




 本文详细介绍了Pandas库,包括其数据结构Series和DataFrame,索引操作、算术运算、数据排序、统计计算、层次化索引及读写数据操作。通过实例展示了如何使用Pandas进行数据处理,帮助读者掌握数据操作技巧。
本文详细介绍了Pandas库,包括其数据结构Series和DataFrame,索引操作、算术运算、数据排序、统计计算、层次化索引及读写数据操作。通过实例展示了如何使用Pandas进行数据处理,帮助读者掌握数据操作技巧。
系列文章目录
1.Pandas的数据结构分析
2 . Pandas索引操作及高级索引
3.算术运算与数据对齐
4. 数据排序
5.统计计算与描述
6.层次化索引
7.读写数据操作
文章内容
1.Pandas的数据结构分析
Series:一维的数据结构。能够保存任何类型的数据,主要由一组数据和与之相关的索引两部分构成。
class pandas.Series(data = None,index = None,dtype = None, name = None,copy = False,fastpath = False)
# 创建Series类对象
ser_obj = pd.Series([1, 2, 3, 4, 5])
# 创建Series类对象,并指定索引
ser_obj = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
#使用dict进行构建
year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5} ser_obj2 = pd.Series(year_data)
# 获取ser_obj的索引
ser_obj.index
# 获取ser_obj的数据
ser_obj.values
# 获取位置索引3对应的数据
ser_obj[3]
DataFrame:二维的、表格型的数据结构。类似于二维数组或表格(如excel)的对象,它每列的数据可以是不同的数据类型。
pandas.DataFrame(data = None,index = None,columns = None, dtype = None,copy = False )
# 创建数组
demo_arr = np.array([['a', 'b', 'c'],
['d', 'e', 'f']])
# 基于数组创建DataFrame对象
df_obj = pd.DataFrame(demo_arr)
#按照指定索引的顺序进行排列
df_obj = pd.DataFrame(demo_arr, columns=['No1', 'No2', 'No3'])
# 通过列索引的方式获取一列数据
element = df_obj['No2']
# 查看返回结果的类型
type(element)
# 通过属性获取列数据
element = df_obj.No2
# 查看返回结果的类型
type(element)
# 增加No4一列数据
df_obj['No4'] = ['g', 'h']
# 删除No3一列数据
del df_obj['No3']
2. Pandas索引操作及高级索引
Pandas中的索引都是Index类对象,又称为索引对象,该对象是不可以进行修改的,以保障数据的安全。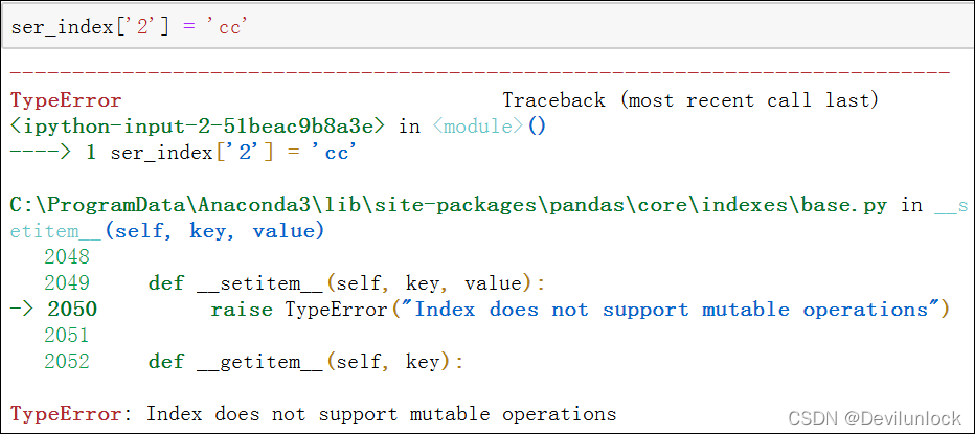
reindex(),:对原索引和新索引进行匹配,也就是说,新索引含有原索引的数据,而原索引数据按照新索引排序。
用法:DataFrame.reindex(labels = None,index = None, columns = None,axis = None,method = None, copy = True,level = None,fill_value = nan,limit = None,tolerance = None )
fill_value参数来指定缺失值
ser_obj.reindex(['a', 'b', 'c', 'd', 'e', 'f'], &nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5913
5913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









