





一种用于工业表面缺陷检测的高效轻量级卷积神经网络
摘要:由于表面缺陷检测对于保证产品的实用性、完整性和安全性具有重要意义,已成为控制工业产品质量的关键问题,引起了研究人员的兴趣。然而,由于存储空间和计算资源有限,在嵌入式设备上部署深度卷积神经网络 (DCNN) 非常困难。在本文中,通过深度学习从图像处理的角度设计了一种高效的轻量级卷积神经网络(CNN)模型用于工业产品的表面缺陷检测。通过将逆残差架构与坐标注意(CA)机制相结合,构建坐标注意移动(CAM)骨干网络进行特征提取。然后,为了解决小物体检测问题,通过将CA引入跨层信息流来开发多尺度策略,以提高特征提取的质量并增强多尺度特征的表示能力。此后,结合多尺度特征设计了一种新颖的双向加权特征金字塔网络(BWFPN),以在不增加太多计算负担的情况下提高模型检测精度。通过在开源数据集上的对比实验结果,评估了所开发的轻量级 CNN 的有效性,检测精度与最先进 (SOTA) 模型相当,参数和计算量更少。
关键词:轻量级卷积神经网络·表面缺陷检测·注意力机制·特征金字塔网络
1介绍
表面缺陷对工业产品质量有显着不良影响。因此,表面缺陷检测近年来受到越来越多的关注,并在工业应用中的质量控制方面取得了积极进展(Chen et al. 2021)。然而,表面缺陷的检测容易受到光照、背景和材料等多种环境因素的影响。这些因素大大增加了表面缺陷检测的难度。 此外,自然环境中的缺陷较为复杂,如银纹、夹杂物、斑块、坑面、轧鳞、划痕等。众所周知,小物体检测是物体检测中最具挑战性的任务之一(Chen et al. 2022;Song et al. 2022)。而且工业产品往往存在细微的缺陷,难以检测(Yang et al. 2020)。无法准确识别细微缺陷,将直接影响智能制造行业的生产管控质量。传统上,制造业中的大多数表面缺陷检测任务仍然是手动执行的。不幸的是,人工缺陷检查具有主观不稳定和耗时的缺点。与人工检测相比,缺陷自动检测技术具有明显的优势。不仅能适应不适宜的环境,而且能长时间高精度、高效率地工作。研究缺陷检测技术可以降低生产成本,提高生产效率和产品质量,为制造业的智能化转型打下坚实的基础(Chen et al. 2021)。随着近年来图像处理技术的快速发展,可以预见,检测中涉及的人工工作将被自动化所取代,这不仅可以降低人工成本,还可以提高效率(Yan et al. 2020)。
传统图像处理技术的主要思想是通过精心设计的手工特征来描述表面缺陷。常用的手工制作特征包括定向梯度直方图 (HOG)(Song 等人 2013)、灰度共生矩阵(GLCM)(Huang 和 Lee 2009)、局部二元模式(LBP)(Liu 等人 2016a) ), 和其他统计特征。然而,这些图像处理方法不能直接应用于现实中,因为缺陷识别通常需要复杂的阈值设置并且对光照条件和背景等环境因素敏感。
传统的机器学习视觉模型依赖于通过人工分析和提取缺陷特征得到的特定视觉检测任务,然后利用基于规则的经验或基于学习的分类器进行决策。支持向量机(SVM)和决策树都使用这种方法(Ghorai et al. 2013),其中系统性能很大程度上取决于特定特征类型的准确表示。然而,现代制造技术需要更强大的产品线,这限制了传统机器学习模型的使用。 对于复杂的表面缺陷特征,传统的机器学习模型需要较长的开发周期才能适应不同的任务。
近年来,基于深度学习的图像处理方法得到了广泛的研究,可以自动从图像中提取特征,并在分类、分割和定位等图像相关任务中取得良好的性能。 随着深度学习的快速发展和卷积神经网络 (CNNs) 在特征提取方面的巨大成功 (Wang et al. 2019),DCNNs 的目标检测算法具有实时性、鲁棒性和泛化性等优点,显示出很好的 自动检测表面缺陷的潜力(Cha 等人 2018 年;Zheng 等人 2021b)。然而,现有的算法模型在表面缺陷检测方面仍有很大的改进空间。 例如,经典的两阶段算法Faster R-CNN(Ren et al. 2017)存在参数冗余、鲁棒性差、效率低的问题。 经典的单阶段算法 SSD (Liu et al. 2016b) 和 YOLOv3 (Redmon and Farhadi 2018) 已经大大提高了效率,但其鲁棒性和准确性仍然不尽如人意。SOTA目标检测算法YOLOX(Zheng et al. 2021a)和EffcientDet(Tan et al. 2020)兼顾了效率和准确性,但其对普适性的强调导致在特定检测任务中鲁棒性不足。这里值得强调的是,经典的物体检测器存在大量漏检,检测精度较低,而SOTA物体检测模型更注重普适性,大部分模型参数和计算量过高。传统的 CNN 通常需要大量的参数和浮点运算 (FLOP) 才能达到令人满意的精度,更重要的是,由于存储空间和计算资源有限,在嵌入式设备上部署 DCNN 非常困难。对于缺陷检测模型,更少的参数和更少的计算量更为重要。 通常,构建具有更复杂层的更复杂的网络可以使网络从输入数据中学习到好的特征。也就是说,具有更多参数和计算总数的模型在准确性方面将表现更好。 因此,本文致力于开发一种具有较少模型Params和FLOPs,同时具有良好性能的缺陷检测模型。目前,一些轻量级 CNN 已成功应用于各个方面(Hui et al. 2018;Zhao et al. 2020;Shen et al. 2022),但在工业缺陷检测方面的研究较少。在这项研究中,为缺陷检测领域开发了一种用于检测表面缺陷的高效轻量级 CNN。 它提供了一种新颖的轻量级 CNN 模型,可以实时定位和显示视频流中的表面缺陷。 这项研究的主要贡献总结如下,
