



 一位CV初学者分享了对天池街景字符编码识别赛题的理解与实践,将问题抽象为定长字符识别,面对环境配置与baseline运行的挑战,详细记录了解决过程,包括使用清华镜像安装pytorch、jupyternotebook环境切换、及常见错误的解决方案。
一位CV初学者分享了对天池街景字符编码识别赛题的理解与实践,将问题抽象为定长字符识别,面对环境配置与baseline运行的挑战,详细记录了解决过程,包括使用清华镜像安装pytorch、jupyternotebook环境切换、及常见错误的解决方案。
小白初学CV
这次的天池赛题是对街景字符编码识别,由于是初学,各方面还有所欠缺,在此搬运大佬们对该赛题的理解。
大佬思路如下:可以将赛题抽象为一个定长字符识别问题,在赛题数据集中大部分图像中字符个数为2-4个,最多的字符个数为6个。因此可以对于所有的图像都抽象为6个字符的识别问题,字符23填充为23XXXX,字符231填充为231XXX。经过填充之后,原始的赛题可以简化了6个字符的分类问题。在每个字符的分类中会进行11个类别的分类,假如分类为填充字符,则表明该字符为空。
以下是我在尝试运行baseline中遇到的一些问题:
1、装环境遇到的问题
通过清华镜像安装pytorch一直显示PackageNotFoundError(队长对此进行解释:清华镜像在安装cpu版本可以,安装GPU版本会出现找不到channels下载的问题),最后采用离线安装的方法,在pytorch中下载包进行安装,在此不再附图。
2、启动jupyter notebook后不能切换环境
经过百度以及队友的帮助,找到了解决方法。该方法的主要目标可以总结为,为jupyter notebook添加一个kernel(原本的jupyter notebook不存在kernel),让jupyter notebook知道可以从那边读取虚拟环境。解决方法如下,
(1)在cmd中切换到想要的环境,比如我的pytorch1
$conda activate pytorch1
(2)在pytorch1环境中安装好ipykernel
$conda install ipykernel
(3)python -m ipykernel install --name pytorch1
$python -m ipykernel install --name pytorch1
再打开jupyter notebook,就可以切换虚拟环境了。
此方法转载于https://blog.youkuaiyun.com/weixin_41813895/article/details/84750990
3、运行baseline时遇到的问题(通过群中大佬都给出了解决方法,在此记录)
(1)错误一:在import各个包时,会出现没有的包的错误。解决方法:没有的包全通过pip install 包名进行安装。
(2)错误二:定义好训练数据和验证数据的Dataset中报错ValueError:num_samples should be a positive integer value,but got num_samples=0。
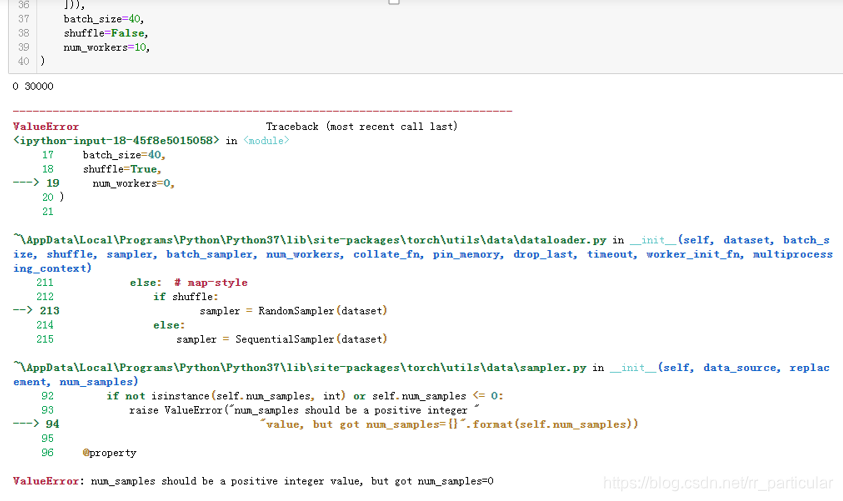 解决方法:把num_workers=10设置为0或者直接注释掉。
解决方法:把num_workers=10设置为0或者直接注释掉。
(3)错误三:迭代训练和验证模型中报错TypeError:train()takes 4 positional arguments but 5 were giver。
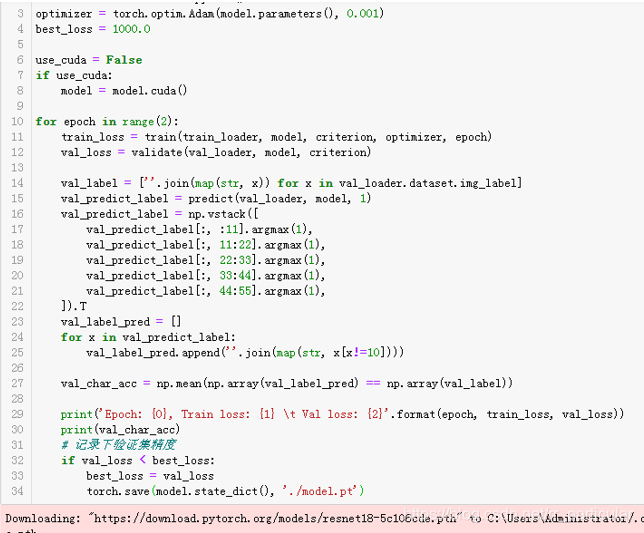

解决方法:删掉第二个图中的epoch参数(原因:定义训练模块时,只有4个参数,没有epoch参数)。
(4)错误四:训练时报错RuntimeError:Expected object of scalar type Long but got scalar type Int
for argument #2 ‘target’。
解决方法:train模块和验证模块添加target = target.long()
总结:能正常运行baseline的过程是磕磕绊绊的,里面还存在很多代码我还不太明白它的具体含义,但是我希望能通过接下来的组队学习弄明白他们的意思并能真正理解这次赛题的思路,同时学习他的整体框架,争取做到举一反三,在拿到其他框架时可以更快地上手。


















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









