




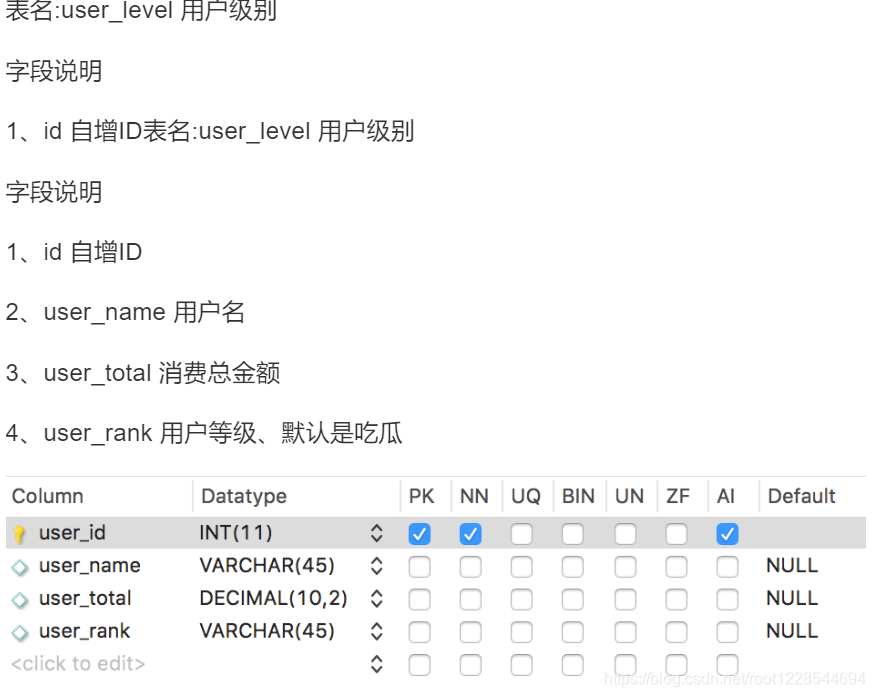
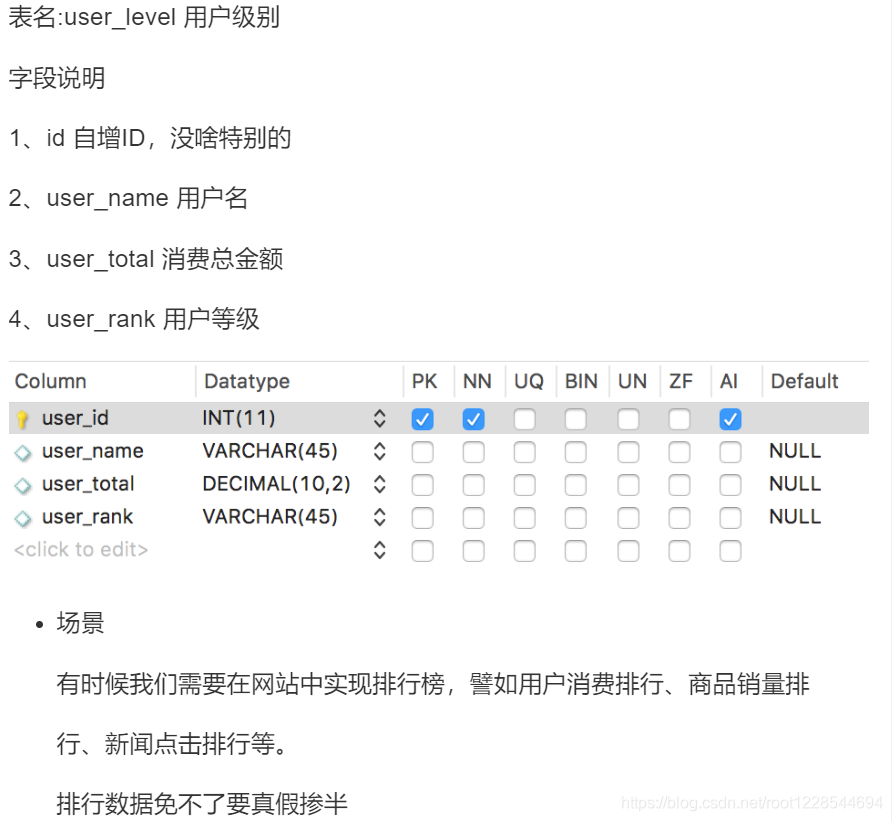
SQL高级操作
Sql高级操作
取出数据并显示行号
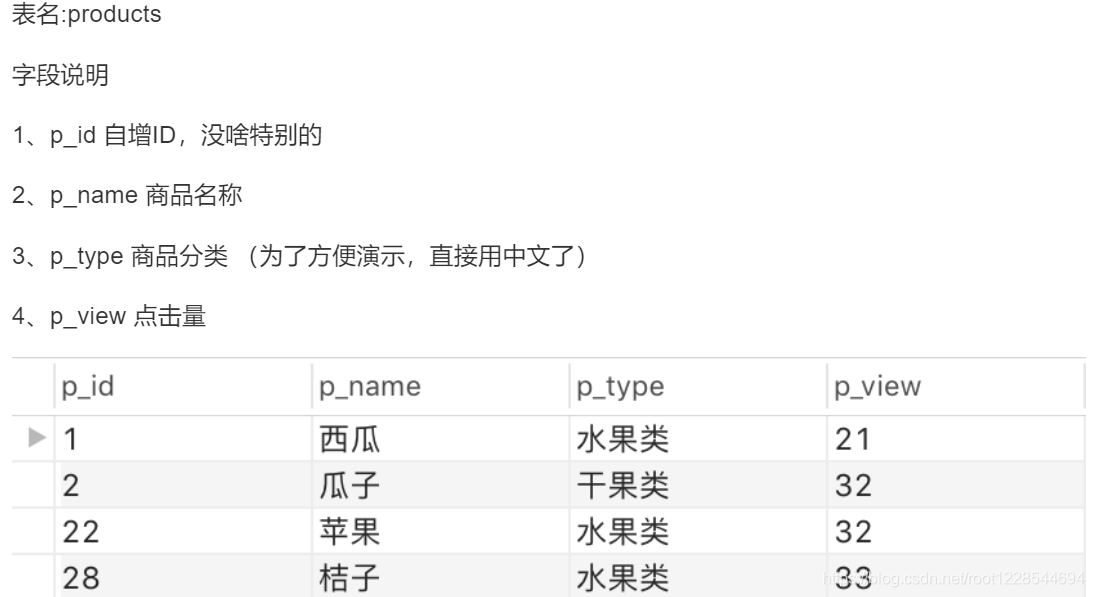
select p_name,p_type,p_view from products ORDER BY p_view desc
添加行号
基本设置方法:set @xxx=xxxx; select @xxxx;只要会话不结束,这个变量就一直存在。
对变量进行赋值
:= 这才是mysql对变量真正赋值的方式
如:set @age=10; select @age:=10;
select p_name,p_type,p_view,@rownum:=@rownum+1 from products ORDER BY p_view desc
存在问题:如果这个变量 一上来没定义,则就一直是null
mysql的 ifnull函数
IFNULL(expr1,expr2)
expr1 不为 NULL,则 IFNULL() 的返回值为 expr1; 否则其返回值为 expr2
select p_name,p_type,p_view, IFNULL(@rownum:=@rownum+1,@rownum:=1) from products a ORDER BY p_view desc
存在问题:第二次运行 @rownum不是从1开始的
set @rownum=0;
select p_name,p_type,p_view,@rownum:=@rownum+1 as rank from products ORDER BY p_view desc;
select p_name,p_type,p_view,@rownum:=@rownum+1
from products a,(select @rownum:=0) b ORDER BY p_view desc
排名 行号
-
变量
- set @XXX=XXX
- select @XXX:=XXX
-
放在from后面: 只会执行一次
-
select子句执行顺序: 整体第一行—最后一行,对于样一行来讲从左到右
-
一定要排序
分组内排序-分组中取前N条
IF(条件,表达式1,表达式2)
如果条件成立 则返回表达式1,否则是2
综合评价算法
select a.p_type,a.p_name,a.p_view from products a order by a.p_type desc, a.p_view desc
- 组内排名 计算行号
select a.p_type,
a.p_name,
a.p_view,
if(p_type=@pre_type,@row_num:=@row_num+1,@row_num:=1) as rank,
@pre_type:=p_type
from products a,(select @row_num:=0,@pre_type:=null) b
order by a.p_type , a.p_view desc
- 必须先考虑排序的字段(按照谁分组,就按照谁排序),最后排序的一定要是排名的字段
- 考虑需要几个变量
- 行号需要一个变量
- 你需要比较几个字段,就定义几个变量
- 写if判断的条件
- 注意最后要赋值
面试分析
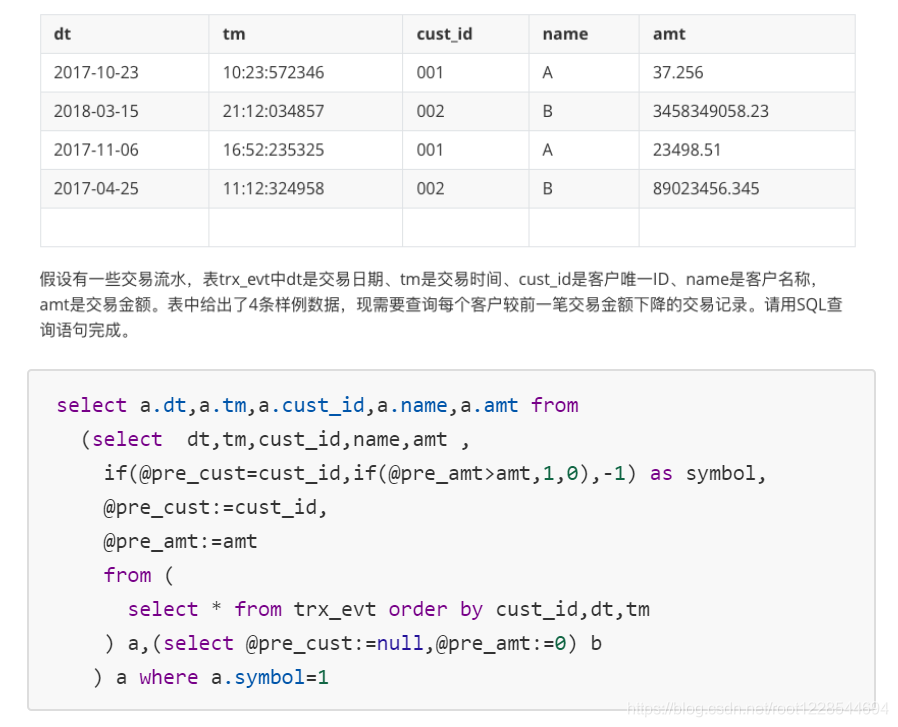
- 核心理论: 当需要拿当前行和上一行的数据进行比较的时候,就可以使用变量来存储上一行的值
计算商品评分、及时补货
原数据表不是所有商品都有销量。
IFNULL(expr1,expr2) expr1 不为 NULL,则 IFNULL() 的返回值为 expr1; 否则其返回值为
expr2
-- 根据分类显示出商品的名称、点击量和销售量情况。没有销售的置为0
SELECT a.p_id, a.p_name,a.p_type,a.p_view,
IFNULL( b.p_sales, 0 ) AS p_sales
FROM products a
LEFT JOIN products_sales b
ON a.p_id = b.p_id
分拆SQL, 先实现 每个分类下的总销售数和总条数计算
