




《软件方法》2025版

潘加宇
http://www.umlchina.com/url/softmeth2025.html
当前更新时间:2025.7.16
**************************************************
您在阅读《软件方法》时如果发现错误,欢迎通过微信umlchina2告知。如果作者认为有道理,决定在下一次发布时根据您的意见修改,每个错误将付给您5.12元报酬,并在书中说明您的贡献。
(1)任何您认为的错误都可以,包括错别字。
(2)同一错误仅支付最先指正者报酬。
(3)请根据最新版本作指正。
目前指正人有(按指正时间排序):吴佰钊、王周文、刘学斌、成文华、黄树成、李蜀斌、杨雪鸿、王书伟、高洪江、张志坚、龙燔、陈文飞、郭沼兵、陈自平、张彬、李宏伟、赵志军、孙赛刚、孙军、左科、王长福、张守金。
2018版《软件方法(上)》的勘误:
http://umlchina.com/book/errata2ed.html
第1章 ABCD工作流
牵着你走进傍晚的风里,看见万家灯火下面平凡的秘密。
《情歌唱晚》;词:黄群,曲:黄群,唱:曹崴;1994
1.1 利润=需求-设计
1.1.1 利润=需求-设计
利润=收入-成本。不管出售什么,要获得利润,需要两个条件:
(1)售价要高;
(2)成本要低。
妙就妙在,价格和成本之间没有固定的计算公式,这正是创新的动力之源。
放到软件业上,我也炮制了一个式子:
利润=需求-设计
在软件开发中,需求工作致力于解决“提升销售”的问题,设计工作致力于解决“降低成本”的问题,二者不能相互取代。能低成本开发和维护某个系统,不一定能保证它好卖。系统好卖,如果开发和维护成本太高,最终利润还是高不了。
以上说的“利润”、“销售”、“成本”是广义的,可以是金钱,也可以是名声、权力、人力等。
即使你做的是没有在市场上公开出售的单位内部系统,甚至是自己为自己的方便做一个系统,也适用上面的式子。
更为关键的是:需求和设计之间不存在,也不应该存在刻板的一对一映射——也幸亏如此,否则人工智能现在就可以轻易学习其中的映射套路,取代软件开发人员完成所有的工作。目前,软件开发人员存在的价值之一就是根据自己掌握的领域知识和软件开发知识,努力在很多可能的映射方案中挑选出最合适的映射方案,以及创造出更好的映射方案。
我们先来看自古以来就有的一个系统,人,即“人肉系统”。
人肉系统的功能(需求)是(人能够)走路、跑步、跳跃、举重、投掷、游泳……但是设计人肉系统的结构时,并不是从功能(需求)直接映射到设计,得到“走路器官”、“跑步器官”、“跳跃器官”……人肉系统的器官是眼、耳、心、肺、肝、胃、骨架、皮肤……这些器官和人肉系统的功能不是一一对应的,在互相协作以完成系统的功能时,它们和功能之间的关系是多对多的。
图1-1表达了某个人肉系统的需求和设计。可以看到,需求和设计的映射是多对多的。各个器官被各个功能共享,不能说“心脏是老板的”、“肺是老婆的”。
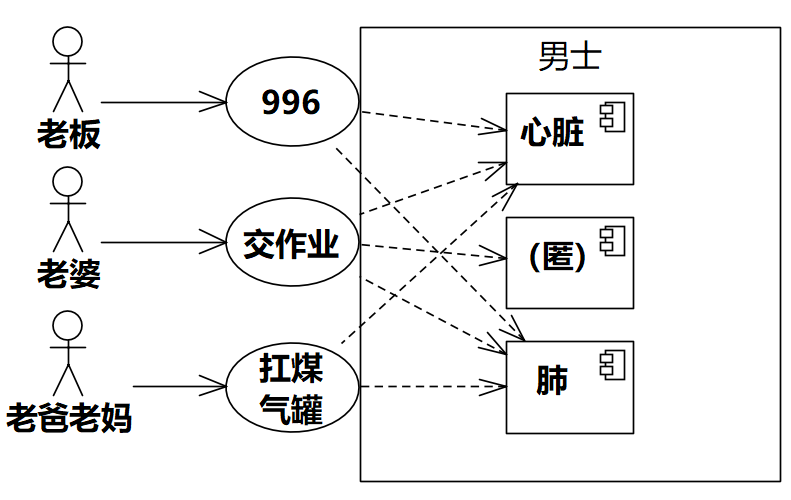
图1-1 人肉系统的需求和设计
★这里要注意一种无知的论调:干嘛要共享,每个功能给它一个心脏不行吗?真实的心脏是肉做的,复制要花成本,软件的代码复制又不用花钱!
图1-1的映射只是造物主——用《异形(Alien)》的说法就是工程师(Engineer)——当初挑选的映射方案。
今天,人类也成为造物主开始“造人”。同样是造能跑能跳能扛的“人”,我们挑选的映射方案可能和人类的造物主(如果存在)当初“造人”的映射方案不一样,如图1-2。当然,目前人类的科学技术水平,连细胞都造不出来,更不用说做到一模一样的方案了。

图1-2 人类和“新人类”
“人”的使用者并不关心这个“造人”的方案。
老板要雇民工扛煤气罐,他只要求这个民工能跑能扛,管他体内构造是心肝脾肺肾(如图1-2上部)还是电路板(如图1-2下部)——如果电路板民工更便宜,他会毫不犹豫地淘汰掉心肝脾肺肾民工。
民工找工作也要从市场的需要来找——“老板,你要雇人扛煤气罐吗,我可以!”,而不是从自己的内部器官出发来找——“老板,我每天都管理我的心脏,你请我吧!”
以上所说的这些,总体意思就是:要学会把需求和设计分开,这也是贯彻全书的核心思想,后面还会反复强调。当然,用词可能会有变化,可能有的时候会说“卖和做分开”,有的时候会说“外和内分开”等等。
软件开发中,如果从需求直接映射设计,会得到大量的重复代码,成本增加;如果从设计出发定义需求,会得到一堆假的“需求”,销量下降。不管是哪一种情况,利润都会下降。
而这一点,很多软件开发人员并没有意识到。
1.1.2 需求-设计混淆的常见错误
1.1.2.1 “子系统”其实是需求包
我们经常听到这样的说法,“本系统分为八大子系统,包括销售子系统、财务子系统、库存子系统……”,这就是需求和设计不分的一个例子。其实,说话人可能应该这样表达自己的意思:“本系统的功能需求分为八大需求包……”。
需求包是基于涉众视角对系统功能分包而得到的,子系统(用UML的说法是组件)是基于内部视角根据系统部件的耦合和内聚情况切割而得到的,这两者不是一一对应的。所谓的“财务子系统”,其实可能是“把财务人员使用的功能放在一个包里”,如图1-3。
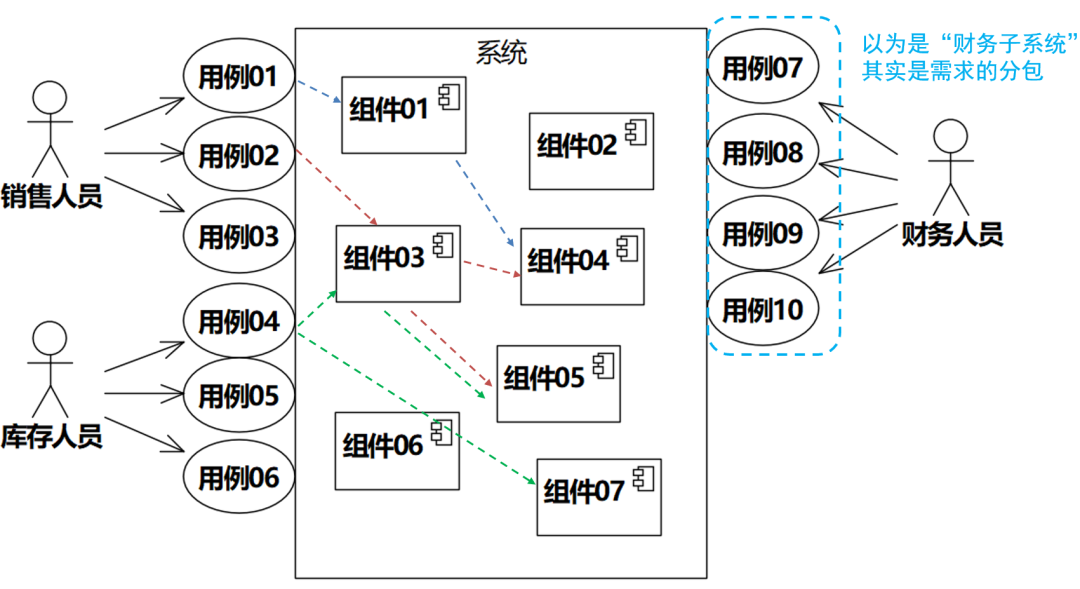
图1-3 “子系统”其实是需求的分包
1.1.2.2 “功能模块”是错误用语
另一个常见的需求和设计不分的说法是“功能模块”。
功能(Function)这个词,如果应用于信息系统,描述的是:系统作为一个整体,接收到外部请求时应该产生的效果。
模块(Module)这个词,如果应用于信息系统,描述的是表示系统分解后得到的各个组成部分。
“功能模块”意味着在意识里认为“功能”和“模块”有直接的映射关系,甚至认为“模块”是属于某个“功能”的模块,是为了完成某个“功能”而存在的。
用前面的“人肉系统”来举例,“功能模块”就是“走路器官”、“走路子系统”……,这是错误的。
******
不但“功能模块”不应该连起来说,而且“功能”和“模块”这两个词的含义也是模糊的。
例如,以自助柜员机(ATM)为目标系统,“取现金”是“功能”,“登录”也是功能,“计算手续费”也是“功能”,到底“功能”有多大?“模块”是一个控件?还是一个类?还是若干个类形成的组件?
因此,本书后文中,会尽量使用更精确的术语。例如,以ATM为目标系统,“取现金”是一个用例,“登录”是用例中的一个回合,“计算手续费”是一个步骤,系统里面可能会有一个“账户”类……。
1.1.2.3 微服务的遮羞布
最近几年鼓吹的新词“微服务”造成一定的误导。有的人误以为“微服务”就是“需求设计一一对应”。
假设考虑到开发团队的结构,把系统分成多个“微服务”,分由各个小团队应用各自的技术栈独立完成。例如图1-1中的男士,可能会被分割为“996微服务”、“交作业微服务”、“扛煤气罐微服务”。
且不说这样划分是否合理,即使这样划分了,“微服务”内部也要通过自己的各个部件(可能是残缺的)协作完成,例如“交作业微服务”要完成“交作业”用例,也需要眼睛、耳朵、手、脚、心脏、**等(可能是残缺的)协作完成,并非映射一个“交作业模块”然后就搞定。更何况,有的用例需要若干个“微服务”协作才能完成。
另外,“微服务”是妥协的不良结构。如果这样的划分风格所得到的软件结构真的是良好的结构,我们几十年前就可以这样做,难道之前的复杂系统没有分解吗?不需要分解吗?如果这真的是好的结构,放在什么时候都是大杀器,根本不用等到现在,拿“微服务”(这也是一个造词)之类的作为理由。即使是一个人完成的项目,也不妨引入一个假设“由各个小团队应用各自的技术栈独立完成”来改善软件的结构嘛。
“微服务”所要解决的问题,在某些系统中确实是存在的,但我在这里要提醒读者,提防把“微服务”(或类似手段)当成遮羞布。
一个人没有能力解决主要问题时,他可能会采取一些措施来掩盖自己能力不足的事实,其中之一就是引入次要问题。
这也是人之常情了。例如,我们在工作中碰到头痛的问题,有时会逃避着不去碰它,而去做一些整理文件,回复邮件等琐碎的事情来获得成就感。
我用盖大楼作类比:
两座大楼耸立在那里,要判断地震来了哪座大楼不容易塌,要考虑的是大楼的结构、所用的材料、所在位置的地质环境等,和这座楼是哪家公司建造的,要了多少钱,建造大楼的公司内部是怎样的组织结构,一共有几支工程队,当时怎么分工的,甚至大楼是猫建造的、狗建造的、外星人建造的,已经没有直接关系——因为大楼已经在那里了。
但要研究这些让大楼不容易塌的直接影响因素,涉及到艰深的工程力学、流体力学、岩土力学等知识。架构师李三没把这些知识学扎实,正在那里犯愁呢。
这时,伪创新专家张四出现了。张四说,时代变了,现在盖楼要讲“新建筑学”,要考虑到人际关系,要搞好团结。
于是,李三想着反正“老的”工程力学那些我也搞不懂,还是搞“人”轻松一些。这样吧,有几个包工队跟自己混,就分几个包,大家开干就是。
转换思想后,李三每天累并快乐着,灯红酒绿,推杯换盏。
而且,运气好的时候,盖出来大楼确实也能住人。
如果李三说,公司又不是我的,想那么多干什么,这可以理解;
如果李三说,这么干盖楼快,反正老板要的就是在某某大日子到来之前有个样子货交差,这也可以理解;
如果李三说,这么干有利于建筑团队的安定团结(虽然坑顾客),这也可以理解;
就怕张四以李三为案例,搞出一个“新工程力学”,说这样盖出来的大楼更抗震,甚至到清华大学建筑学院开课“划时代革命性的工程力学”,取代原有的“工程力学”——这就是无耻了!
1.1.3 总结
我简要归纳需求和设计的区别如图1-4,在后面的章节中再慢慢进一步阐述这些区别。
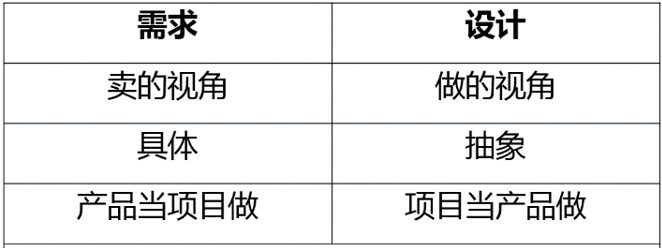
图1-4 需求和设计的区别
★高焕堂在他的书《USE CASE入门与实例》[高 2008]中说过:用例是收益面,对象是成本面。本书基于他的思想做了扩展。
1.1.4 自测题
本书不提供习题答案,访问http://www.umlchina.com/book/quiz1_1.html自测,做到全对自然就知道答案了。
1[单选]
软件开发中需求工作的目的是____。
A) 让系统更加好卖
B) 更好地指导设计
C) 对系统做概要的描述
D) 满足软件工程需求规范
2[单选]
软件开发中设计工作的目的是____。
A) 对系统做详细的描述
B) 更好地指导编码
C) 降低开发维护成本
D) 满足软件工程设计规范
3[单选]
开发人员说“根据客户的需求,我们的系统分为销售子系统、库存子系统、财务子系统……”,这句话反映了开发人员可能有什么样的认识错误?
A) 开发人员没有认识到面向对象设计的重要性
B) 开发人员直接从设计映射需求
C) 开发人员直接从需求映射设计
D) 开发人员没有用UML模型来描述子系统
4[单选]
打开开发人员写的需求规约,发现用例的名字都是“学生管理”、“题库管理”、“课程管理”……,这背后可能隐藏的最大问题是什么?
A) 用例的名字不是动宾结构,应改为“管理学生”……
B) 用例粒度太粗,每一个应该拆解成四个用例,“新增学生”、“修改学生”……
C) 开发人员直接从需求映射设计
D) 开发人员直接从设计映射需求
5[单选]
以下这些经常在开发团队里使用的词汇,都是不严谨的。其中_______混淆了需求和设计的区别。
A) 功能模块
B) 详细设计
C) 用户需求
D) 业务架构
6[单选]
关于需求和设计,以下说法正确的是____。
A) 需求关注概要、设计关注详细
B) 需求的目的是更好地指导设计
C) 设计的目的是把系统分解成可以编码的模块
D) 需求和设计不是一一对应的
7[多选]
有的开发人员没有能力剖析复杂领域逻辑,于是引入性能、开发时间、开发团队组成等遮羞布来转移问题的焦点。以下的哪些做法和这样的做法类似?
A) 医生在给癌症患者看病时,偷偷借助人工智能来帮忙。
B) 医生在看病时,对癌症患者说“你经济条件不好,目前只能吃得起这个药,所以这个药最合适”。
C) 医生在看病时,对癌症患者说“我们医院目前只有这个药,所以这个药最合适”。
D) 医生看到癌症患者经济条件不好,于是80000元一盒的药只收800元。
1.2 建模工作流
1.2.1 建模工作流ABCD
要做好需求和设计,从而低成本制造出好卖的系统,并非喊喊口号就可以,需要静下心来学习和实践一些必要的建模技能。
软件开发是增量、迭代进行的,每一个迭代周期都需要依次思考这么几个事情:
A-业务建模(business modeling)——定位需要改进的目标组织以及该组织接下来最需要改进的问题。
B-需求(requirements)——描述为了改进组织的问题,待引入的信息系统必须具有的整体表现。
C-分析(analysis)——提炼为了满足功能需求,待引入的信息系统需要封装的核心域机制。
D-设计(design)——考虑质量需求和设计约束,将核心域机制映射到选定非核心域上实现。
本书将以上ABCD称为软件开发的4个建模工作流。
如果采用本书的方法学以及UML表示法,其ABCD大致如图1-5。读者先看一眼即可,后文再详细解说图中内容。
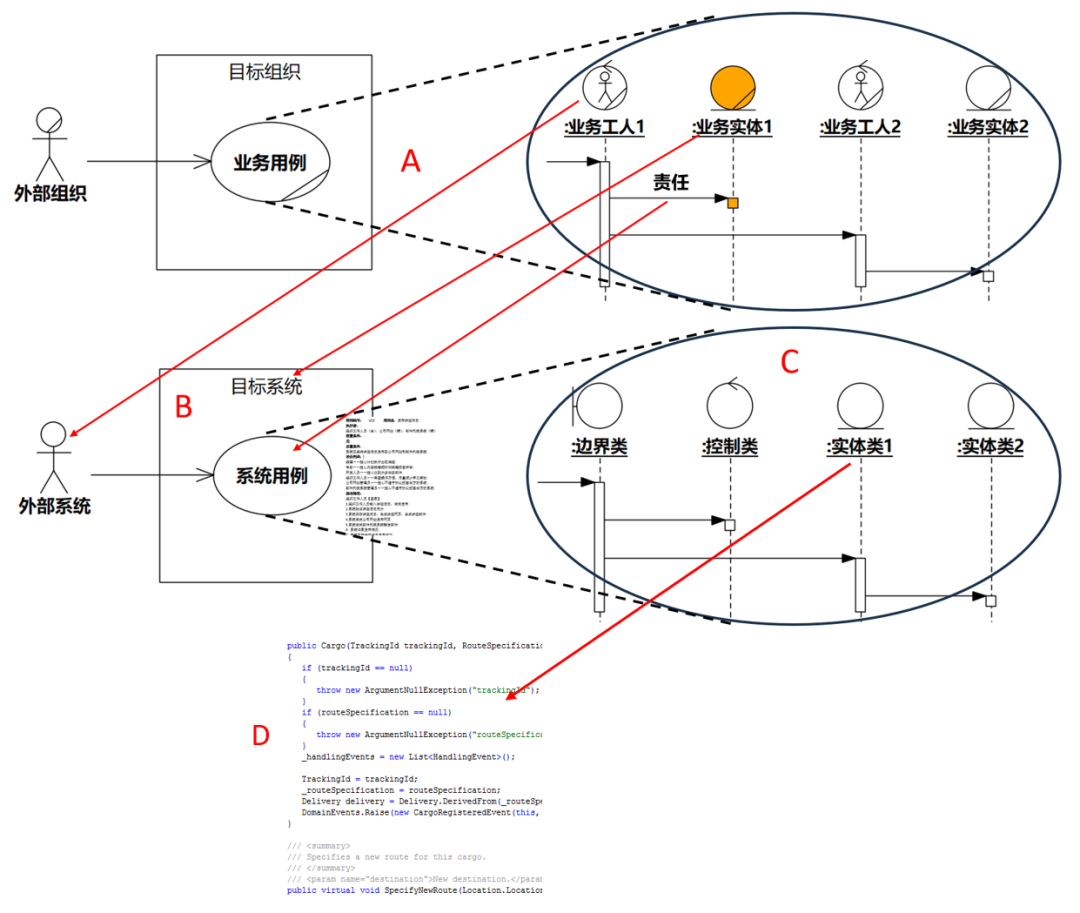
图1-5 四个建模工作流(本书方法学+UML)
软件江湖中各种花里胡哨的用语,不管是真创新还是伪创新,基本上都可以用上面的ABCD来归纳,例如:
产品经理、需求工程师、需求分析师:A+B+部分C。
业务架构师:可能是A(此时“业务”的含义是“组织”),也可能是C(此时“业务”的含义是“核心域”)。
系统架构师:C+D。常有团队说要改进系统架构,其实他想改进的是B-需求。
领域驱动设计:C+D。也有团队声称要学习“领域驱动设计”,其实想解决的却是A-业务建模的问题。
中台:C+D
微服务:C+D
设计模式:C+D
……
欢迎读者随时补充更新。
1.2.2 关于用词
“工作流(workflow)”沿用自RUP(Rational Unified Process)的早期版本,后来的RUP版本改为“科目(discipline)”。
在我看来,“工作流”和“科目”这两个词都不算太好,但目前没有更合适的选择,暂时先用“工作流”。
4个工作流的名称“业务建模”、“需求”、“分析”、“设计”沿用了以往各个方法学的用语,这些用语也不严谨。
例如,“业务建模”末尾有一个“建模”,其他3个却没有,难道其他3个不是建模?如果把其他3个也加上尾巴“建模”,就变成批量刷废话了;如果把“业务建模”的“建模”去掉剩下“业务”,意思已经不对。
甚至“业务”二字都是模糊用语,这个后文再详述。
更贴切的名称可能是:
A-组织改进
B-系统责任
C-核心域逻辑
D-实现
但再三权衡,还是沿用之前的用语。
如果读者真正理解了ABCD的内容,叫什么问题都不大,改成A-阿猫、B-阿狗、C-阿鸡、D-阿鸭也无所谓。
阅读到此处,读者可能会发现,本书中的“需求”和“设计”两个术语有两种用途。
一种用于表达建模得到的结果,例如“需求和设计不是一一对应的”;另一种用于表达建模的工作流,即“B-需求”工作流和“D-设计”工作流,例如“我正在做需求”。
希望下面的话能帮助理解:
为了得到需求,需要做的建模工作流有“A-业务建模”和“B-需求”,为了得到设计,需要做的建模工作流有“C-分析”和 “D-设计”。
另外也说一下本书关于人员的一些用词,其中大多用词含义模糊。本书在某些场合沿用了这些词汇,但在此说明其含义。
(1)开发人员
这个用语的含义目前已经模糊。有的人使用时含义很窄,意思等同于“编码人员”,有的人使用时含义很宽,泛指软件开发团队中的所有人(当然,什么叫“软件开发团队”也是模糊的)。
本书作者在使用“开发人员”一词时,含义是:
软件开发团队中从事ABCD工作流中任何一项工作的人员。根据后文的讲述,所谓“测试”工作也是ABCD工作流,所以,测试人员也属于开发人员。
团队中从事管理工作的角色,不属于开发人员。
(2)建模人员
“开发”本质上就是建模,“建模人员”一词所涵盖的人员和“开发人员”相同.
本书作者在描述某人使用UML或类似表示法的场景时,可能会使用“建模人员”一词来称呼该人员。
(3)程序员
本书作者使用“程序员”时,含义是“实现人员”,即从事D工作流的人员。
(4)产品经理、架构师
另外,本书可能还会出现“产品经理”、“架构师”等用词,但一般会出现在描述某个软件开发团队的某个场景时。产品经理一般指从事AB工作流的人员,架构师一般指从事CD工作流的人员。
本书作者在讲解知识或讨论问题时,会尽量使用严谨的用语,不会主动使用“产品经理”、“架构师”等含义模糊的用语。
1.2.3 逃不掉的思考
在迭代周期中,如果要追求好的结果,按A→B→C→D的顺序来进行推理是必须的,而且各个开发团队一直都在这样做。我们来看几个场景:
开发团队甲,所有成员都认真学习《软件方法》和认真做题,引进了UML和建模工具(例如Enterprise Architect,EA),并按照书中的改进指南改进,最终得到很不错的结果。
开发团队甲的A→B→C→D很容易看出来。
开发团队乙,没听说过《软件方法》,也不用UML和EA,用的是技术总监自己归纳的一套“软件工程方法学”和符号,也还算行之有效。
开发团队乙的A→B→C→D也容易看出来,但形式上和开发团队甲不同。
开发团队丙,快乐拥抱挂着“敏捷”或“领域驱动设计”名头的伪创新。这些伪创新投资少,见效快,门槛低,产量大,仪式感十足。开发团队轻松愉快、热热闹闹地讨论和糊墙。
这里面有A→B→C→D吗?也许有一点,但很少,这些热闹只是装模作样。真正起作用的A→B→C→D推理,可能是在编码的时候在大脑里朦朦胧胧进行的,推理的质量可想而知。
开发团队丁,觉得既然ABC我都不会,我也不想装模作样,就一步到D,直接编码。
这种情况下,还有A→B→C→D吗?有的,和开发团队丙差不多,真正起作用的A→B→C→D推理,是在编码的时候在大脑里朦朦胧胧进行的,同样,推理的质量可想而知。幸好,省去了伪创新装模作样的成本。
★更巧妙的是,有的开发人员以“敏捷”为名故意选择这样做,目的是为了遮掩自己ABC能力的不足。他宁可直接跳到D,然后面对着编码环境慢慢在大脑里朦朦胧胧地补课前面的A→B→C工作流,因为这样做“压力”会小很多。
★此时明面上的任务是编码,A→B→C的推导是顺带做的,属于添头,做到什么程度不好苛责。如果专门设置了一个任务,摆明现在是做A-业务建模,那大家对产出结果的要求就高了,那可就不好遮羞了。
开发团队戊的故事(纯杜撰,勿对号入座)看起来有点不一样。他们所在的公司赶上了风口,成了某个领域(例如预制菜)的互联网巨头。在开发和维护预制菜相关的项目时,开发团队戊的领导下觉得现在的前端框架Vue、React等还差点意思——更有可能是为了自己的简历积极主动地“觉得”Vue、React等还差点意思,于是搞了个内部项目,自研前端框架“闪电五连鞭”。过了几年,也许是风潮过了,也许是历史使命已经完成,预制菜市场冷却,反倒是“闪电五连鞭”框架误打误撞,受到全世界开发人员热捧,成为公司的生存支柱。
这里面有A→B→C→D吗?看起来像是颠倒了?
再看一个特别的,程序员张三自己做一个东西给自己用。张三只会用编码工具,也没学过UML或类似的知识。
张三这里面还有A→B→C→D的推理吗?
最后这两个,答案也是一样的,并没有什么特别,具体留到后文详述。
总之,每一个软件项目,只要不是故意摆烂,开发团队都会有A→B→C→D的推理过程——也许无意识、隐式地做,也许有意识、显式地做;也许推理过程严谨合理,也许推理过程漏洞百出;也许分成很多人来做,也许一个人做;推理产物的形式也许是UML模型,也许是其他……
就像一道复杂的数学填空题,答案是974/2025,如果考生能填对这个正确答案,他必然在考试过程中的某个时间点做了正确的推理——毕竟蒙对这样的填空题答案还是挺难的。只要不是故意摆烂,即使是学渣,也会尝试着去推理。只不过相对于学霸的一击必中,学渣可能要反反复复“敏捷探索”多次才答对,甚至直到考试结束还没答对。
本书希望教给读者一种严谨和高效的推理方法。当然,要掌握它,需要付出辛勤和汗水。
1.2.4 不了解ABCD的危害
1.2.4.1 思维颠倒
如果软件开发人员对以上的“A-业务建模”、“B-需求”、“C-分析”、“D-设计”工作流没有概念,就会出现这样的现象:
问一名开发人员“你在做什么”,他可能回答“我在做设计”、“我在写文档”。
其实,此时他的大脑可能正在思考组织的流程(A-业务建模),或者在思考系统有什么功能性能(B-需求),或者在思考系统要封装的领域概念之间的关系(C-分析),但他通通回答成“在做设计”、“在写文档”。
也就是说,在他的大脑中,软件开发工作被简单地分为“写代码”和“做设计(写文档)”两部分。如果他没有在“写代码”,那么通通是在“做设计(写文档)”。
那么,他是怎么区分自己在“写代码”还是“做设计(写文档)”呢?可能是这样区分的:在Visual Studio、Android Studio、Eclipse……中写出来的叫“代码”,在Word、wiki、Visio、EA……中写或者画出来的叫“文档”。
这时候如果有人忽悠一句口号:代码就是设计,那就更妙了。因为本来我就认为“设计”是“代码以外的各种东西”,现在又说“代码就是设计”,一推导,不就变成了“代码就是(软件开发的)一切”?
即使没有“代码就是设计”这样的忽悠,开发人员也会把“设计”(注意,此处的“设计”不是本书严格定义的D工作流,而是“代码之外的所有东西”)或“文档”看成“代码”的一种比较概要或比较形象的表现形式。不同的“设计”或“文档”代表着“代码”的不同视图,可以让开发人员从不同的视角观察代码,如图1-6所示。