- 一种基于多尺度检测和注意机制相结合的轻量级 CNN 模型,专为实时、复杂和真实的工业场景而设计。选择了两个开源且具有挑战性的数据集来验证所提出方法的有效性,结果证明该框架在准确性方面优于其他经典模型,并在此类任务中获得与 SOTA 模型相当的性能,模型参数和计算量更少 高架。
- 提出了一种基于逆残差块 (IRB) 和 CA 机制相结合的 CAM 骨干网络,用于初步特征提取。 CAM骨干网络能够通过残差连接和深度可分离卷积技术以少量参数和计算开销有效地提取特征。
- 针对小物体(缺陷)检测问题提出了多尺度策略,可以极大地提高所提出模型的准确性和鲁棒性。特征量的提取直接影响到缺陷检测系统的分辨能力比。由于较低层的特征图具有更详细的信息和更高的分辨率,而更深层的输出具有更多的语义和更小的分辨率,跨层特征融合可以利用图像丰富的语义特征和空间特征,提供更多的信息并更好地做出结果。 针对小物体检测问题的不同尺度的预测。
- 然后设计了一种新颖的 BWFPN 来有效地表示和处理多尺度特征,可以融合更多特征但不会增加太多成本。设计的网络以一种特殊的方式将深度可分离卷积、跨尺度连接和加权特征融合方法结合在一起,使其在有效减少参数冗余和提高特征融合效率方面发挥着强大的作用。 此外,将CA应用于BWPFN的跨层信息流,可以增强感兴趣对象的表示,可以以较小的计算开销更好地利用多尺度特征信息。
本文的其余部分安排如下。 在第二节中,本文介绍了表面缺陷检测的相关工作。 接下来,在第 3 节中详细设计了所提出的用于表面缺陷检测的网络架构。然后,在第 4 节中介绍了实验分析,并在第 5 节中总结了结论。
2 相关工作
本节研究了基于图像处理的表面缺陷检测的相关技术,包括传统的检测方法和基于深度学习的检测方法,并进行了详细讨论。
2.1传统检测方法
传统的检测方法主要包括基于手工特征的图像处理和浅层机器学习技术。使用手工制作的特征来提取、描述和检测缺陷的传统图像处理技术可分为四类:传统统计方法、光谱方法、基于模型的方法和机器学习方法(Luo et al. 2020)。具体而言,统计方法通过评估像素强度的规则和周期性分布来实现缺陷检测,主要包括局部二进制模式 (LBP) 算子 (Ojala et al. 1996)、基于阈值的方法 (Amir et al. 2022)、gray- 水平统计方法 (Hasan et al. 2016) 和基于边缘的检测方法 (Wu and Li 2021)。尽管早期研究人员对传统统计方法进行了广泛研究,但许多方法无法为光照变化或轻微强度转变的缺陷提供可靠和正确的结果。光谱方法在变换域中找到比像素域中的直接处理方法对噪声和强度变化更不敏感的更好的解决方案。谱方法主要有傅立叶变换(Aiger and Talbot 2010)、伽博滤波器(Xie et al. 2010)、小波变换(Ghorai et al. 2013)和优化的有限脉冲响应(FIR)滤波器(Kumar and Pang 2002)。基于光谱的检测方法通过寻找一个特殊的变换域将缺陷对象从背景中分离出来,然而,这些方法缺乏局部信息并且在表示杂项缺陷方面存在瓶颈。基于模型的方法通过参数学习增强的结构特殊模型将图像块的原始纹理分布投影到低维分布上,可以更好地检测各种缺陷。一些经典的表面缺陷检测模型包括马尔可夫随机场模型(Cross and Jain 1983)、威布尔模型(Wu et al. 2018)和主动轮廓模型(Wang et al. 2017)。作为基于模型的方法的一个强大分支,机器学习已被广泛提出用于表面缺陷检测。 这些方法将缺陷检测任务视为二元(缺陷或非缺陷)分类问题,例如支持向量机 (SVM)(Li et al. 2022)、决策树(Alex et al. 2022)和浅层神经网络 网络(Tan 等人,2015 年)。
2.2 基于深度学习的检测方法