SELECT p_type,round( sum( sales )/ count(*), 0 ) AS sales_avg
FROM(SELECT p_type,a.p_name,a.p_view,
IFNULL( b.p_sales, 0 ) AS sales
FROM products a
LEFT JOIN products_sales b ON a.p_id = b.p_id ) c
GROUP BY p_type
上面两个SQL进行合并
select a.*,b.sales_avg,
from
(select a.p_id, a.p_name, a.p_type, a.p_view,
IFNULL(b.p_sales,0) as p_sales
from products a
left join products_sales b
on a.p_id=b.p_id) a
join
(SELECT p_type, round( sum( sales )/ count(*), 0 ) AS sales_avg
FROM (SELECT p_type, a.p_name, a.p_view,
IFNULL( b.p_sales, 0 ) AS sales
FROM products a
LEFT JOIN products_sales b
ON a.p_id = b.p_id ) c
GROUP BY p_type ) b
on a.p_type=b.p_type
再加入商品的分类点击量平均值
select
a.*,b.sales_avg,c.avg_view
from
(
select
a.p_id,a.p_name,a.p_type,a.p_view,IFNULL(b.p_sales,0) as p_sales
from products a left join products_sales b on a.p_id=b.p_id
) a
join
(
SELECT
p_type,
round( sum( sales )/ count(*), 0 ) AS sales_avg
FROM
(
SELECT
p_type,
a.p_name,
a.p_view,
IFNULL( b.p_sales, 0 ) AS sales
FROM
products a
LEFT JOIN products_sales b ON a.p_id = b.p_id
) c
GROUP BY
p_type
) b
on a.p_type=b.p_type
join
(
select p_type,round(avg(p_view)) as avg_view from products group by p_type
) c
on b.p_type=c.p_type
实现方法
分别把 计算各自的
1、点击量/点击量均值
2、销售量/销售量均值
两者相加,可以得到一个简单评分
加入权重
点击量评分占30%、70%
select
a.*,b.sales_avg,c.avg_view,
(a.p_view/c.avg_view)*0.3+(a.p_sales/b.sales_avg)*0.7 as rating
from
(
select
a.p_id,a.p_name,a.p_type,a.p_view,IFNULL(b.p_sales,0) as p_sales
from products a left join products_sales b on a.p_id=b.p_id
) a
join
(
SELECT
p_type,
round( sum( sales )/ count(*), 0 ) AS sales_avg
FROM
(
SELECT
p_type,
a.p_name,
a.p_view,
IFNULL( b.p_sales, 0 ) AS sales
FROM
products a
LEFT JOIN products_sales b ON a.p_id = b.p_id
) c
GROUP BY
p_type
) b
on a.p_type=b.p_type
join
(
select p_type,round(avg(p_view)) as avg_view from products group by p_type
) c
on b.p_type=c.p_type