图1-6 误解:文档只是代码的视图
这样的误解不只“普通”的开发人员会有。Martin Fowler所著的UML畅销书《UML精粹》,认为UML有三种用法:草稿、蓝图和编程语言,也是把UML模型看作是代码的视图——这是错误的。虽然Martin Fowler在某些社群的心目中如大神一般存在,但是从Fowler写作的其他书籍《重构》、《企业应用架构模式》、《分析模式》等可以知道,他的研究工作集中在“C-分析”和“D-设计”工作流,较少涉及“A-业务建模”和“B-需求”工作流。他关于“A-业务建模”和“B-需求”工作流的言论,应谨慎看待。
更危险的是,把“文档”当作“代码”的视图还会带来思维颠倒:先拍脑袋编码(快进到D工作流),然后再从代码(D)来反推A、B、C工作流的内容,导致其他工作流变成徒有形式的装模作样。
以下是几段我经历过的思维颠倒的对话:
★对话一
我:这个不应该是系统的用例(如果读者不理解什么叫“用例”,就先把它理解为“功能”好了)。
开发人员:是的!我都写好了,运行一下给你看,这个系统确实提供了这个用例。
系统是否应该有这个用例,应该从“A-业务建模”来推理,通过愿景、业务序列图等步骤的推理后,觉得应该有,系统就有,不该有就没有。不能说,我写好了代码,所以就应该有。
★对话二
我:这两个类的关系不应该是泛化,而是关联。
开发人员:是泛化,不信我打开代码给你看(或:逆向工程转出类图给你看)。
是否泛化关系应该从领域逻辑来判断,领域逻辑不是,那就不是,代码就不应该那样写。不能先写代码“人是猪的一种”(这肯定能通过编译器的检查),再用写好的代码来证明“人是猪的一种”。
★对话三
我:A聚合(组合)B,这个不太对。
开发人员:对的,你看我代码,A是聚合根,其他对象调用时要先找A,存取数据也是以它作为单元。
同对话二,是否聚合(组合)关系应该从领域逻辑来判断,领域逻辑不是,那就不是,代码就不应该那样写。
如果了解了ABCD工作流的概念,以及在不同工作流中所需要思考和表达的内容,我们可能就不会再说“我在写文档”这种话了。“我在写文档”只是表达“我写的东西不是代码” 或者“我正在用文档编辑工具在工作”。
你在写什么“文档”?“A-业务建模”?“B-需求”?“C-分析”?我不写,我画图,难道不可以吗?我不写不画,我用语音清楚地表达组织的流程,难道不可以吗?我用Word编码(即D-设计),难道不可以吗?我用C#写需求(即B-需求),难道不可以吗?
更有意义的说法应该是“我在做业务建模”、“我在做需求”……如果说“文档”二字可以给你带来不可替代的快感,可以说“我在写业务建模文档”。
1.2.4.2 胡乱应对
开发人员常说要“应对变化”,甚至有的人还喊口号“拥抱变化”,但是很多人并不清楚要应对的是什么样的变化,也不知道应该怎样正确地应对变化。
当我们谈到“变化”的时候,真相有可能是下列之一:
真相(1):根本没有变化
系统的需求(功能、性能和约束)没有变化,只是之前由于实现人员的能力问题,导致实现没有满足需求,或者能满足需求但自认为系统的内部结构不合理。这样的修改不能叫“应对变化”,只能叫“纠错”。
可笑的是,有的人也把这个情况也称为“应对变化”。就像考试有一道题难度稍高,学渣“敏捷”地算了一下,没算出来,把原来的擦掉,再来,还是没算出来,于是大喊“变化剧烈!”。
这种情况下,需要关注的工作流是“C-分析”和“D-设计”。
真相(2):系统的功能没变,性能和约束变了
例如,响应时间需要缩短,实现平台需要更换等。
应对这样的变化,需要关注的工作流是“D-设计”,实现的套路要调整。
真相(3):系统功能的合理变化
经过严谨的“A-业务建模”和“B-需求”的推理,认为系统的功能(用例、步骤、输入输出信息、业务规则……)确实需要变化。
应对这样的变化,需要关注的工作流是“C-分析”。
注意,这里说的是经过“A-业务建模”和“B-需求”的严谨推理得出的“合理变化”。系统的功能之所以需要变化,根源在于系统所处的大环境中的某些东西发生了变化,而这样的变化往往是有其规律的。通过“C-分析”工作流,调整系统的核心域模型,使其更好地体现核心域的规律,有助于应对这样的变化。
真相(4):系统功能的不合理变化
这就是平时常说的“假需求”。和(1)一样,这其实不是“变化”,是“错误”。
没有经过严谨的“A-业务建模”和“B-需求”的推理,拍脑袋得到的所谓“系统功能”,不能改进组织流程,也不满足涉众利益。
这种情况下,关注“C-分析”工作流意义并不大,因为这种变化缺少规律。
如果我们发现在“C-分析”工作流下功夫对“应变”的改进并不大,那意味着我们需要关注的工作流应该是“A-业务建模”和“B-需求”。先学会严谨推理出系统的功能,才能知道真相到底是(3)还是(4)。
我们用医生给患者看病类比:
真相(1):
医生的诊断没问题,开的处方也没问题,护士或患者执行医嘱时执行错了。
这不是“变化”,这是“错误”。如果还把这个叫作“拥抱变化”,就是无耻了。
真相(2):
输液时,换了另外一种品牌的一次性输液器。
真相(3):
患者病情确实有变化。张三原来只是乙肝,现在是肝癌。
这种变化是有规律的。张三得了乙肝却不注意保养,依然酗酒和熬夜,很快进展到肝硬化,然后进展到肝癌。
如果充分了解肝脏的工作机制(C-分析),当张三被诊断出乙肝时,就可以合理应对当时的情况,并预测和提前应对后面可能会发生的变化。
真相(4):
医生诊断错了病情。
张三出现恶心、乏力、食欲减退。村里的道士九叔给他诊断,认为他被鬼上身了,需要搞一个驱魔仪式。九叔已经精研驱魔理论体系和实践多年,一手辟邪剑法已经达到传奇王者。
实际上张三是得了乙肝,九叔的传奇王者对此没有帮助。
当然,如果是玩驱魔游戏或Cosplay,又不一样了。
******
也许是不了解其中区别,也许是为了掩盖自己的无能,开发人员经常胡乱应对。
例如,把真相(4)说成真相(3),营造出“需求变化剧烈”的假象,从而掩盖自己缺少“A-业务建模”和“B-需求”能力的事实。
例如,对真相(3)和真相(4)避而不谈,只谈真相(2),或者想通过真相(2)的应对方案“D-设计”来应对真相(3)和真相(4),因为“D-设计”是他唯一熟悉的内容。
一些资料以“领域驱动设计”为名,结果一看内容,所举的例子就1-2个“领域”类,然后就开始讨论Entity、Service、Repository、DTO、六边形架构……哪里有“领域”?分明说的是“企业应用架构模式”、“互联网系统架构模式”。
在各种软件开发技术大会上,也可以看到这样的场景:某电子商务网站的架构师上台讲了一通,接着某视频网站的架构师上台也讲了一通,咦,这两人是同事吗,演讲内容如此相似?原来,他们讲的内容都是“D-设计”的内容。究其原因也许不是不愿意讲,而是讲不出来——该架构师就会这一点点,连自己所开发系统的核心域都研究得很浅。
1.2.4.3 伪创新泛滥
很多开发人员只有D的知识。当岗位发生变化,需要他做A、B、C的工作时,按道理应该去认真学习A、B、C的技能才对。
可惜,很多人并不愿意走出自己的舒适区,甚至还会有意无意地把其他人拉到自己的舒适区。
例如,在和涉众讨论需求时,频频蹦出一些“技术潮词”,目的就是以自己的“所长”来碾压涉众,从而掩盖自己业务建模(A)和需求(B)技能的不足。
例如,在讨论核心域的类模型(C)时,动不动就谈到如何实现(D)或者质疑“会不会有性能问题”(D),从而掩盖自己抽象能力的不足。
于是,各种投其所好的伪创新就登场了。
有的伪创新极力贬低A、B、C的重要性,通过“砸烂一切枷锁”来吸引热血青年。例如,想那么多有啥用,最后不是还得写代码?张嘴就是Linus Torvalds的“Talk is cheap. Show me the code.”。
后来,“发明家”及其追随者慢慢发现砸烂一切是不行的,追随者的信念开始动摇。于是,伪创新不再贬低A、B、C,而是从D来臆想A、B、C,得到的A、B、C“方法学”非常“简单易学”,让只了解D的开发人员感觉“很受用”。
例如,深入第一线调研各类涉众的利益很麻烦。有办法,摆一个“现场客户”在旁边,开发人员就可以心安理得坐在电脑前面编码,有问题就推给“现场客户”。
例如,认真学习领域知识的各种概念和术语很麻烦。有办法,开发人员可以按照自己的理解创造一套“通用语言”。
伪创新往往并不会直接说自己简单易行,而是会说自己很高深。宣传中往往带有“艺术”、“禅”、“道”等字眼,有意无意地朝宗教、艺术、玄学方向引导——比起枯燥的数学理论和逻辑推理,这些东西可是太好下嘴了。还有一个很大的优势,一些媒体人听到“艺术”、“禅”、“道”等字眼就亢奋,自觉地加入到宣传伪创新的队伍中。
开发人员一开始以为很难很深奥,上手一学,发现其实不难!可以说是:投资少,见效快,产量高,门槛低,而且仪式感十足。最妙的是,不用走出舒适区辛苦学习,就得到了“方法学”,这可太符合只了解D的开发人员的胃口了!开发人员立刻有捡到了便宜的感觉,心中豪气顿生——不愧是我!别整三岁的,有能耐你整四岁的!
伪创新还会声明“领域驱动设计不是银弹”之类,也是为了进一步塑造形象。我都诚实地说了我不是满分,所以我前面塑造的90分的形象应该是真的。
关于各个工作流的各种伪创新,本书后面各章节还会进一步讨论。
1.2.5 没有测试工作流?
“测试”可以看作建模的验证过程,所以不能光说“做测试”,要清楚认识“测试”所验证的内容。
如果“测试”验证的是组织流程中各个系统之间的协作,那就是“A-业务建模”。
如果“测试”验证的是目标系统的整体表现,那就是“B-需求”。
如果“测试”验证的是目标系统内部各个部件之间的协作,那就是“C-分析”和“D-设计”。
无论是启发、定义还是验证,如果你思考的内容是某一个工作流的内容,你就是在做该工作流。在一个迭代周期中,启发、定义和验证往往是交错进行的。
1.2.6 没有项目管理工作流?
本书关注的范围限于方法学,即A→B→C→D的正确推导方法,至于推导是一个人做的,很多人做的,甚至是猫做的、狗做的、外星人做的,没有直接关系。
还是用前面的大楼类比。两幢大楼耸立在那里,地震来了,一幢塌了,另一幢没塌。
直接因素是大楼的结构、所用的材料、所在位置的地质环境等,这些涉及到艰深的工程力学、流体力学、岩土力学等知识——类似于本书所研究和阐述的方法。即使大楼是外星人盖的,也要讲这个基本法。
直接原因往往比较难理解,此处要提防,有的人为了掩盖自己的无能,干脆找比较容易理解的其他原因来把水搅浑。例如,一出事故就嚷嚷“有人吃回扣了”,就算经过调查没人吃回扣,他也会从工作服的颜色,工人是否结对洗澡,施工队开会时是否站立等更容易理解的方面来找原因。
当然,要成功完成一个软件开发项目,还有很多其他工作,例如进度管理、人力资源管理等,但这些都不属于本书讨论的范围。关于软件项目管理方面的内容,读者可自行阅读专门的书籍。
1.2.7 人工智能对ABCD各工作流的影响
从广义上来说,所有封装了逻辑的信息系统都可以叫“人工智能(AI)”。例如,计算器封装了运算的逻辑,你只要告诉它输入:2355465722232×5465768797343,它就会给你输出,而且比绝大多数人要快。所以,我们使用AI,AI在某些方面比人强,已经有几十年的时间了。
★算盘不是AI,知识点见第4章。
当然,我们这里谈到的AI是狭义的,指生成式人工智能(Generative AI)。自从GPT-1在2018年推出,生成式人工智能热潮兴起至今。
目前,Copilot、Cursor、Augment Code等AI编码环境(或插件)已经逐渐普及,AI在D工作流形成非常大的助力。D工作流变得更更简单,使得竞争焦点进一步向ABC(业务建模、需求、分析)工作流转移。
而在ABC工作流,AI目前带来的帮助并没有那么大——人类还没理清楚更大粒度的ABC工作流怎么做,刚取得一些进展,又有被伪创新拉着倒退的趋势。
现在又有一个不好的情况,伪创新圈子的“造词”、“念经”、“批量刷废话”已经在污染AI。在ABC工作流,我们暂时无法把AI当成“专家”,只能把AI当成一个非常非常聪明的学生,用严谨的方法学来给它解毒并引领它。
本书的后续章节在探讨软件开发工作流的每一个步骤时,都会引入AI辅助的内容。我们会把方法学的知识细致分解并训练AI,让它给我们带来真正的价值。
1.2.8 自测题
本书不提供习题答案,访问http://www.umlchina.com/book/quiz1_2.html自测,做到全对自然就知道答案了。
1[单选]
以下描述最可能对应于软件开发中的哪个工作流?
每个项目由若干活动组成,每项活动又由许多任务组成。一项任务消耗若干资源,并产生若干工件。工件有代码、模型、文档等。
A) 业务建模
B) 需求
C) 分析
D) 项目管理
2[单选]
以下描述最可能对应于软件开发中的哪个工作流?
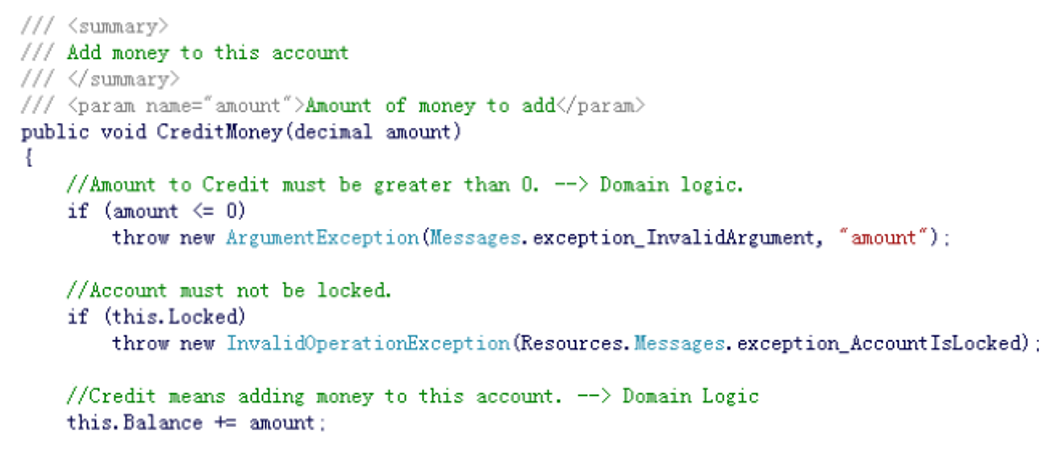
A) 需求分析
B) 代码设计
C) 详细设计
D) 设计
3[单选]
以下描述最可能对应于软件开发中的哪个工作流?
系统向会员反馈已购买商品的信息。
A) 功能规约
B) 需求分析
C) 需求
D) 需求规约
4[单选]
以下描述最可能对应于软件开发中的哪个工作流?
在去给外婆拜年的路上,李雪琴突然想起需要一些现金给外婆做现金红包。她先用高德地图查询了附近的ATM机网点,并挑中了一处工行的网点,开车过去一看,好家伙,路边这么多人排队取现金!李雪琴只好又看高德地图,挑了一家她觉得人应该会比较少的,开车过去,终于在ATM机取到了现金,然后,她又想了想哪里有卖红包的地方……
A) 业务建模
B) 用户故事
C) 需求
D) 流程分析
5[单选]
以下不属于建模工作流ABCD的是______。
A) 需求
B) 分析
C) 设计
D) 测试
6[单选]
本书中,建模工作流的名称沿用了之前方法学中的名称,这些名称其实都不太合适,例如,______工作流的名称改为“系统责任”更合适。
A) 业务建模
B) 需求
C) 业务需求
D) 分析
7[单选]
有方法学家发明了比“糊墙”还有仪式感的“美女建模法”。
例如,某医卫领域软件公司招聘一批颜值较高的美女,分别扮演患者、护士、医生、收费员、HIS系统、支付宝、微信等。和客户沟通时,就让这些美女一起上场表演各种场景给客户看。
客户一致反映:这样的方式生动、活泼、新颖、看得见、闻得着、有嚼头、有回昧、一举多得(附加题:这一串的出处是?),下次沟通还这样搞!
请问。美女们向客户表演的最有可能是哪个工作流的内容?
A) 业务建模
B) 总体设计
C) 需求
D) 分析
8[单选]
软件开发工作流:A-业务建模、B-需求、C-分析、D-设计。目前(2025年5月),AI(人工智能)帮助最大的是哪一个?
A) A-业务建模
B) B-需求
C) C-分析
D) D-设计
1.3 统一建模语言UML
1.3.1 UML的历史和现状
UML(Unified Modeling Language,统一建模语言)是由OMG(对象管理组织)维护的一个软件建模表示法标准。
在1.2中,我们阐述了A→B→C→D的推导是不可避免的,但具体如何推导,有各种不同的做法,这些做法可以称为“方法”。甚至只要愿意,每个人都可以创造自己的“方法”,无非是有的正确,有的错误,有的高效,有的低效。有一些“方法”被成体系地归纳出来,并向业界推广,这些可以称为“方法学”。
最开始的软件开发方法学重点关注的是D部分,即所谓的“程序设计方法学”。后来,才逐渐在方法学中加入前面的部分,大致的添加顺序和推导的顺序刚好相反,→C→B→A。其中的很多概念借用了其他学科的术语。像“流程建模”、“需求”等术语在计算机出现之前就已经存在,而且含义和今天软件开发中使用时的含义差不多。
本书不想花很多篇幅来回顾这些方法学中的概念的历史,感兴趣的读者可自行搜索相关论文,例如Kolligs 等人写的“The Origins of Requirements”[Kolligs 2021]。
20世纪60-80年代,有名的软件方法方法学有:功能分解、数据流、E-R(实体-关系)等。
进入20世纪90年代,OOAD(面向对象分析设计)方法学开始受到青睐,许多方法学家纷纷提出了自己的OOAD方法学。流行度比较高的方法学有Booch、Shlaer/Mellor、Wirfs-Brock责任驱动设计、Coad/Yourdon、Rumbaugh OMT和Jacobson OOSE。其中,Jacobson的方法学添加了用例、业务工人、业务实体等概念,为OOAD方法学扩展了业务建模和需求部分。
这个百花齐放的局面带来了一个问题:各个方法学有自己的一套概念、定义和标记符号。
例如现在UML中的操作(Operation),在不同方法学各有叫法,这些叫法有:责任(Responsibility)、服务(Service)、方法(Method)、成员函数(Member Function)……
同一个类图,不同方法学也有各自的符号表示,如图1-7所示。在图中,我们可以看到,三角形符号在OMT方法学中表示泛化,在Coad/Yourdon方法学中却表示关联,Coad/Yourdon方法学中泛化用的是类似铃铛的形状。
类似这样的差异造成了混乱,使开发人员无从选择,也妨碍了方法学的推广。
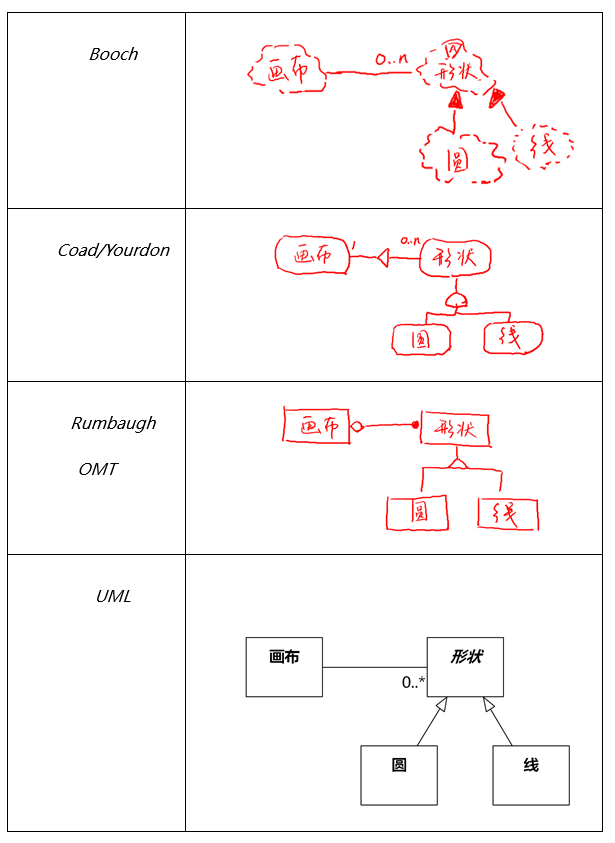
1-7 不同方法学图形比较
1994年,两位已经在Rational公司工作的方法学家James Rumbaugh和Grady Booch开始合并OMT和Booch方法。随后,Ivar Jacobson带着他的OOSE方法学加入了Rational公司,一同参与合并工作。这项工作造成了很大的冲击,因为在此之前,各种方法学的拥护者觉得没有必要放弃自己已经采用的表示法来接受统一的表示法。