CNN因其出色的特征提取能力和对二维图像的直接处理能力,近年来被广泛应用于表面缺陷检测(Luo et al. 2021; Li et al. 2021; Xie et al. 2021)。Cha 等人提出了一种无需手动设计缺陷特征即可检测混凝土和钢材表面裂缝的深度卷积神经网络 (DCNN) 方法(Cha 等人,2017 年)。该框架能够在一定程度上抵御广泛变化的现实环境所带来的干扰。 然后,该团队还设计了一种基于更快的基于区域的 CNN(Faster R-CNN)的自动视觉检测方法,以确保可以准实时地同时检测多种类型的缺陷(Cha et al. 2018)。Lin等人通过将R-CNN的主干网络VGG16修改为ResNet50生成特征图来检测热轧带钢表面缺陷,实验结果表明,基于深度学习的检测方法比传统方法更有效,能够检测出热轧带钢表面缺陷。 更准确地检测带材的表面缺陷(Lin et al. 2019)。更重要的是,Song 等人。 将 DCNN 与骨架提取相结合,实现了金属表面微弱划痕的精确检测,实验结果表明其对背景噪声具有鲁棒性(Song et al. 2019)。Li等人以完全卷积的思想改进了YOLO网络,然后使用YOLO变体检测肥钢表面缺陷,网络准确率达到99%(Li et al. 2018)。然而,上述方法大多只考虑分类精度而忽略了缺陷位置的提取和定位。 更重要的是,大多数 DCNN 通常需要大量的参数和 FLOP 才能达到令人满意的检测精度。 由于存储空间和计算资源有限,在嵌入式设备上部署 DCNN 非常困难。目前,已有研究人员在应用研究中对轻量级 CNN 进行了研究。 例如,Hui 等人提出了一种用于光流估计的轻量级 CNN,其模型大小仅为用于光流估计的 SOTA 模型的三十分之一。结果表明,所提出的轻量级模型的性能与大型 SOTA 模型相当(Hui 等人,2018 年)。Zhao 等人提出了一种轻量级情绪识别 (LER) 模型来处理自然条件下的延迟问题。 与 VGG13 相比,LER 模型实现了更高的精度,并将参数数量减少了 97 倍(Zhao et al. 2020)。Pan 等人提出了一种名为 MCNA 的轻量级网络用于气体识别,它结合了多尺度深度卷积网络和自我注意机制。与以前的深度学习网络相比,MCNA 需要的参数和计算成本要少得多,但它仍能达到同样高的气体识别精度 (Pan et al. 2022)。然而,在缺陷检测领域对实用的轻量级CNN模型的研究仍然不足。 与目前的检测方案相比,我们的方案具有更低的计算开销但更高的效率和精度。 现在我们的方案进行了详细的设计,所采用的相关技术的相应特性将在下一节进行分析。
3 拟议的表面缺陷检测网络
小物体检测问题尤其是表面缺陷检测是现实应用中物体检测领域最具挑战性的技术问题之一。正如我们在第一节中提到的,工业表面缺陷具有复杂的特征,因此高效准确地检测表面缺陷非常困难。因此,本节开发了一种新型高效表面缺陷检测网络,包括所提出的基于 IRB 和 CA 的 CAM 骨干网络、一种结合多尺度和注意力机制的检测策略以及一种新型 BWFPN。 完整的网络架构如图 1 所示。
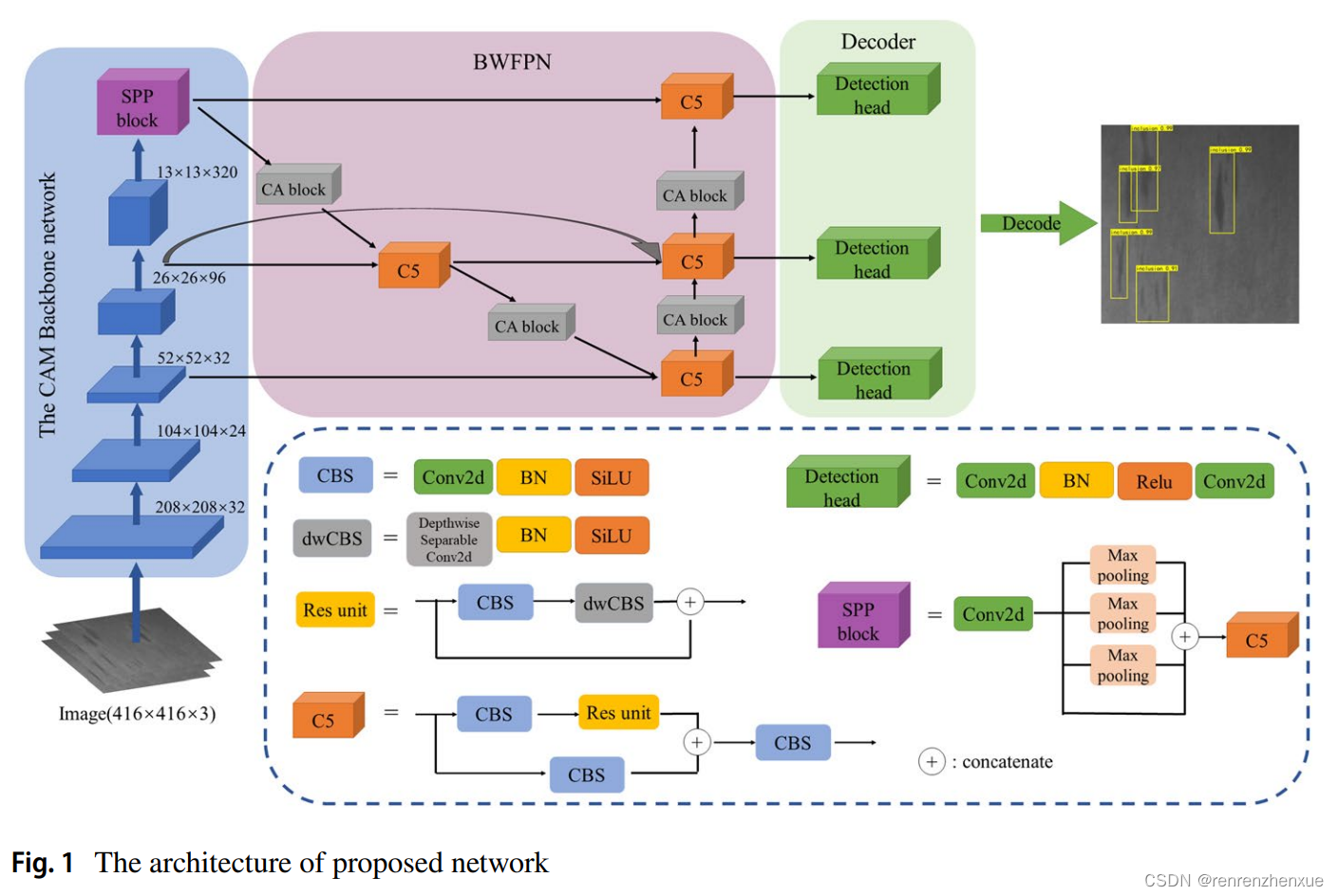
3.1 骨干网络
3.1.1 CA机制
尽管部分(第 3.3 节)建立了一种新颖的特征融合算法,但并非目标的所有特征信息都具有重要意义。研究人员基于动物视觉注意力的启发,发现图像中的大部分信息是无用的,只选择相关部分进行计算,称为注意力机制,可以使计算过程更加高效(Wang et al. 2021a ; Li 等人 2020)。注意机制的主要目标是从大量信息中选择对任务目标更关键的信息。CA 是一种轻量级的注意力机制,由 (Hou et al. 2021) 提出。 CA可以看作是一个计算单元,其目的是增强学习到的特征在网络中的表达能力。受此启发,在我们的方法中,将 CA 块引入建议的网络以增强感兴趣对象的表示。CA块首先使用两个一维全局池操作将垂直(Y)和水平(X)输入特征聚合成两个独立的方向感知特征图,然后将具有特定方向信息的两个特征图分别编码成两个注意力图, 并且每个注意力图都捕获输入特征图沿空间方向的远程依赖性。位置信息可以保存在生成的attention map中,两个attention map通过相乘的方式应用于输入的feature map,以强调attention regions的表示。其实现见图2,其中avg pool代表平均池化,Conv2d(1×1)代表卷积核大小为1的卷积运算,BN代表批量归一化,hard-swish(Hswish)( Howard et al. 2019) 和 Sigmoid 激活函数表示如下,
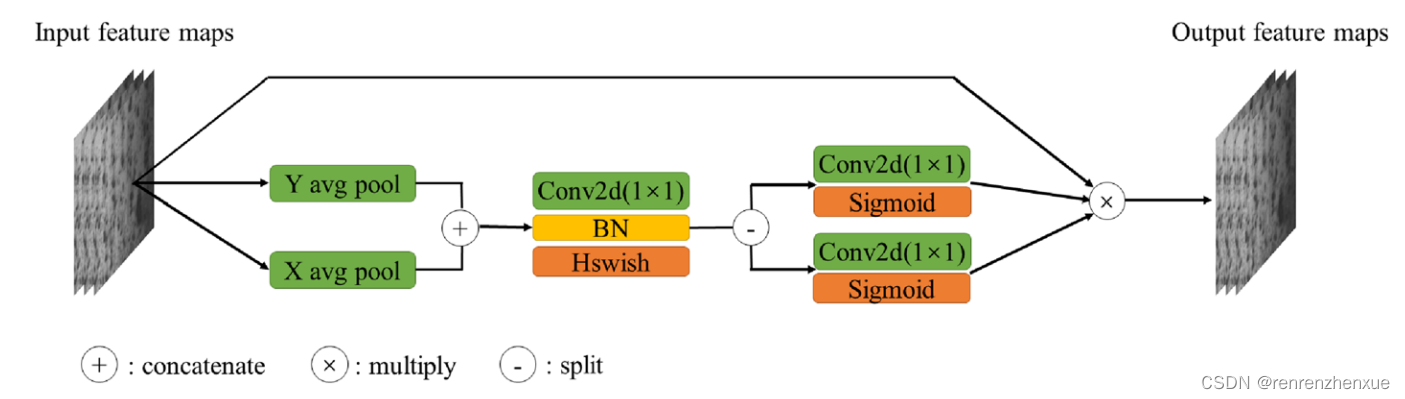
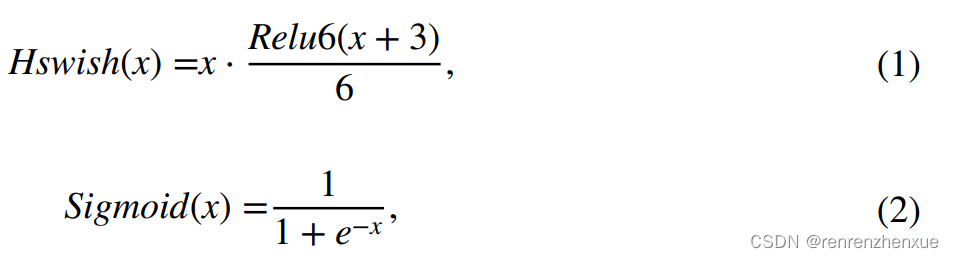
Relu6 函数将在 3.1.2 节中描述。 Sigmoid 激活函数虽然可以提高检测精度,但它具有指数运算,导致计算成本较高。 这在移动设备上更为重要。 Hswish激活函数的引入可以有效降低模型的计算开销。
3.1.2 CAM骨干网
与 DCNNs 相比,MobileNet 系列模型是优秀的轻量级主干网络,体积更小,计算量更少。 随着网络架构的优化,MobileNet网络的准确率已经超过了一些DCNN。MobileNet 系列以其高效率和良好的检测精度成为实际应用中最流行的目标检测方法 (Wang et al. 2021b)。
