



 文章详细介绍了Transformer模型在中英翻译任务中的应用,从模型输入输出构建、优化目标、Transformer结构等方面展开。在构建模型时,涉及分词、词汇表建立、嵌入层、填充等步骤。优化目标是通过最小化预测序列与目标序列的交叉熵损失。Transformer结构包括Encoder和Decoder,Encoder处理源语言序列,Decoder则利用Encoder的输出和已生成序列预测目标语言。Decoder中的多头注意力机制、残差连接和层归一化、前馈神经网络等组件协同工作,实现高效翻译。
文章详细介绍了Transformer模型在中英翻译任务中的应用,从模型输入输出构建、优化目标、Transformer结构等方面展开。在构建模型时,涉及分词、词汇表建立、嵌入层、填充等步骤。优化目标是通过最小化预测序列与目标序列的交叉熵损失。Transformer结构包括Encoder和Decoder,Encoder处理源语言序列,Decoder则利用Encoder的输出和已生成序列预测目标语言。Decoder中的多头注意力机制、残差连接和层归一化、前馈神经网络等组件协同工作,实现高效翻译。
如有疑问,可以关注公众号【寻沂】,看到消息后会第一时间回复。
1. 翻译任务简介
当我们拿到现实世界当中的一个中英翻译任务的时候,我们需要怎么构建一个模型通过学习已有的数据来建立源语言(中文)和目标语言(英文)之间的关系呢?接下来,我们分两部分来介绍一个翻译任务工作的流程,包括如何构建模型输入、输出和模型优化目标的构建。
1.1 模型输入/出的构建
在翻译任务中,输入和输出都是文本序列。假设我们需要将中文翻译成英文,那么输入的是一个中文的句子,输出是一个英文的句子。例如:
输入: 你最近怎么样?
输出:How are you?
首先,我们需要构建模型可以识别的输入和输出。
从 one-hot 编码到word2vec 的词汇嵌入。在 NLP 领域里面已经衍生出了一系列通用的处理方法: 包括分词、词汇表建立,通过 Embedding 层做嵌入。为了处理现实世界中语言长短不一的问题。通过填充(Padding) 来做序列的对齐。
为了使得模型能够识别我们的输入,需要提前做一些工作。
- 分词: 将文本序列切成词的列表。
输入: [“你”,“最近”, “怎么样”, “?”]
输出:[“How”, “are”, “you”,“?”] - 建立词汇表:对输入和输出分别建立一个词汇表,每个词映射到一个唯一的整数。词汇表还需要包含特俗的标记。比如:开始符号<S>,结束符号</S>和填充的标记。
中文词汇表: {“<pad>”:0,“<S>”:1, “</S>”:2, “</S>”:3,“?”:4,“你”:5,“最近”:6,“怎么样”:7}
英文词汇表: {“<pad>”:0,“<S>”:1, “</S>”:2, “</S>”:3,“how”:4,“are”:5,“you”:6,“?”:7,} - 内容数值化
输入: [“你”,“最近”, “怎么样”, “?”] [4, 5, 6, 3]
填充: [“How”, “are”, “you”,“?”] [4,5,6,7] - 填充:为了能够让模型处理批量的数据,需要将所有的输入输出序列填充到相同的长度。这可以通过在短序列的末尾添加填充标记来实现。假设最大长度为 10, 最终得到的填充结果是:
输入: [4, 5, 6, 3, 0, 0, 0, 0, 0, 0]
输出: [4, 5, 6, 7, 0, 0, 0, 0, 0, 0]
1.2 优化目标
对一个翻译的训练任务而言,目的是训练一个function实现源语言(中文)和目标语言(英文)之间的映射。

在训练过程中,function初始化的时候是随机的。训练数据包含源语言的序列source seqence和目标语言的序列target sequence。对于每个输入的source seqence得到一个预测的序列predict sequence,例如预测的序列predict sequence是"How old are you?"