Rational公司的这三位方法学家被大家称为“三友”(three amigo)。1996年,三友开始与James Odell、Peter Coad、David Harel等来自其他公司的方法学家合作,吸纳他们的成果精华。1997年9月,所有建议被合并成一套建议书提交给OMG。1997年11月,OMG全体成员一致通过UML,并接纳为标准。
从2005年起,UML被ISO接纳为标准。ISO/IEC 19501相当于UML 1.4.2,ISO/IEC 19505相当于UML 2.1.2。2012年,ISO继续接纳UML 2.4.1为ISO/IEC 19505-1:2012 和ISO/IEC 19505-2:2012,接纳OCL 2.3.1为ISO/IEC 19507:2012。
2011年,中华人民共和国也发布了统一建模语言国家标准GB/T28174。
UML的最新版本是OMG于2017年12月通过的UML 2.5.1,相关网址:https://www.omg.org/spec/UML/。
OMG还和各种行业标准组织如DMTF、HL7等结盟,用UML表达行业标准。
UML诞生已经超过25年,在软件开发表示法标准上已经获得了胜利。随便打开一本现在出版的软件开发书,里面如果提到建模,使用的标准符号基本都是UML。
另外,以UML为契机,掀起了一股普及软件工程的热潮,在UML出现后的几年,不但有关建模的新书数量暴增,包括CMM/CMMI、敏捷过程等软件过程改进书籍数量也出现了大幅度增长。制定UML标准的角色(OMG)、根据标准制作建模工具的角色(UML工具厂商)、使用UML工具开发软件的角色(开发人员)这三种角色的剥离,也导致建模工具的数量和种类出现了爆炸性的增长。而之前的数据流等方法从来没有像面向对象分析设计方法一样,出现UML这样的统一表示法,从而带动大量书籍和工具的产生。
最开始一批UML书籍,基本上由方法学家所写。最近几年,以“UML”为题的新书大多为高校教材或普及性教材。这并不是说UML已经不重要,而是没有必要再去强调,焦点不再是“要不要UML”,而是要不要建模、如何建模。
1.3.2 使用UML(或某个标准建模语言)的理由
在开发团队中,不乏刻意排斥UML的人。这些人如果只是不使用UML,改为使用其他标准的图形表示法(如BPMN),那倒没有什么好说的——但仔细观察可以发现,绝大多数情况下并非如此,这些人要么使用自编的“图形表示法”,要么使用文本,甚至有的人只强调“口头交流”。
当然,通过UML、自编图形、文本、语音等形式都可以交流软件开发中的各种逻辑,但能达到的目的和付出的代价是不一样的。
1.3.2.1 听觉 vs. 视觉
回忆一下我们在学生时代做听力题和阅读理解题的过程,就可以体会到,相对于听觉,视觉传递信息的效率更高,而且可以传递更复杂的信息。正常情况下,把模型表达成视觉信息,不管是文本还是图形,比起语音信息来说是更好的选择。非正常情况,视觉无法使用的时候,例如开车或者累得眼睛睁不开,这时用语音来见缝插针,通过听觉利(zhà)用(gān)建模人员的生产力,也不是不可以。
如果有人以“敏捷”为理由,特别推崇“口头交流”,排斥文档或图形,很可能是遮羞布,背后的脓包是此人没有能力剖析复杂逻辑,试图通过这种方式来遮掩。
有的开发团队动不动就开会,你一嘴我一嘴,场面看起来热热闹闹,其实沟通的效果不好,更谈不上思考的深度和知识的沉淀。对比一下街坊老大爷下象棋的热闹和职业棋手比赛时的沉静就知道了。
1.3.2.2 文本 vs. 图形
相对于只有自上而下顺序的文本(包括自然语言文本和编程语言文本),能够朝四个方向扩展的平面图形(如果有三维模型就更好了)更容易让建模人员看出概念之间的联系。例如,图1-8和图1-9的内容,如果没有图形的帮助,通过文本一行一行地构造和阅读模型,人脑的负担非常重。
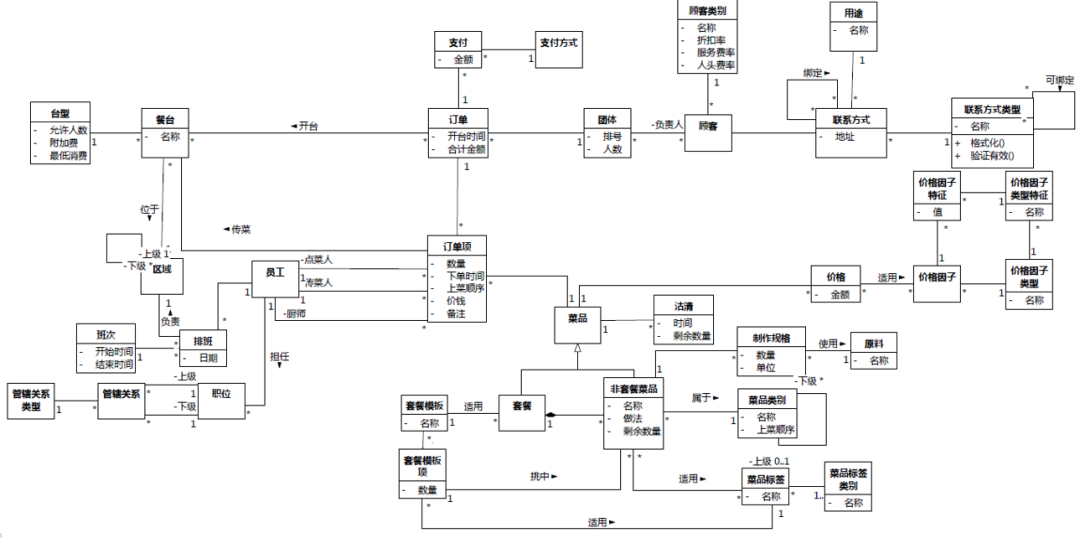
图1-8 餐饮领域的类图
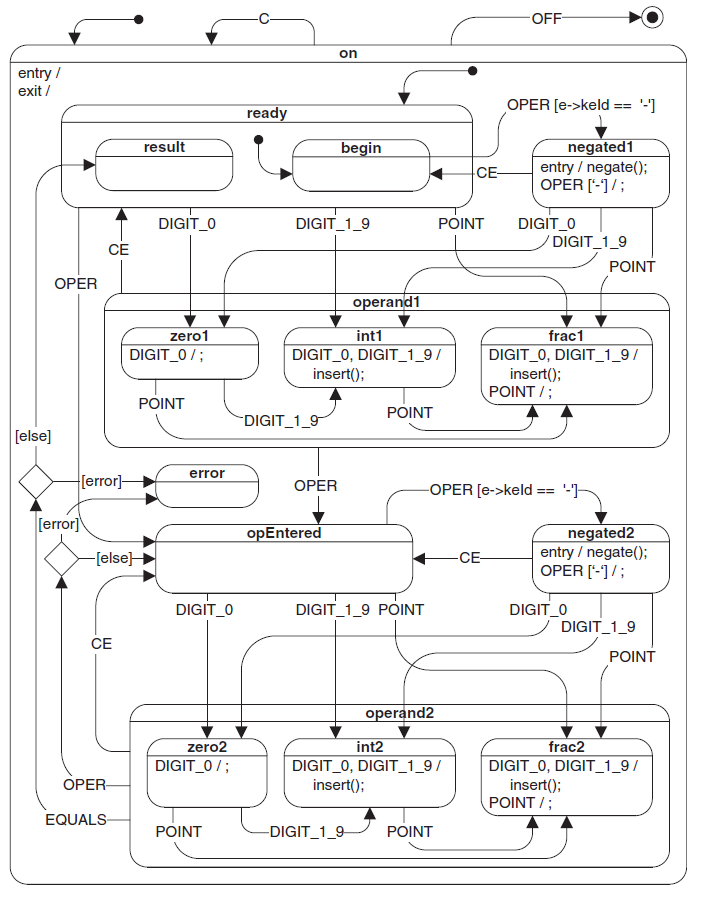
图1-9 计算器的状态机图,摘自Practical UML Statecharts in C/C++[Samek 2008]
说到这里,又不可避免地要提醒,故意选择文本的形式来表达领域知识,有可能也是一种遮羞布。图1-8和1-10的内容如果用文本表达,可能会得到很多页文本——这就有了理由:因为工作量太大了,所以很多地方无法做深入的思考,可以原谅!
1.3.2.3 自编图形 vs. 标准图形
事实上,纯口头交流甚至纯文本交流是很少见的。除非要交流的问题极其简单或者其他同事对这样的人极其容忍,否则他至少也得随意画几张“草图”来传达自己的意思——自编的图形才是比例最大的存在。
这样的人之所以用自编的图形,往往并不是因为他看出了UML有哪些不足,然后用自己的表示法弥补了这些不足,而是要遮掩背后的一些脓包。
脓包一:利益绑架
项目中,有人画了张自编的图形,然后往往会伴随这样的招呼,“来,我给大家讲讲!”。这意味着项目要依赖于“我”头脑中的隐式知识——要是“我”不给大家“讲讲”,大家就不理解“我”画的图的意思,项目就玩不转了。于是,“我”在团队里的地位就提高了,大家得哄着“我”捧着“我”,领导不敢轻易开掉“我”,“我”提出离职领导还要挽留。这在有一定资历、但又不对项目的成败承担首要责任的“高手”身上表现得更明显。
★开发人员让我看他的模型时,如果开口说“我先来给你讲讲”,我都会拦住,“如果还需要你先讲讲,说明你所想的没有体现在模型中”。
脓包二:遮羞
因为符号是“我”自创的,所以这个图的解释权归“我”所有。如果有其他同事质疑图上什么地方画得不对,“我”就有了充分的躲闪空间——“你理解错了,这个图形不是你以为的那个意思。你以为我画的是鹿,其实这是马,在我的规范里面,马就是鹿的意思,鹿就是马的意思”。
如果使用了标准的表示法,例如用UML画了一个状态机图,其他人就有得说了,“好像手册上不是这样说的”,“我看那个书上不是这样说的”,这不就尴尬了嘛。
自编图形未必是看起来十分简陋的白板草图,也有看起来比较精致的。例如,来自某项目的图1-10。
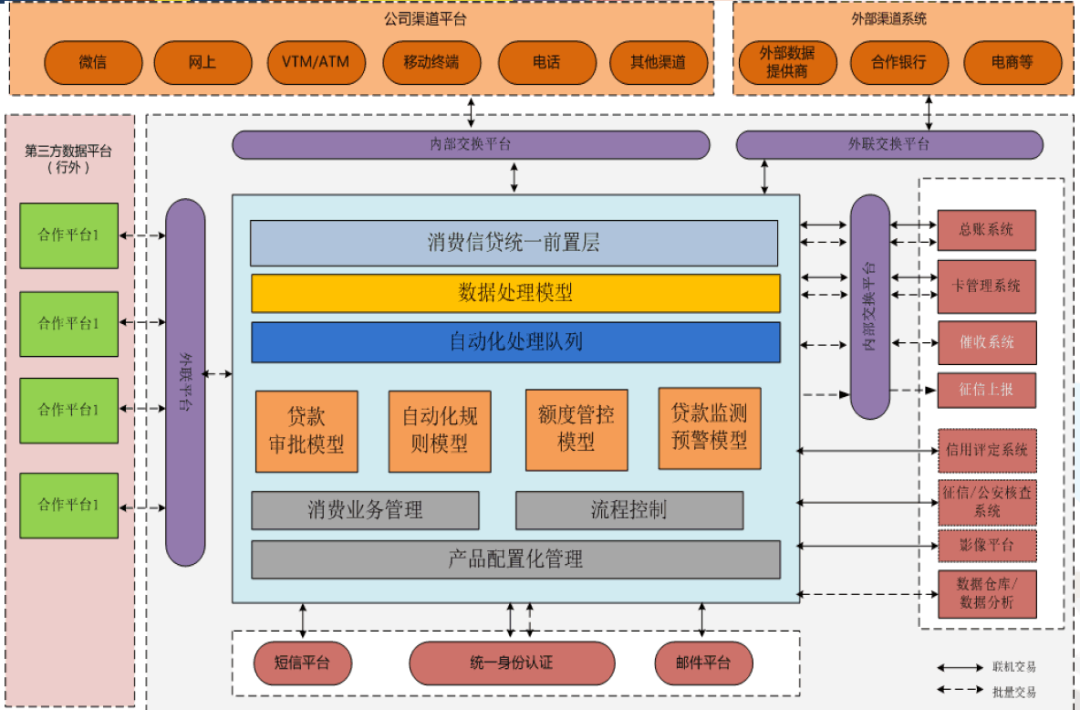
图1-10 自编图形示例
其实,抛弃标准符号和建模工具带来的便利,用绘图工具或幻灯片工具画出这样的图,所花费的时间往往还要更多。但是,有意思的是,有的人画这样的图,还以“敏捷”为理由。
注意,上面说的只是“看起来比较精致”,其实内容还是很粗陋的,仅仅是把一些动词、名词的罗列成一个个形状,各个形状之间的关系基本没有,读者可以把图1-10和图1-8、图1-9对比。
有心的读者可以观察近年来被吹捧为“革命性创造”的领域驱动设计的文章,看看其中所画的图,看看会不会发现上面所批评的情况,简单罗列,无一致性。然而,为了掩盖逻辑上的不足,这些图的作者会把力气下在“美工”方面,因此,伪创新的图有时看起来比科研风格的图更赏心悦目,对外行来说更有吸引力。
1.3.2.4 挑破乱七八糟图的脓包
我们甚至可以“抛开事实(具体领域知识)不谈”,仅从“一致性”这一点入手,就可以挑破这种自编“乱七八糟图”的脓包。
自编“乱七八糟图”的画图者,很可能并没有归纳过各种形状的定义,只是凭感觉随意使用,或者即使归纳了,也不会像标准语言这么严谨,所以,大概率会产生“不一致”的问题。
我们就以图1-10为例。
图1-10中,同样被称为“平台”的东西,有着不同的形状和颜色,如图1-11。
图1-11 图1-10的不一致示例1
我们再来看中间这些方框,如图1-12。
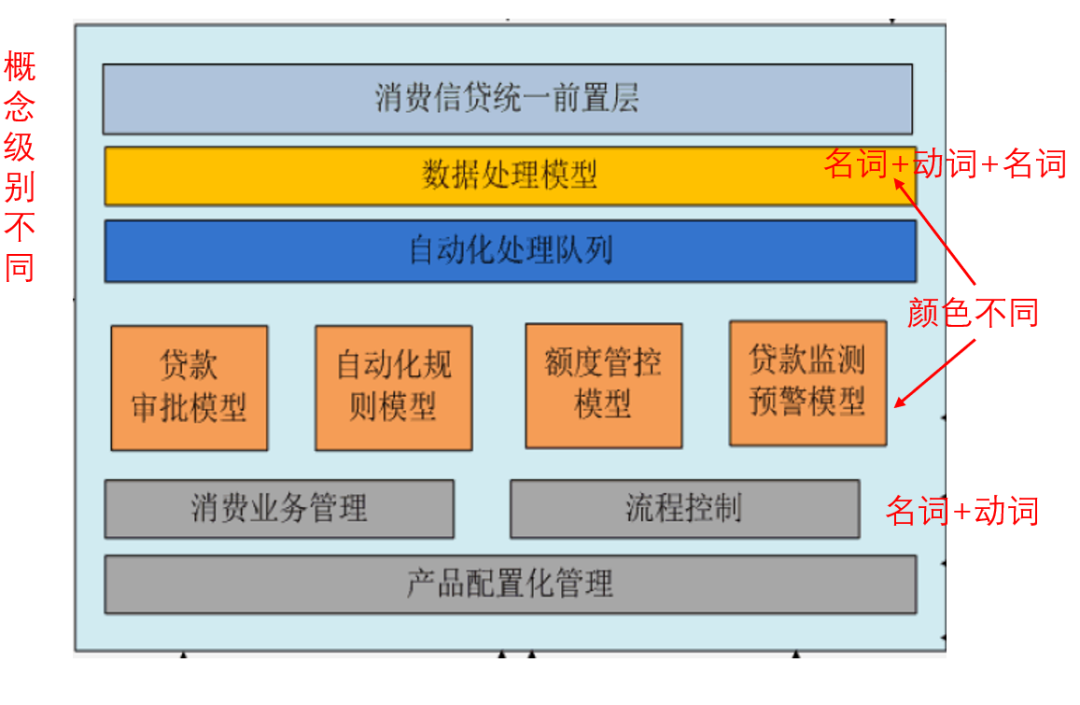
图1-12 图1-10的不一致示例2
先看图1-12的最顶上3个方框,它们形状一样,长度一样,但有的叫“层”,有的叫“模型”,有的叫“队列”,这些概念可不是一个级别的。
(可能的辩解)也许在颜色中暗示?
再来看方框里的命名。最上面4行的命名,基本上都是“名词+动词+名词”结构,例如“消费信贷+统一前置+层”、“额度+管控+模型”,最下面2行的方框,命名是“名词+动词”结构,例如“消费业务+管理”、“流程+控制”。
(可能的辩解)你没脑子吗,自己脑补一个尾巴不行吗,“……模型”、“……层”、“……功能”、“……队列”、“……AI赋能领域驱动设计革命性创新微服务功能模块组件分布式大数据数智化平台”。
还有,名称同样是“模型”,颜色也有多种……
读者可以尝试从“一致性”着手,看看身边的同事画的“乱七八糟图”有没有这方面的问题。
可能有人会问:难道用UML来画就没有这个问题吗?
有的,例如,建模人员故意往用例的圈圈里乱填东西,有的填名词,有的填动词,有的填形容词,但这是违反UML相关的规范或指南的,其他人可以看出问题,批评和纠正。刚才说的情况是没有规范或规范模糊,这两者是不一样的。
用法律类比:精确严谨的法律条文并不能保证没有人违法,但至少大家有共识,什么是违法,什么不是。而另一种情况则可能是,孪生兄弟张三和张四做了同样的事情,张三违法,张四不违法,理由?不知道。
1.3.2.5 基本共识上的沟通
表示法标准并不是随便哪个人拍脑袋定下来,然后毫无道理地强迫大家接受。符号背后往往隐含着我们对某个学科的一些基本共识。
如图1-13,最上一行的积分表示法“∫”,幼儿园小朋友也能画出这样的形状,但其所代表的知识可能需要上到大学才能理解。如果要懂得为什么是这样一个表示法,还需要了解数学史中莱布尼茨、傅立叶等人的贡献。图1-13中间一行的五线谱小豆芽和横线,最下一行UML的小人圈圈和框框,也是如此。
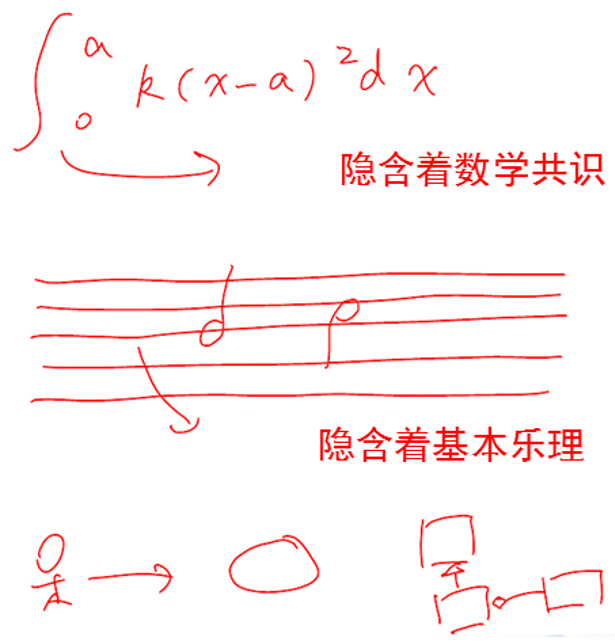
图1-13 表示法背后隐含基本共识
这意味着,学习建模表示法标准并非硬生生把形状记住后照葫芦画瓢就行,还要学习背后的一些建模知识。但是,开发团队成员咬咬牙,花费一些精力跨过这个门槛是值得的,因为一旦有了基本共识,会大大提高沟通的效率和深度。在严谨建模思维的追问之下,有意无意遮掩的脓包也会被强制露出——这也是一些“高手”潜意识里不愿意直面UML的深层原因。
★面对一个棋局,下一步怎么走?在业余棋手看来到处都是正确答案,在职业棋手眼里,值得讨论的选项只有两三种,因为职业棋手针对一些东西形成了共识,大大减少了思考中的浪费。
★有的开发人员的“十年工作经验”实际上是“一年工作经验用了十年”,一直在热热闹闹的民工层次徘徊,没有积累和成长。
不过要注意一点:使用UML沟通仅限于软件组织内部,UML模型不是用来和涉众沟通的!这个道理以及和涉众沟通的技能将在第7章详细叙述。
1.3.3 SysML
UML的另一个成就,就是把“统一建模语言”扩展到了系统工程。INCOSE(国际系统工程协会)和OMG(对象管理组织)以UML为基础,进行系统工程方面的扩展后推出了SysML(Systems Modeling Language,系统建模语言),目的是和UML相似:为了统一系统工程的建模语言。
UML是信息系统的建模语言。“信息系统”的意思是该系统只负责处理信息:信息流进来,经过系统的处理,变成信息流出去,但是,信息系统不能处理物质流和能量流——或者简单说就是能量流,因为物质是能量表现形式之一。
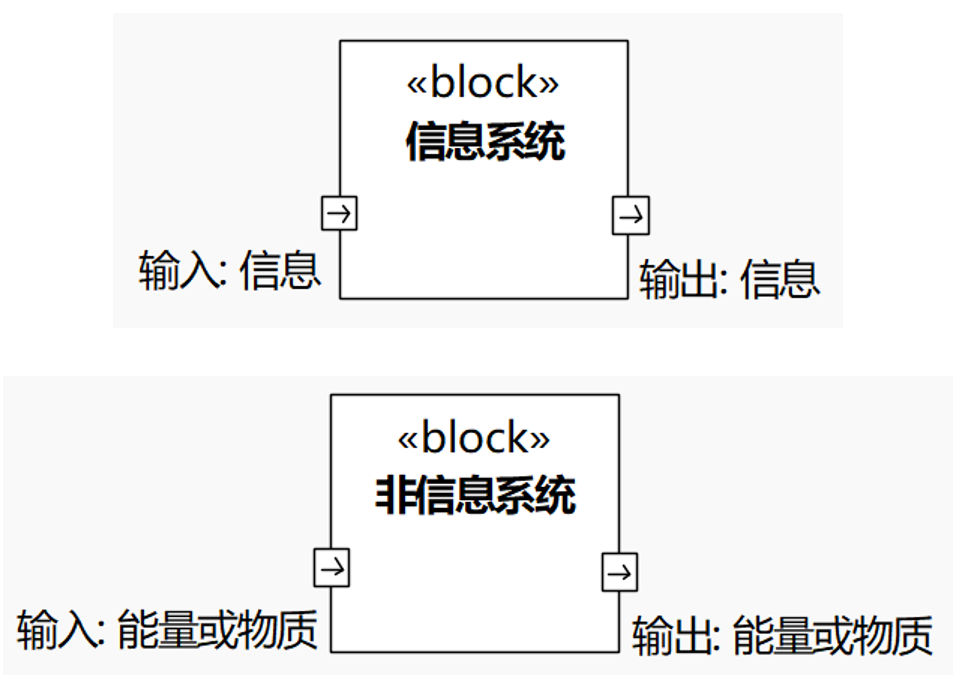
图1-14 信息系统和非信息系统(此图用SysML表达)
SysML可以建模处理能量(物质)流的非信息系统。将来能量(物质)、信息进一步大一统,SysML是可以取代UML的,但目前还不能。
关于系统工程、软件工程、SysML、UML的区别,我用刘慈欣的小说《流浪地球》举个例子。
太阳即将在400年内发生氦闪变成红巨星,人类社会怎么办?
众多科学家经过大量研究,得到一个解决方案:给地球装上发动机,驱动地球飞向比邻星(夭寿啦!正好三体舰队迎面飞来,嘭!)。
******
小说《流浪地球》原文:
地球发动机安装在亚洲和美洲大陆上,因为只有这两个大陆完整坚实的版块结构才能承受发动机对地球巨大的推力。地球发动机共有一万二千台,分布在亚洲和美洲大陆的各个平原上。
……
在六千米处,我们见到了进料口,一车车的大石块倒进那闪着幽幽红光的大洞中,一点声音都没传出来。
……
“重元素聚变是一门很深的学问,现在给你们还讲不明白。你们只需要知道,地球发动机是人类建造的力量最大的机器,比如我们所在在华北794号,全功率运行时能向大地产生一百五十亿吨的推力。”
******
“地球发动机”是一个巨大的系统,横跨多个学科,能源、材料、建筑、物流、人员管理……。
其中用来描述和处理信息的信息系统可能只占其中的一小部分,UML不适合描述“地球发动机”,SysML可以。
通过SysML建模,不断把“地球发动机”分解成各个Block,Block又分为小Block,可能会得到其中一个Block叫“发动机中控系统”,这是一个信息系统。该系统其中一个功能可能是:根据接收到的测量参数值(可能有上万个),计算地球发动机下一步的最佳行动。我用SysML的块定义图画了图1-15,只是简单展示,我也不知道地球发动机应该分成哪些Block。
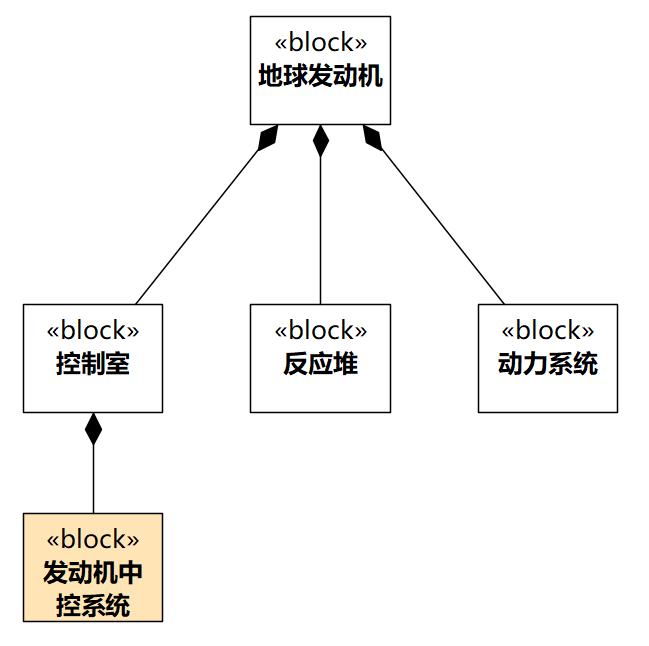
图1-15 地球发动机的分解(此图用SysML表达)
图1-15中的“发动机中控系统”这个信息系统,就适合用UML来建模。
听起来SysML描述的系统比UML描述的信息系统大,是不是意味着SysML建模的难度更高?
目前来说并非如此。目前使用SysML建模时,更多的是“描述”,例如描述图1-15中“地球发动机”的各个部件及部件之间的关系。至于为什么地球发动机的部件和关系是这样的,这可能是其他各个学科的专家的工作成果。SysML建模人员只需要通过模型如实描述并验证。
我们再来看图1-15中的“发动机中控系统”。即使SysML建模人员已经通过SysML建模严谨地推导出信息系统的责任,包括输入什么信息,输出什么信息,从输入到输出计算的规则是怎样的,也就是说把B-需求都给描述清楚了,“发动机中控系统”这个信息系统的内部部件以及部件之间的关系依然是不确定的,需要“发动机中控系统”的开发人员自己构思和实现——100个团队可能有100个不同的构思。
“地球发动机”的部件以及部件之间的关系,可是其他专家团给出来的,并不需要自己构思。这一点就使得“发动机中控系统”的建模要比“地球发动机”更难。
当然,如果领导只是吩咐一句,做一个“地球发动机”,剩下所有工作都由SysML建模人员来做,那难度可就大了。
我们来看图1-15中的“反应堆”,《流浪地球》原文提到的“重元素聚变”应该属于“反应堆”的责任。我用SysML画了一张活动图,如图1-16。可以看到,这个过程处理的是能量(物质),原料和催化剂进来,变成能量出去(当然,还有废渣)。
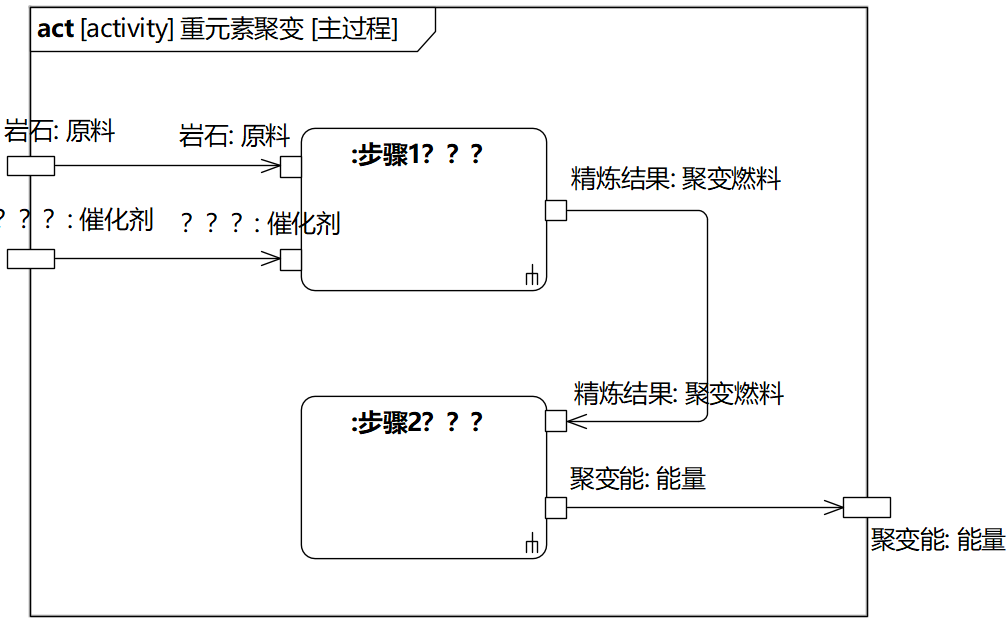
图1-16 重元素聚变过程
打问号的地方,例如聚变过程的各个步骤应该怎么进行,催化剂是哪些,需要什么样的反应设备(1000万℃的高温啊!),这些难题都需要各个学科的专家去攻克。和这些难题相比,通过UML建模构思信息系统的内部结构的难度就不算什么了。
信息系统可以看作是人脑的替代。像上面说的“根据接收到的测量参数值(可能有上万个),计算地球发动机下一步的最佳行动”,这个事情人也可以做到,因为计算的方法就是人指定的嘛,只不过人算得很慢很慢,所以用信息系统来做。
也就是说,我们建造信息系统是要把人脑总结出来的各种知识转移到信息系统中,并用它来取代人脑来做计算。信息系统的一切,包括规则如何表达,数据如何组织,各个部分的耦合、内聚等等,都需要我们一个一个构思。
目前,非信息系统的建模还没有“取代人脑”的压力,SysML更多是描述和帮助验证。
SysML最新规范地址:https://github.com/Systems-Modeling/SysML-v2-Release,最新版本是2025年2月发布的。
从目前的信息看,SysML v2有很大的变革,特别是大刀阔斧地清理术语。UML虽然把各种软件建模“方言”统一成“普通话”,但仍然做了一些妥协,留有各种冗余的尾巴。衍生自UML的SysML也不可避免存在冗余的问题。SysML把非必要的术语全部清理(和领域驱动设计圈子热衷造词形成鲜明对比),这是非常值得期待的。
因为UML和SysML两者非常相似,学习了一个相当于学习了另一个。如果你的工作只是开发信息系统,那么学习UML就可以。如果你的工作确实涉及到开发信息系统和非信息系统,可以直接学习SysML。在碰到不好用SysML建模的问题时,再适当引入SysML所没有的UML元素。
一条双赢的路线是:SysML发展到足以覆盖现在的UML后,吞并UML,然后把自己改名为UML——比UML还统一的统一建模语言。商业领域就有类似例子,2005年,SBC电信以160亿美元收购AT&T,然后把自己更名为AT&T。
1.3.4 UML建模工具和文本UML建模
1.3.4.1 UML建模工具的统计
从2000年开始,UMLChina就在网站上提供UML建模工具的统计。最开始是链接到objectsbydesign,我们负责帮objectsbydesign把它的统计文章翻译成中文,现在仍然可以访问,地址为http://www.objectsbydesign.com/tools/modeling_tools_cn.html。