Depthwise separable convolutions (Howard et al. 2017) 是高效 MobileNet 架构的关键构建块。 基本思想是用两个独立的层代替卷积算子,第一层是深度卷积,第二层是点卷积。Depthwise convolution 对每个输入通道应用单个卷积滤波器,pointwise convolution 是一个 1×1 卷积,负责通过计算输入通道的线性组合来构建新特征。常规卷积采用 Pin × H × W 输入特征图,并应用卷积核 K 产生 Pout × H × W 输出特征图。它的计算成本为 Pin × K × K × Pout。 在depthwise separable convolution中,计算量等于:Pin × K × K + Pout × 1 × 1 × Pin,是depthwise和pointwise卷积的总和。 根据经验,深度可分离卷积在大多数情况下几乎与常规卷积一样有效。
逆残差架构最早是由(Sandler et al. 2018)提出的,它是通过瓶颈(expansion-convolution-compression)的思想构建的。与残差块不同,逆残差架构的设计内存效率更高,并且工作得更好。 inverse residual architecture 的思想是在扩展通道后使用卷积提取特征,然后压缩通道。
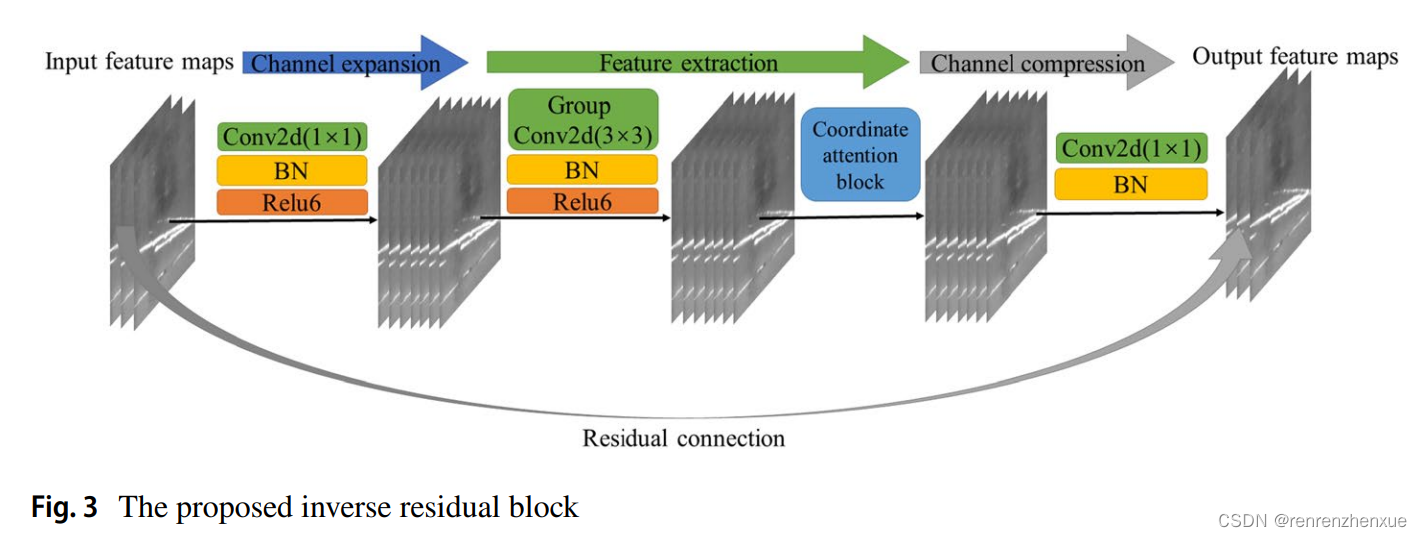
受上述启发,在本文中,我们通过在逆残差架构中结合 CA 提出了 CAM 主干网络。 具体来说,我们采用的逆残差架构首先使用 1×1 常规卷积运算来扩展通道,对生成的特征图进行批量归一化(BN)并使用 Relu6 函数激活它们。 Relu6函数可以表示如下,
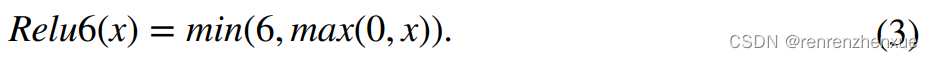
选择Relu6激活函数是因为它比Relu函数具有更低的计算复杂度,并且可以避免移动网络进行权重量化时Relu函数导致的权重范围过大的问题。
其次,我们采用组卷积(convolution-BN-activate)在扩张的通道上逐一提取特征以生成特征图。 然后,这些特征图将被输入到 CA 块中,以增强感兴趣区域的有效表示。 最后,我们使用逐点卷积(convolution-BN)来压缩通道。在图 3 中可以找到更直观的表示。CAM 骨干网络的详细配置参数可以在第 4.2.1 节中找到。
3.1.3 SPP模块
He等人首先提出了空间金字塔池化(SPP)。 (2015) 用于将特征图张量转换为固定长度的特征向量。 CNN 以滑动窗口方式获取任意大小的图像,但全连接层只能接受固定大小的输入。SPP 将特征图划分为固定数量的局部空间单元,并将每个单元内的所有元素汇集在一起,使 CNN 模型能够接收不同大小的输入图像,而无需裁剪或调整图像大小。
SSP 模块还有助于对象检测,因为它可以从同一卷积层提取具有不同感受域的多尺度特征。SPP 模块连接四个不同尺度的输入特征图,1 × 1、5 × 5、9 × 9 和 13 × 13,步幅为 1。从同一层汇集的多尺度特征图被连接起来以融合多尺度局部 用于目标检测的区域特征。因此,我们在 CAM 主干网络的最后几层之后插入 SPP 模块。 这有助于以更少的计算开销提高检测精度。
3.2 多尺度检测策略
小物体检测是物体检测中最具挑战性的任务之一(Chen et al. 2022;Song et al. 2022)。 由于工业产品的表面缺陷存在较多的细小缺陷,提高细小物体的检测精度是缺陷检测网络必须应对的问题。
CNN 的主干通过增加网络层数同时逐渐缩小网络的空间尺度来提取语义信息。 通常,骨干网络中较早的空间分辨率较高的层具有较少的语义信息和更多的细粒度信息,而较深的空间分辨率较小的层具有更多的语义信息。跨层特征融合集成了来自较早层的细粒度信息和来自较深层的更有意义的语义特征,这有助于检测小物体(Lin et al. 2017)。 同时,由于输入图像的大小对检测模型的性能有明显的影响,通过输入不同大小的图像进行训练可以在一定程度上提高检测模型对物体大小的鲁棒性。因此,多尺度策略是提高模型精度的最佳技术之一。鉴于上述基本原理,针对基于所提出的 CAM 主干网络的小物体检测问题设计了多尺度策略,可以极大地提高所提出模型的准确性和鲁棒性。较低层的特征图具有更详细的信息和更高的分辨率,而更深层的输出具有更多的语义和更小的分辨率。 跨层特征融合利用图像丰富的语义特征和空间特征。 具体来说,我们选择CAM骨干网络中输出通道分别为32、96和320的IRBs的三个输出特征层作为多尺度检测的输入。这些多尺度特征跨越更广泛的 CNN 层并提供更多信息,从而更好地预测不同尺度的对象。
3.3 The BWFPN
