




本文对采用RGBD Fusion类的传统三维人体重建的三个算法流程,即self 3D Self-Portraits[1],DoubleFusion[2],PIFuFusion[3],做个简单的记录,不涉及细节,感兴趣的读者可自行阅读原始论文。
一.简介
场景均为相机固定人体转动,也就是算法的输入为多视角下的人体RGBD图,核心在于配准算法。
二.具体流程
1.3D Self-Portraits[1]
![图1.算法[1]整体流程](https://i-blog.csdnimg.cn/img_convert/3aed67830e69e17bac184739e4859801.png)
简介
无任何先验,将重建问题看作是一个纯纯的配准问题,也可适用于一般物体。
-
扫描
多视角无需多说,而在单视角情况下,论文利用了kinect v1的马达采集了多张RGBD图,为的是覆盖更多的人体区域,因此也就多了下面单视角融合一步。
-
单视角融合与分割
1)对单个视角下的多帧点云进行刚性ICP配准,然后进行泊松重建得到单视角下的完整人体点云。
2)首先根据大致的bbox分割出来大致的人体点云,然后删掉与原始帧不重叠的部分点云(消除泊松重建带来的杂点),接着根据法线在滤除一些平面区域的点,最后移除多个视角下不动的(因为背景在人体自转时是不动的)和小的不连接离群的点云。
-
逐帧刚性配准
刚性ICP配准:两次逐帧的ICP配准,第一次是以第一帧为基准,第二次是最后一帧为基准。
-
全局非刚性配准
1)寻找对应点对:首先进行相邻两帧之间的NICP配准(Embeding Graph[5]那套方法,下面介绍的两篇论文也是这种方法),然后查找最近点对并记录下来。
2)全局非刚性NICP配准,和相邻帧NICP的能量项一样,只不过这里是对所有帧同时进行优化,一次优化得到所有帧的非刚性变化(全局只要是可以消除累积误差,最明显的效果就是第一帧和最后一帧可以闭合上)。
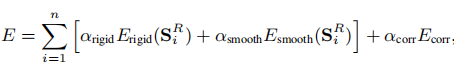
-
点云重建
对配准后的点云进行泊松重建。另外由于单相机视角的限制,像人头顶部的孔洞仅靠泊松重建修补的效果比较差,因此又利用visual hull[4]计算出了一部分点云,与原始点云合并在一起后进行泊松重建。
-
纹理贴图
首先利用SIRFS算法[6]对原始RGB图进行处理用于减少光照变化的影响,然后利用泊松融合用于产生很好的纹理过渡。
2.DoubleFusion[2]
![图2.算法[2]整体流程](https://i-blog.csdnimg.cn/img_convert/407419e256ddabcedf2e9193599cafed.png)
简介
利用smpl模板作为先验,smpl模板作为内层人体辅助外层人体的配准。
-
初始化
1)利用首帧深度图初始化TSDF,同样的利用首帧深度图和smpl模型进行配准初始化内层smpl形状和姿态参数;
2)初始化NICP配准的节点图,含内外两层,其中内层节点为由smpl定义,外层节点为距离内层节点一定距离的外层模型上采样得到。
-
联合运动跟踪
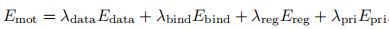
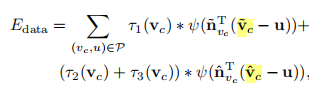
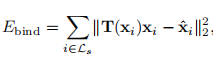
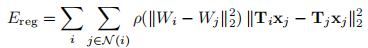
1)优化的参数为每个节点的旋转和平移,用于将双层模型配准当当前深度帧上(这里之前应该还有个ICP配准,然后是以上公式所示的NICP配准);
2)式3)数据项包含内层模型与深度图(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3854
3854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