图1-17 objectsbydesign.com网页
图1-18 2000年和objectsbydesign合作的邮件
★Stuart当时为此翻译慷慨地支付了我$1000。现在,翻译一本《分析模式》,估计最终得到的稿酬也比这个多不了多少。
考虑到objectsbydesign.com的统计更新频率较慢以及信息覆盖面不够,2002年,UMLChina开始自行制作UML建模工具一览表,不定期发布。
图1-19是一份以pdf格式保存的2003年6月的一览表,共31页,摘自《非程序员》电子杂志。该文件的下载地址:http://www.umlchina.com/tools/umltools200306.pdf。
图1-19 2003年6月统计的UML工具一览表
图1-19 的文件共列了130款UML建模工具,根据我的记忆,这个一览表上收集的工具最多时达168款。目前,UML发布类似信息的主要渠道改成了UMLChina公众号,http://www.umlchina.com/url/tools.html,如图1-20。

图1-20 UMLChina公众号发布的工具更新统计
★以上统计仅针对涉及UML建模的工具,其他建模表示法也会有相应工具,不在统计范围之内。
★感兴趣的读者可以搜索“国产 MBSE”,看看能搜到多少国产建模工具。
1.3.4.2 本书使用的UML建模工具
本书中的模型图,如果是我为了讲解知识而画的,用的建模工具主要是Enterprise Architect,有的图会用到Rhapsody和MagicDraw。如果是截取其他人提供的模型图,可能还会涉及其他工具。
以上提到的工具仅是我个人的选择,本书不详细评价各款UML建模工具。以上这三款工具目前都是收费的,从常理看来,收费工具的体验比免费工具好。如果您基于各种考虑选择使用其他的建模工具,甚至是在纸上手绘,本书的绝大部分建模知识依然适用。
1.3.4.3 文本UML建模
近年来,文本建模(Textual Modeling,营销用语有Diagrams as Code等)工具是UML工具市场中增长最快的细分领域。
如果把“从文本生成UML模型”都可以看做文本建模,那么上个世纪的Rational Rose和I-Logix Rhapsody都已经可以把Ada、C++、Java、VB代码转成UML类图。我们把定义缩窄,把文本建模定义为“以获得A、B、C工作流UML模型为目的而提供文本”。
OMG为UML定义了元模型、建模元素的语义和表示法,还定义了XMI(XML Metadata Interchange,XML元数据交换)标准用于各个工具厂商的不同建模工具之间的模型数据交换。这些标准一直沿用至今。
OMG曾在2004年发布过一个“UML Human-Usable Textual Notation”(https://www.omg.org/spec/HUTN/1.0/PDF),简称HUTN,试图提供统一的文本建模标准,但该规范未能继续下去。
以文本方式建模的非官方尝试,在这之前已经开始了。2002年,DiomidisSpinellis发布了UMLGraph(https://www.spinellis.gr/umlgraph/index.html),随后又有TextUML(始于2006年,https://abstratt.github.io/textuml/)、WebSequenceDiagrams(始于2007年,https://websequencediagrams.com)等。
★DiomidisSpinellis的书在国内有中译本的有《代码阅读》、《代码质量》。
★始于2001年的UMLet(https://www.umlet.com)比较难以归类。
目前最流行的应该是PlantUML(始于2009年,https://plantuml.com/),它是当前各个主流AI生成UML内容的缺省表示。其他类似文本建模工具还有:yUML、Mermaid、MetaUML、nomnoml、dotuml、ZenUML等。
现有的文本建模工具,绝大多数是基于Graphviz(始于1991年,https://graphviz.org)和DOT 语言的二次开发。
文本建模的优点
文本建模能够获得推行,主要原因是它降低了获得的门槛。
(1)web访问
比起类似于Enterprise Architect等点击、选择、拖动图形元素的建模界面,实现编辑文本然后渲染成图形的建模界面实现起来相当简单,何况有了Graphviz。
构造一款基于web的“建模工具”难度降低,使得文本建模工具普遍提供在线编辑器,这对于偶尔需要建模的开发人员来说十分便利,他们不需要额外安装软件,目前还都是免费的!
(2)和程序员常用的工具集成
文本建模时,模型的内容相当于另一门语言的代码,在编码环境、版本控制工具上的处理是一样的。这也使得文本建模在程序员群体中的曝光率大大增加。
★以上只是说“容易获得”,并没有说“容易使用”。比起Enterprise Architect等工具“所见即所得”的建模操作,编辑文字并不利于大脑的思考。这一点,在“1.3.2.2 文本 vs. 图形”中已提到。
文本建模当前存在的问题
(1)绘图而不是建模
目前的文本建模工具所做的其实是“绘图”:建模人员输入文本,工具把文本渲染成形状符合UML规范要求的图形,各张图(或各段文本)之间是独立的。
这样做实际上并不算建模。就像机械制图中的主视图、俯视图、侧视图都是描述同一个六角螺母一样,建模时,图只是从某个视角对某些模型元素的观察,不同图上的内容是有对应关系的。
注意,上面只是说目前文本建模工具存在这个问题,并没有说这个问题是由文本建模引起的。如果工具没有封装UML元模型的逻辑,只有图形处理的逻辑,都可能存在类似问题。
也就是说,界面是文本输入还是点击拖拽,并不是判断一个工具本质上是绘图工具还是建模工具的标准。A工具可能只有文本输入,文本输出,也不渲染图形,但它有可能是建模工具,因为它封装了UML元模型的逻辑;反之,B工具界面操作方便,图形在保持UML规范所要求形状的同时,用尽美工手段打磨得十分高大上,但它有可能仅仅是一款绘图工具。
如果本质上是当成图形来处理,还时不时会出现另一个问题:复杂图形(例如复杂状态机)的处理错误:不提供支持,或者无法渲染,或者得到的图形看起来违反语义。
(2)不统一
各个文本建模工具都有自己的语法,把PlantUML的脚本放到Mermaid工具中渲染,是得不到图形的。难道要再搞一个像XMI一样的交换标准?
过度吹捧文本建模的危险
上面讨论了文本建模当前的优缺点,建模人员可以在适合的场合下使用文本建模。如果有人(例如伪创新圈子)过度吹捧某个文本建模工具“敏捷”,很有可能是把它当成遮羞布了。学习了本书的内容后,你可以用《软件方法》提供的照妖镜去照一照他产出的各种工件,到处都是脓包的可能性非常大。
文本建模的将来
新版本的SysML同时支持文本表示法和图形表示法,完全可以覆盖现有的各种“文本建模”,而且足够严谨。这是一个努力的方向,即使SysML v2没有达到统一的目的,SysML v3再努力。
1.4 应用UML的建模工作流
1.4.1 UML工具箱
UML 2.5包含的图形一共有14种,如图1-21所示的树上的叶结点。
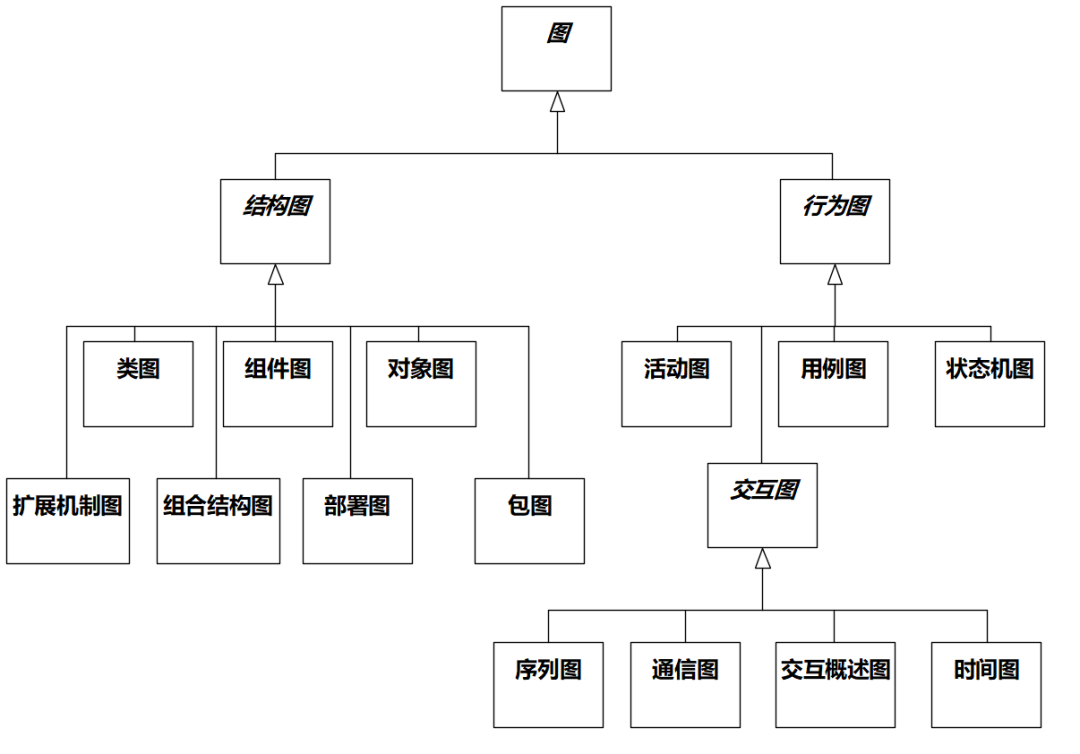
图1-21 UML图形(根据UML2.5规范绘制)
经常会有人有意无意地误导,让人以为使用UML建模需要画这么多图,顺势攻击“UML笨重”。其实,应该把UML看作一个工具箱。工具箱里面有各式各样的工具,建模人员只需要根据当前所开发系统的特点,从这个工具箱中选择合适的工具就可以,并不需要“完整地”使用UML。
这和编程语言类似。很多人说“我用Java”,其实只是用Java的一小部分,而且很长时间内也只会用这一小部分。
经常有学员问:潘老师,能不能给一个案例,完完整整地实施了整套UML?这是误解。这样的案例不应该有。这相当于问:有没有一本经典的小说,把字典里所有的单词都用上了?
有一些建模工具自带的案例模型会造成误解,一个模型里展示十八般武艺,把所有的UML图都给用上了。这是工具厂商出于展示其工具建模能力的目的而提供的,真实项目中不要这样去模仿。
我用类图表示建模工作流相关概念如图1-22。
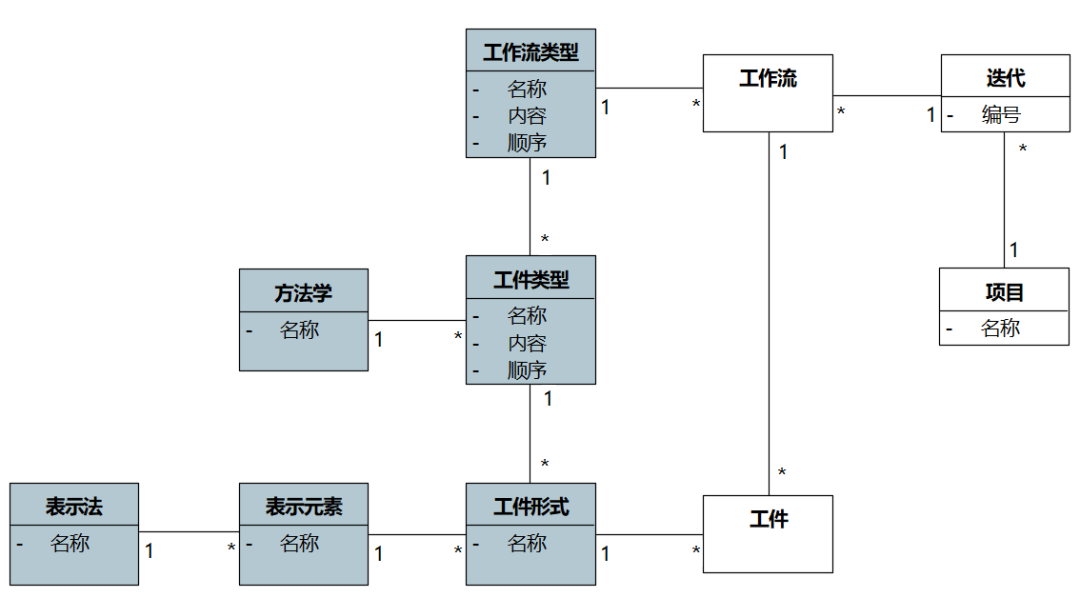
图1-22 建模工作流相关概念
图1-22左侧灰色部分定义了“游戏规则”,右侧则是在“游戏规则”上“玩游戏”的结果。
我用对象图展示本书202505版本之前推荐的“游戏规则”如图1-23,以帮助读者更好地理解相关概念。
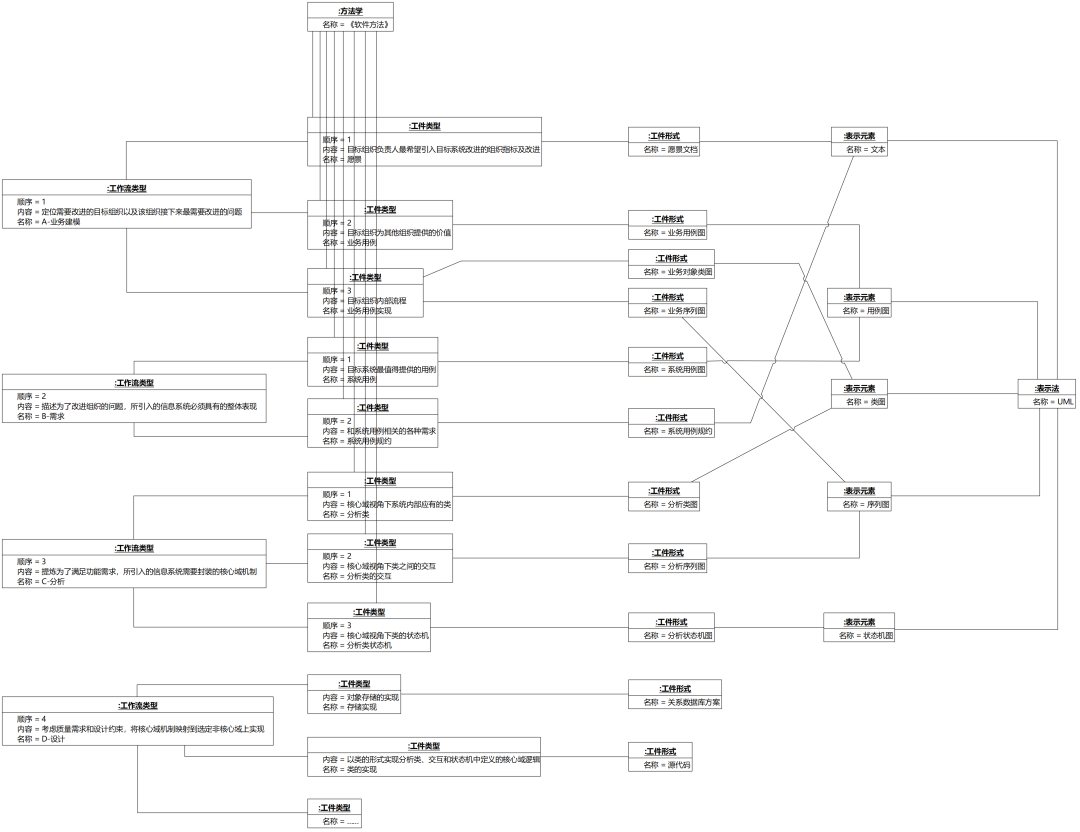
图1-23 建模工作流相关概念的对象图(图形较大,点开看或访问原图http://www.umlchina.com/book/1pics/fig1_023.png)
图1-23中,除了最左侧的“工作流类型”之外,都是可以变化的。
本书从202505版本开始,系统用例规约将改为用活动图表达。此时,我们只需要把图1-23中的工件形式“系统用例规约”和表示元素“文本”之间的链接改为工件形式“系统用例规约”和表示元素“活动图”之间的链接,如图1-24。
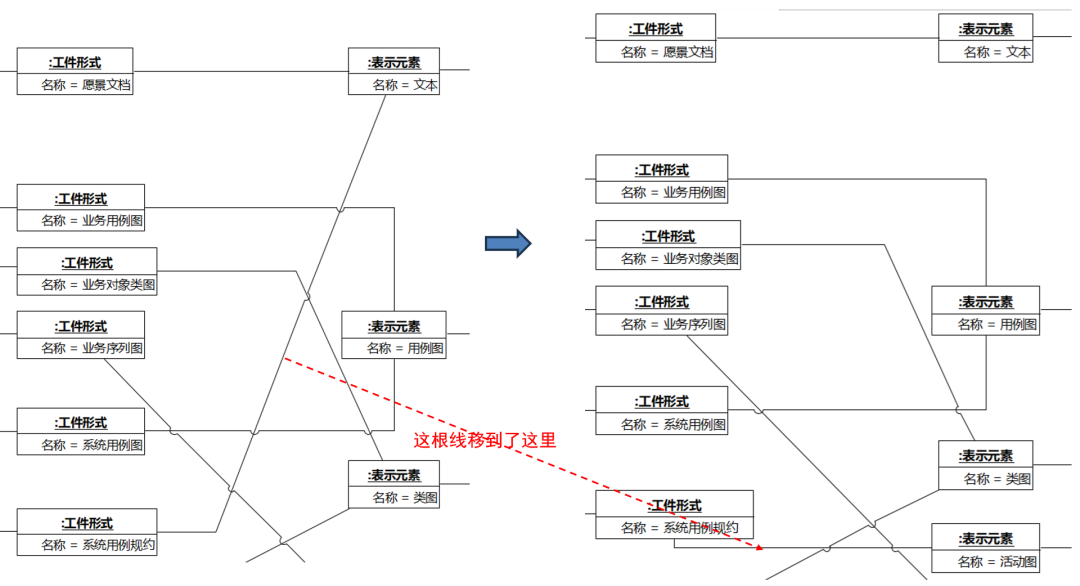
图1-24 系统用例规约改为用活动图表达
从图1-23到图1-24是更换“系统用例规约”这个工件的表示元素,从“文本”更换到“活动图”。
★也可以更换“表示法”。例如,把UML换成其他表示法或自创的表示法,那么图1-23左起3到5列都要修改。
★也可以更换“方法学”。例如,受“少林功夫+唱歌跳舞”启发,创造出“浑元形意太极+革命性创造划时代洞见领域驱动设计敏捷精益方法学”,但仍然使用UML表示法,那么图1-23左起2、3列需要修改。
从图1-23和图1-24可以看出,本书推荐使用的UML图形有5个:用例图、类图、序列图、活动图和状态机图。图1-25列出了其他可选的用法。
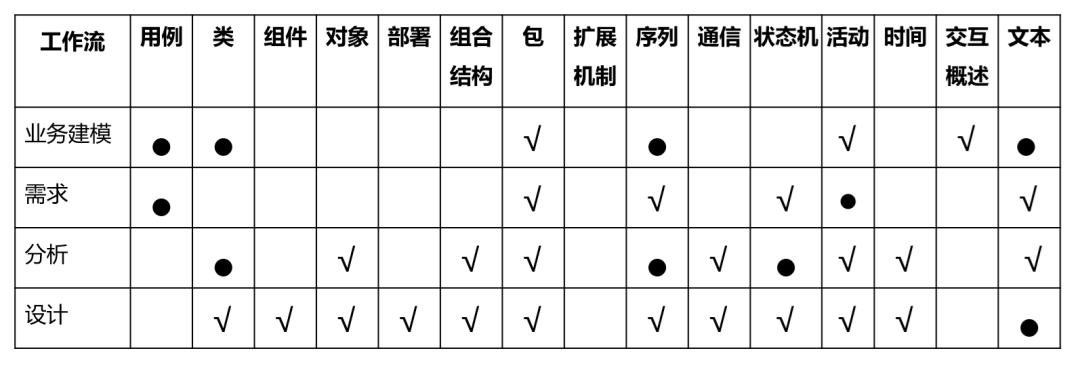
图1-25 可选和推荐的建模元素用法(●表示推荐使用,√表示可以使用 )
从图1-25可以看出,设计工作流的建模,推荐做法是不用UML表达,而是用相应实现平台的表示法表达,即所谓的“源代码”(目前大多是文本形式)。考虑了具体平台实现的类图、序列图、状态机图等,其中包含的信息和“源代码”差不多,没有必要花费精力去画设计工作流的UML图再编码,因为这样做没有带来任何增值。
更合理的做法是,做好分析工作流,把领域逻辑放进分析模型中,然后再结合实现平台的特点,定制从分析到设计的有规律的映射套路,通过建模工具或者人力搬砖把分析按照套路映射到设计。
这时,即使要画设计的类图、序列图等,也只需要挑选典型的类、典型的用例来展示映射的套路,不需要把分析模型的内容都结合实现平台画一遍。
像Rhapsody(当前的全名是IBM Engineering Systems Design Rhapsody)这样的建模工具,可以和各种开发环境集成,配置好后就可以通过正向工程从类图、状态机图生成可执行的代码。开发人员甚至可以做到只需要编辑和调试UML模型,不需要在编码环境中编辑和调试。图1-26是用Rhapsody工具绘制的某个模型(洗碗机)的运行时状态机图,粉红色标出了当前的状态。类图和状态机图的背后有真实的C++代码。
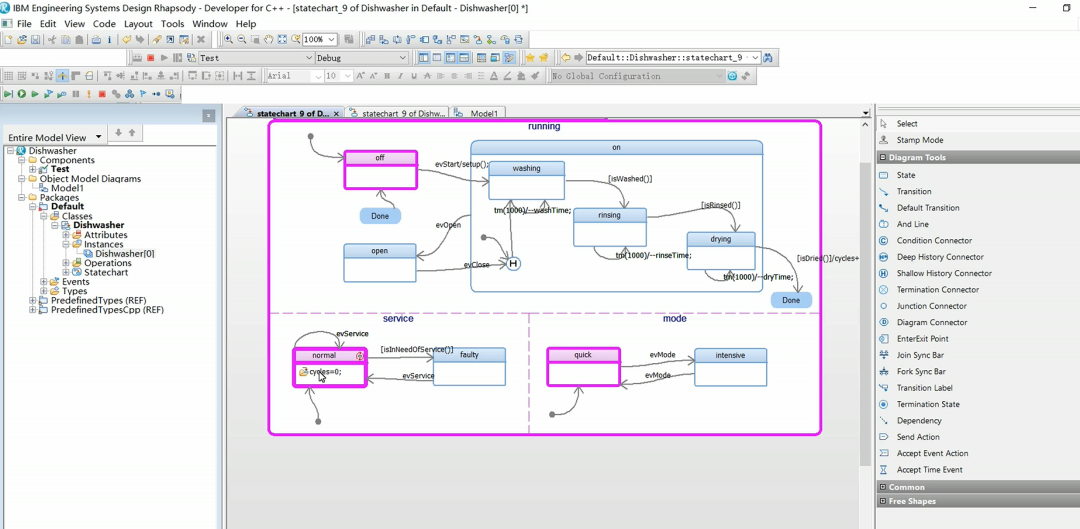
图1-26 Rhapsody下的运行时状态机图
当然,Rhapsody支持的平台和语言只是少数,而且目前很多建模工具在分析映射设计方面达不到类似Rhapsody的水平,但这并不妨碍我们针对所选择的实现平台来定制映射套路,然后通过人力搬砖来达到类似目的。在有AI辅助的情况下,通过例子不断训练AI,直到它掌握套路,可以代替大部分原来由人力搬砖的工作。
同样,如果需要设计工作流的UML图来搞形式主义充场面,可以通过建模工具对源代码或数据库做逆向工程,生成设计工作流的各种UML图。如图1-27,就是用建模工具UModel对某个C#类的某个操作做逆向工程生成的序列图。可以看到,这张序列图涉及到很多类的协作。图的右侧放大了一个小片段,勉强让读者能够阅读。
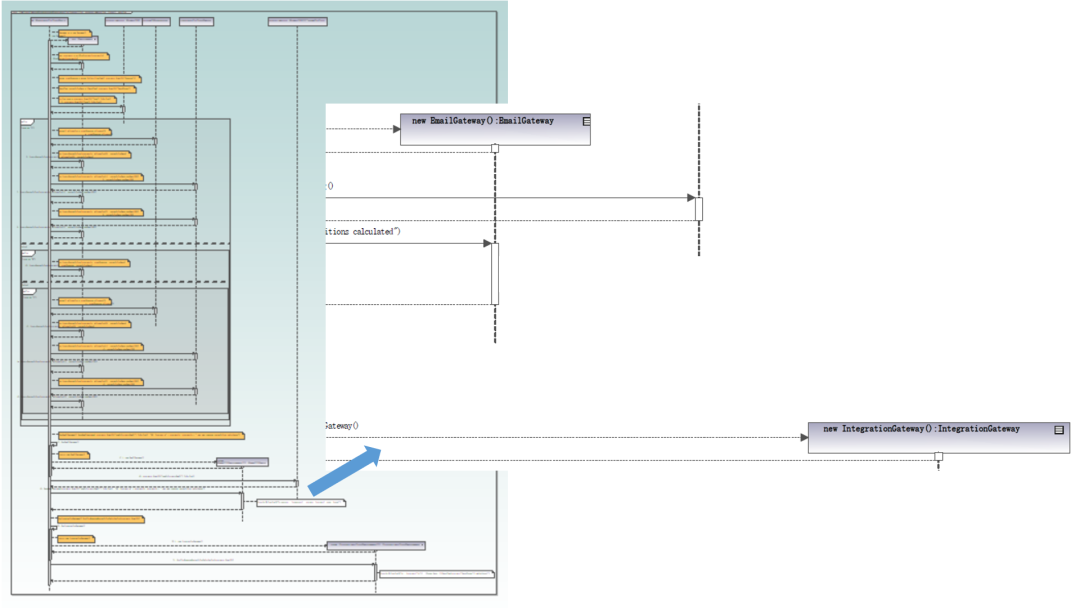
图1-27 从代码逆向工程得到的UML序列图
建模过程中,我们写的每一个字,画的每一张图,都应该能带来增值,否则就没有必要写它或者画它。这一点,在AI生成内容已经极其廉价的今天尤为重要。本书后面还会不断提到。
以上提到的定制映射套路、正向逆向工程等内容,本书在设计工作流的章节会再详述。
1.4.2 本书方法学推荐的建模步骤
我用活动图进一步表示本书方法学推荐的建模步骤如图1-28,让读者看到这些工件是怎样出现的。本书的内容就是按照图1-28的顺序讲述。
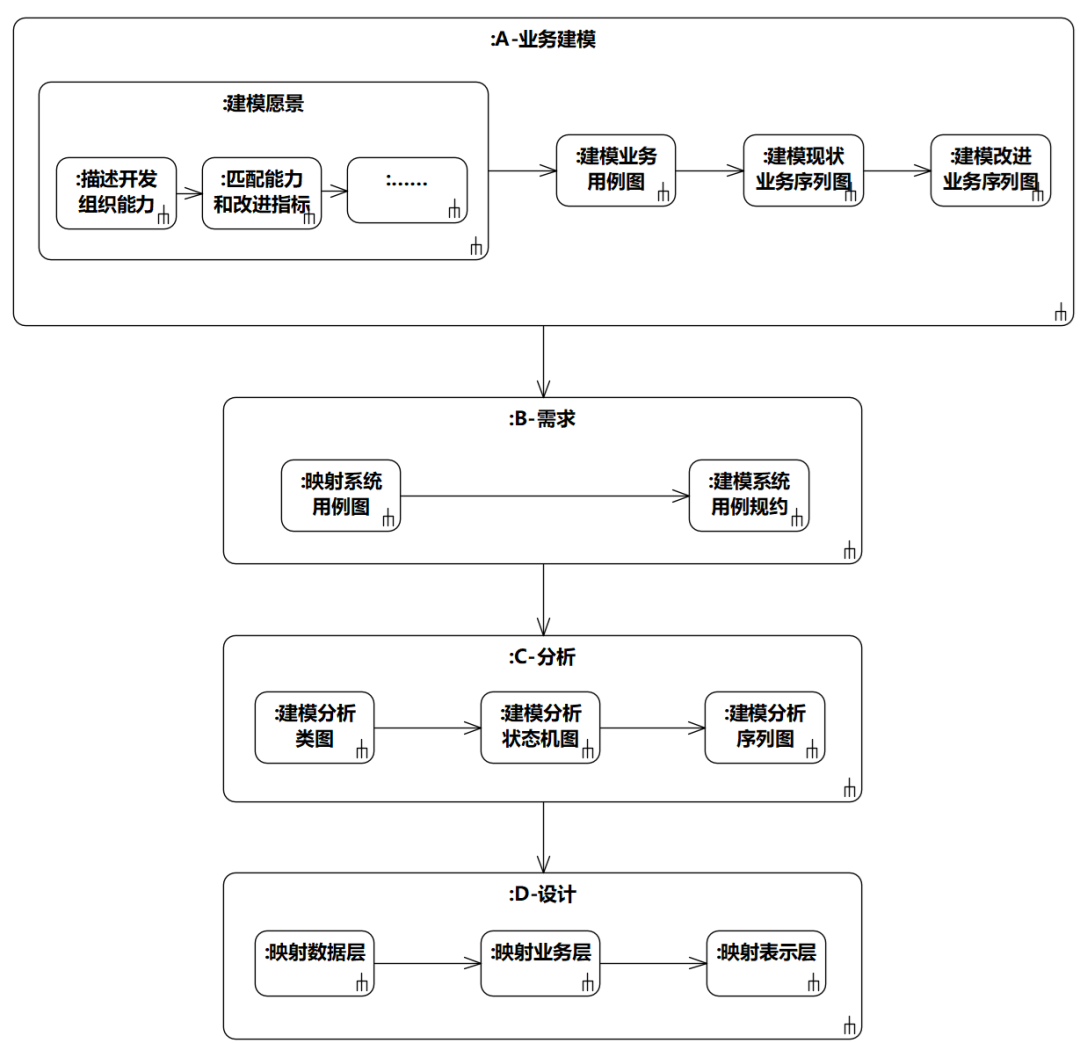
图1-28 使用UML的ABCD建模工作流步骤
图1-28的各个步骤,都可以用AI辅助。我们把AI当成一名学习能力极强的学生,用本书的方法学引导它,利用它掌握的资源帮助我们提高每个步骤所产出工件的质量。
例如,图1-28 左上角的“建模愿景”在AI辅助下的展开,可以如图1-29:
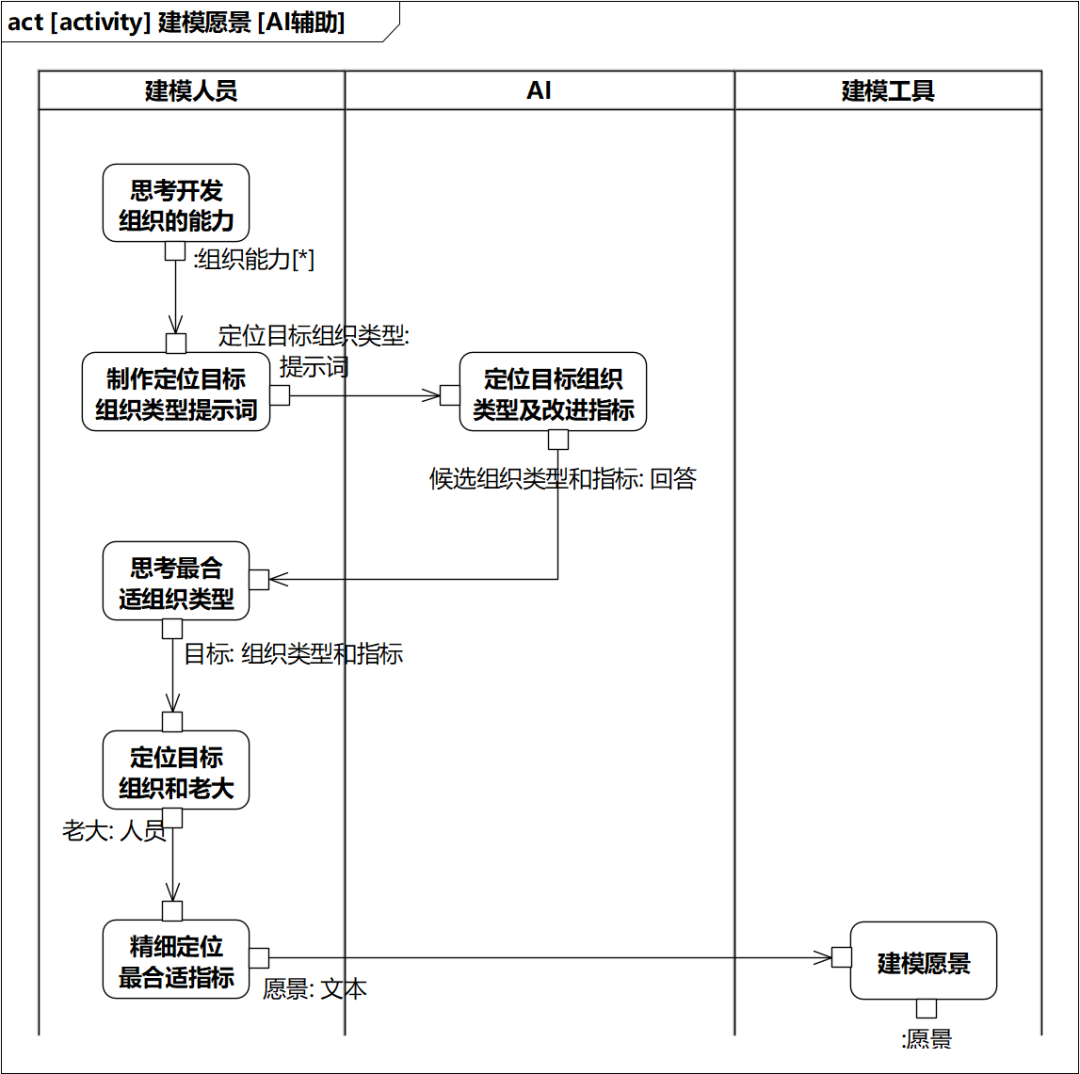
图1-29 AI辅助下建模愿景
1.4.3 关于“源代码就是设计”的歪曲和真相
1.4.3.1 Jack Reeves的文章
1992年,Jack Reeves在“C++ Journal”上发表了一篇名为"What Is Software Design(什么是软件设计)”的文章。
我把Jack Reeves文章中的观点列出如下,并附上我的评论。
(1)根据他的观察,软件开发生命周期中,唯一满足工程标准的软件文档是源代码清单。
——这是正常的。当时(1992年),除了源代码所使用的编程语言之外,软件开发生命周期中其他产出很难谈得上有什么严格的语法和语义规则。
(2)软件开发的一切都是设计过程的一部分。编码是设计,测试和调试是设计,平时我们称为“软件设计”的东西也是设计。
——这是要求从“设计”的高度来看编码,不是说代码能编译运行就行。
(3)C++是很有表达力的软件设计语言。
——要从“设计”的高度来看编码,编程语言要有好的表达力,例如C++。毕竟是发表在C++ Journal上的文章嘛。
整体来看,Jack Reeves的文章没有太偏激的观点。即使存在问题,也是前文提到的普遍缺少A、B工作流知识的问题。
1.4.3.2 Robert C. Martin的修饰
"What Is Software Design”一开始并没有广为流传。
2002年,Robert C. Martin在他的书“Agile Software Development, Principles, Patterns, and Practices”第1版中附上了这篇文章,并在前面加了个大标题“The Source Code Is the Design(源代码是设计)”。
这是Robert C. Martin的第一个“小心思”。
Robert C. Martin这本书的书名也包含着“小心思”。“Agile Software Development, Principles, Patterns, and Practices”主要讲的是面向对象设计的一些方法(原理、原则和模式),这些方法并非Robert C. Martin首先提出,和“敏捷”提倡的“过程”也没有必然关系,但Robert C. Martin把它们称为“敏捷**”,很容易让开发人员误解,这些东西是“敏捷”人士提出来的。