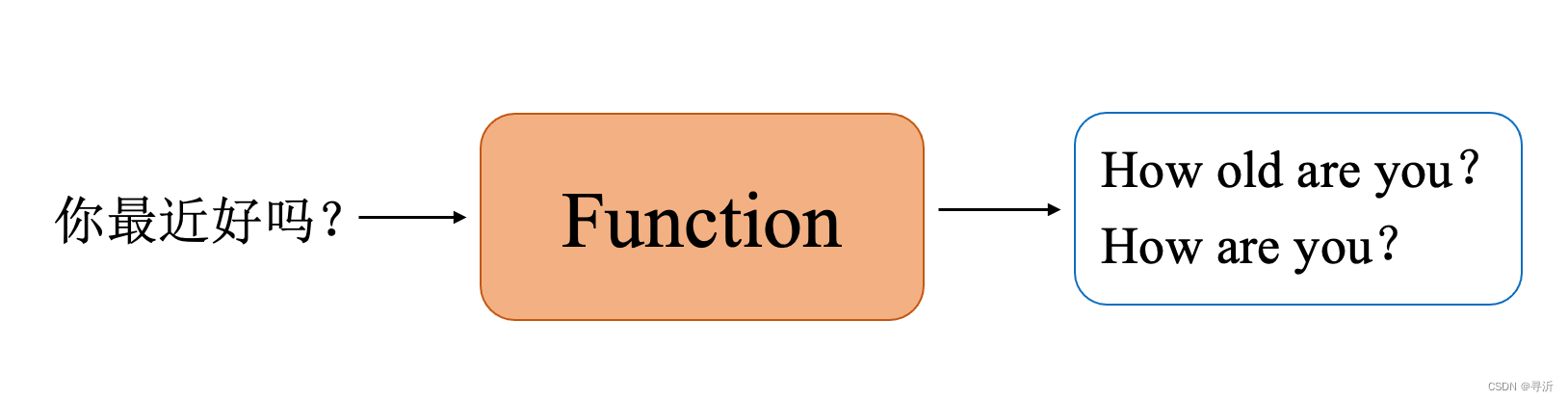
模型训练的目的是为了使function尽可能的准确,那么也就要求predict sequence和target sequence尽可能的相近。所以在训练阶段计算两个序列的交叉损失作为训练过程中的 loss。
在 function的输出层实际上输出的是一个Tensor, tensor 的大小为:
[
b
a
t
c
h
_
s
i
z
e
,
t
a
r
g
e
t
_
s
e
q
_
l
e
n
,
t
a
r
g
e
t
_
v
o
c
a
b
_
s
i
z
e
]
[batch\_size, target\_seq\_len, target\_vocab\_size]
[batch_size,target_seq_len,target_vocab_size]。这个tensor 表示在不同位置上不同词汇的预测概率。最终损失的具体计算代码如下:
import tensorflow as tf
# 假设模型的输出 logits 形状为 (batch_size, seq_length, target_vocab_size)
logits = tf.random.normal((1, 10, 10000)) # 这里假设批大小为1
# 假设实际的目标序列 target 形状为 (batch_size, seq_length)
target = tf.constant([[4, 5, 6, 7, 0, 0, 0, 0, 0, 0]])
# 计算交叉熵损失
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
loss = loss_object(target, logits)
mask = tf.cast(tf.not_equal(target, 0), tf.float32) # 忽略填充部分(假设填充值为0)
loss *= mask
loss = tf.reduce_sum(loss) / tf.reduce_sum(mask)
print(loss)
1.3 Transformer 的输入
在实际的翻译或者生成任务中,目标序列的长度是有限的,例如在上面的例子中如果每次function只预测当前词汇的 token。那么对应的预测顺序应该是:
- step 1:
输入: 你最近好吗?
输出: How- step 2:
输入: 你最近好吗?
输出: are- step 3:
输入: 你最近好吗?
输出: you- step 4:
输入: 你最近好吗?
输出: ?
从上面的例子可以看出,为了让整个“How are you?”的句子连贯,我们可能不仅需要输入源语言(中文)的序列,还需要输入当前已经预测的序列结果。这个时候function的输入变成如下格式:
- step 1:
输入: 你最近好吗? <S>
输出: How- step 2:
输入: 你最近好吗?<S> How
输出: are- step 3:
输入: 你最近好吗?<S> How are
输出: you- step 4:
输入: 你最近好吗?<S> How are you
输出: ?- step5
输入: 你最近好吗?<S> How are you ?
