




前言
在语音合成技术不断演进的背景下,早期版本的IndexTTS虽然在多场景应用中展现出良好的表现,但在情感表达的细腻度与时长控制的精准性方面仍存在提升空间。为了解决这些问题,并进一步推动零样本语音合成在实际场景中的落地能力,B站语音团队对模型架构与训练策略进行了深度优化,推出了全新一代语音合成模型——IndexTTS2 。
相比于自回归(Autoregressive, AR)系统,非自回归(Non-Autoregressive, NAR)系统的一大优势在于生成时长可控,便于对语速、节奏进行精确编辑。而在 IndexTTS2 中,我们创新性地提出了一种通用于 AR 系统的“时间编码”机制,首次解决了传统 AR 模型难以精确控制语音时长的问题。这一设计让我们在保留 AR 架构在韵律自然性、风格迁移能力、多模态扩展性等方面优势的同时,也具备了合成定长语音的能力。该技术已率先应用于 B 站“原声视频翻译”功能,目前正在内测,部分用户已可体验。
在实际使用中,往往难以同时获得音色匹配且情感准确的参考音频。为此,IndexTTS2 引入了音色与情感解耦建模机制,处理支持单音频参考以外,额外支持分别指定音色参考与情感参考,实现更加灵活、细腻的语音合成控制。同时,模型还具备基于文本描述的情感控制能力,可通过自然语言描述、使用场景描述、上下文线索等进行精准调节合成语音的情绪色彩。
IndexTTS2 在灵活性与可控性之间实现了更优平衡,不仅支持高质量的零样本语音合成,还显著提升了语音在情感表达维度的真实感与表现力。其合成语音情绪自然饱满,贴近真人,广泛适用于 AI 配音、有声读物、动态漫、视频翻译、语音对话、播客创作等场景,是推动零样本 TTS 走向实用化的重要里程碑。
为进一步推动语音合成技术的开放创新与行业应用落地,我们已将 IndexTTS2 的相关研究成果整理为论文《IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech》,现已发布于 arXiv,欢迎查阅:👉 https://arxiv.org/abs/2506.21619
后续,我们也将全面开源 IndexTTS2 的推理代码与模型权重,诚邀关注项目进展,欢迎前往项目仓库点击 ⭐ 以获取最新开源信息:👉 https://github.com/index-tts/index-tts
未来,我们还将持续优化模型性能,开放更多资源,与开发者社区携手共建开放繁荣的技术生态。
概述
我们提出了 IndexTTS2 ,其整体框架如图1所示。首先,该模型引入了一种新颖、通用且兼容自回归架构的语音时长控制方法。该方法支持两种生成模式:一种允许用户显式指定生成的token数量,从而实现对语音时长的精确调控;另一种则无需手动设定token数,模型可基于自回归机制自由生成语音,同时忠实还原输入提示语中的韵律与节奏特征。
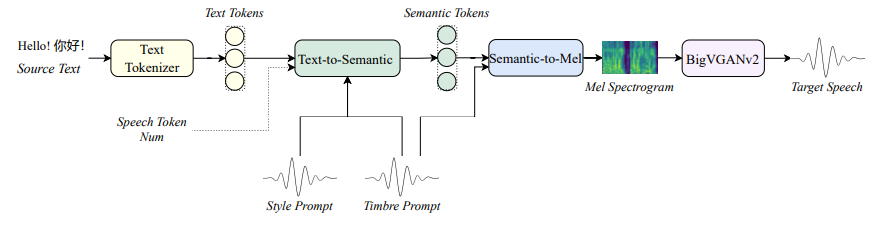
图1 IndexTTS2整体框架
此外,IndexTTS2 对情感表达与说话人身份进行了有效解耦,实现了音色与情感的独立控制。在零样本zero-shot模式下,模型能够高质量地复现输入参考语音中蕴含的情感特征。另外用户还可提供独立于音色提示的情感描述(甚至来自不同说话者),使得模型能够在重建目标音色的同时,准确传达指定的情感基调。
为了提升在高强度情感表达下的语音清晰度与稳定性,我们在模型中引入了GPT式潜在表征机制,显著增强了语音生成的鲁棒性。与此同时,为降低情感控制的使用门槛,我们通过对 Qwen3 进行微调,设计了一种基于自然语言描述的情感软指令机制。这一机制允许用户通过文本输入灵活引导生成语音的情感倾向,极大提升了交互体验与可控性。
在多个数据集上的实验结果表明,IndexTTS2 在词错误率、说话人相似度以及情感保真度等多个关键指标上均优于当前最先进的零样本语音合成模型,展现出其在实用性与表现力方面的显著优势。
方法
IndexTTS2 由三个核心模块组成:Text-to-Semantic(T2S) 、Semantic-to-Mel(S2M) 以及 BigVGANv2 [1] 声码器 。首先,T2S 模块基于输入的源文本、风格提示、音色提示以及一个可选的目标语音token数,生成对应的语义 token 序列。然后,S2M 模块以语义 token 和音色提示作为输入,进一步预测出梅尔频谱图。最后,BigVGANv2 声码器将梅尔频谱图转换为高质量的语音波形,完成端到端的语音合成过程。
基于AR的T2S模块
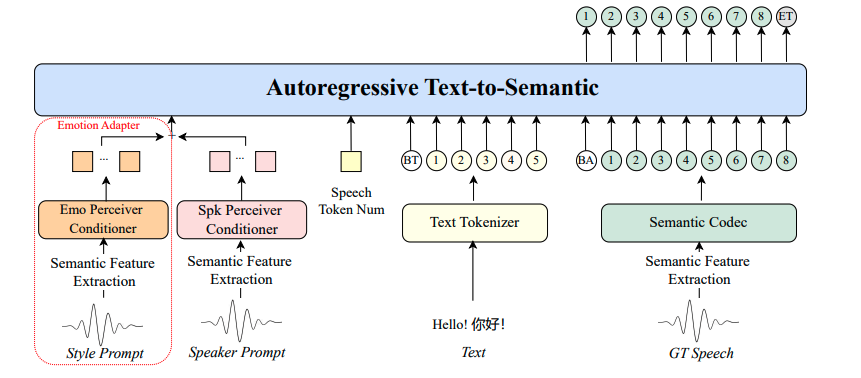
图2 自回归Text-to-Semantic
如图2所示,我们将T2S任务表述为一个自回归语义token预测任务,遵循与传统大型语言模型(LLM)训练相同的方法,使用下一个token预测进行训练。构建的训练序列如下:
![]()
其中, 是表示说话者相关属性或情感特征的全局条件,
是用于时长控制的嵌入,
是文本嵌入序列。
是语义token嵌入序列,该序列由真实语音通过语义编码器获得。
和
分别是在文本和语义token序列之前添加的特殊token嵌入。因此,训练
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