应用多尺度策略后,如何有效地表示和处理多尺度特征成为目标检测的主要难点之一。作为开创性工作之一,特征金字塔网络 (FPN) (Lin et al. 2017) 提出了一种自上而下的路径方式来组合多尺度特征。 遵循这一思想,路径聚合网络 (PAN) (Liu et al. 2018) 在 FPN 之上添加了一个额外的自底向上路径聚合网络,并在各种提出的特征金字塔中取得了最好的结果。双向特征金字塔网络 (BiFPN) (Tan et al. 2020) 提出高效的双向跨尺度连接和加权特征融合来优化 PAN,使其能够更有效地融合特征。多尺度特征融合旨在聚合不同骨干层的特征。 形式上,给定多尺度特征列表Pin = (Pin1 , Pin2 , … , Pinl ),其中Pinl表示第l层的输入特征,l表示输入的分辨率为1∕2l的特征层 图片。例如,如果输入分辨率为 416 × 416,则 Pin3 表示分辨率为 52 × 52(416∕23 = 52)的特征级别 3,而 Pin5 表示分辨率为 13 × 13 的特征级别 5。特征金字塔的目标是 找到一个可以有效聚合不同层的特征并输出新特征列表的变换 f,即 P⃗out = f(P⃗in)。
FPN引入自上而下的通路来融合多尺度特征,有效提高了检测精度和小物体的检测效果,如图4a所示。 但是传统的自上而下的路径本质上受到单次信息流的限制。 PAN 在 FPN 之后添加了一个额外的自底向上路径聚合网络来解决这个问题,如图 4b 所示。BiFPN以跨尺度连接的思想进一步优化了PAN:首先,去除只有一条输入边的节点,因为如果一个节点只有一条输入边,它对旨在融合不同特征的特征网络的贡献会很小。其次,当输入节点和输出节点处于同一层级时,从输入节点和输出节点增加一条额外的边,从而在不增加太多成本的情况下融合更多的特征。 第三,每条双向路径都被视为一个特征网络层,这一层可以重复多次以实现更高层次的特征融合。 图 4c 显示了 BiFPN 的具体结构。
不同输入特征对不同分辨率输出特征的贡献通常是不相等的。 BiFPN 通过为每个输入添加额外的权重让网络了解每个输入特征的重要性。 受此启发,我们采用快速归一化融合方法进行加权融合,定义如下:

其中 wi 和 wj 是可学习的权重,h 是一个小的固定值以避免数值不稳定,X 表示每个输入特征,F 表示融合的加权特征。 例如,在图 4c 中,第 4 级的两个融合特征可以描述如下,
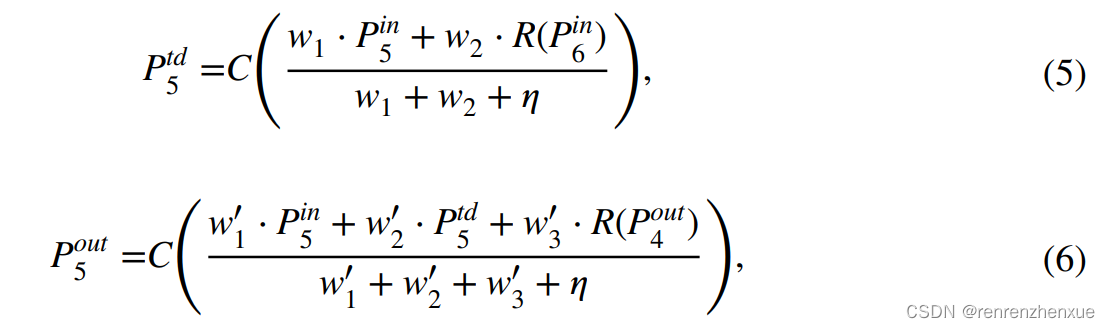
其中Ptdl是l层的中间特征,Poutl是l层的输出特征。 R通常表示上采样或下采样操作,C通常是特征处理的卷积运算。
总之,受 BiFPN 和 (Bochkovskiy et al. 2020) 的启发,然后设计了一种新颖的 BWFPN 来有效地表示和处理多尺度特征,它可以融合更多特征但不会增加太多成本。 所设计的网络将深度可分离卷积、残差连接、跨尺度连接、注意力机制和加权特征融合方法以一种特殊的方式结合在一起,使其在有效减少参数冗余和提高特征融合效率方面发挥着强大的作用。上述 BWFPN 的节点由称为 C5 的模块构建,其基本构建块是 CBS(卷积、BN 和 SiLU 激活函数)单元和残差单元。 SiLU 函数没有上界,有下界,是平滑且非单调的。虽然它的操作比 Relu 函数大,但我们选择 SiLU 函数作为激活函数以提高 BWFPN 的有效性。 SiLU函数的表示如下,

残差单元将输入特征图输入一个CBS单元和一个dwCBS(深度可分离卷积,BN和SiLU激活函数)单元,并将得到的结果与初始输入特征图拼接起来。此外,我们将 BWFPN 中每次上采样或下采样的结果输入到 CA 块中,以增强感兴趣对象的表示。 在多尺度信息流中引入注意力机制是处理多尺度特征的有效方式。 所提出的 BWFPN 的简单框架表示可以在图 5 中找到,其具体实现可以在图 1 中找到。

4 实验和结果
在本节中,进行了实验来证明所开发的表面缺陷检测方法的有效性,并给出了结果和分析。首先,选择了两种开源且具有挑战性的数据集,并引入评估指标来评估该方法的性能。其次,对改进方法进行了消融实验,验证了所提方法的有效性。最后,对比了其他9种经典模型和SOTA模型,给出了实验结果和分析。
4.1 数据集和评估指标
4.1.1 数据集准备
在实验中,我们选择了两个开源且具有挑战性的数据集:东北大学提供的NEU-DET数据集和北京大学HRI实验室提供的PCB缺陷数据集,以验证所提方法的有效性。NEU-DET 数据集包含 6 种钢材表面缺陷,包括银纹 (Cr)、夹杂物 (In)、斑块 (Pa)、麻点 (Ps)、轧痕 (Rs) 和划痕 (Sc)。 每个缺陷有 300 张 200×200 像素的图像,每张图像包含上述一种缺陷。 PCB 数据集包含 690 张图像,包含 6 种类型的缺陷,包括漏孔 (MH)、鼠标咬伤 (MB)、开路 (OC)、短路 (SH)、杂散 (SP)、杂铜 (SC)。 每个缺陷有 115 张图像,像素范围从 3034 × 2464 到 2904 × 1521。PCB数据集由于分辨率高、缺陷区域小等特点,对模型的小物体检测能力提出了很高的要求。 图像中的缺陷用称为ground truth box的矩形框标记。另外,标注文件中记录了ground truth box的坐标信息。 所有数据集都包含超过 5000 个地面实况框。图 6 显示了 NEU-DET 数据集中带有真实边界框的缺陷图像示例。