输出: </S>

那么,最后我们得到整个训练、预测任务的输入、输出结构是这个样子的。在本篇文章中,Transformer 对应的就是图中function的部分。
2. Transformer 的结构
在了解了 Transformer 的输入输出之后,我们来看一下function 内部是如何处理这些输入得到输出的。首先来看一下《Attention is all you need》里面给出的图结构。
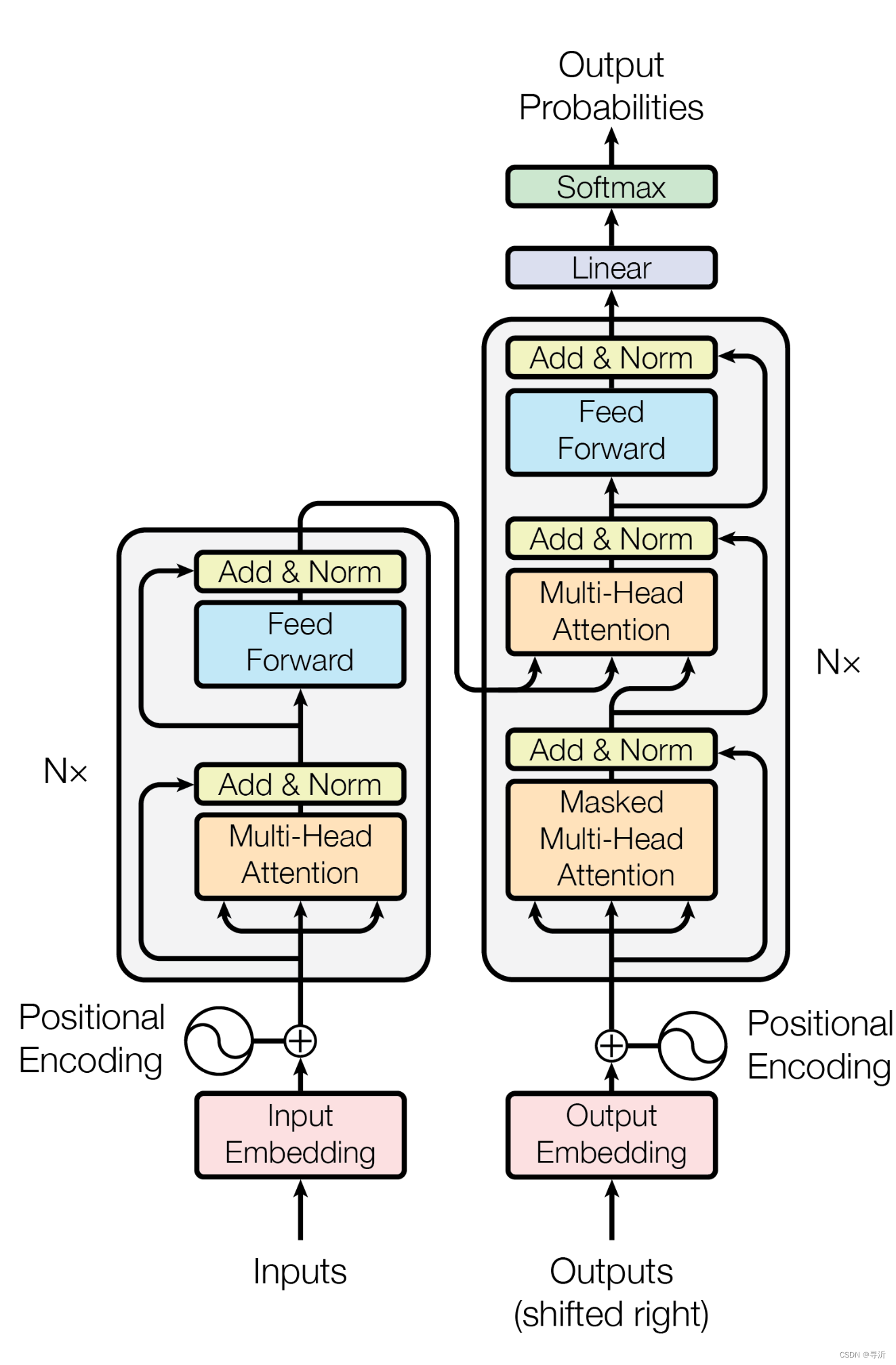
为了简化地描述上图的结构,由整体到部分,从全局到细节。我们先对整体的结构进行简化。
首先来看一下整体的结构。【从这里开始】
2.1 Transformer 的整体结构
Transformer 的整体结构由两个部分组成: Encoder和 Decoder 两个部分。还是以翻译任务为例,Encoder 部分的输入是原始的目标语句,Decoder 部分输入是已经已经生成的前序序列的值。对于例子:
输入: 你最近怎么样?
输出: How are you?
