




 本文深入探讨Transformer模型,包括其结构、注意力机制和在自然语言处理及计算机视觉领域的应用。通过学习李宏毅的课程,理解Self-Attention如何实现并行训练和捕获词间关系。同时,Transformer在CV中结合CNN进行目标检测和分割任务。
本文深入探讨Transformer模型,包括其结构、注意力机制和在自然语言处理及计算机视觉领域的应用。通过学习李宏毅的课程,理解Self-Attention如何实现并行训练和捕获词间关系。同时,Transformer在CV中结合CNN进行目标检测和分割任务。
参考资料:
1 模型原理详解:https://zhuanlan.zhihu.com/p/44121378
2 attention机制:https://zhuanlan.zhihu.com/p/43493999
3 详解transformer子结构的计算方式:https://zhuanlan.zhihu.com/p/59629215
4 算法流程:https://baijiahao.baidu.com/s?id=1651219987457222196&wfr=spider&for=pc
5 李宏毅课程PPT:https://blog.youkuaiyun.com/frank_ljiang/article/details/104382282
课程:https://www.bilibili.com/video/BV1J441137V6?from=search&seid=16273963478069518947
6 transformer在计算机视觉的应用:http://www.360doc.com/content/21/0116/16/32196507_957302113.shtml
前景:https://www.thepaper.cn/newsDetail_forward_10820015
文章:《Attention is all you need》
学习过程:
先学ref5李宏毅的课程,了解基础
通过ref2简单了解attention和rcnn的机制
ref1对模型(网络结构)进行了简介
ref3对子结构有详细的描述,偏学术
ref4详细地说明了算法流程,易懂
transformer模型结构:
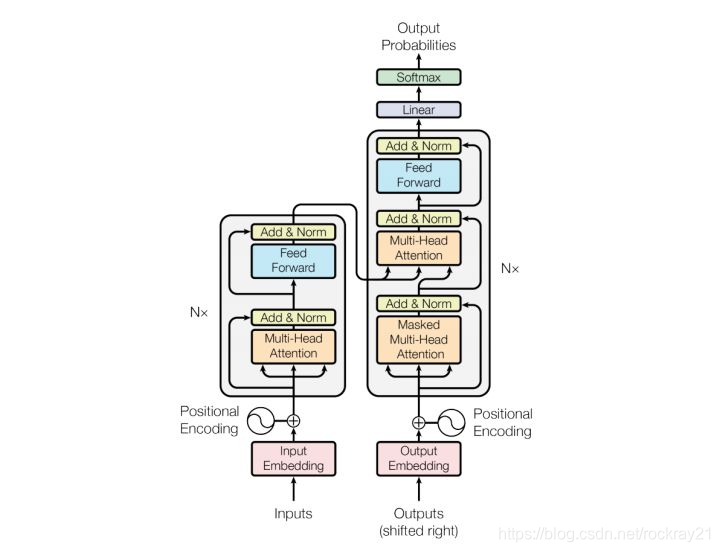
attention机制
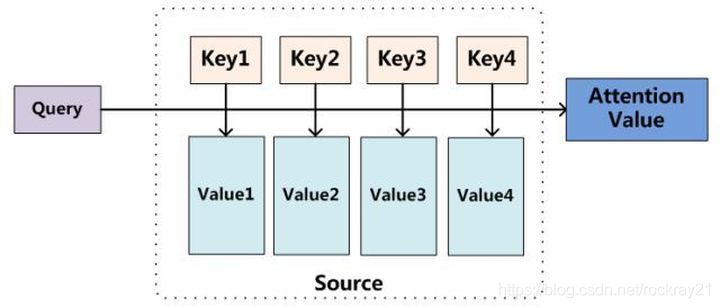
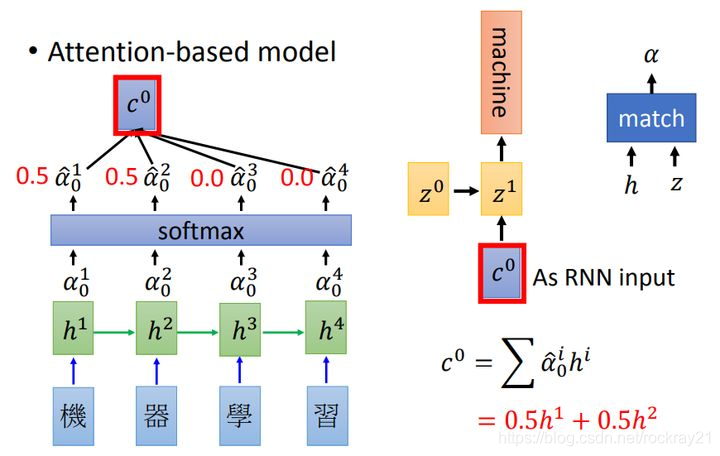
其中h 是编码器每个step的输出,z是解码器每个step的输出,计算步骤是这样的:
先对输入进行编码,得到h
开始解码了,先用固定的start token也就是 z最为Q,去和每个h (同时作为K和V)去计算attention,得到加权的c
用c作为解码的RNN输入(同时还有上一步的z),得到 z并预测出第一个词是machine
再继续预测的话,就是用 z作为Q去求attention:
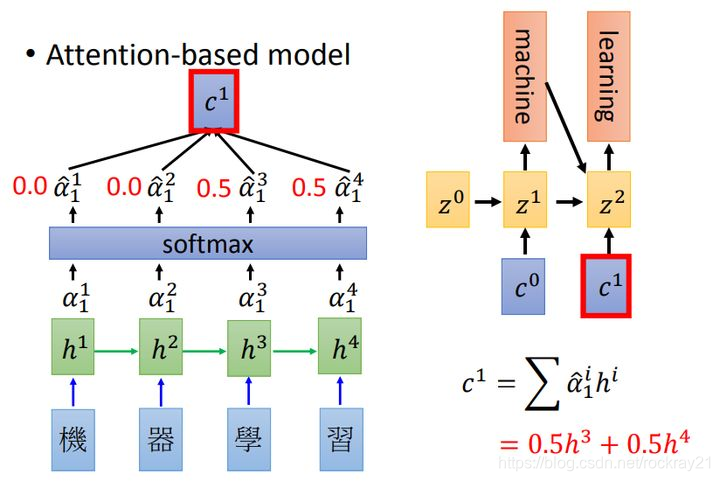
ref3
selfattention计算过程
多头注意力机制
使用位置编码表示序列顺序
残差连接
解码器
linear层和softmax层
transformer总结
Transformer 与 RNN 不同,可以比较好地并行训练。
Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
transformer在计算机视觉中是靠CNN提取特征,它完成目标检测和分割的任务
李宏毅课程
RNN无法被平行化,而CNN的视野有限
self_attention 通过q,k,v习得相互关系、语序等,得到预测结果
self_attention主要解决平行化和加速的问题
不同head关注点不同
注意区分layer norm和batch norm的区别
目前存在的疑问:
qkb怎算出来?
前景:
CNN用于提取特征,transformer完成推理并生成预测
目前主要是将用于NLP的transformer结构套在视觉任务上


















 9373
9373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