mysql中自连接的使用
自连接就是自己和自己进行inner join或 left join
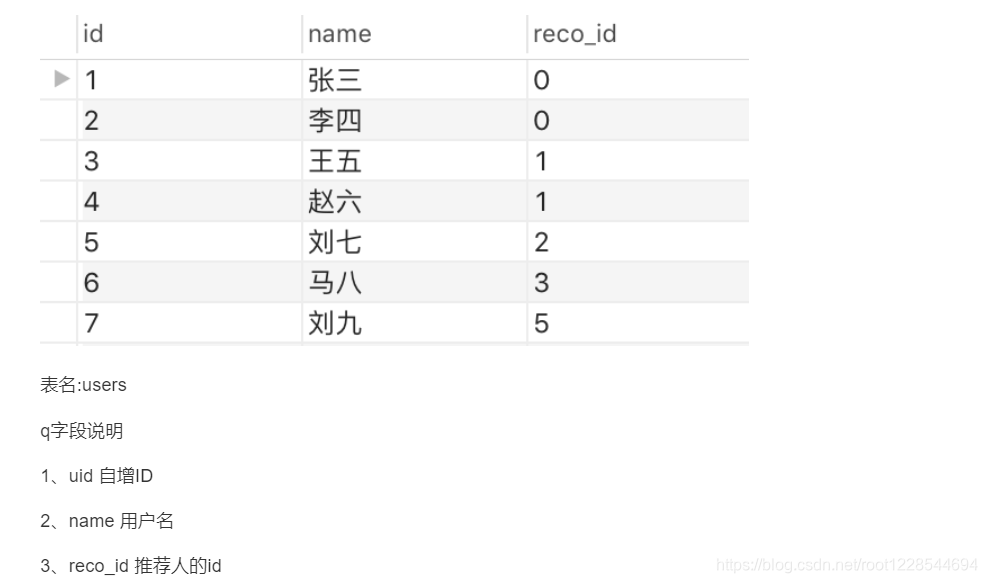
SELECT
a.u_name AS username,
b.u_name AS refer
FROM
webusers a INNER JOIN webusers b
ON a.p_id = b.u_id;
GROUP_CONCAT
通常和group by 一起使用,把相同的分组的字段值连接起来
SELECT
GROUP_CONCAT( u_name ORDER BY u_id DESC SEPARATOR '|' ) AS u,
p_id
FROM
webusers
GROUP BY
p_id;
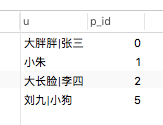
SELECT
u,u_name
from (
SELECT
GROUP_CONCAT( u_name ORDER BY u_id DESC SEPARATOR '|' ) AS u,
p_id
FROM
webusers
GROUP BY
p_id
) a,
inner join webusers b
on a.p_id=b.u_id
不等连接
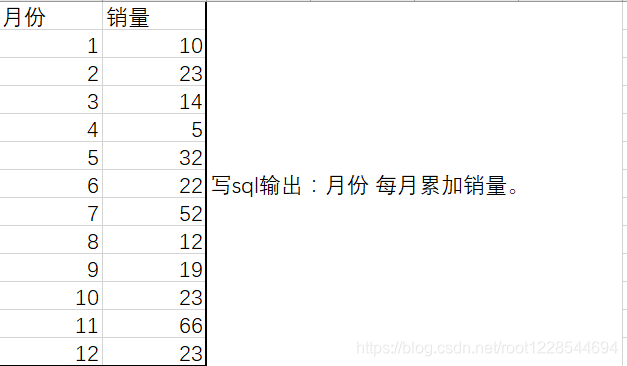
求累和问题
select a.month,sum(b.money) as cum_sales
from sale a,sale b
Where b.month<=a.month
Group by a.month
order by a.month
删除重复数据
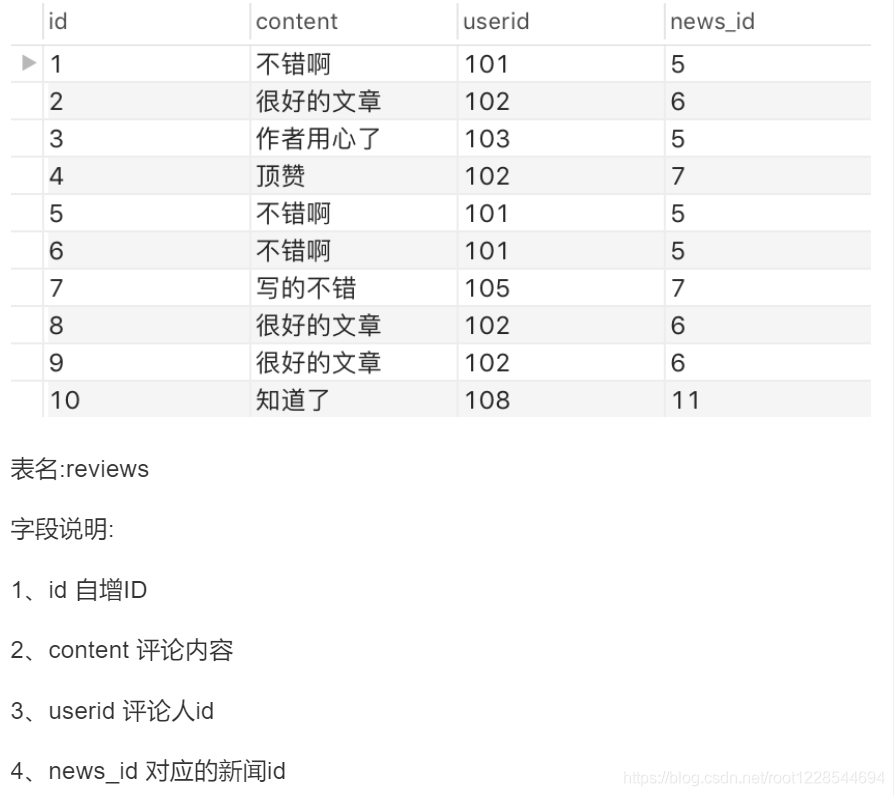
1. 内容查看
SELECT
r_content,
r_userid,
count(*)
FROM
reviews
GROUP BY
r_content,
r_userid
2. 找到重复的内容
SELECT r_content,r_userid FROM reviews GROUP BY r_content,r_userid
HAVING COUNT(*)>1
3. 找到重复值的唯一id
SELECT r_id FROM reviews GROUP BY r_content,r_userid
HAVING COUNT(*)>1
4. 删除
DELETE FROM reviews_copy2 WHERE (r_content,r_userid)
IN
(SELECT r_content,r_userid FROM (SELECT r_content,r_userid FROM reviews_copy2 GROUP BY r_content,r_userid
HAVING COUNT(*)>1) s1)
AND
r_id NOT IN (SELECT r_id FROM (SELECT r_id FROM reviews_copy2 GROUP BY r_content,r_userid
HAVING COUNT(*)>1) s2);
5.利用group_concat
select GROUP_CONCAT(r_id) as ids,r_content,r_userid,count(*)
from reviews
GROUP BY r_content,r_userid
HAVING count(*)>1

有重复数据不插入或更新的处理方法
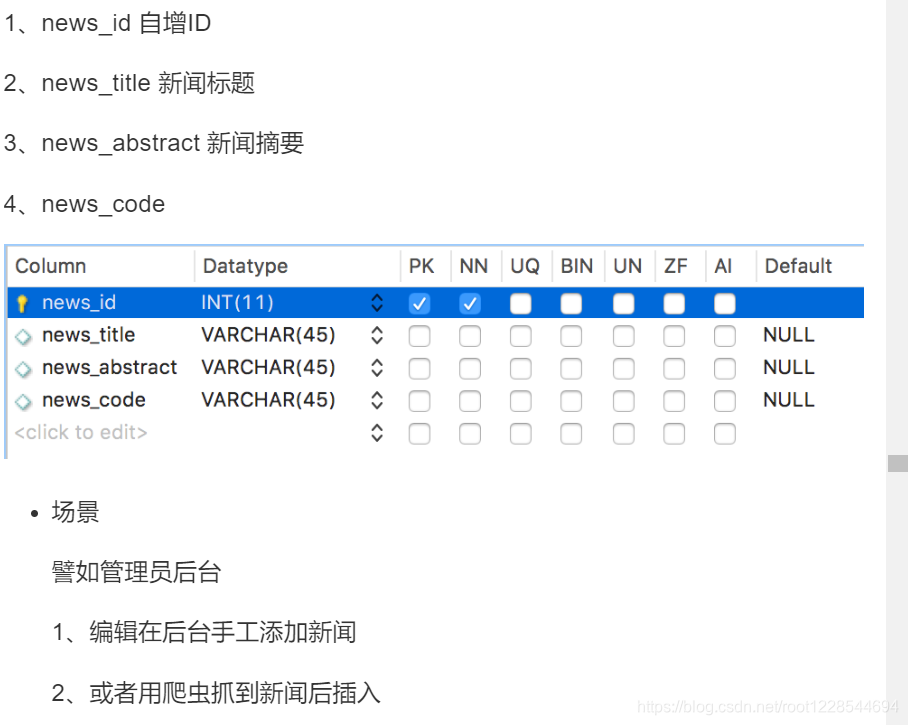
可能需要插入相同的新闻
insert into news(news_id,news_title,news_abstract,news_code)
VALUES(1,'新闻标题1','新闻摘要1','a');
利用news_code字段
在程序拼凑SQL语句时,执行一个md5 过程,
让news_code值=md5(标题的内容+摘要的内容)
insert into news(news_title,news_abstract,news_code)
VALUES('新闻标题1','新闻摘要1'
,MD5(CONCAT('新闻标题1','新闻摘要1')));
设置news_code字段为唯一索引
扩展