transformer 生成翻译结果的过程如下:
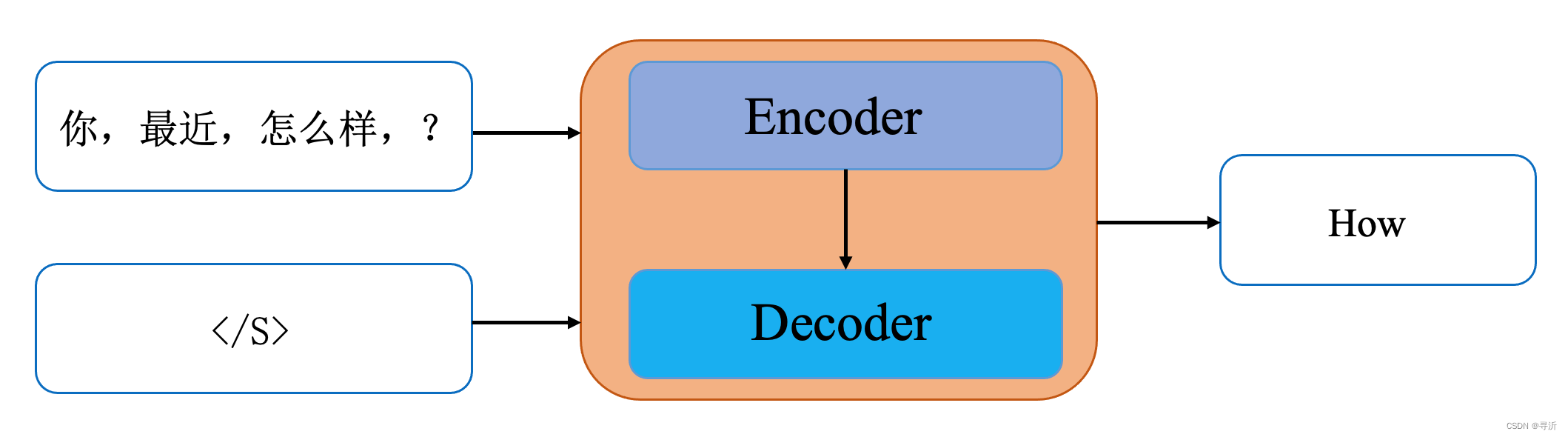
- Step 1:
输入: 你最近好吗? </S>
输出: How
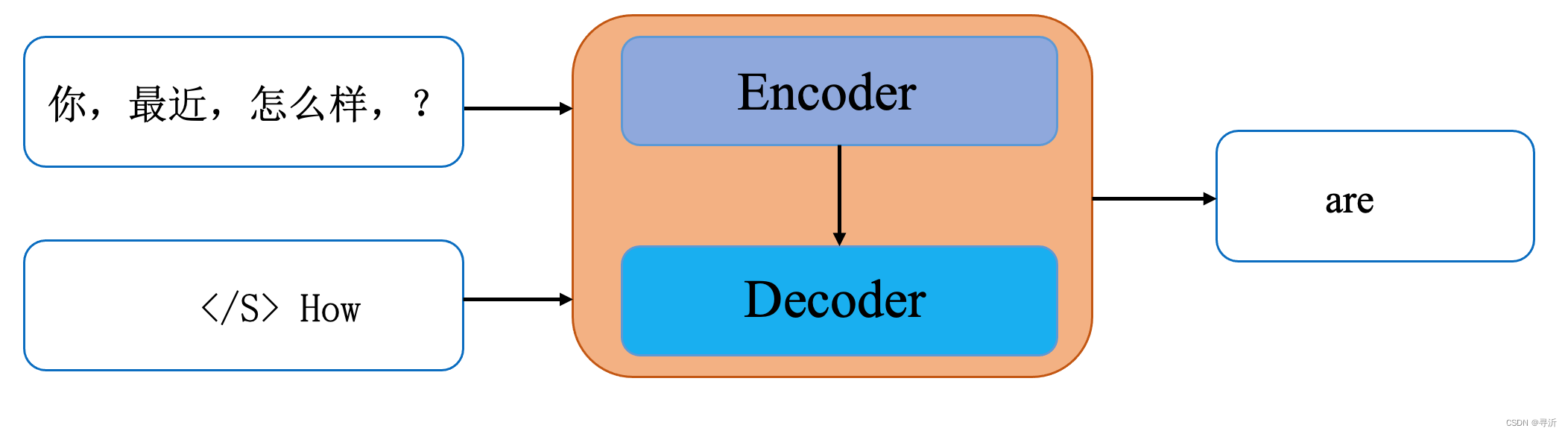
- step 2:
输入: 你最近好吗? </S> How
输出: are
- step 3:
输入: 你最近好吗? </S> How are
输出: you
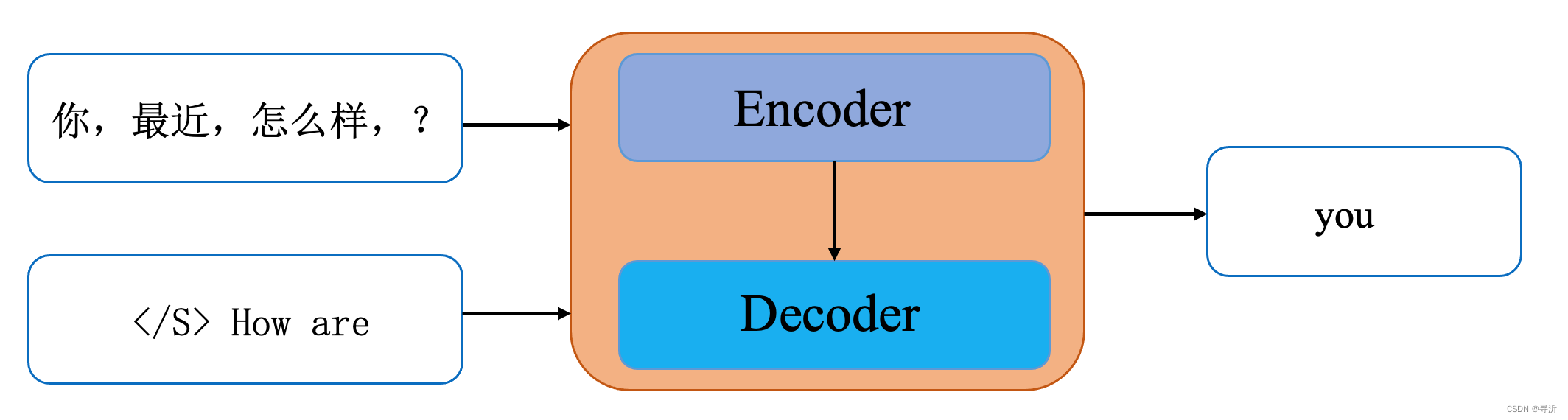
- step 4:
输入: 你最近好吗? </S> How are you
输出: ?
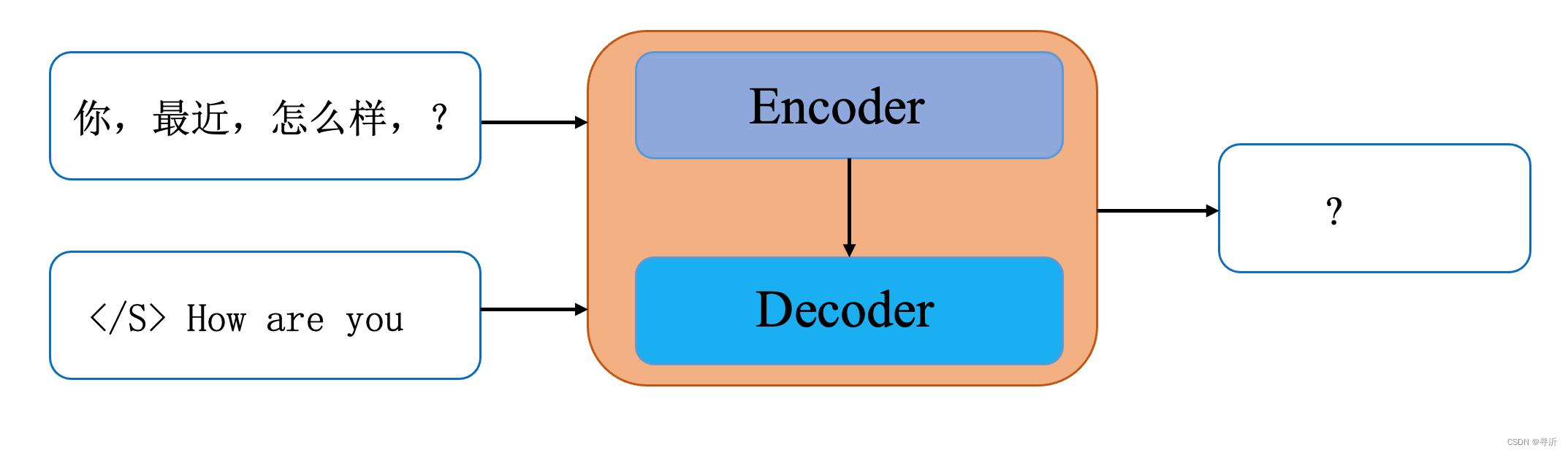
- step 5
输入: 你最近好吗? </S> How are you ?