4.1.2 评价指标
有几种常用的指标来评估对象检测方法的性能。 True Positives (TP) 是指与基本事实相匹配的积极预测。假阴性 (FN) 是指与基本事实不匹配的负面预测。 假阳性 (FP) 表示与基本事实不匹配的阳性预测。 精确率(P)和召回率(R)的量化指标定义如下,

Precision一般用来评价模型的全局准确度,反映了分类器确定的预测正样本中真阳性样本的比例。召回率反映了真正的阳性样本在标记的阳性样本中所占的比例。用以上两个指标来评价模型的性能是不合适的,因为当模型A的准确率高于模型B时,其召回率很可能低于模型B。即, P 和 R 之间存在一定的矛盾。准确率-召回率曲线说明了不同阈值下准确率和召回率之间的权衡。 平均精度(AP)代表曲线下的面积,它衡量单个类的检测性能。 平均精度 (mAP) 是作为每个类别的平均精度的平均值的全局分数。
在这篇论文中,所有的 mAP 分数都是在联合交集 (IoU) 阈值大于 0.5 的情况下得出的。 IoU 可用于衡量量化预测和地面真值边界框之间的重叠水平,其定义如下,

其中|*|表示集合的基数。 如果 IoU 高于某个阈值(例如 0.5 或 0.75),则认为预测结果是正确的。
模型中总参数(Params)和FLOPs的数量反映了模型的大小和复杂度。 例如,对于一个卷积层,它的参数可以计算如下,
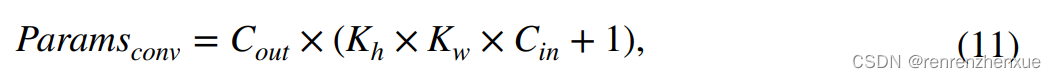
其中Kh和Kw代表卷积核的宽度和高度,Cout和Cin分别代表输入通道数和输出通道数。 卷积层的 FLOPs 可以计算如下,
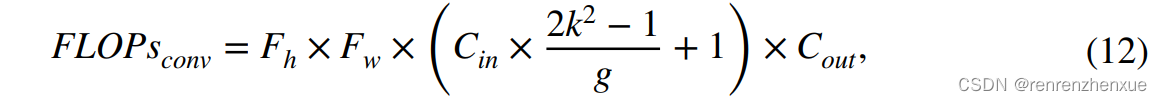
其中 Fh 和 Fw 表示输入特征图的宽度和高度,k 表示卷积核的大小,g 表示卷积的组大小。 对于物体检测模型,Params的度量单位一般是megaParams(M),FLOPs的单位一般是gigaFLOPS(G)。
需要注意的是Params和FLOPS没有对应关系。 Params 多的模型可能 FLOPs 少,Params 少的模型也可能 FLOPs 多。 比如DenseNet是一个Params比较少的模型,但是由于它的密集连接结构,在一个module内有大量的FLOPs。
4.2 建议方法的实施
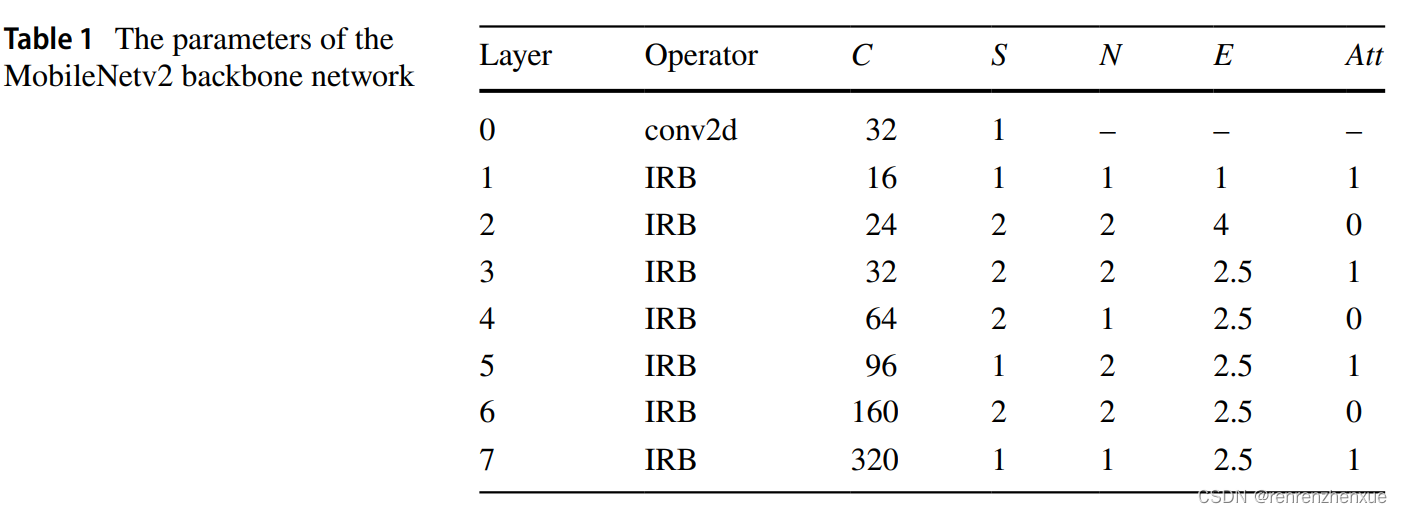
所提出的CAM骨干网络的详细参数如表1所示,其中C表示本层的输出通道数,S表示IRB中卷积运算的步幅,N是本层IRB的数量,E表示扩展 本层IRB的因子,Att表示本层是否包含CA块,0表示否,1表示是。
4.2.3 锚框设置
Anchor box是一个预定义的具有一定纵横比的bounding box,主要用于提高物体检测模型中的速度和准确率。 在我们的工作中,为了从数据集中学习正确数量和大小的锚框,我们选择在 3 个尺度上为每个检测设置 3 个锚框。人工设置的9个anchor boxes:(10, 13), (16,30) and (33, 23) 用于小对象, (30, 61), (62, 45) and (59, 119) 用于中对象和 (116, 90), (156, 198) 和 (373, 326) 用于大对象。
4.3 消融研究与分析
为了证明所提出网络的不同部分的贡献,进行了消融实验。 在本节中,相继报道了 CAM 主干网络、BWFPN 和 CA 的消融研究。
4.3.1 CAM骨干网络的消融研究
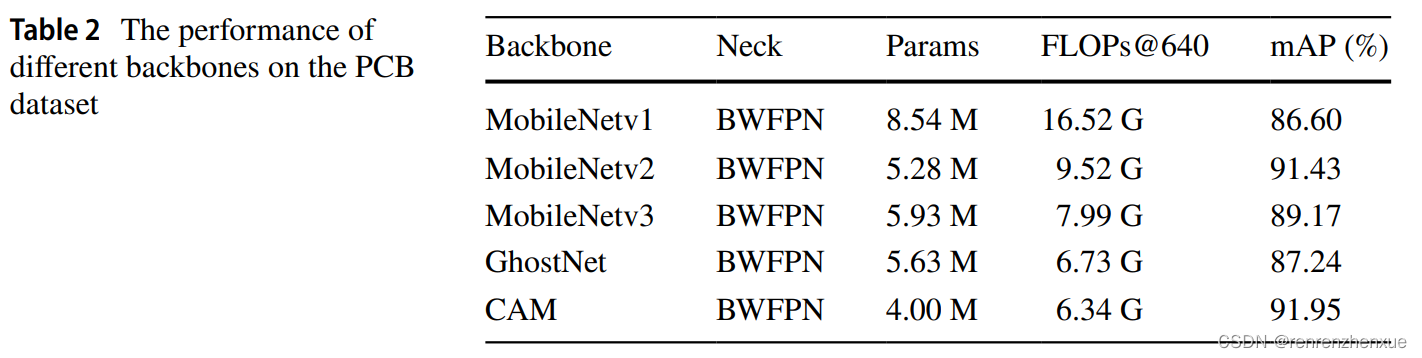
在这个实验中,我们通过在所提出的框架上替换不同的轻量级主干来评估 CAM 主干网络的有效性:MobileNetv1 (Howard et al. 2017)、MobileNetv2 (Sandler et al. 2018)、MobileNetv3 (Howard et al. 2019) 和 GhostNet (Han 等人,2020 年)。 我们选择的这些网络是用于视觉任务的优秀轻量级主干网络。 网络的 Params 和 FLOPs 是用 640 × 640 (@640) 的输入大小计算的,以反映主干的复杂性。我们在PCB数据集上进行实验,结果如表2所示。表中的Neck是指网络中用来处理从骨干网络中提取的多尺度特征的部分。如表 2 所示,CAM 主干网络在四个主干网络中的 PCB 数据集上获得最高的 mAP 分数,而 Params 和 FLOPs 低于其他四个主干网络。从表 2 可以得出结论,CAM 主干网络以较低的 Params 和 FLOPs 实现最佳性能。 CAM骨干网的优越性由此得到证明。
