




 本文介绍了概率链式法则在语言模型中的应用,包括不同阶数的Markov假设及其扩展,如Unigram与Bigram等,并探讨了语言模型评估指标Perplexity。此外,还讨论了如何通过Laplace平滑方法解决概率为零的问题。
本文介绍了概率链式法则在语言模型中的应用,包括不同阶数的Markov假设及其扩展,如Unigram与Bigram等,并探讨了语言模型评估指标Perplexity。此外,还讨论了如何通过Laplace平滑方法解决概率为零的问题。
Chain Rule
p(A,B,C,D) = p(A)*p(B|A)*p(C|AB)*p(D|ABC)
Markov Assumption
Unigram (一阶)

Bigram (二阶)
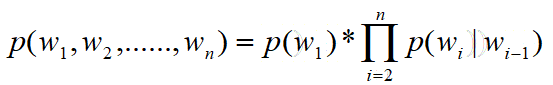
可扩展至N阶
语言模型的评价
- 理想情况下
- 假设有两个语言模型A,B
- 选定特定的任务,比如拼写纠错
- 把两个模型A,B都应用在此任务中
- 比较准确率,判断A,B表现
模型评价:Perplexity
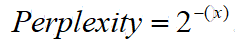
x:average log likelihood
Laplace Smoothing
为了避免单个概率为0,使整个句子概率为0
原MLE模型(Markov LM):

改进后的Add-one Smoothing LM
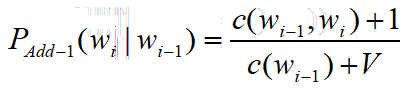
V: 词库的大小(去重)
Add-K Smoothing
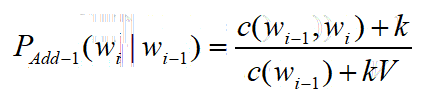


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









