




数据分析-pandas数据处理
概述
业务建模流程
- 不是机器学习建模流程
- 将业务抽象为分类or回归问题
- 定义标签,得到y
- 选取合适的样本,并匹配出全部的信息作为特征的来源
- 特征工程 + 模型训练 + 模型评价与调优(相互之间可能会有交互)
- 输出模型报告
- 上线与监控
特征工程
- 基础特征构造(基础特征提取)
- 特征预处理
- 数据清洗/归一化/标准化
- 特征衍生— 用已有的特征构造新的特征
- 多项式 平方 三次方
- 特征交叉
- 数值 x1*x2
- 离散:交叉组合
- 非线性变换— 用非线性函数对原特征进行计算
- 对数/指数/ cos/sin/相除得到比例/ knn中的近邻法/svm中的核方法
- 特征筛选和特征降维— 防止过拟合,减小计算量
数据清洗
- 缺失值,异常值和重复值的处理
缺失值处理
- 缺失值分类
- 行缺失/列缺失
- 处理方法
- 删除
- 原则:根据确实比例和重要性进行衡量
- 删除
- 删除行— 数据量大的时候可以删除空行
- 注意问题
- 删除后数据量小了不能删
- 注意类别平衡问题
- 注意问题
- 删除列
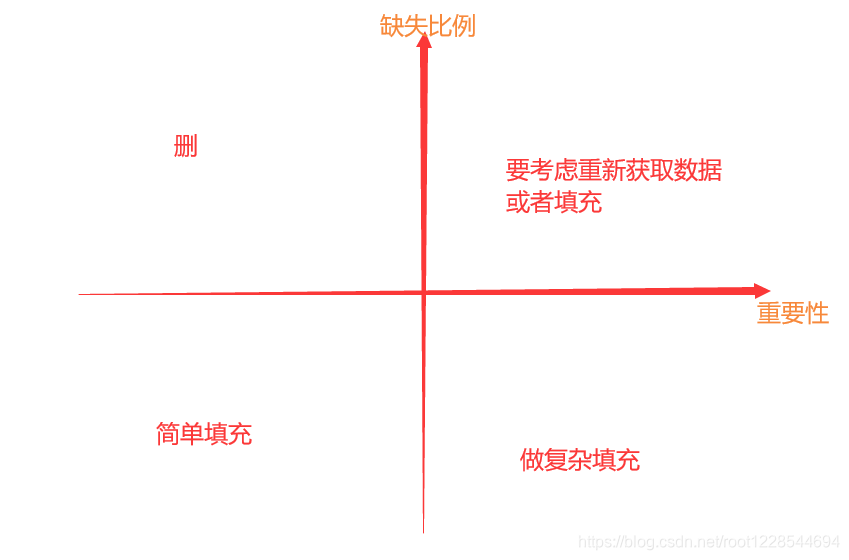
- A:直接删出特征
- B:重新获取数据
- C:删或者简单填充
- D:精准填充
填充
- 统计法 --简单填充
- 数值:均值,中位数
- 类别特征:众数
- 模型法
- 用没有确实的数据作为训练数据,训练模型,对缺失数据进行预测,来补全缺失值
- 数值:用回归模型
- 类别:分类模型
- 用没有确实的数据作为训练数据,训练模型,对缺失数据进行预测,来补全缺失值
- 逻辑推测—比较常用的方法
- 身份证号推测年龄,名字推测性别
- 专家补全
- 随机填充
-
- 真值转换法
- 将缺失值本身也看成是一种值
- 性别:男,女 未知
- 地铁线路未知代表没有地铁
- 注意:距离地铁的距离 0-1 2:代表离地铁站很远
- 注意:要跟业务人员沟通后确定
- 不处理
- 很多算法可以兼容缺失值
- knn,决策树,xgboost等
- 很多算法可以兼容缺失值
- 真值转换法
- 缺失值处理套路
- 发现缺失值
- 统计每个特征中缺失值比例
- 考虑如何额处理缺失值
异常值(极值)处理
如何判断异常:
-
正态分布
-
画箱线图
- boxplot
-
异常检测算法: GMM、孤立森林
-
判断异常值
- 假异常:有业务导致的异常数据,真实存在的
- 真异常:就是数据本身有异常
-
异常值处理
- 删
- 不删:
- 由业务导致的假异常 ,反映的是真实业务
- 做异常检测不用删
- 对异常值不敏感的算法
- 决策树:对数值型异常值不敏感
- 原因:决策树关注的顺序,不是值本身的大小
- 1,2,3,4,5,6,7,8
- 决策树:对数值型异常值不敏感
- 看成缺失值进行填充
重复值处理
- 去重
- 什么时候不去重
- 样本不平衡的时候重复采样的数据
- 真实业务产生的重复数据
python数据清洗案例
import pandas as pd
import numpy as np
from sklearn.impute import SimpleImputer
#缺失值处理
df=pd.DataFrame(np.random.randint(0,10,(6,4)),columns=['col1', 'col2', 'col3', 'col4'])
df.iloc[1:3,1]=np.nan
df.iloc[4,2:]=np.nan
df
df.isnull()
df.isnull().any(0)
df.isnull().sum()
df2=df.dropna()
df2
nan_model=SimpleImputer(missing_values=np.nan,strategy='mean') #使用sklearn填充空值
result=nan_model.fit_transform(df)
result
# pandas填充
# 向上填充
df3=df.fillna(method='backfill')
# 向上填充
df3=df.fillna(method='bfill',limit=1)
# 向下填充
df4=df.fillna(method='pad')
# 指定值填充
df5=df.fillna(0)
# 字典为每个列指定不同的填充
df6=df.fillna({
'col2':10,'col3':100})
df7=df.fillna(df.mean())
# 异常值
import pandas as pd
df=pd.DataFrame({
'col1': [1, 120, 3, 5, 2, 12, 13],
'col2': [12, 17, 31, 53, 22, 32, 43]
})
df
z_score=(df-df.mean())/df.std()
z_score
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
new=sc.fit_transform(df)
pd.DataFrame(new)
z_score.abs()<=2.2
df[(z_score.abs()<=2.2)].dr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1896
1896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









