




一、前言
FM已经公认是稀疏数据预测中最有效的嵌入方法之一,真实世界中的数据往往是非线性且内部结构复杂,而FM虽然能够比较好的处理稀疏数据, 也能学习稀疏数据间的二阶交互, 但说白了,这个还是个线性模型, 且交互仅仅限于二阶交互, 所以作者认为,FM在处理真实数据的时候,表达能力并不是太好。
NFM这里同样是有着组合的味道,但是人家不是那么简单的拼接式组合了,而是设计了一种结构,NFM的核心创新点是Bi-Interaction池化部分来代替其他模型使用的拼接。把FM和DNN拼接了起来。这样一来同样是利用了FM和DNN的优势。
二、NFM模型介绍
改进的思路就是用一个表达能力更强的函数来替代原FM中二阶隐向量内积的部分。
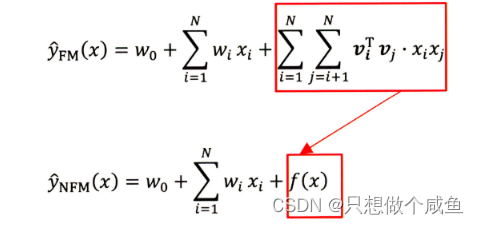
而这个表达能力更强的函数呢, 我们很容易就可以想到神经网络来充当,因为神经网络理论上可以拟合任何复杂能力的函数, 所以作者真的就把这个f (x)换成了一个神经网络,当然不是一个简单的DNN, 而是依然底层考虑了交叉,然后高层使用的DNN网络, 这个也就是我们最终的NFM网络了:
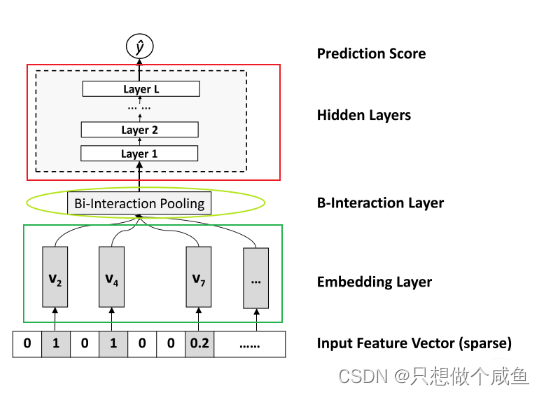
1、Input和Embedding层
输入层的特征, 文章指定了稀疏离散特征居多, 这种特征我们也知道一般是先one-hot, 然后会通过embedding,处理成稠密低维的。 这个地方真正实现的时候,往往先LabelEncoder一下(而不是one-hot encoder), 这样就直接能够得到那些取值非0的特征对应的embedding向量了, 毕竟LabelEncoder一下就相当于为某个特征的所有取值建立了一个字典, 我们知道在取某个值的embedding向量的时候, 直接去字典的索引值就好了(one-hot Encoder * 嵌入矩阵其实也是取得为1的那个值,就是索引值其实)
2、Bi-Interaction Pooling layer
在Embedding层和神经网络之间加入了特征交叉池化层算是本paper最大的创新点了,也正是因为这个东西,才实现了FM与DNN的无缝连接, 组成了一个大的网络,且能够正常的反向传播。假设是所有特征embedding的集合,
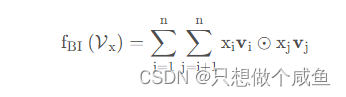
⊙表示两个向量的元素积操作,即两个向量对应维度相乘得到的元素积向量(可不是点乘呀),要注意这个地方不是两个隐向量的内积,而是元素积,这一个交叉完了之后k个维度不求和,最后会得到一个向量,
参考FM,可以将上式转化为:
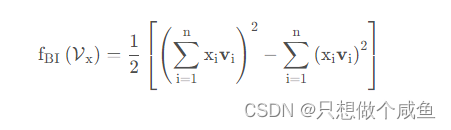
在特征交叉层上,作者使用了dropout技术:为了防止过拟合
还用了BatchNormalization技术:避免embedding向量的更新将输入层的分布更改为隐藏层或输出层。
3、隐藏层
还是全连接的神经网络
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