图1-30 “Agile Software Development, Principles, Patterns, and Practices”的目录
最近一些年的领域驱动设计伪创新走的也是这条路线,背后的操盘者们也是来自同一个圈子。更多评价见后文提到的“染色”。
2007年,Robert C. Martin在第2版“Agile Principles, Patterns, and Practices in C#”中,也附上了Jack Reeves的文章,但名字改成了“What Is Software(什么是软件)”
1.4.3.3 中文翻译的误导
Robert C. Martin书的第1版中译本《敏捷软件开发:原则、模式与实践》中,把“The Source Code Is the Design”翻译为“源代码就是设计”。
“是”和“就是”有微妙的差别,“是”表达的是从属关系,“就是”隐含着相等关系。
马铃薯是草本植物:马铃薯∈草本植物
马铃薯就是土豆:马铃薯=土豆
源代码是设计:源代码∈设计或源代码⊂设计
源代码就是设计:源代码=设计
从上面列出的观点(2)可以看出,Reeves的文章中并没有这个意思。
文章"What Is Software Design”目前可在以下地址获得:
https://www.developerdotstar.com/mag/articles/PDF/DevDotStar_Reeves_CodeAsDesign.pdf
感兴趣的读者可以去下载阅读。
另外,以上只是说Reeves的意思被歪曲了,但没有说Reeves本来的意思就一定是对的。类似这样的观点,往往都存在前文提到的普遍问题:缺少对A和B工作流的认识。
**********
关于“source code(源代码,代码)”,有的开发人员也存在误解。
计算机运行的是二进制指令,源代码是程序员需要理解和编辑的最低形式模型——编辑完这个,后面的事情就可以交给计算机了!
中文翻译“代码”中的“代”字就体现了这个意思,用更方便理解和编辑的符号来“代替”原来的指令。从这一点看,编码就是一种最低形式的建模工作,源代码也是“模型”。
这个最低形式模型是随着时代的发展不断变化的,如图1-31所示。
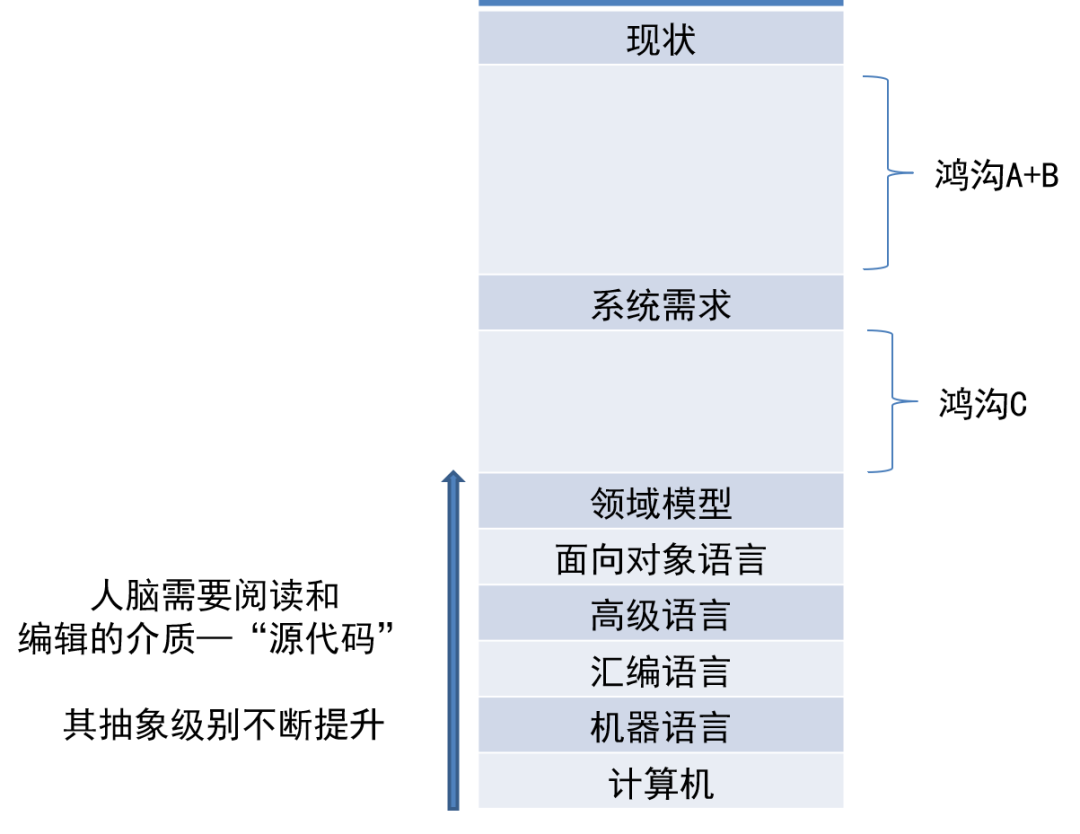
图1-31 “源代码”的发展历程
最开始,程序员在纸带或卡片上打孔来表达0和1,这可不是“代码”了,就是“码”本身。
后来发现这样太累了,于是发明了一些助记符,这就是汇编语言。
有的开发人员凡尔赛,“这些我不太懂唉,我是做底层的,用C编码”,可是C语言却被归类为“高级语言”,因为类似C这样的语言出现的时候,大多数程序员编辑的是汇编语言,C相对于汇编来说,当然很高级。
今天的一名企业应用程序员,需要编辑的可能有HTML、CSS、JavaScript、Java、配置脚本、SQL等,这些就是当前常见的“源代码”的形式。
如果人脑只需要编辑UML模型就可以实现系统,不需要编辑Java、C#等文字形式代码,那么UML模型就相当于“源代码”。这是目前可以期待的,也是图1-31中向上的箭头目前能到达的。
图1-31中的“鸿沟”则表示目前还非常需要人脑(建模人员的大脑)去解决的部分,后面在谈到人工智能对建模工作流的帮助时还会详细讲解。
因此,不存在什么“无代码”、“低代码”,人最终需要编辑的那个东西就是“代码”。
★很多(15+)年前,一位CTO向我展示他们的软件,说不用编码就可以为不同的客户定制(当然,变化范围也有限)。我问他怎么做到的,回答“只需要改配置文件里面的各种信息就行!”。其实那个配置文件就是一种“代码”。
总之,关于“源代码是设计”,不管是Jack Reeves,还是后来花心思包装的Robert C. Martin,认识都是不够严谨的,正如1.2.4.1 思维颠倒所说的,主要问题出在对“设计”的认识上。
1.5 警惕和揭秘伪创新
初中数学里要学习全等三角形、相似三角形、SSS、SAS……,到了高中以后学了正弦定理、余弦定理等解三角形的知识……就不会再回去用初中的方法解题了。
但是,不是所有人都能学会高中的知识,比如说张三。
张三可能会这样解释:
“我这个人能力比较弱,只能掌握全等三角形、相似三角形的方法。”
这样的说法没有问题。
张三还可能会这样解释:
“这个题目比较简单,用全等三角形、相似三角形的方法做足够了,而且这样更方便广大人民群众理解。”
这样的说法也可以。不过,竞争对手不是傻子,市场中哪里有什么"简单题目"!能带来利润的题目都很复杂。
但是,张三如果这样说:
“全等三角形、相似三角形的知识比高中三角函数的知识更深刻。”
这是自欺欺人。
更要警惕的是,有一个李四,也许和张三一样没有掌握高中方法,也许掌握了高中方法但是为了忽悠张三们,偷偷把"全等三角形"改名为"叠合三角形",然后和张三宣传:
“我发明了"叠合三角形"新方法,比高中的三角函数有用,三角函数过时了。”
这就是可恶了。
前文已经提到过伪创新,此处,我们再来详细谈一谈。
1.5.1 你情我愿的伪创新
前面20-30年间,互联网和信息行业的大发展,使得大量没有受过应有训练的人员加入并从事软件开发工作。他们中的一部分人并没有“补课”的意愿和能力,而是致力于寻找可以让他们逃避辛苦学习的伪创新。他们是“伪创新”的买家。
某些开发团队的工作实际上是在装模作样,浪费时间在那里废话刷工作量。在“猪都会飞”的时期,特别是在开发团队的能力不是关键竞争要素的领域,废话刷工作量的危害没那么明显。而开发团队为了突出自己的贡献,想表明所在组织取得的成功来源于本团队超人一等的能力和努力,迫切需要拉上某些“方法”作为面子和证据。他们是“伪创新”的买家。
有买家就有卖家,于是,国外国内就有人炮制出各种投资少,见效快,产量大、门槛低、仪式感十足的伪创新,组成圈子向开发团队宣传。
开发人员和开发团队一接触,欢天喜地连称“受用”,更加心安理得地假装努力,骗客户,骗领导,骗自己。
前些年,伪创新以“敏捷”为名,近年来,伪创新以“DDD(领域驱动设计)”为名。细心观察可以发现,背后的主要推手是同一批人。
1.5.2 不学有术
严谨而系统化地研究某个领域中前人的成果,清楚前人曾经想过什么,做过什么,哪些成功了,哪些失败了,才能提出真正的问题并解决问题——这是真正的创新。
伪创新圈子的“创新”却来得非常容易,可以说是“不学有术”——不学习却能大量输出。
他们不去认真研究前人的成果,而是基于自己碎片化的阅读和经验,把一些朦胧感悟写出来,然后造一个新词来命名,就得到“创新”了。
★有的网红甚至是这样“创新”的:我和公司同事某某(也是网红)讨论了什么什么,就悟到了某某创新。
在伪创新圈子的文字里,常会见到“我突然想到”、“我发现”、“我悟到了”等字眼。
如果仅仅是发表自己的体会或感悟,即使内容是错误的,也是个人自由。伪创新圈子的问题在于:他们硬要把自己的体会包装成“创新”,然后向大家布道。
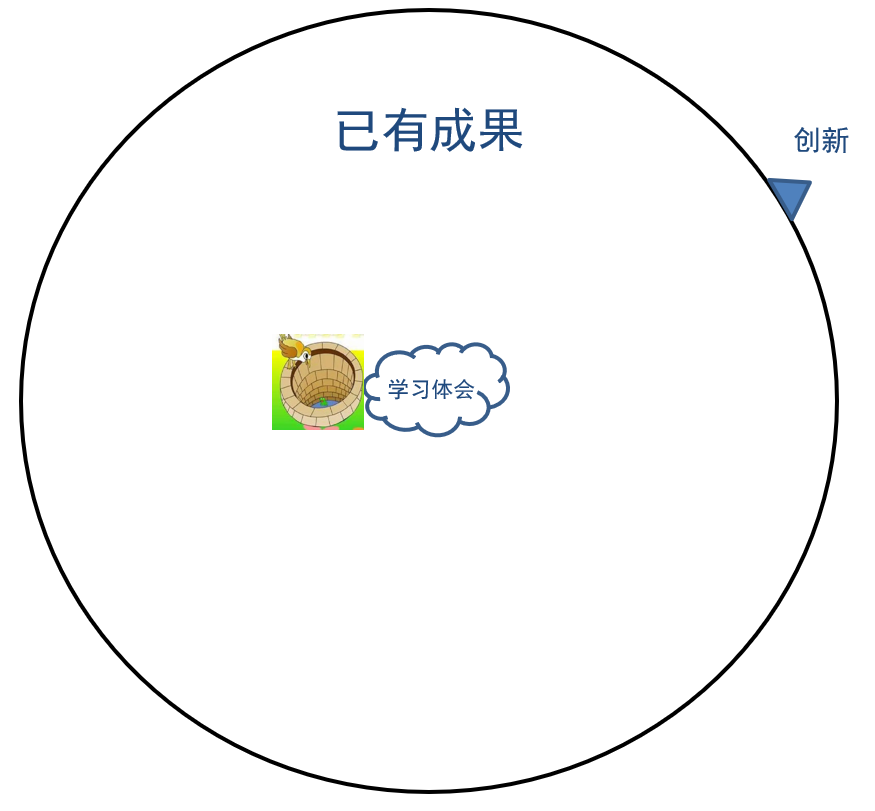
图1-32 体会和创新的区别
天下没有免费的午餐!“不学”却“有术”的伪创新,它的内容符合以下特点之一:
(1)错误
不管是过去的开发团队,还是现在的开发团队,用上了不但没用反而有害。错误的内容可谓是“百花齐放”,什么样的都有。
(2)过时
悟出来的内容,其实之前已经存在而且在一定时期内发挥了作用,但现在已经被更好的知识取代。
例如,某DDD实践者分享了自己创造的架构表示法,仔细一看,不就是1970年代的数据流图吗?现在在需要画数据流图的地方,使用UML或SysML活动图是更好的选择。
(3)拙劣的模仿
例如,某发明家急于“创新”,模仿现在仍在发挥作用的方法学自己搞了一套,只不过各种名称换成了自己的“造词”。由于不下功夫学习,囫囵吞枣,“创新”的“方法学”比起现有的成熟方法学来,到处是倒退和漏洞。
学霸做了一份试卷,比较难,估计拿不到满分。学渣自告奋勇,硬是要帮学霸改一下以提高分数,你猜会是什么结果?
该掌握的知识没有掌握,就硬着头皮“创新”,后果可想而知。
上面所说的不只是符合软件开发的伪创新,网络上的各种“数学民科”、“物理民科”的“数学创新”、“物理创新”也是非常符合的。
如果这些“民科”能花时间去认真学习大学(本来想说高中,但听说中学要求的学习深度在逐年下降)的数学和物理——就当是卧底,带着批判和找茬的目的去学——学习到能独立把大部分习题做对的程度。
如果他们真的能做到这一步,估计也就不会再相信之前自己瞎掰的那些东西了。
可是有多少“民科”会这样去做呢?如果他有如此认真学习的兴趣和毅力,之前他也不会“不学有术”地频频“创新”了。
我也曾经和软件开发的伪创新圈子说过多次,就算是带着批判和找茬的目的,把我的书看一看,把我出的几百道题做对了。
同上,要是真的把题做对了,他也就不会再去相信那些伪创新了,甚至会为曾经相信那些东西而羞愧。
可惜,没有人能做到。有的人看两页书,题也不做,就啪啪啪发一堆感悟——然后,一直停留在那里。
最后要说明一下:
“民科”说的是做事的态度和方法,并不绑定具体身份——例如定义官方研究机构之外的研究者一律为“民科”。
不少真正的创新来自企业。特别是IT业,一些创新甚至来自非正式团体或个人。不过,官方研究机构的人员筛选,使得伪创新的概率会小一些,至少知道写东西之前要先做研究。
而企业特别是互联网企业在“猪都会飞”的膨胀期,吸纳了各种各样没有严谨态度的人员——所以,大家可以看到一些头部互联网企业会加入很多伪创新的推波助澜中,特别是员工喜欢到处“布道”的企业。
当然,也有著名科学家年轻时真正在研究科学,进入老年之后大脑退化,不能也不愿沿着科学的道路继续探索,同时又面临死亡的无解难题,于是转为宣传宗教甚至宣传迷信。
1.5.3 造词
伪创新圈子很擅长造词,恨不得每个用词都能当演讲题目。
如果人们得知一个东西曾经存在过,那么当这个东西再次被拿出来宣传时,人们会对宣传持有较多的理性,“这东西如果真的这么厉害,那之前怎么……”,宣传的人也会收敛,不至于那么夸张。如果起一个新名字,就会给人一种“全新”的感觉,人们可能就会给一个机会,毕竟是“新”的,没准人家真的有这么牛呢。
例如,说青霉素可以治愈肝癌,大众肯定不信,要是真的可以治愈肝癌那么多年不早就验证了嘛;如果把青霉素改个名字叫“K9527-α”,说可以治愈肝癌,可能就会有患者给它一个机会,买了试一试。
一个机会就够了!大不了这个词不好使了再换个词呗,造词工厂的流水线可是全年开工的!
并不是说青霉素没有价值,杀灭还没有耐药的细菌总是可以的。就算是淀粉做的假药,还可以起到充饥的作用呢。
危害在于,被误导的肝癌患者可能会将宝贵的金钱和时间资源优先用在了“K9527-α”上,耽误了获得更好治疗方案的机会。
1.5.3.1 造词手法1:换词
造词手法可以是换词,相当于X→Y。
例如,把“术语表(Glossary)”换成“通用语言(Ubiquitous Language)”。
换词是比较粗暴的,下面的做法就比较温和。
1.5.3.2 造词手法2:微调
造词手法可以是微调,相当于mX→nX。
微调可以是加减数量,例如,把“六边形架构”的边数减2,得到“四边形架构”。
微调可以是换某个字,例如,把“彩色建模”改成“四色建模”。
1.5.3.3 造词手法3:加前缀
造词手法可以是加前缀,而且可以加不止一个,相当于X→AX、ABX……。
例如,在“愿景”前面加前缀“领域”,得到“领域愿景”;在“事件”前面加前缀“领域”,得到“领域事件”;在“需求”前面加前缀“业务”,得到“业务需求”;在“需求”前面加前缀“用户”,得到“用户需求”。
图1-33是知乎上的一篇阅读量还比较大的DDD(领域驱动设计)文章,先不说“领域模型……反映需求的本质”的说法是错误的,光是看在“需求”前面累计叠加了三个前缀得到的“领域内用户业务需求”就叹为观止了。