如果当新闻被重复插入时,需要统计次数。判断是否“失误的次数太多”。加入一个字段,叫做dupnum,int型 (用来记录重复的次数)。
ON DUPLICATE KEY UPDATE(mysql特有的语法) 一般跟在insert 后面出现。 如果insert会导致UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE
insert into news(news_title,news_abstract,news_code)
VALUES('新闻标题2','新闻摘要2'
,MD5(CONCAT('新闻标题2','新闻摘要2')))
on DUPLICATE key
update dupnum=dupnum+1
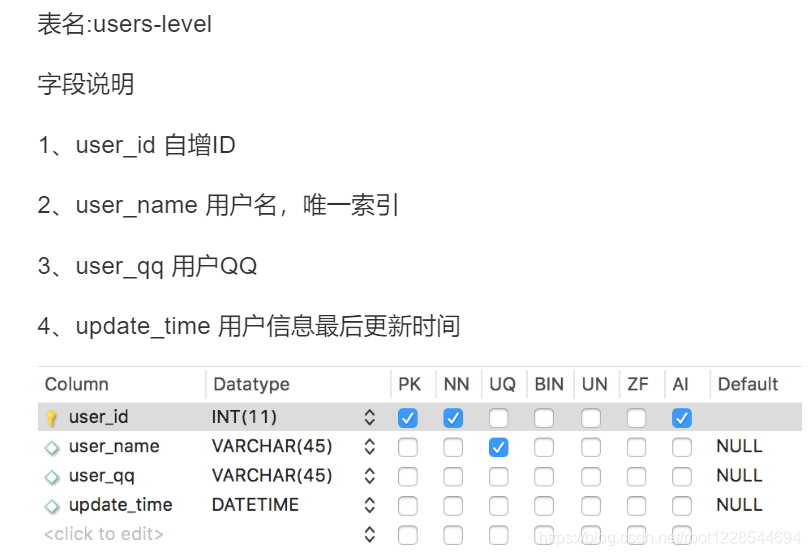
1.插入记录时
insert into users(user_name,user_qq) values('ccy','123')
2.一旦有用户更新记录
insert into user_info(user_name,user_qq) values('ccy','345')
on DUPLICATE key update update_time=now(),user_qq=values(user_qq);
小结:重复数据
- new_code 唯一索引
- MD5(concat(标题,摘要))
- 不插入记录次数:
- on DUPLICATE key
update dupnum=dupnum+1
- on DUPLICATE key
update表子查询、多条件判断
select 查询时 对字段进行特殊条件处理
select *,
case user_total
when 100 then '消费正好满100的用户'
else '其他'
end
from user_level
select *,
case
when user_total> 50 and user_total<100 then '消费超过50的用户'
when user_total> 100 then '消费超过100的用户'
else '其他'
end
from user_level
update
update user_level,(select avg(user_total) as avg from user_level) b set user_rank=
case
when round(user_total/avg)>=1 and round(user_total/avg)<2 then '白金用户'
when round(user_total/avg)>=2 then '黄金用户'
ELSE
'普通'
end where user_total>=b.avg
order by 实现"排名作弊"
union 配合子查询排序
需求是
1、根据字段 user_total倒排序
2、其中id为2,4,6的用户为我们“内部用户”,置顶
常规做法---union
select * from (select * from user_level where id in (2,4,6) ORDER BY user_total desc LIMIT 1000) a
union
select * from (select * from user_level where id not in (2,4,6) ORDER BY user_total desc LIMIT 1000) b
新做法
select * from user_level order by id in(4,6,2) and id<>2 desc,user_total desc
10
select * from user_level order by id in (2,4,6) desc, user_total desc
select * from user_level order by id in (2,4,6)and id<>2 desc, user_total desc
连续签到X天用户列表
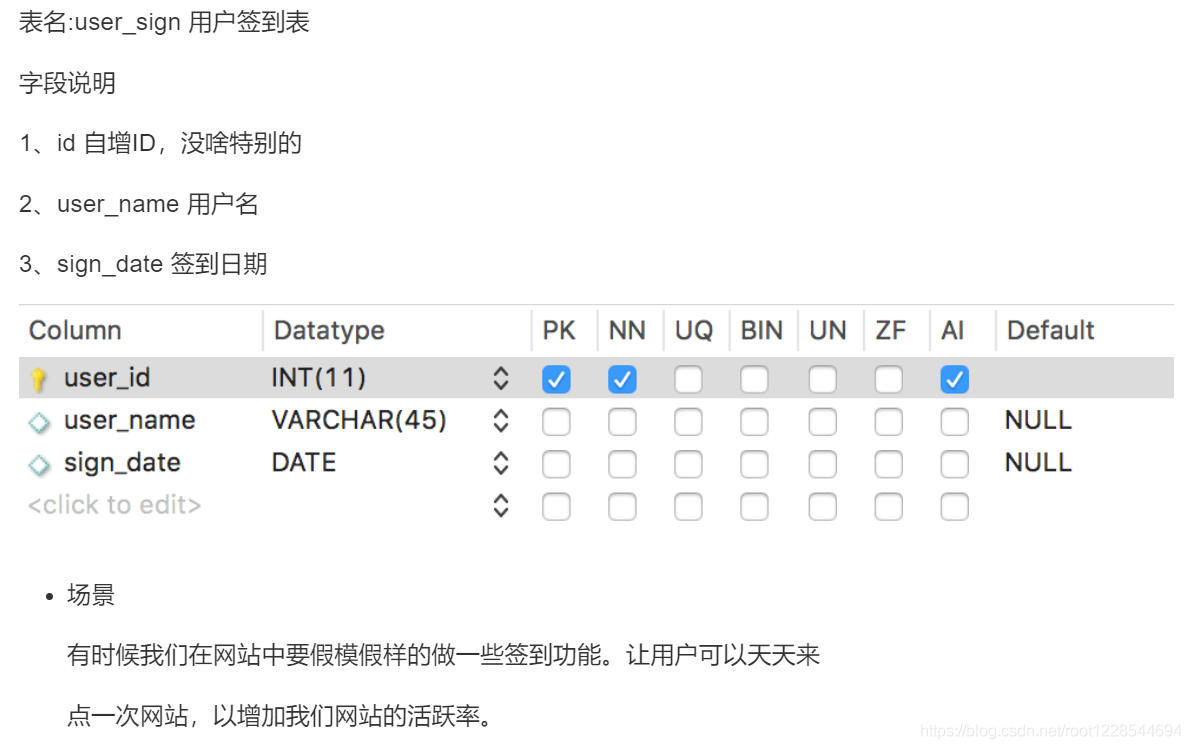
1.分组排序
select user_name,sign_date from user_sign