输出: </s>
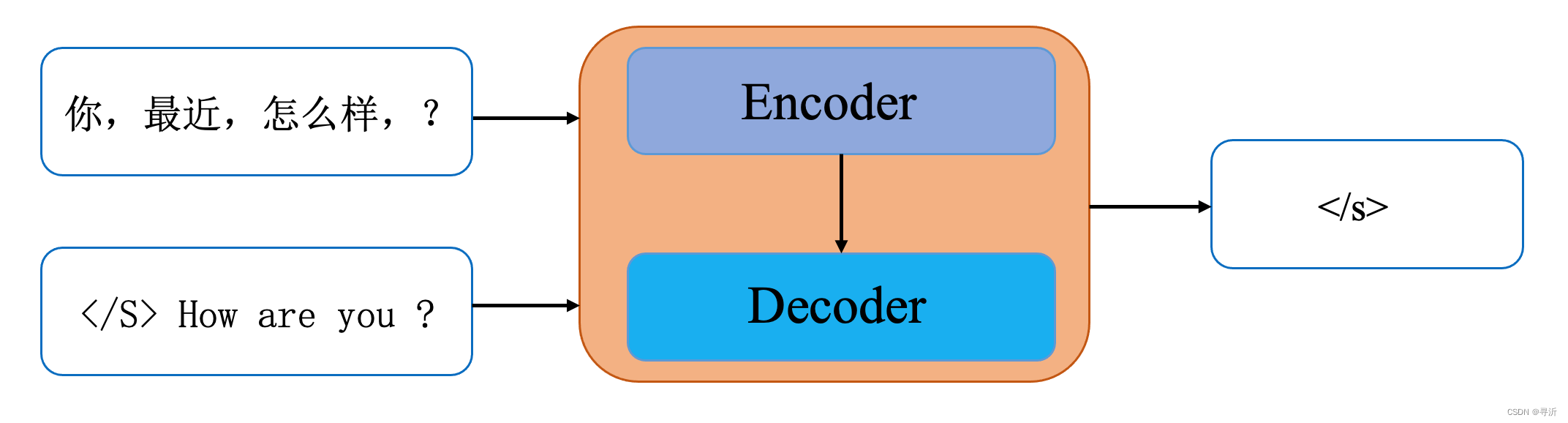
根据上面的图示可以知道,Encoder 的输出以及已经预测出的序列会作为 Decoder的输入,对目标序列的预测到终止符结束。
2.2 Input/Output Embedding结构
了解完Transformer整体的结构之后,来看一下Transformer 输入部分是如何来有效的处理一个序列的。这一个小节当中,主要关注 Transformer在整体结构图中的处理部分,具体如下:
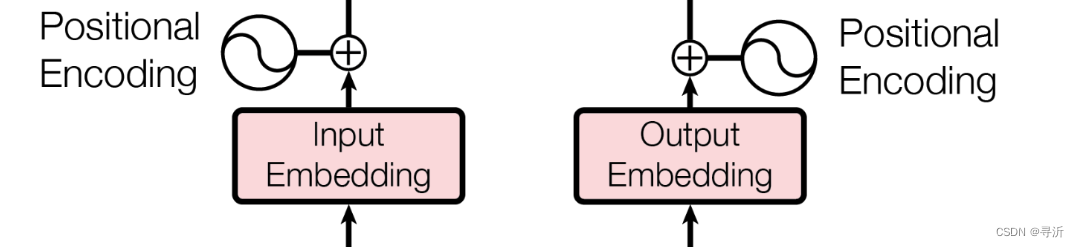
input/output Embedding 部分,我们拿到的是源语言的序列:
[你, 最近, 怎么样, ?]
这个输入转化成 词汇表中的Token 之后,假设序列长度为 10表示如下:
[4, 5, 6, 3, 0, 0, 0, 0, 0, 0]
为了表示序列之间的位置关系,引入 Positional Encoding 来对位置进行编码,为了使得模型可以区分不同的位置。在 Transformer 论文当中主要采用的编码方式为正弦函数和余弦函数相结合,具体编码公式如下:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
(
2
i
/
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
(
2
i
/
d
m
o
d
e
l
)
)
\begin{align} & PE(pos, 2i) = sin(pos / 10000^{(2i / d_{model})} \\ & PE(pos, 2i + 1) = cos(pos / 10000^{(2i / d_{model})}) \end{align}
PE(pos,2i)=sin(pos/10000(2i/dmodel)PE(pos,2i+1)=cos(pos/10000(2i/dmodel))
在上面的公式中,
d
m
o
d
e
l
d_{model}
dmodel 表示向量的维度,这个维度一般和词嵌入向量的维度是相同的。对于给定的位置(索引从 0 开始),我们计算每个位置的编码得到一个长度为
d
m
o
d
e
l
d_model
dmodel的向量,对于向量的每个索引位置
i
i
i。如果
i
i
i 是偶数,计算正弦函数的值,具体的计算公式如公式(1)。如果,位置编码是偶数,计算余弦函数的函数值。作为索引
i
i
i 的值。
对上面的例子,假设
d
m
o
d
e
l
=
12
d_{model}=12
dmodel=12
对于"你" 这个词汇,词汇位置为 0,向量值的索引
i
i
i 分别为[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
