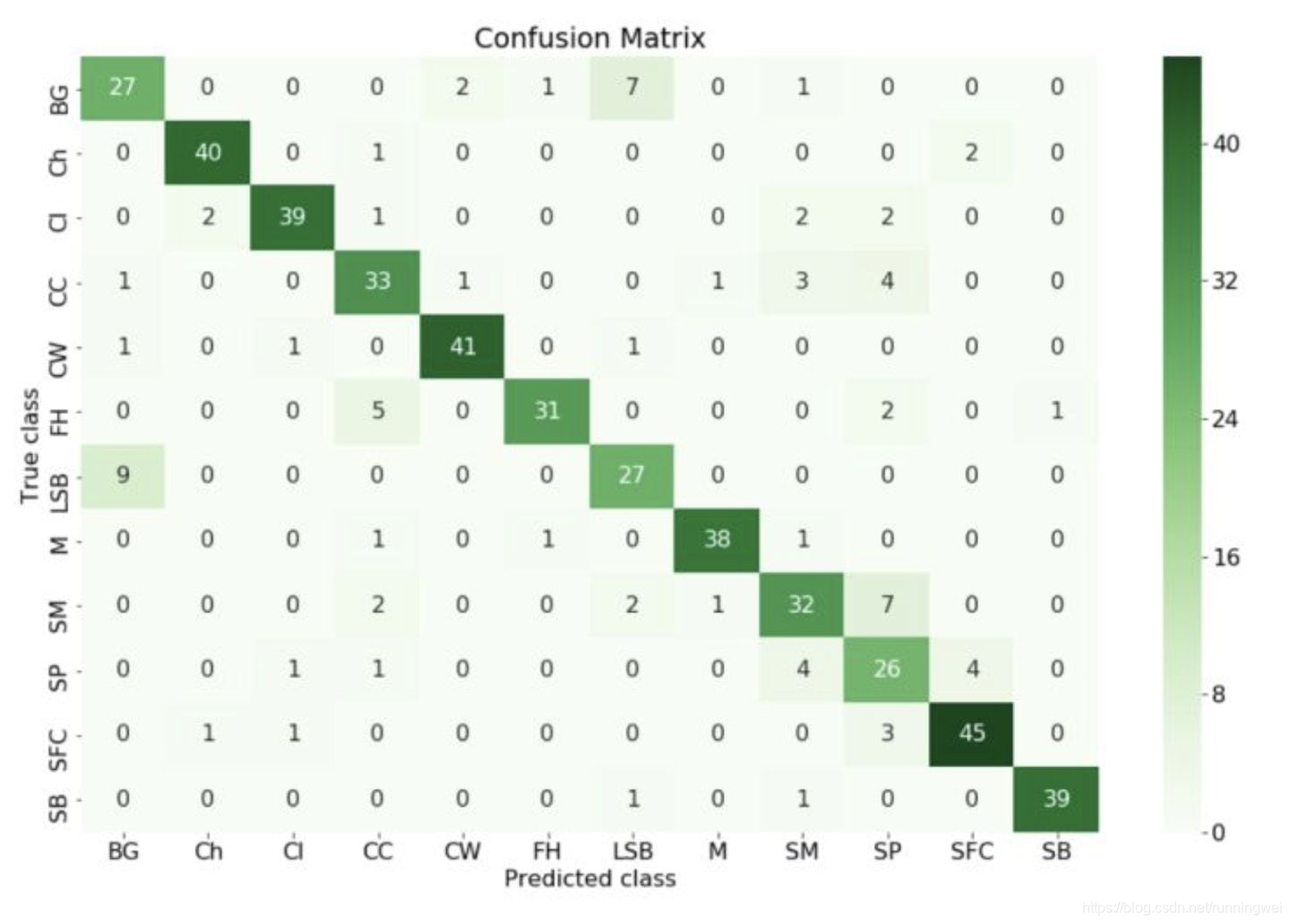
二:混淆矩阵(Confusion Matrix)
混淆矩阵又称错误矩阵,把预测结果与真实标签按类别对应,在一个矩阵中显示出来,方便直观地评估结果。
横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。
对角线表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。
三:精确率、召回率、F指标
- 精确率(Precision)与召回率(Recall):
对于二类分类问题常用的评价指标是精确率与召回率(在信息检索领域又叫查准率与查全率)。通常以关注的类为正类,其他类为负类。二分类的混淆矩阵为:
|
|
预测为正类 |
预测为负类 |
| 正类 |
TP |
FN |
| 负类 |
FP |
TP |
Precision = TP/(TP+FP)
Recall = TP/(TP+FN)
在实际使用中我们的模型通常不是直接预测出类别,而是预测出属于各类别的概率(或置信度),然后通过与阈值比较来划分正负预测结果的;阈值不同,结果就不同。这时我们可以画P-R曲线。
- F指标(F-Measure, F-score):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2868
2868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