GROUP BY user_name,sign_date ORDER BY user_name,sign_date
2.加入分组行号
SELECT
user_name,sign_date,
IF
(
@pre = user_name,
@rownum := @rownum + 1,
@rownum := 1
),
@pre := user_name
FROM
(
SELECT
user_name,sign_date FROM user_sign GROUP BY user_name,sign_date
ORDER BY user_name,sign_date
) a,
(SELECT @pre := '',@rownum := 0 ) b
计算相邻两行的日期是否 相差一天
mysql的函数 datediff(date1,date2)
返回两个日期之间的天数 注意是 date1-date2
select
user_name,sign_date,
IF(@pre=user_name and DATEDIFF(sign_date,@pre_date)=1,
@rownum:=@rownum+1,@rownum:=1),
@pre:=user_name,@pre_date:=sign_date
from (
select user_name,sign_date from user_sign
GROUP BY user_name,sign_date ORDER BY user_name ,sign_date ) a ,
(select @pre:='',@rownum:=0,@pre_date:='' ) b
连续签到
- 去重— 分组去重
- 排序 user_name sign_date
- 思考变量 比同一个人 比连续(日期相差1天)
- 三个变量
子查询去重、获取商品分类最新销售情况
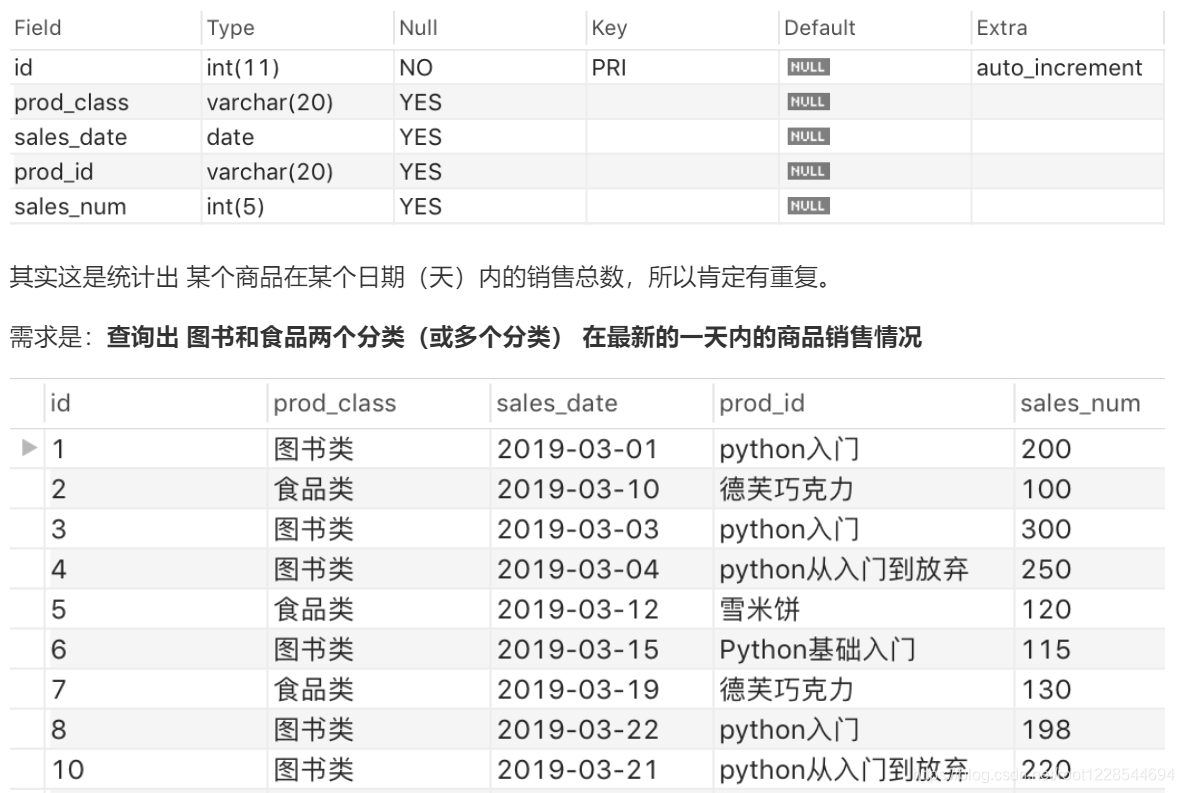
1. 做法1
select prod_class, max(sales_date) as sn from prod_sales
GROUP BY prod_class
或
select prod_class,prod_id, max(sales_date) as sn from prod_sales
GROUP BY prod_class,prod_id
2. 做法2
2.1 找出各个分类中 最新有销售的日期
select prod_class, max(sales_date) as sn from prod_sales
GROUP BY prod_class
2.2合并
select a.* from prod_sales a INNER JOIN
(select prod_class,max(sales_date) as sn from prod_sales
GROUP BY prod_class) b
on a.prod_class=b.prod_class and a.sales_date=b.sn order by prod_class
多表关联update(用户积分奖励)
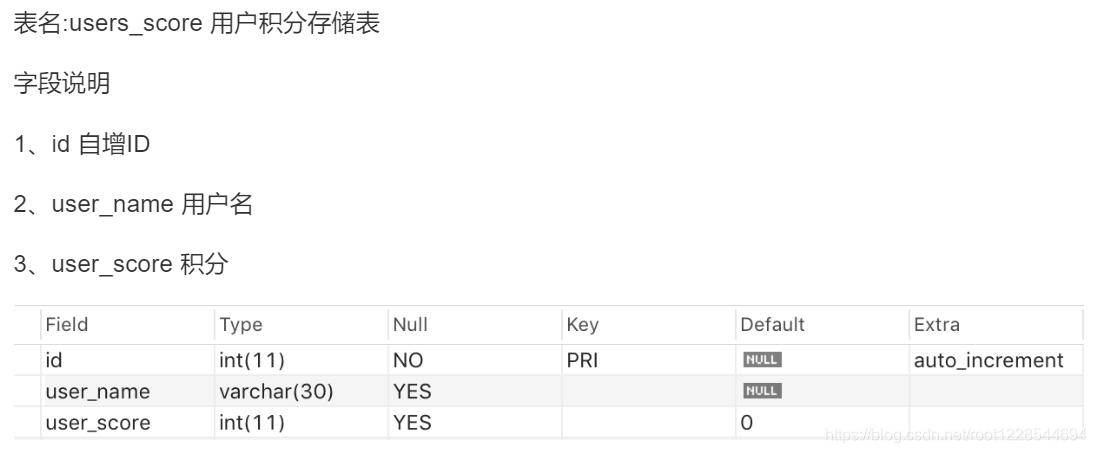
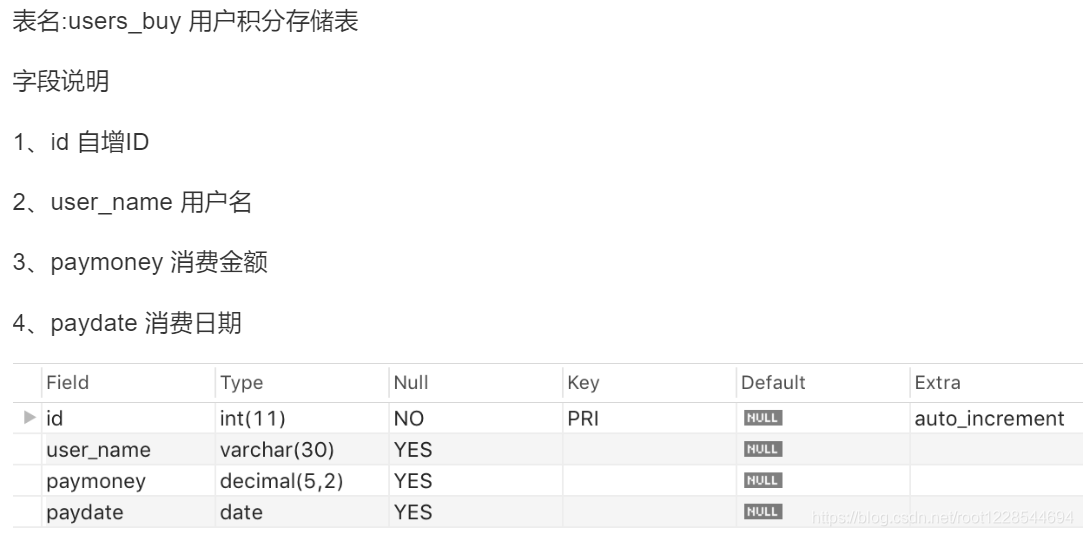
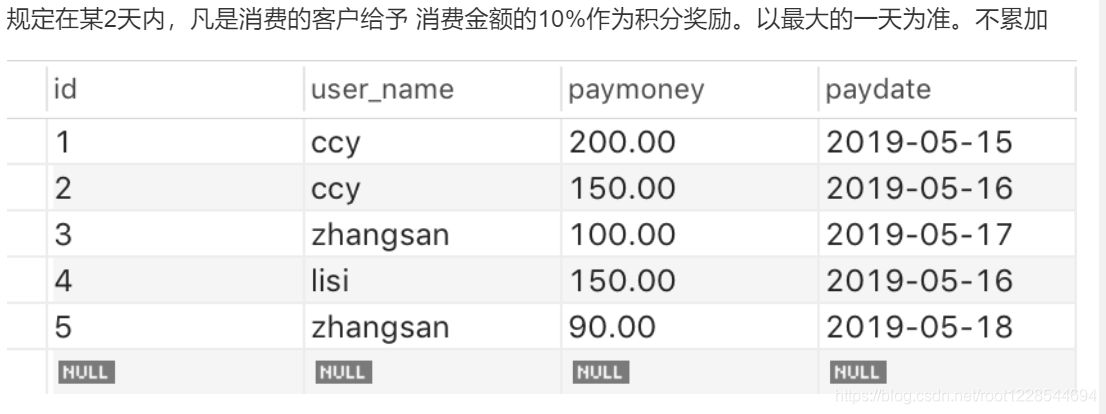
找出消费最大的金额
select max(paymoney) as mp,user_name from users_buy group by user_name
解法1:
1、写个存储过程
利用游标循环,然后一句句update users_score set xxxxx
2、用程序把上述语句取出来,循环
继续一句句 update xxxxx
解法2:— 连接表其实就实现了筛选的功能
update
users_score a
INNER JOIN
(select max(paymoney) as mp,user_name from users_buy group by user_name ) b
on a.user_name=b.user_name
set a.user_score= a.user_score+(b.mp*0.1)
-- 在set子句中做子查询 — 注意子查询返回空值问题
UPDATE users_score a