P
E
(
0
,
0
)
=
s
i
n
(
0
/
1000
0
2
×
0
12
)
P
E
(
0
,
1
)
=
c
o
s
(
1
/
1000
0
2
×
1
12
)
P
E
(
0
,
2
)
=
s
i
n
(
2
/
1000
0
2
×
2
12
)
\begin{align} & PE(0, 0) = sin(0 / 10000 ^ {\frac{2 \times 0}{12}}) \\ & PE(0, 1) = cos(1 / 10000 ^ {\frac{2 \times 1}{12}}) \\ & PE(0, 2) = sin(2 / 10000 ^ {\frac{2 \times 2}{12}}) \\ \end{align}
PE(0,0)=sin(0/10000122×0)PE(0,1)=cos(1/10000122×1)PE(0,2)=sin(2/10000122×2)
依此类推,可以得到一个位置向量
P
E
∈
R
1
×
d
m
o
d
e
l
PE \in \mathbb{R}^{1\times d_{model}}
PE∈R1×dmodel。对于词汇向量,随机初始化为一个可学习的词汇向量表。那么对于每个词汇有一个词汇向量
V
j
V_{j}
Vj 和位置向量
P
E
j
PE_{j}
PEj。其中
j
j
j表示词汇向量在词汇序列当中的位置。那么我们可以得到Encoder 的向量表示:
I
0
=
V
0
+
P
E
0
I
J
=
V
j
+
P
E
j
\begin{align} & I_0 = V_0 + PE_0 \\ & I_J = V_j + PE_j \\ \end{align}
I0=V0+PE0IJ=Vj+PEj
对于 Decoder 的输入有类似的计算结果。
2.3 Encoder 结构
了解完成Input/Output Embedding 部分之后,我们来看一下Transformer 当中 Encoder 的部分。这部分的主要涉及的结构如下:
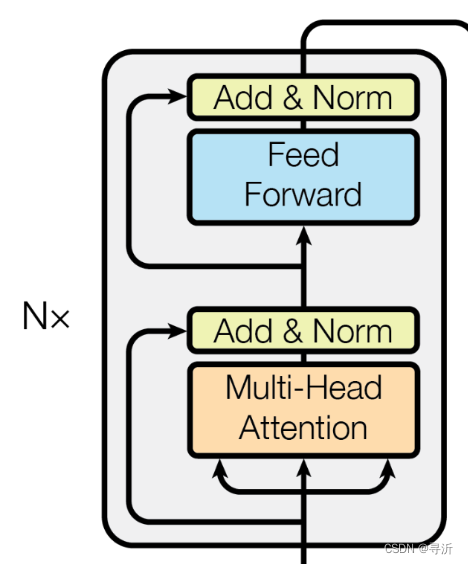
在 Encoder 部分,接受经过 Positional Encoding 之后通过得到一个输入的 tensor,这个tensor 的大小是
[
b
a
t
c
h
_
s
i
z
e
,
s
e
q
_
l
e
n
,
d
m
o
d
e
l
]
[batch\_size, seq\_len, d_{model}]
[batch_size,seq_len,dmodel]。
- b a t c h _ s i z e batch\_size batch_size: 表示整个输入的 batch大小
