



 NFM(Neural Factorization Machine)模型是一种融合了FM(Factorization Machine)与DNN(Deep Neural Network)优势的深度学习模型,旨在增强特征交互的表达能力。NFM在FM的基础上引入特征交叉池化层,不仅保留了FM的二阶特征交互,还利用DNN学习高阶特征交互和非线性。通过Bi-Interaction Layer,NFM能更好地捕捉数据的复杂结构。代码实现中,NFM模型包括输入层、线性部分、DNN部分以及最终的预测层,其中关键区别在于NFM特有的特征交叉池化层。与FM相比,NFM的Bi-Interaction层通过元素积而非内积计算,增强了模型的表达能力,当权重为常数时,NFM退化为FM。
NFM(Neural Factorization Machine)模型是一种融合了FM(Factorization Machine)与DNN(Deep Neural Network)优势的深度学习模型,旨在增强特征交互的表达能力。NFM在FM的基础上引入特征交叉池化层,不仅保留了FM的二阶特征交互,还利用DNN学习高阶特征交互和非线性。通过Bi-Interaction Layer,NFM能更好地捕捉数据的复杂结构。代码实现中,NFM模型包括输入层、线性部分、DNN部分以及最终的预测层,其中关键区别在于NFM特有的特征交叉池化层。与FM相比,NFM的Bi-Interaction层通过元素积而非内积计算,增强了模型的表达能力,当权重为常数时,NFM退化为FM。
深度模型笔记04 NFM模型与应用
具体NFM模型学习资料来源请参考datawhale
1.NFM模型
一句话来描述NFM,NFM模型是在FM的模型基础上引进特征交叉池化层,使FM和DNN完美衔接的模型,既具有FM的低阶特征交互能力,又具有DNN学习高阶特征交互和非线性的能力。
模型大致结构如下图所示:
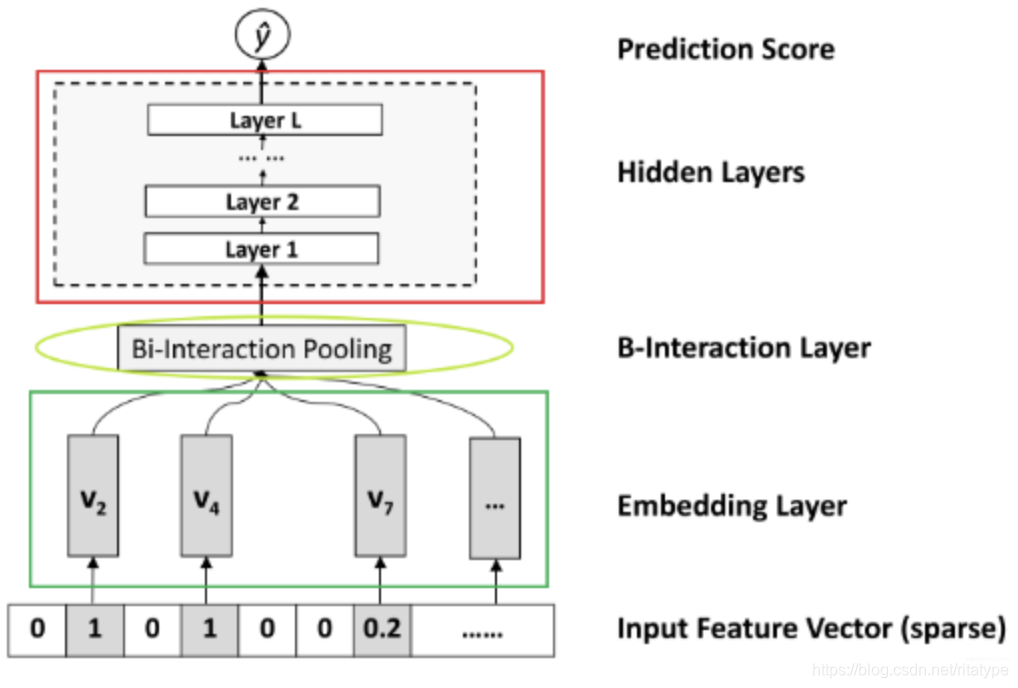
各层作用如下:
- input和embedding层:输入层,稀疏输入转稠密向量
- Bi-Interaction Layer:NFM模型最关键的一层,组合二阶交叉信息,给DNN进行高阶交叉的学习
- Hidden Layer:堆积隐藏层以期来学习高阶组合特征
- Prediction Layer:用来预测,回归问题。
2.代码实现
def NFM(linear_feature_columns, dnn_feature_columns):
"""
搭建NFM模型,上面已经把所有组块都写好了,这里拼起来就好
:param linear_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是linear数据的特征封装版
:param dnn_feature_columns: A list. 里面的每个元素是namedtuple(元组的一种扩展类型,同时支持序号和属性名访问组件)类型,表示的是DNN数据的特征封装版
"""
# 构建输入层,即所有特征对应的Input()层, 这里使用字典的形式返回, 方便后续构建模型
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns+dnn_feature_columns)
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# 线性部分的计算 w1x1 + w2x2 + ..wnxn + b部分,dense特征和sparse两部分的计算结果组成,具体看上面细节
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_feature_columns)
# DNN部分的计算
# 首先,在这里构建DNN部分的embedding层,之所以写在这里,是为了灵活的迁移到其他网络上,这里用字典的形式返回
# embedding层用于构建FM交叉部分以及DNN的输入部分
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
# 过特征交叉池化层
pooling_output = get_bi_interaction_pooling_output(sparse_input_dict, dnn_feature_columns, embedding_layers)
# 加个BatchNormalization
pooling_output = BatchNormalization()(pooling_output)
# dnn部分的计算
dnn_logits = get_dnn_logits(pooling_output)
# 线性部分和dnn部分的结果相加,最后再过个sigmoid
output_logits = Add()([linear_logits, dnn_logits])
output_layers = Activation("sigmoid")(output_logits)
model = Model(inputs=input_layers, outputs=output_layers)
return model
3. NFM与FM对比
3.1 异同:
FM:以线性的方式学习二阶特征交互,对于捕获现实数据非线性和复杂的内在结构表达力不够
NFM:增加Bi-Interaction层操作来对二阶组合特征进行建模。使得low level的输入表达的信息更加的丰富,极大的提高了后面隐藏层学习高阶非线性组合特征的能力。Bi-Interaction层实际是一个pooling层操作,计算的方式是将嵌入向量对应位置相乘,即元素积。而FM计算的是内积。
NFM特例:当元素权重为常数向量[1,1,...1]时,NFM退化为FM,说明除特征交叉池化层的计算外,NFM和FM基本相同
3.2 代码上进行对比
#不同点
#NFM模型中加入:特征交叉池化层(Bi-Interaction层)
pooling_output =
get_bi_interaction_pooling_output(sparse_input_dict, dnn_feature_columns, embedding_layers)
pooling_output = BatchNormalization()(pooling_output)

















 8378
8378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