SET user_score = user_score + IFNULL(( -- 加ifnull的目的是防止子查询返回空值
SELECT
max( paymoney )
FROM
users_buy
WHERE
user_name = a.user_name
),
0
)* 0.1
小知识总结
-
set @xxx=xxxx; select @xxxx;
只要会话不结束,这个变量就一直存在。
:= 是mysql对变量真正赋值的方式
如:set @age=10; select @age:=10; -
mysql的 ifnull函数
IFNULL(expr1,expr2)
expr1 不为 NULL,则 IFNULL() 的返回值为 expr1; 否则其返回值为 expr2 -
IF(条件,表达式1,表达式2)
如果条件成立 则返回表达式1,否则是2 -
GROUP_CONCAT
通常和group by 一起使用,把相同的分组的字段值连接起来 -
计算相邻两行的日期是否 相差一天
mysql的函数 datediff(date1,date2)
返回两个日期之间的天数 注意是 date1-date2
sql计算各种指标
获取指定日期的活跃人数
explain
select COUNT(DISTINCT userid) ,DATE_FORMAT(logintime,"%Y-%m-%d")
from user_login
where DATE_FORMAT(logintime,"%Y-%m-%d")="2019-02-01"
explain
select count(distinct userid),DATE_FORMAT(logintime,'%Y-%m-%d')
from user_login
where DATEDIFF(logintime,'2019-02-01')=0
explain
select count(distinct userid),DATE_FORMAT(logintime,'%Y-%m-%d')
from user_login
where logintime>="2019-02-01" and logintime<"2019-02-02"
Explain:描述sql查询的效率,以下描述效率从高到低
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > ra
- 最好是写成范围 > <=
统计指定日期范围内用户的登录总次数、每天登录次数
- 一定要筛选出前一天注册的用户
select
count(DISTINCT userid),DATE_FORMAT(logintime,'%Y-%m-%d')
from user_login
where logintime>="2019-03-06" and logintime<"2019-03-07" and userid in (
select userid from user_info where addtime>='2019-03-05' and addtime<'2019-03-06'
)
select
count(DISTINCT b.userid),DATE_FORMAT(logintime,'%Y-%m-%d')
from
(select userid from user_info where addtime>='2019-03-05' and addtime<'2019-03-06') a
join user_login b
on a.userid=b.userid
where logintime>="2019-03-06" and logintime<"2019-03-07"
指定日期范围内每天都登录的用户(连续x天都登录、加行号)
- 统计指定日期范围内每天都登录的用户
- 6天每天都登陆,意味着登录的不同天数必须有6个 按照userid分组,统计每个用户登录的不同天的数目=6
select
userid
from
(
select userid,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc from user_login
where logintime>='2019-03-05' and logintime<'2019-03-11'
