




 本文探讨了工业缺陷检测中的难点,包括场景分析、数据理解、方法论与算法设计、工具链与部署。主要难点在于数据的难分、多样性、不平衡和脏数据问题。提出了简单粗暴的可行性分析、数据生成策略、定制化模型以及任务拆分等解决思路。同时强调了版本管理、闭环意识和tradeoff意识在方法论中的重要性。文章还介绍了定制语义分割模型、目标检测模型和正常样本建模,并讨论了工具链的建设和部署问题。
本文探讨了工业缺陷检测中的难点,包括场景分析、数据理解、方法论与算法设计、工具链与部署。主要难点在于数据的难分、多样性、不平衡和脏数据问题。提出了简单粗暴的可行性分析、数据生成策略、定制化模型以及任务拆分等解决思路。同时强调了版本管理、闭环意识和tradeoff意识在方法论中的重要性。文章还介绍了定制语义分割模型、目标检测模型和正常样本建模,并讨论了工具链的建设和部署问题。
作者丨皮特潘
编辑丨极市平台
注意:本文从我的一个PPT整理而来,行文可能比较随意,很多细节没有写清楚,后续有时间会持续修改。
上次说到,要写一个系列,最后整理才发现,还是合成一篇比较好一点。
[皮特潘:AI 工业缺陷检测 —— 写在前面的话zhuanlan.zhihu.com(https://zhuanlan.zhihu.com/p/375383384)
主要内容还是围绕着场景分析与数据理解、方法论与算法设计、工具链与部署落地等方面进行展开。重点关注的还是顶层设计,因此涉及到的很多具体的细节没有说太多,仁者见仁智者见智吧。在平时工作中和思考问题上,我喜欢用简单粗暴的手段去分析,比如:本质上,和某某没有区别,说白了就这等语气。目的就是透过现象看本质,抓住主要矛盾。
皮特潘:谈一谈我对AI项目落地的看法zhuanlan.zhihu.com
内容提要
本文大致的脉络是按照场景、数据分析,方法论算法设计,工具链与部署等进行展开。行文中一些比较重要点的,会单独开篇幅进行展开。包含以下论点:
- 主要难点
- 场景分析
- 缺陷归纳
- 简单粗暴的可行性分析
- 数据的四大难点
- 数据生成
- 场景VS数据
- 方法论
- 算法积木
- 任务拆分
- 定制分类模型
- 定制语义分割模型
- 语义分割利器dice loss
- 定制目标检测模型
- 正常样本建模
- 工具链
- 技术壁垒
- 总结
(一) 主要难点
我认为缺陷检测没有啥难的,基本上都可以做。那为啥槽点还那么多?我认为很大一部分是AI的槽点,因为目前使用AI来做是主流,或者说只传统方法搞不定的,没办法,只有上AI的方法。AI的槽点有很多,例如:
- 多少人工就有多少智能,太依赖于标注的数据;
- 过拟合严重,泛化能力差;
- 容易被攻击到,没有提取到真正的特征;
- 提取特征太多抽象,可解释性差,大家都是“黑盒子”玩家;
- 经验学、尝试学,没有建立起方法论,trick太多,很多都是马后炮强行解释;
- “内卷”严重,nlp领域的sota 拿到CV,各种模改就work了?甚至都使用mlp进行返租现象,让我们一时半会摸不到方向。
当然,学术界和工业界也有一条巨大的鸿沟。学术界在于新,有创新点,在开源数据上各种尝试。工业界强调的是精度、成本、落地。再者场景过于分散,没办法达成一致的共识,场景、数据、需求等均是如此。
单单从工业界来看,在“缺陷检测”这一个细分的场景(其实也不是啥细分场景,所有找异常的都可以叫缺陷检测)。也有很多的槽点或者坑点,我认为原因如下:
- 方法论没做好:例如迭代中涉及多个环节,管理容易混乱,或没有意识到baseline数据集的重要性,敏捷开发变成扯皮甩锅。
- demo难做:业务场景分散,没有现成的可以直接展示。方案涉及光学硬件,做demo耗时耗力,关键的是最后不一定能拿下。
- 更换型号难做:光学+标注+训练+部署一条龙,对工具链的用户体验要求非常高。有时别提用户体验了,甚至一个项目现做一套也不夸张。
- 高度定制:还是那句话,业务场景分散,推广困难,复制基本等于重做。
- 精度需求:用户期待高,动辄要求100%?超过人类?
- 检测时间:人工一个小小的动作,自动化执行超级复杂。尴尬的是面对的产品价值可能很低,比如几毛钱的一个塑料制品。
- AI+传统:AI信不过,传统来兜底。结果超参过多,运维困难。单纯AI有时也会存在模型过多的情况。
从业务、工具、管理上来说,有三大难点:
- 业务难点:场景分散,更换型号困难,大规模标注困难,理解数据需要一个过程。
- 工具难点: 工具都有,但是整合困难。
- 管理难点:更新迭代,敏捷开发,需要需求、光学、标注、算法、运维等多方人员协同完成。
(二)场景分析
本文讨论的是工业场景,那就先和自然场景比一比吧!如下:
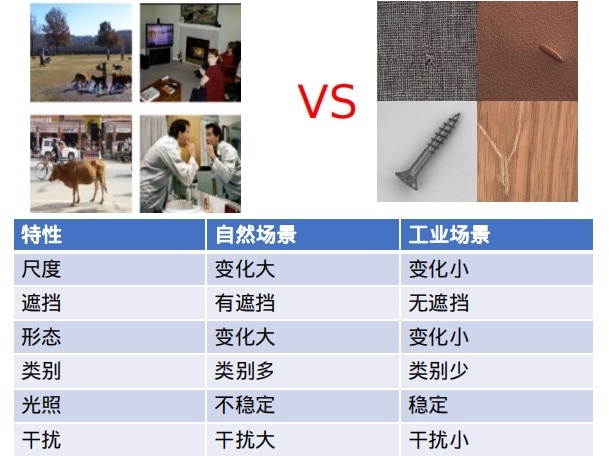
当然有一个非常重要的特性没有说:
自然场景一般是强语义信息,缺陷检测一般为弱语义信息。近期利用轻量级语义分割训练缺陷检测不好使有感而发。缺陷检测不需要特别大的感受野,一般为纹路上的缺陷,局部区域就可以判别。
貌似难度比自然场景少不少,再仔细分析一下,工业场景其实有以下几个特点:
- 业务场景过于分散 ,对标一下“人脸”,甚至“OCR”等领域,缺陷检测场景还是非常分散的,难以归纳。
- 受限、可控 ,有比较的大人工干预空间。例如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