4.3.2 BWFPN 消融研究
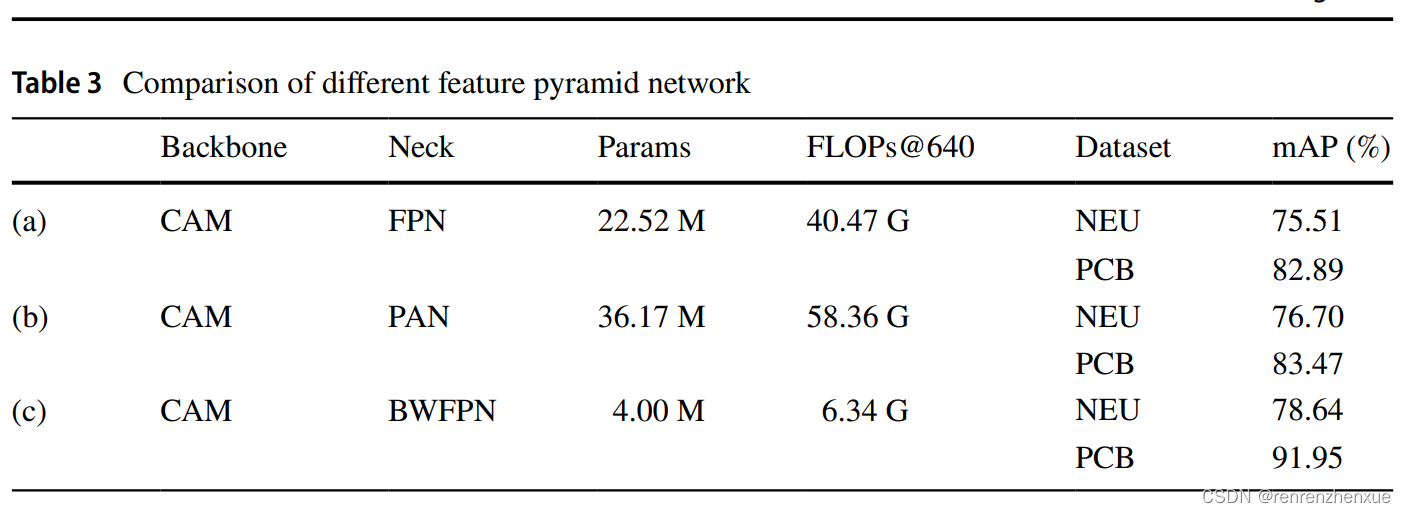
BWFPN融合并提取从主干网络获得的多尺度特征,对于提高模型性能具有重要意义,有待验证。分别使用FPN、PAN和提出的BWFPN在两个数据集上进行测试验证,结果如表3所示。其中,FPN的具体实现在(Redmon and Farhadi 2018)中有介绍,具体实现 PAN 的介绍见 (Bochkovskiy et al. 2020)。 表中的Params和FLOPs反映了整个网络的参数量和计算量。如表 3 所示,(a) 和 (b) 的 Params 远高于 (c),而 (a) 和 (b) 的 FLOPs 略高于 (c)。 (c) 在两个数据集上以最低的 Params 和 FLOPs 实现最佳性能,这证明了所提出的 BWFPN 的有效性。
4.3.3 CA的消融研究
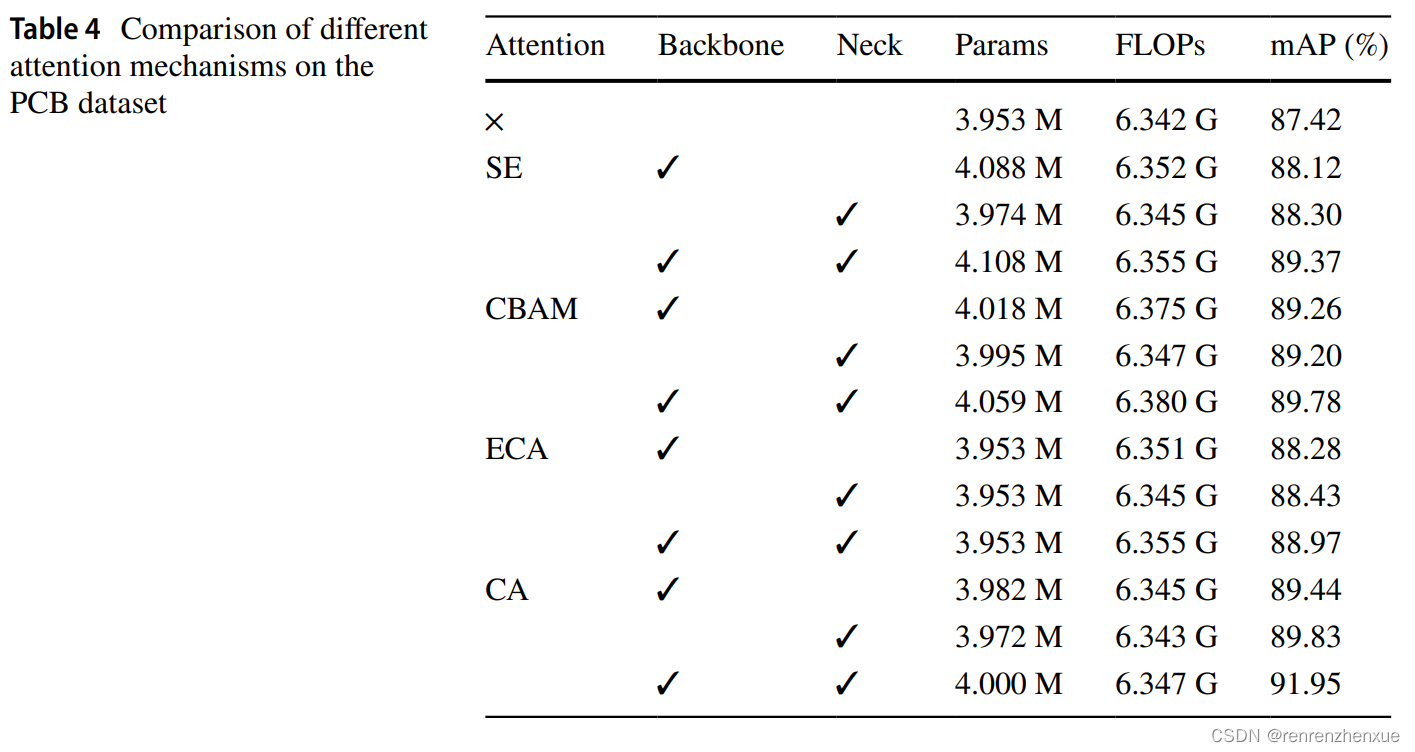
注意力机制对于提高具有较轻骨干的网络的性能具有重要意义,需要得到强调和验证。 我们专门进行了实验,以基于 PCB 数据集检验不同注意力机制对性能的影响。
我们选择了其他三种轻量级经典注意力机制,包括挤压和激发 (SE) 注意力 (Hu et al. 2020)、高效通道注意力 (ECA) (Wang et al. 2020) 和卷积块注意力模块 (CBAM) (Woo 等人,2018 年)。 分别采用四种注意力机制:(1)attention用在backbone,(2)attention用在neck,(3)attention用在backbone和neck,结果如表4所示。如表 4 所示,在所有轻量级注意模块中,CA 获得了最高的 mAP 分数并且具有最小的额外计算开销。 ECA几乎没有带来额外的模型参数,但对检测性能的提升微乎其微。 可以看出,在颈部添加注意力块通常比在脊柱上添加注意力块更有效。这是因为多尺度检测策略产生的跨层信息流中的特征信息更为重要,这证实了所提方法结合多尺度检测和注意机制的有效性。
4.4 对比实验与分析
本节在第 1 节提到的数据集上对所提出的模型和 SOTA 模型进行了一系列对比实验。 4.1.1 验证所提出模型的有效性,并给出相应的结果和分析。
4.4.1 NEU‑DET 数据集上的实验
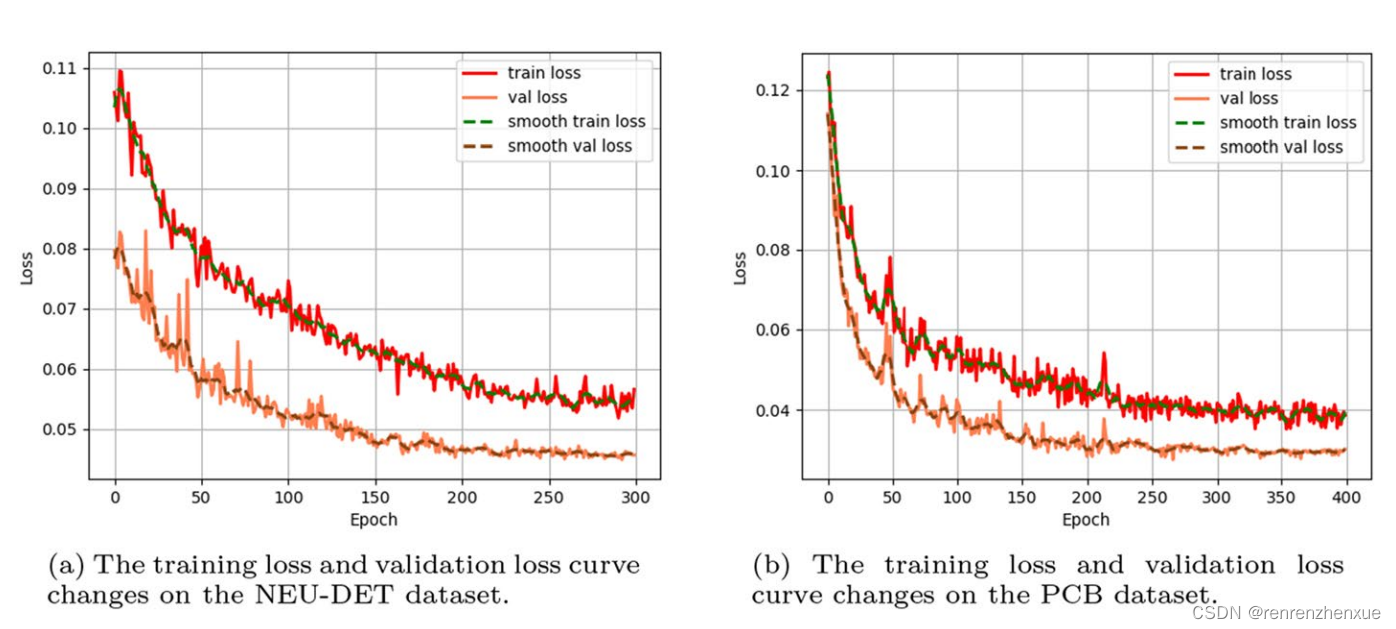
进一步进行训练和测试以验证所提出的网络模型,图 7a 和 b 分别显示了所提出的模型训练损失函数值在 NEU-DET 数据集和 PCB 数据集上的变化曲线。 可以看出,在NEU-DET数据集上,我们的模型在250个epochs收敛,在PCB数据集上,我们的模型在400个epochs收敛,损失函数值按照余弦波动递减。在PCB数据集上完成收敛需要更多的epochs,因为PCB数据集的输入分辨率更高,小物体的检测难度更大。
在验证所提模型有效性的基础上,通过对比实验进一步验证所提模型的先进性。 九个物体检测器,即 SSD(Liu 等人 2016b)、Faster R-CNN(Ren 等人 2017)、CenterNet(Duan 等人 2019)、RetinaNet(Lin 等人 2020)、YOLOv3(Redmon 和 Farhadi) 2018)、YOLOv4 (Bochkovskiy et al. 2020)、YOLOv5、YOLOX (Zheng et al. 2021a)和EffcientDet (Tan et al. 2020),对应的对比测试结果如表5所示。
在所有模型中,除EfcientDet之外的FLOPs都是以640×640的输入大小计算的,因为EfcientDet模型采用了根据相应模型在检测中使用不同输入大小的策略,其具体输入大小表示在 @ 符号表。如表 6 所示,总体而言,经典目标检测器的检测精度较低,Params 和 FLOPs 较高。 大多数 SOTA 模型具有较高的 Params 和 FLOPs,因此由于检测硬件的成本,它们不适合实际检测应用。
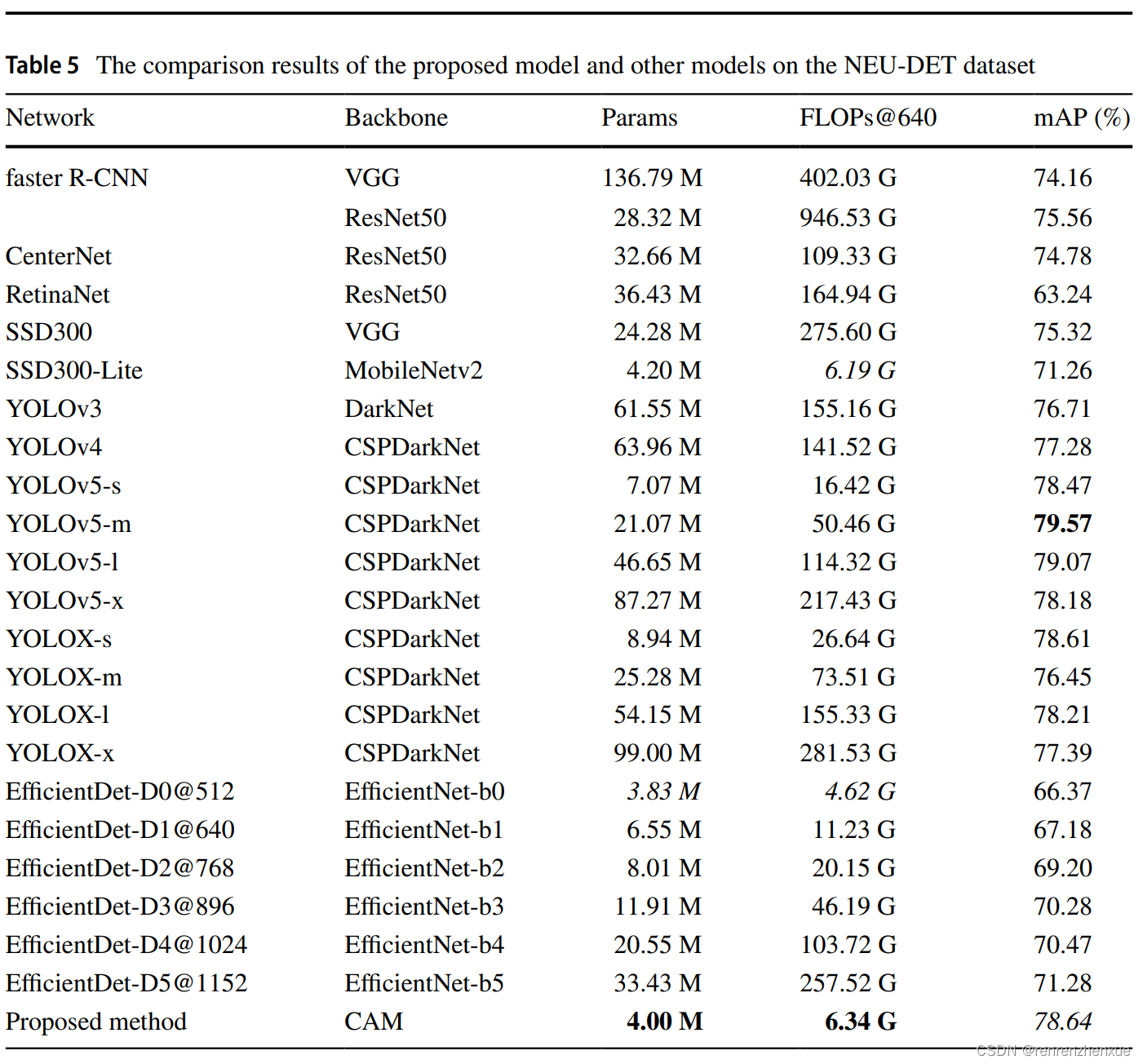
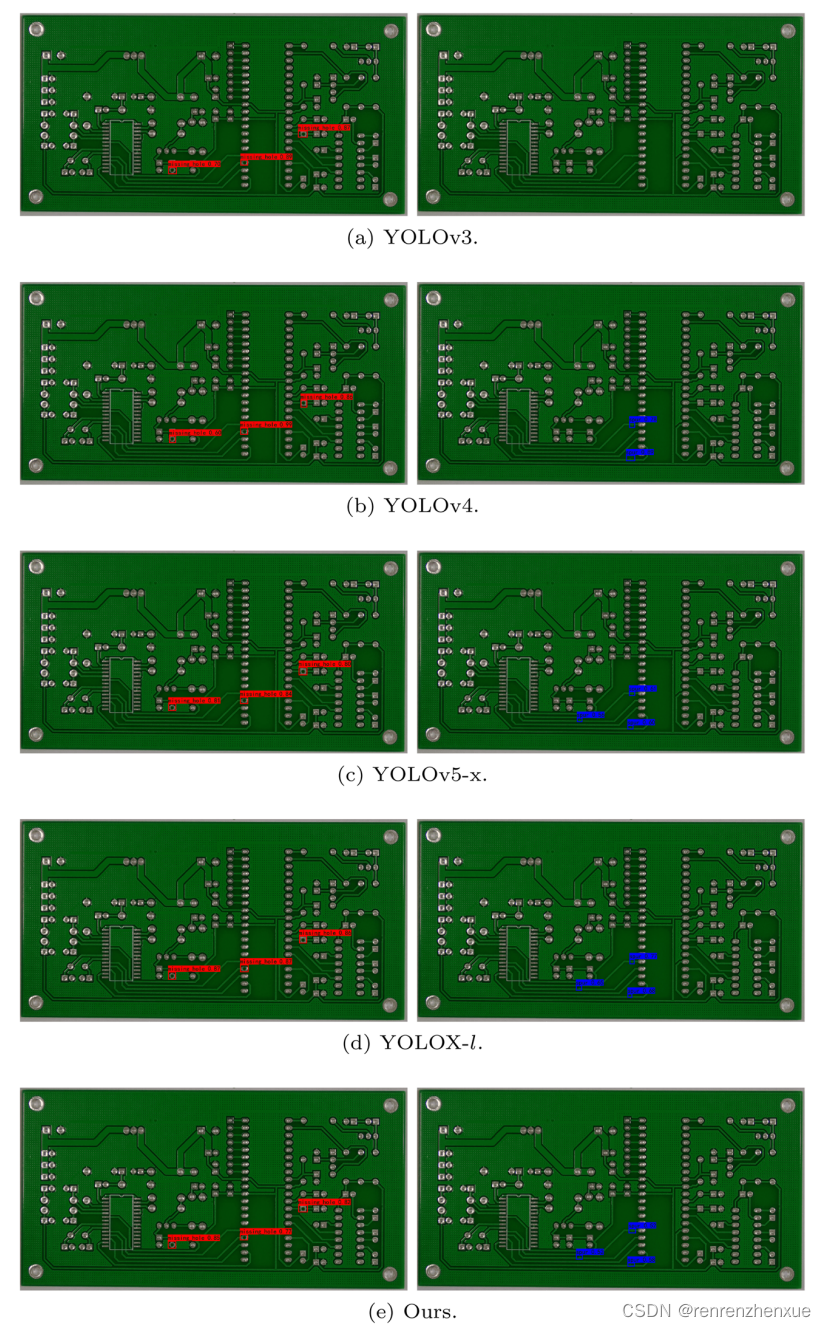