图1-33 知乎上的一篇关于领域驱动设计的文章
1.5.3.4 造词手法4:加后缀
造词手法可以是加后缀,而且可以加不止一个,相当于X→XA、XAB……。
例如,在“功能”后面加后缀“架构”,得到“功能架构”;在“功能”后面加后缀“设计”,得到“功能设计”。当然,还可以连起来——“功能架构设计”。
把前缀后缀都利用起来,可以得到“领域用户业务需求功能架构设计”。
显然,在加各种前缀后缀的时候,“发明家”并不真正了解原词和前缀后缀的真正含义,只是为了强调自己对所加前缀后缀的重视——我非常重视领域、业务、用户、架构、设计。
伪创新圈子喜欢用当下的热词作为前缀和后缀,例如现在的“数智化”、“人工智能”等,因为这些热词给了他们造词的理由——××时代都到了,不得整一套新方法啊?
有心的读者可以观察造词圈子的文章,看看有没有类似以下模式的表达:
在[某热词]的时代,[某伪创新]提出[某新词]
在[某热词]的形势下,[某伪创新]提出[某新词]
1.5.4 运作
1.5.4.1 偷梁换柱
步骤如下:
(1)当X比较难时,发明aX,用a来装饰X。a通常是某个带有褒义的形式或仪式。
(2)组圈子互吹互捧aX,把焦点放在a上。
(3)对X畏难的“目标客户”闻风而来,大家热烈讨论a,心照不宣地假装所有人的X已经没有问题。
以“大声建模”为例:
(1)建模比较难,于是发明“大声建模”;
★“大声”是一个形式,这个形式带有褒义:我大声我骄傲,你要是反对“大声建模”,你就是“偷感建模”。不过,以下人士哭晕在厕所:霍金、图灵(口吃)、牛顿+特斯拉+诺贝尔(害怕交际,终身未婚),“大声建模”对他们来说可太难了!
(2)组圈子互吹互捧“大声建模” ,把焦点放在“大声”上。
(3)对建模畏难的“目标客户(软件开发人员)”闻风而来,大家热烈讨论如何“大声”,心照不宣地假装所有人的“建模”已经没有问题。
这样的手法也可以很隐蔽。我们来看“领域驱动设计”,这个看起来不符合我们上面说的aX,别慌,我们这样:
(1)面向对象分析设计比较难,于是把“领域驱动设计”定义为“新一代的面向对象分析设计”;
(2)组圈子互吹互捧“领域驱动设计是新一代的面向对象分析设计” ,把焦点放在“新一代”(或革命性、划时代)上;
(3)对面向对象分析设计畏难的“目标客户(软件开发人员)”闻风而来,大家热烈讨论 “新一代”,心照不宣地假装所有人对“传统的面向对象分析设计”已经熟悉到“见山还是山”,都不屑一谈了。
这样的手法也可以用在其他领域,例如“微笑手术”:
(1)手术很难,于是发明“微笑手术” 。“微笑”是一个形式,这个形式是褒义的,谁能反对“微笑手术”呢?
(2)组圈子互吹互捧“微笑手术” ,把焦点放在“微笑”上。
(3)对手术畏难的“目标客户(医生)”闻风而来,大家热烈讨论如何“微笑”,心照不宣地假装所有人的“手术”已经没有问题——董小姐们的“微笑”可是碾压各位木呆呆医生!
大家可以拿这个思路去观察还有没有类似这种用形式来掩盖内容的“偷梁换柱”。
我以前在文章里也提到过某次“我和小伙伴都惊呆了”的经历:大概是18年前(感慨,今年2025年,已经18年了啊), 一个文科出身的编辑上台大谈敏捷开发一个小时。
没有专门学过计算机科学或软件工程方面的知识(应该没有),也没有从事过软件方面的工作,谈“开发”是谈不来的,但可以谈“敏捷开发”——重点谈“敏捷”嘛,那可太擅长了!
“偷梁换柱”是谈a而避谈X,如果这一招不凑效,必须得谈X了,怎么办呢?
1.5.4.2 山寨
(1)迎合伪创新买家的喜好,有意或无意地模仿已有的X、Y、Z方法,发明出相应的X-、Y-、Z-方法。
★有意:发明者知道X、Y、Z的存在,但只是粗浅了解,没有认真研究。
★无意:发明者不知道X、Y、Z的存在,费尽心思发明出X-、Y-、Z-,实际上仅是对已有X、Y、Z拙劣模仿。
★买家的喜好:只了解D工作流,不了解ABC工作流也不愿意学习。
(2)把谈论范围限制在X-、Y-、Z-,避免谈及X、Y、Z。
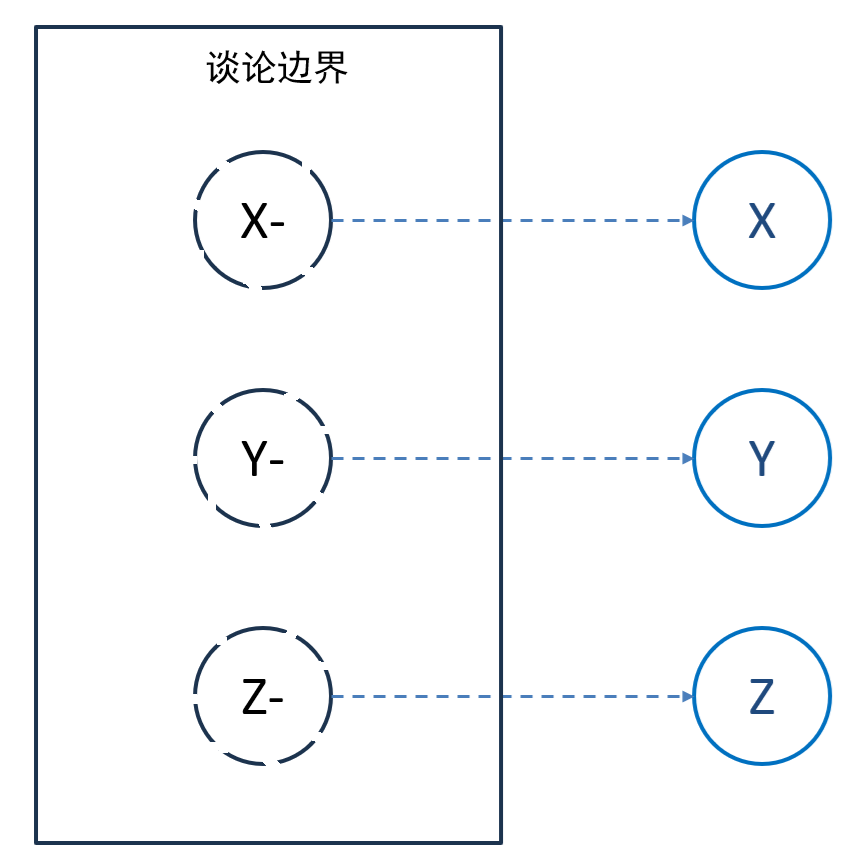
图1-34 山寨
可能有的读者会下意识认为,哇塞,这不是GoF设计模式里面的“适配器(Adapter)”模式吗?这样一搞,X、Y、Z能适配不同的目标人群,这是好事啊!
这不是“适配器”。“适配器”是接口不兼容的时候提供“适配”,干活的逻辑还是X、Y、Z的逻辑。伪创新则是另搞了一套粗陋或错误的内容,把X、Y、Z扔掉了(或者压根没听说过X、Y、Z)。
也就是说,有可能X-、Y-、Z-的“接口”和X、Y、Z一样,但内容是粗陋或错误的。
1.5.4.3 染色
把自己定义得很抽象,以便把已有成果纳入自己的领地,我把这个叫作“染色”。
“Domain-Driven Design”的作者Eric Evans就把领域驱动设计称为“哲学”,他在“Domain-Driven Design”的前言中说:
Although it has never been formulated clearly, a philosophy has emerged as an undercurrent in the object community, a philosophy I call domain-driven design.
不过,一门哲学像一股暗流已经在对象社群出现,虽然还从来没有被清晰确切地表述出来。我把这门哲学叫作“领域驱动设计”。
把领域驱动设计定位为“哲学”,这个超然的地位使得领域驱动设计更方便地把从前、现在和以后的成果纳入领域驱动设计的领地。
有心的读者可以用“DDD的”、“领域驱动设计的”、“DDD提出”、“领域驱动设计提出”等关键词搜索,会得到各种染色的结果,如图1-35。