group by userid,dd
) a
group by userid
having count(*)=6
日活,连续七天的日活
- 步骤:
- 统计每天每个用户登录次数 筛选出日活用户
- 再次进行统计,统计日活用户数
统计每个用户登录的次数
select
userid,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc
from
user_login
where logintime>='2019-03-02' and logintime<'2019-03-03'
group by userid
having cc>=2
统计人数就是日活
select
count(*) as dau
from
(select
userid,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc
from
user_login
where logintime>='2019-03-02' and logintime<'2019-03-03'
group by userid
having cc>=2
) a
计算连续7天的日活
首先统计出每天每个用户登录的次数
select
userid,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc
from
user_login
where logintime>='2019-03-02' and logintime<DATE_ADD('2019-03-02' ,INTERVAL 7 DAY)
group by userid,dd
having cc>=2
统计每一天的日活
select
dd,count(userid) as dau
from
(select
userid,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc
from
user_login
where logintime>='2019-03-02' and logintime<DATE_ADD('2019-03-02' ,INTERVAL 7 DAY) group by userid,dd
having cc>=2
) a
group by dd
统计指定日期日活用户的日增长率(一条SQL)
- 注意: 数据要往前算一天,最终结果在进行limit
- 解决方案: 使用变量保存上一天的日活进行计算
select
dd,(dau-@pre_dau)/@pre_dau as ratio,@pre_dau:=dau
from
(select dd,count(userid) as dau from
(
select userid,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc
from
user_login
where logintime>='2019-03-01' and logintime<DATE_ADD('2019-03-02' ,INTERVAL 7 DAY)
group by userid,dd
having cc>=2
) a
group by dd
) a,
(select @pre_dau:=0 ) b
order by dd
统计月活人数、日活缓存表的使用
- 月活计算
- 按照日和userid分组,统计出每个用户每天登录的次数
- 筛选掉次数<2的记录
- 再对结果按照月份分组,并对userid去重之后计数 就是月活
select
mm,count(DISTINCT userid) as mau
from
(
select
userid,DATE_FORMAT(logintime,"%Y%m") as mm,DATE_FORMAT(logintime,"%Y%m%d") as dd,count(*) as cc
from
user_login
where logintime>='2019-01-01' and logintime<"2019-04-01"
group by userid,dd
having cc>=2
) a
group by mm
缓存表
insert into user_dau (d,dau)
select
d,count(userid) as dau