在 SOTA 模型中,只有 EffcientDet-D0 的 Params 和 FLOPs 低于所提出的模型,但其输入大小为 512,其 mAP 分数远低于所提出的模型。 由于采用了轻量级骨干网络MobileNetv2,SSD300-Lite的Params和FLOPs与proposed model相似,但是其mAP score远低于proposed model. 作为YOLOv5和YOLOX的轻量级模型,YOLOv5-s和YOLOX-s表现出SOTA模型的优越性,但由于它们强调通用性,在工业表面缺陷检测任务中的指标不如所提出的模型。 虽然 YOLOv5-m 在 NEU-DET 数据集上取得了最高的 mAP 分数,比提出的模型高 0.8%,但其 Params 是提出模型的五倍,FLOPs 是提出模型的八倍。值得注意的是,我们观察到 EffcientDet 和 RetinaNet 的划痕类 AP 分数较低,只有 30% 到 40% 左右。 据分析,这是由于两个模型都使用了focal loss。 Cr、In、Pa、Ps、Rs类图片中缺陷区域的灰度值低于背景区域,而Sc类图片中缺陷区域的灰度值高于背景区域,且 背景中有很多干扰。 提出焦点损失是为了解决正(物体)和负(背景)样本之间的不平衡问题。 在训练过程中,focal loss误判了Sc类中的正负样本,并相应地调整了自己的权重,最终导致了低AP。并且我们还随机抽取了上述9个模型的2张检测结果图片,并与本文提出的模型的2张检测结果图片进行了对比。 结果如图8所示。锚框上的标签显示了模型确定该区域中对象的类别和置信度。 如图 8 所示,所提出的模型与 SOTA 模型具有几乎相同的检测效果,但使用的参数更少,计算能力也更低。
4.4.2 PCB 数据集上的实验
由于PCB数据集的缺陷图像像素高、缺陷区域小,这些都对模型的小物体检测能力提出了更高的要求。 因此,为了进一步验证所提出模型对尺度变化的性能,使用 PCB 数据集来评估我们所提出模型的有用性。相应的实验结果如表6和图10所示。经典的物体检测模型对尺度变换的抵抗力较差,几乎无法检测出PCB数据集中的缺陷。 Faster R-CNN (ResNet)、SSD (VGG)、RetinaNet 和 CenterNet 在此数据集上的 mAP 分数分别为 5.77%、12.37%、6.24% 和 26.41%。 尽管 EffcientDet-D0 的 Params 和 FLOPs 较少,但其在 PCB 数据集上的 mAP 得分为 8.7%。
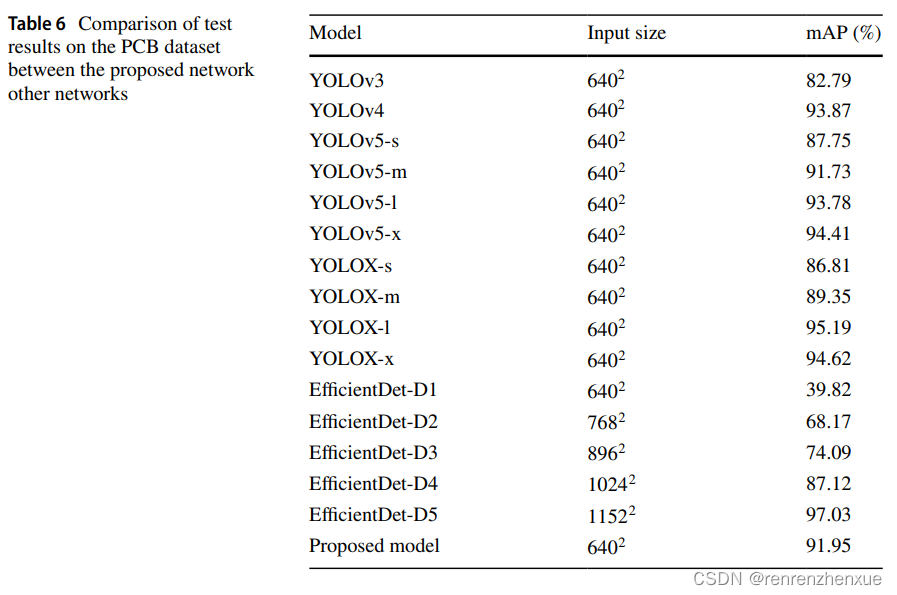

EffcientDet-D1 的 Params 和 FLOPs 略高于提出的模型,其输入图像大小为 640 × 640,但其 mAP 分数仅为 39.82%,比提出的模型低 52.13%。 这证明所提出模型的体系结构对于小缺陷检测任务更加合理和高效。 YOLOX-l 在 PCB 数据集上以 640 输入大小获得最高的 mAP 分数,比建议的模型高 3.24%,但与建议的模型相比,额外的 FLOPs 和 1353% 的成本增加了 2450%。基于多尺度输入策略和多尺度训练策略,我们尝试使用不同的较大输入尺寸对YOLOX-l、YOLOX-x、YOLOv5-l、YOLOv5-x和提出的模型进行实验和测试。 选择的输入大小分别为 640、768、896、1024 和 1152。 1152×1152是YOLOv5-x和YOLOX-x在FP16混合精度训练策略下单张RTX3090显卡上可以达到的最大输入尺寸。由于FLOPs低的优势,该模型额外选择了1536、1920和2432三种输入尺寸。图9是以模型在不同输入尺寸下的计算量为横轴,mAP分数为纵轴绘制的 . 从图中可以看出,当将输入大小增加到 2432 时,所提出的模型在 mAP 分数方面达到了与 SOTA 模型相当的性能,但在这种情况下,所提出模型的 FLOPs 远低于 SOTA 模型。图 10 显示了所提出的模型与 SOTA 模型在 2 个随机选择的检测结果图像上的比较。 对于YOLOv5、YOLOX等多模型SOTA模型,我们都是选择mAP分数最高的模型来展示。 从图中可以看出,本文提出的模型对小物体的检测能力与大型SOTA模型相当,并且本文模型在模型规模和计算复杂度方面远低于大型SOTA模型。
5 结论
针对现有卷积神经网络参数量大、计算量大、难以应用于工业表面缺陷检测的问题,该研究提出了一种用于工业产品缺陷检测的高效轻量级表面缺陷检测模型。 首先,基于逆残差结构和CA机制,设计了一个名为CA移动骨干网的轻量级骨干网用于初步特征提取。其次,针对小物体检测问题,对从骨干网络提取的特征在三个尺度上进行多尺度策略,可以极大地提高所提出模型的准确性和鲁棒性。 最后,结合深度可分离卷积、跨尺度连接、加权特征融合方法和基于注意力机制的多尺度特征融合策略,构建了一个用于特征融合的BWFPN。 此外,该方法的有效性通过在两个开源和具有挑战性的数据集上的实验得到验证。广泛的消融研究和对比实验的结果表明,本文提出的模型的每个模块都是高效的,并且 SOTA 模型在两个数据集上的检测精度与 SOTA 模型相当,但特征参数和计算量要少得多。
虽然本文提出的轻量级模型在参数数量和计算开销方面具有显着优势,但拟议的模型在复杂缺陷图像检测中存在少量漏检,检测精度仍有提升空间。在未来的工作中,我们将致力于设计更高效、精度更高的轻量级检测模型,另一方面,我们将探索我们提出的方法在实际工业过程中的应用。

















 282
282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