图1-35 领域驱动设计的染色
“领域驱动设计”继承的是“敏捷”的风格。“敏捷”可以说是染色的“巨人”了。
2001年2月喊出“敏捷”口号之后,迅速出现一批名为“敏捷××”的书籍。我挑出一些名字相当直白的书(还有很多内容类似的书名字稍委婉):
Agile Software Development, Alistair Cockburn,2001
Agile Modeling,Scott Ambler,2002
Agile Software Development: Principles, Patterns, and Practices,Robert C. Martin,2003
Lean Software Development: An Agile Toolkit,Mary Poppendieck 等,2003
Agile Management for Software Engineering,David J. Anderson,2003
Agile Documentation,Andreas Rüping,2003
Agile Database Techniques,Scott Ambler,2003
Agile Software Development,Alan S. Koch,2004
Agile Project Management,Jim Highsmith,2004
Agile Project Management,Gary Chin,2004
Agile Estimating and Planning,Mike Cohn,2005
Agile Java,Jeff Langr,2005
Agile Web Development with Rails,David Thomas 等,2005
Agile Development with ICONIX Process,Doug Rosenberg 等,2005
Agile Java Development with Spring, Hibernate and Eclipse,Anil Hemrajani,2006
Agile Systems with Reusable Patterns of Business Knowledge,Amit Mitra 等,2006
Agile Information Systems,Kevin C. Desouza,2006
Agile Software Construction,John Hunt,2006
……
上面所列的这些书籍,大部分有中译本。

图1-36 敏捷宣言之后的几年内出版的一些书
注意,“敏捷”并不把染色限于项目管理或过程改进,面向对象、数据库、Java、Web等内容也被“敏捷”染了色。
最典型的是Robert C. Martin的“Agile Software Development: Principles, Patterns, and Practices”。这本书主要讲述的是面向对象分析设计的一些内容,这些内容非Robert C. Martin首先提出,而且和具体过程没有必然关系,但Robert C. Martin的做法使很多开发人员产生误解,以为这些内容是敏捷圈子的研究成果。
“Agile Software Development: Principles, Patterns, and Practices”的内容扩展自Robert C. Martin于2000年在自己网站objectmentor.com上发表的“Design Principles and Design Patterns”,Robert C. Martin在这篇文章中整理了一些他认为比较重要的“原则”和“模式”。

图1-37 “Design Principles and Design Patterns”截图
★目前,objectmentor.com已不再有效,在网络上可以下载到“Design Principles and Design Patterns”文章的地址是:
https://staff.cs.utu.fi/~jounsmed/doos_06/material/DesignPrinciplesAndPatterns.pdf
“Design Principles and Design Patterns”的几十页内容中,没有一处提到“agile”(正常,口号还没喊出来呢),也没有一处提到“light”、“lightweight”、“process”或“methodology”,说明Robert C. Martin自己非常清楚这些内容写的是什么。
而在他2003年的书中,这些内容摇身一变,成了“敏捷软件开发原则”。读者可以体会一下,Robert C. Martin是出于什么样的心思。
这二十多年来,我在和各种开发人员打交道的过程中,就因此备受困扰。
在圈子的强力宣传之下,开发人员变成井底之蛙,以为所谓的SOLID原则就是软件设计的法宝,学会了它,就能搞定软件设计的问题;反过来,如果没搞定,就是因为没理解透这几个原则。
于是,开发团队就来找我给他们讲SOLID原则(以及同样出名的GoF模式)。碰到这种情况,我也只能如实告知,讲当然没问题,主要就是一个泛化(继承)的应用,车轱辘话产出这么多内容,但除此之外,分析设计还有更难也更有价值的内容值得学习。
读者不妨结合前文内容猜一猜,我这样一说之后,开发团队怎么反应的概率最大?
“敏捷”的“染色”持续到今天。最近几年的各种热点,“敏捷”都有“染色”——敏捷大数据、敏捷机器学习、敏捷人工智能,如图1-38。

图1-38 最近几年出版的紧跟热点的“敏捷”书籍
除了圈子众人主动出击四处“染色”之外,当“敏捷”成为政治正确时,一些本来在圈子外的方法学家(甚至还包括UML三友之一)眼见口号来势汹汹,于是就带着自己的方法来投靠,宣称“我这个***也是敏捷的!”。
如何让“武德驱动设计”包揽每一年的诺贝尔物理、化学、生理学奖?
(1)提出“武德驱动设计”的口号,把它定义为“一种强力推动人类文明发展的科学”;
(2)全球组圈子,散布“武德驱动设计是一种强力推动人类文明发展的科学”的说法;
(3)称赞乐意投靠的诺贝尔物理、化学、生理学奖获得者符合“武德驱动设计”的精神;
(4)建立“凡是强力推动人类文明发展的科学就叫武德驱动设计”的思想钢印。
(5)不认同(至少在口头上)“武德驱动设计”的科学家,将无法获得诺贝尔物理、化学、生理学奖。
你,学会了吗?
1.5.4.4 割裂历史
伪创新会有意无意地忽略掉自己被“创新”出来之前的某段历史,把对比的参照物拉回到很多年前,来证明自己的“进步”。
“敏捷”的宣传中,一开始会描述“瀑布”如何如何糟糕,然后说“敏捷”如何如何比“瀑布”好。把“敏捷”直接和“瀑布”对比,似乎在“敏捷”出现之前就是“瀑布”。
实际上,增量迭代开发、持续集成等软件工程实践早已有之。即使是那篇被频繁引用的著名“瀑布”论文,Winston W. Royce发表于1970年的“Managing the Development of Large Software Systems”,也并不提倡以顺序模型作为团队的过程模型。图1-39是该文的一个截图,注意图中的“Iterative(迭代)”一词。对全文感兴趣的读者可自行搜索阅读。
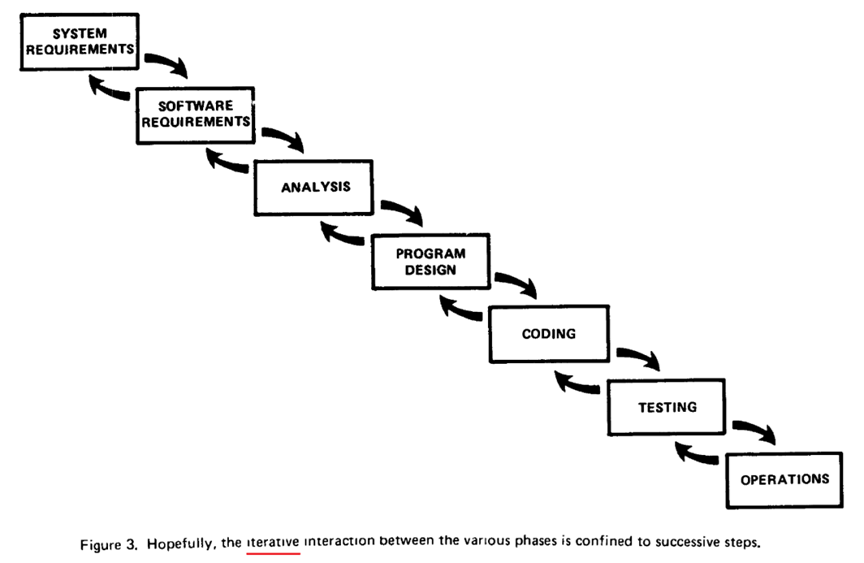
图1-39 摘自Managing the Development of Large Software Systems(Royce W. W. , 1970)
这样的宣传,抹杀了造词“敏捷”之前的软件开发过程所取得的进展,给不了解情况的开发人员留下“这是敏捷发明的,所以嘴上喊着敏捷的人最懂”的印象。
“领域驱动设计”的宣传中,会说“面向过程”如何糟糕,“贫血模型”的假面向对象如何不好,或者说以前的方法是如何只关心“技术”不关心“业务”,似乎“领域驱动设计”之前就是一片空白。
Eric Evans可以说是始作俑者,他在“Domain-Driven Design”的前言中说:
Leading software designers have recognized domain modeling and design as critical topics for at least 20 years, yet surprisingly little has been written about what needs to be done or how to do it.
领先的软件设计人员认识到领域建模和设计的关键性已经有至少20年,然而令人惊讶的是,关于需要做到什么或者如何做,一直以来几乎没人写点什么。
对Eric Evans以上言语的批评,可参见我写的文章《DDD浮夸,Eric Evans开了个坏头》(umlchina.com/url/evans1.html)以及《领域驱动设计割裂历史,哪里有详细一些的真实历史?》(umlchina.com/url/dddhistory.html)。
Eric Evans说的20年,指《领域驱动设计》出版时间2003年前面的20年,大约是1983-2002年。事实和Eric Evans所说的在这个期间“几乎没人写点什么”恰好相反,去翻翻那个年代的各种面向对象方法学书籍,“领域驱动”味道比今天还要浓。
这是令人感到讽刺的。既然以“领域驱动设计”为名,按道理应该是领域逻辑越复杂的系统越需要“领域驱动设计”,但领域驱动设计“大行其道”的地方却是面向大众的互联网公司,鼓吹者所举例子的领域逻辑也非常简单,从内容上看,鼓吹者也不像是掌握了面向对象建模方法。参见《是不是互联网更适合用DDD》(umlchina.com/url/internetddd.html)。
究其原因,就是讲述 “X→aX,偷梁换柱”手法时说过的:大家热烈讨论 “领域驱动设计”,心照不宣地假装所有人对“传统”的面向对象分析设计已经熟悉到都不屑一谈了——一块掩盖自己无知的遮羞布。
1.5.4.5 封闭引用
伪创新圈子在“创新”时,不会系统化地检索文献,而是按照自己的接触面或爱好来引用文献。他们优先把引用停留在“圈子”内,例如Robert C. Martin Series、Martin Fowler Series,对“圈子”外的贡献所知甚少或视而不见。
这样,就形成了一个互吹互捧的封闭圈子。张三造(山寨或染色)了一个新词,他自己不吹,由李四、王五、赵六来帮着吹,李四造了一个新词,他自己不吹,由张三、王五、赵六来帮着吹……更离谱的是,有的人写文章,所引用的文献,作者全是自己公司的同事。
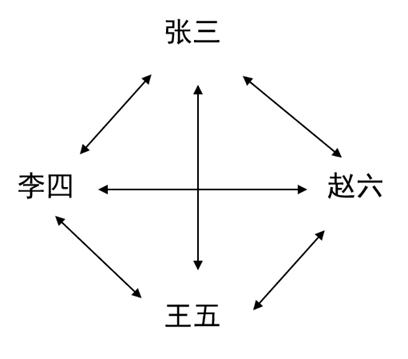
图1-40 封闭圈子引用
Eric Evans的《领域驱动设计》,参考文献共25篇,图1-41是前17篇。