from
(
select
userid,DATE_FORMAT(logintime,"%Y%m%d") as d,count(*) as cc
from
user_login
where logintime>='2019-02-01' and logintime<"2019-04-01"
group by userid,d
having cc>=2
) a
group by d ORDER BY d
留存率计算
- 留存率
某天进来一批新用户,有的用了一下就再也没回来过,有的用过几次后也离开了,还有些在一定时间段里,能够一直持续活跃使用,这些一直保持活跃的我们称之为留存用户。留存用户占这批次新增用户的比例,就是留存率。
p一般有:
次日留存率:(当天新增的用户中,在注册的第2天还登录的用户数)/第一天新增总用户数;
第3日留存率:(第一天新增用户中,在注册的第3天还有登录的用户数)/第一天新增总用户数;
第7日留存率:(第一天新增的用户中,在注册的第7天还有登录的用户数)/第一天新增总用户数;
第30日留存率:(第一天新增的用户中,在注册的第30天还有登录的用户数)/第一天新增总用户数。 - 连续n日留存
- 计算出第一天注册人数
- 计算出后续几天的每天的登录人数(挑出第一天注册的人)
- 相除计算留存率
select
d,login_num/add_num
from
(
select count(*) AS add_num from user_info where addtime>='2019-03-01'
and addtime <'2019-03-02'
) a,
(
select DATE_FORMAT(logintime,"%Y%m%d") as d, count(DISTINCT userid) as login_num from user_login
where logintime>='2019-03-02' and logintime<'2019-03-08'
and userid in (
select userid from user_info where addtime>='2019-03-01'
and addtime<'2019-03-02')
group by d
) b
笔试题

select week_no, email as driver_name
from (
select driver_id,week_no
from (
select driver_id,order_count,if(@pre=week_no,@rownum:=@rownum+1,@rownum:=1) as rank,@pre=week_no
from (
select driver_id,WEEKOFYEAR(request_at) as week_no ,count(*) as order_count
from trips
where city_id in (1,6,12)
and request_at>=UNIX_TIMESTAMP('2013-06-03 00:08:00') and request_at<=UNIX_TIMESTAMP('2013-06-24 00:08:00')
group by week_no,driver_id
order by week_no,order_count desc
) a,(select @pre:=null,@rownum:=0) b
) a
where rank<=3) a join users b on a.driver_id=b.usersid
- 日期问题 — timestamp 时间戳 时间戳转换成北京时区
- 也可以将日期转换成时间戳进行判断
- 时区问题
- 北京+8
- where条件
- city_id
- request_at
- 分组统计
- 每周 每个司机 两个字段分组 统计每组的记录条数(订单数)
- topn
- 每周订单量前三名
- 组:周
- 排名:订单量
- order by week_no,order_count
- 第一:加行号 @rownum 第二:同一周的一起计算 需要保存上一行的周 @ore_week
- 每周订单量前三名



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