图1-41 摘自《领域驱动设计》清华大学出版社2005中译本
[1][2] 的作者Alexander不是软件人士,[3][7][10]的作者不算在“敏捷”圈子里。除此之外,全在“敏捷”圈子里(对的,Larman也是)。
★还留了3本不在圈子里的,已经算不错的了。现在圈子里的文章,恨不得100%封闭引用。感兴趣的读者用“架构”这样一个中性的词搜索,看看热门文章里面的内容和参考文献,封闭到了什么地步。
就拿被多次引用的Martin Fowler来说,Fowler没有赶上1980-1990年代那一段面向对象分析设计方法学兴起的时期(所以没有Fowler方法学),他的第一本书“Analysis Patterns”出版的时候已经是1996年,当时Fowler32岁。Fowler在书中也称自己为“后来者”。
“Analysis Patterns”中使用的是James Odell的方法学,模式可以看作原创的。Fowler后来写的书涉猎甚广,但原创度不如“Analysis Patterns”。
引用Martin Fowler的书是可以的,但不应该停留在Martin Fowler,否则就会产生前面所说的“(20年)一直以来几乎没人写点什么”的错觉。
例如,David C. Hay有一本和“Analysis Patterns”类似的“Data Model Patterns”,在“Analysis Patterns”中也有引用,可惜不在圈子中,很少有人提。
★下面这段花絮属于写到此处时的随想,将来会删掉。
★我的遭遇和David C. Hay类似。最近一年我不是在翻译“Analysis Patterns”嘛,《分析模式》漫谈写了60多篇文章(umlchina.com/url/aptalk.html),把书上所有的模型图全部改编成了UML,并把一部分重要的模式用代码实现了。这些都是之前的译本没有做到的。你猜怎么着,这一年来,DDD圈子没有人提起过,当作不存在。
★啥?DDD圈子凭什么要提《分析模式》?问题是,上一个中译本(2020中译本),DDD圈子可是大力宣传的,已经把它纳入领域驱动设计的领地了!
★在此也一并回答有同学提过的问题:《分析模式》漫谈,为啥有时要顺带评点领域驱动设计?因为“Analysis Patterns”原书没有提到“领域驱动设计”(这个词还没出来呢),2004中译本中也没有提到“领域驱动设计”,而2020中译本中则出现了“领域驱动设计”。
1.5.4.6 用口号代替方法
以下做事情的方式:有口号有方法、有口号无方法、无口号无方法,哪一个方式最坏?
可能有的人会认为无口号无方法最坏,其实不然。无口号无方法地呆在原地,可能会慢慢衰落,但不是最坏的。
历史上各种最坏的事情往往和“有口号无方法”有关——最坏的事是“有口号无方法”的“好人”做的。
“坏人”知道自己做的是坏事,会暗自收敛,事后会内疚,甚至做一些善事来弥补以求心安。比如,强盗打家劫舍抢了一千万,可能会拿出五十万来“济贫”,剩下九百五十万自己爽。这样,他心里就觉得自己是“侠盗”。
而“好人”认为自己是做好事,既然做好事,那出手就不要有顾虑了,做得越绝越好,所以可能会做得很极端。如果有口号无方法,大悲剧就发生了。
软件开发行业如果不警惕“有口号无方法”,可能会有以下危险:
(1)无意识的自我陶醉
很多产品经理会喊口号:我们只做最重要的需求,尽快把系统推向市场;
很多架构师会喊口号:设计要分离变和不变,这样可以减少变更的成本。
问题来了:
怎样知道哪个需求最重要?拍脑袋?
怎样知道哪些变哪些不变?抓阄?
可惜,有的人喊完口号之后,就满足了,陶醉了,觉得自己太牛×了,这么厉害的道理都懂,其他都是小意思了,到矣尽矣,蔑以加矣。他们并不认真思考怎样才能真正做到,连自己以前采用的一些虽然不是很好但还过得去的做法也懒得做了。
200*年,有一位网络名人,北京大学计算机科学博士说过一段话:
关于软件工程,我并不看重。我更相信人对代码的控制能力,正常人对于正常复杂程度的代码,控制几十万行代码应该是可以的;如果软件总体上有很好的结构设计,模块之间有稳定、合理的接口,那么,仅仅依靠人的脑袋,加上良好的编程习惯,即使面对大型的软件,应该也能控制。
问题来了:
“很好的结构设计,模块之间有稳定、合理的接口”、“良好的编程习惯”怎么来的?从天上掉下来的?这不正是软件工程研究的学问吗?上面这段话就是正确无用的废话。
如果不具备基本的经济学常识,不要说计算机科学博士,就算是院士,针对软件开发发表的言论都有可能是错得离谱的。
(2)有意识的胡作非为
这是最坏的情况。
因为口号是正确的,在口号的遮掩下胡作非为就很难阻挡,而且后果也不好追责。
前文描述过的场景:嫌画类图、状态机图不“敏捷”,一上手就直接编码,然后对着编码环境反复折腾;嫌UML不“敏捷”,自己手画或用绘图工具做自编草图,花的时间比用建模工具点几下还多……其实就是反智和掩盖无能的遮羞布,但没关系,“毕竟初衷是好的”。
★有一次我评点客户开发人员提交的工件,顺便批评了他们团队中一些打着“敏捷”旗号的粗陋做法。然后,一位女生天真无邪地问我,“老师,希望敏捷一些难道不好吗?”——我还能怎么说!“敏捷”这个词本身就是褒义的。它占领了正能量高地,让人无法反对。
★此处提到“女生”,没有歧视的意思,只是如果让我想个例子,我印象最深的就是这个。
在陈述事实的基础上,才可能有合理的讨论。像下表中这些,都是陈述事实:
| 面向对象 | 面向过程 |
| 命令式 | 函数式 |
| 深度优先 | 广度优先 |
| 状态图 | 活动图 |
| 民营企业 | 国有企业 |
图1-42 陈述事实的用词
面向过程好还是面向对象好?或者什么情况下面向过程会好一点,什么情况下面向对象会好一点?民营企业好还是国有企业好?或者什么行业适合民营企业,什么行业适合国有企业?或者什么发展阶段优先发展哪一个?
这些都可以讨论。
“敏捷”就不一样了,它直接上了一个褒义词。这个褒义词的对面是什么?迟缓?笨拙?你还怎么讨论呢?它已经立于不败之地了。
可能有的人会说,“敏捷”的对面是“瀑布”啊!前面的段落“割裂历史”已说过,“瀑布”对面其实是“迭代”、“增量”这样阐述具体做法的词——这也是本来已经在用的词,但“敏捷”把它们抹掉,直接上一个褒义词来降维打击。
在“敏捷”口号之前,那些后来被称为“敏捷”的过程,叫做“轻量(Lightweight)”过程。
“轻量”虽然也是一个形容词,但还是比较中性的。就像我们说一个公司是小公司,从员工数量、注册资金或营业额上看,事实确实如此,但如果说公司是“敏捷公司”,味道就大不相同。也许是因为“轻量”的煽动性不够,圈子选择了“敏捷(agile)”。
★近年圈子使用的褒义词还有“精益”、“现代”、“活”等(欢迎读者补充更多资料)。
1.6. 伪创新的乐土:“互联网”

图1-43 林正英电影海报
有个巫医发明了一种治疗方法。他坦言,我这个方法对付癌症可能不太行,但对付感冒很管用噢!你不信,找个感冒患者来!
巫医让感冒患者躺在一张绘有八卦图案的方桌上,然后绕患者八八六十四圈,每一圈的唱词都不一样(看到没,他也是有一套方法的!),然后对患者说,回去该吃吃该喝喝,五天之内就好了!
果然,患者好了。巫医四处宣传他的革命性划时代感冒疗法,迅速收获大批粉丝。
真相是:对于感冒来说,喝白水、喝肥宅快乐水+姜、喝盐水、吃草药、吃合成药、巫医施法,无论哪一个,感冒患者要走的流程都差不多,因为它是靠自身免疫力来对抗病毒。
★严格来说,这些也不是完全没有“好处”。可以借机放松身材管理,痛饮肥宅快乐水;吃合成药可以缓解一些症状;巫医施法能带来心理安慰。
1.6.1 “互联网系统”
我们这里说的“互联网系统”,更严谨的说法是面向大众、用户量巨大的网络信息系统。
目前(2025年)很多信息系统所使用的技术栈、部署方式以及访问方式和“互联网系统”相似,例如某家制药企业内部使用的制药行业生产管理系统,但并非面向大众,用户量也不大,像这样的系统,不是我们这里说的“互联网系统”。
互联网浪潮到来之前,信息系统的竞争焦点是功能。
★我1997年硕士毕业,先到高校当了一年老师,然后才去软件公司做程序员。第一个参与开发的系统是酒店管理系统(实现:Visual Basic+SQL Server)。这样的系统用的人不多,服务器一台,每个部门放上一台客户端电脑就差不多了,但功能很多,入住、退房、收银、客房,餐饮、娱乐、财务、电话计费、各种报表,覆盖了酒店内部流程的方方面面。
互联网的兴起带来了这样的系统:系统功能很简单,开发系统时需要思考的核心域逻辑很少,但是通过互联网,系统可以让非常多的人使用。
早期的典型例子是1996年出现的hotmail(被微软收购后演变成今天的outlook.com),这是一个基于web的电子邮件系统,推出一年多时间就有1200万的用户。同一时期类似的系统还有ICQ(即时通信)、GeoCities(个人主页)等。
★注意,邮件系统也是有丰富逻辑的,包括标准化的协议(SMTP、POP3、IMAP、MIME……)、地址解析和路由、加密等等,但绝大多数这些逻辑已经被前人探索得很清楚,甚至有实际的可用组件提供,并不需要web电子邮件系统的开发人员从头思考和建模。
今天,典型的例子是微信、抖音、微博等,当然,它们用户量往往以亿甚至十亿计。
用户量的增加和功能的简单化是互相促成的。随着系统用户数量的增加,系统的功能往往会取各类用户想要的功能的“公约数”,想要添加点什么必须非常谨慎,不会为了小部分人的特别要求就为系统增加新功能。
例如,有微商希望微信提供“美化营销话术”的功能,能根据对方的工作性质、性格等美化要发过去的信息,让其更容易打动对方……张小龙肯定理都不理。当然,其他开发组织可以为这些特定人群开发相应的微信小程序,那是另外的系统了,用户量也不是微信的用户量。
反过来,功能简单的系统,如果用户量不大,就没有盈利的可能,也就养不起开发团队,不会出现后文所描述的伪创新危害。
你觉得现在的记事本用得不爽,于是自己写一个自己用,你爱怎么开发怎么开发。只不过,你以此为素材分享你的“敏捷开发经验”的时候,造成的影响很小。
如果你的记事本不小心碰到了哪个痛点,用户量大增,但模仿者也很快出现,这时就进入到比拼背景、人脉、资金的环节。拼不过,“先驱”成了“先烈”。拼得过,成了赢家,这时再分享你的“敏捷开发经验”,影响力就不一样了。
这样的“互联网系统”,如果说有什么“技术难度”,肯定不是功能的实现,而是用户量起来之后,如何保持性能不下降。起大作用的还是金钱——有没有足够的资金不断购买基础设施来支撑到打败竞争对手。
这个“技术难度”也不是竞争的关键因素。微信之前有米聊,后来者还有易信、来往……。微信的对手们之所以在竞争中落败,是因为它们做不出微信的功能吗?是因为它们的技术无法应对用户量的增长吗?
1.6.2 “敏捷”的乐土
很多开发人员进入了开发或维护这样的“互联网系统”的公司,我们就叫 “互联网公司”吧。这样的公司就成了很多打着“敏捷”旗号的“方法”(实际上也没啥方法,主打一个“干就是了”)的乐土。
经常有人和我说:潘老师,敏捷这一套做工厂管理系统之类的可能不太行,但不得不承认,做互联网很管用噢!
我还看到,互联网公司的开发人员霸占了各个技术大会的讲台,他们四处布道“互联网开发思维”、“敏捷开发思维”。经常有这样的场景:一个互联网公司的开发人员在台上讲他们怎么开发自家系统的,台下的听众一听,这TM不就是瞎搞,不就是以前常说的作坊式开发嘛!当然了,演讲者自称“敏捷试错”、“敏捷开发”。
可是,不服不行,人家公司上市了,而且现在开始盈利了!台下有做电力、税务之类软件的同学就开始反思了,人家“瞎搞(敏捷试错)”,这么成功,我们又什么规范,什么建模,一年辛辛苦苦就赚个辛苦钱,不行,要向他们学习,回去马上引进互联网思维和敏捷开发思维,把我们的研发流程互联网化、敏捷化!
有的公司真的这样搞了,结果搞出烂摊子来,后来又来找我,潘老师,我们还是得把建模这些东西重新捡起来。
首先,可以用“幸存者偏差”来解释。很多“瞎搞(敏捷试错)”的公司死掉了,没有“正在其中工作”的开发人员,更不用说在技术大会的讲台上布道了。
其次,即使对幸存者而言,它们在竞争中能够打败其他对手存活下来,并不是自家系统本身的能力比竞争对手系统的能力高出一截,而是其他因素导致的。布道者为了拔高自己的形象,有意无意把自己所在公司的成功和“瞎搞(敏捷试错)”联系起来(这一点,前面在谈到“伪创新”买家时已经说过),引导听众掉入“错误归因”的逻辑陷阱。
“瞎搞”是事实,“成功”也是事实,但不能把并存当作因果,得出结论“因为瞎搞,所以成功”、“只要瞎搞,就能成功”甚至“只有瞎搞,才能成功”。很可能该公司的背景、人脉以及烧的钱才是成功的原因,至于公司里的开发团队采用什么开发方法,是站着、坐着、躺着还是倒立着开发,无关紧要,但是布道者巧妙地把并存转成了因果。
有一天,张三喝酒喝得半醉去买彩票,结果一开奖,中奖两个亿。大家请张三上台介绍经验,张三如实描述“我那天喝酒喝得半醉去买彩票,就中大奖了”,于是台下听讲的彩民纷纷去喝个半醉然后买彩票,以为这样就能中大奖。可惜,没中奖的李四王五等人没资格上台布道(幸存者偏差),喝醉是事实,中大奖也是事实,但不能因此推导出因为喝醉所以中大奖(错误归因)。
张三之所以能中大奖,背后肯定有原因,只不过这个原因很复杂,属于“上帝算法”,人类目前还算不清楚(否则用来算一下明天双色球多好),所以常会归因到能观察或理解的事情上。“喝醉酒”是一个用于加深读者印象的极端例子,更常见的归因是张三“祖上积德”。
利物浦和曼城激烈搏杀,最终利物浦2:0曼城。为什么利物浦能赢球,原因是球员、技术、战术的问题,哪个环节做对了或者搞砸了,球队主教练斯洛特或瓜迪奥拉心里是清楚的,但这对某些球迷来说太复杂了。他们会从一些自己能理解的地方找原因,比如球员球衣的颜色,教练穿什么内裤,球员在更衣室里是站着开会还是坐着开会,球员是不是结对洗澡等等。
★类似互联网布道者这样的错误归因,在互联网之前的软件开发行业就已经有了。上个世纪,很多企业的信息化改进受到很大阻力,反对的声音说:我们企业那么多年一直这么干,不也一直在赚钱嘛。这就是把并存当成因果。
★“没有做信息化改进”和“赚钱”是并存的,但之所以赚钱,是因为背后的某些背景。了解改革开放初期历史的同学可能知道“双轨制”、“官倒”这些词,以前某些官员的亲戚办公司赚钱实在太容易了。如果这个权力带来的好处能一直很爽地吃下去,搞不搞信息化改进是无所谓的。之所以要改进,就是因为这个“红利”不能继续吃下去了。
可能有人会说“就算功能很简单,但要应付这么多用户,背后技术门槛也不低啊,要是没有很多技术大拿支撑,网站早就崩了”。
我们再拿醉汉张三中奖的故事来说。喝醉酒和中大奖是并存,但不是因果关系,这是前面所说的。我们再看另一个问题,张三中奖两个亿,必须纳4000万所得税,否则大奖就没收而且还要坐牢。假设有个有钱人李四,他看到张三先中两亿大奖然后纳税4000万,于是李四干脆就预交了4000万给税务局,然后再去买彩票。李四中奖两个亿的概率会大大提高吗?
纳税4000万是中奖两个亿的结果,不是中奖的原因。互联网公司的很多开发人员属于“纳税型”,是公司的成功带来了他,他却误以为自己带来了公司的成功——“没有我们,双11的时候网站就崩了”。
★如果觉得“纳税”不好听,可以说“保镖”。张三中奖两个亿,然后请保镖,保镖说“没有我,你能有这两个亿吗”。
1.6.3 “领域驱动设计”的乐土
随着互联网(以及移动互联网)的不断扩展,工作和生活的各个流程中和大众接口的环节,大多数都已经改成了信息系统接口,例如购物流程中的下单环节、就医流程中的挂号环节、政务流程中的申请环节……。
开发人员开始不得不思考一些领域逻辑,但前面已经“敏捷”习惯了,建模能力普遍退步或者从来就没有建立,也不愿意咬紧牙关认真学习。于是,迎合这些开发人员口味的伪创新翩翩登场。
其中的代表就是“领域驱动设计”。在[1.5.4.1 偷梁换柱]中已有描述:把比较难、懒得学的建模方法归为“传统方法学”,把“领域驱动设计”吹捧为“新一代方法学”,这些开发人员在谈论时把焦点放在“新一代”(或革命性、划时代)上,心照不宣地假装自己对“传统方法学”已经熟悉到不屑一谈了。
所以就出现了这样的诡异现象:既然以“领域驱动设计”为名,按道理应该是领域逻辑越复杂的系统越需要“领域驱动设计”,但领域驱动设计“大行其道”的地方却是“互联网系统”,布道者很大比例来自“互联网公司”。
常见的领域驱动设计文章是这样的:
先念经“DDD是解决业务系统复杂性的方法学”,然后再把几个DDD造词吹一通,这一套复制粘贴的常规操作做下来,就已经占据不少篇幅了。
接下来开始举例了,但例子只有1-2个领域类,涉及的领域逻辑也极其简单(也许在DDD圈子看来已经够复杂),然后就开始大谈实体、值对象、仓储、上下文、聚合根、六边形架构……还会给出代码,代码一层又一层,颇为壮观。一点点领域逻辑,包出这么多饺子,难怪伪创新买家(开发人员)会大喊“受用”!
也有银行、保险、医疗等行业组织中的开发人员分享“领域驱动设计”的心得,你以为这回应该有真东西了吧?
仍然没有。他们象征性地简单罗列一些领域概念,意思是“你看,我这里有领域喔”,然后还是前面那个套路,最后,声称领域驱动设计给他们带来了多少多少的好处。
领域逻辑哪里是简单罗列一下就能表达,不使用类图、状态机图这样的建模技能(或等价的形式)是很难刻画出来的——但没关系,他们会骗自己以及骗别人,只要我开始编码,领域逻辑会自然而然从天上掉下来。退一步说,大不了就不断“敏捷试错”嘛!
伪创新圈子如果能咬咬牙去学习,掌握了真正有用的建模知识,大概率也就不会再去相信之前那些伪创新话术了,甚至会为曾经相信那些东西而羞愧。但是很遗憾,伪创新圈子很少有人会这样做,他们更热衷于组圈子,搞人情世故。
行业组织中的伪创新买家(开发人员)更值得警惕,特别是他们把手伸向汽车、航空、航天、国防等领域时。
更多详细探讨,参见我写的《DDD领域驱动设计批评》文集。

















 9970
9970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