- s e q _ l e n seq\_len seq_len: 表示输入序列的长度。
- d m o d e l d_{model} dmodel: 表示词汇嵌入 Embedding 的大小。
在 Encoder 内部是一个由 N N N个相同的层堆叠起来的,在 Transformer 当中 N = 6 N=6 N=6。在 Transformer 当中层按照执行顺序包含四个子模块:
- 多头注意力机制(Multi-Head Self-Attention)
- 第一个残差链接和层归一化(Residual Connection & Layer Normalization)
- 前馈神经网络(Position-wise Feed-Forward):
- 第二个残差链接和层归一化(Residual Connection & Layer Normalization)
2.3.1 多头注意力机制(Multi-Head Self-Attention)
在多头注意力机制当中,引入了Self Attention 学习序列空间当中的内部结构。通过引入Self-Attention 具备如下优势:
- 可以实现并行计算
- 可以无视词汇之间的距离计算词汇之间的相关性(和 RNN 以及 LSTM 对比)。
Self-Attention 的计算过程如下:
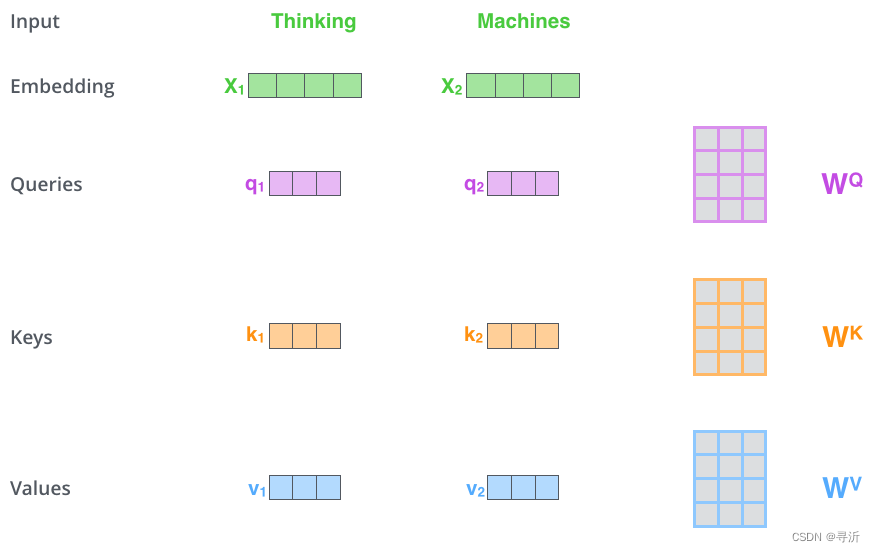
- Step 1: 初始化 Q, K, V
通过讲输入的 Embedding和我们构建的三个矩阵相乘分别创建一个 Query、Key 和 Value 向量。
Q
=
W
q
X
K
=
W
k
X
V
=
W
v
X
\begin{align} & Q = W_q X \\ & K = W_k X \\ & V = W_v X \\ \end{align}
Q=WqXK=WkXV=WvX
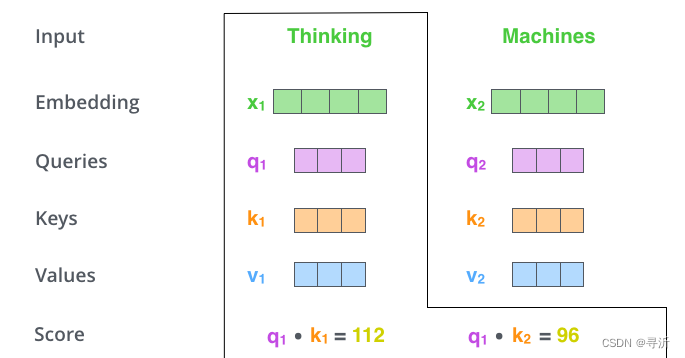
- Step 2: 计算 Self-Attention Score
在计算序列当中每个词汇的自注意力的时候,需要根据这个词对每个词进行评分。当我们对某个位置进行编码的时候,分数决定了讲多少注意力放在输入句子的其他部分上,我们通过目标词汇的
Q
u
e
r
y
Query
Query和输入语句当中所有词汇的
K
e
y
Key
Key计算点积来得到不同词汇的
S
c
o
r
e
Score
Score
具体如下图:
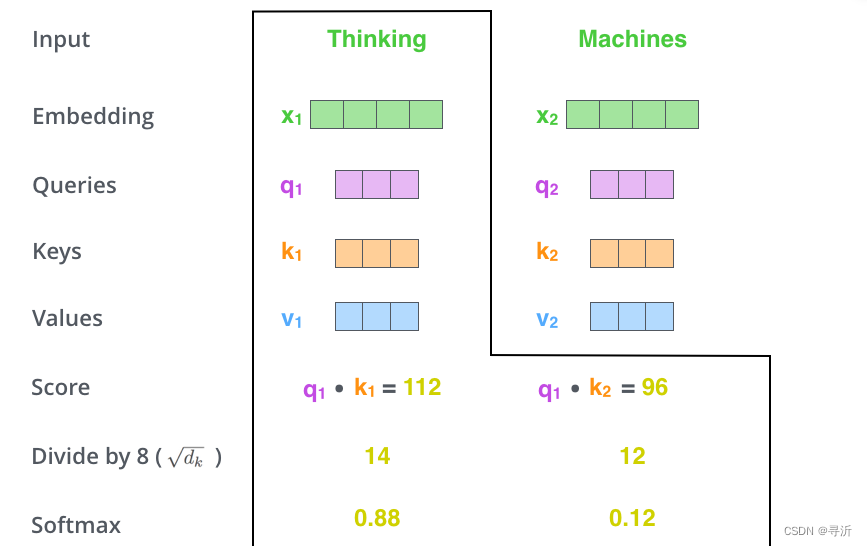
-
Step 3: 对 Self-Attention Score 进行缩放和归一化,得到Softmax Score
-
Step 4: 通过 Softmax Score 乘以Valule 的向量,求和得到 Attention Value
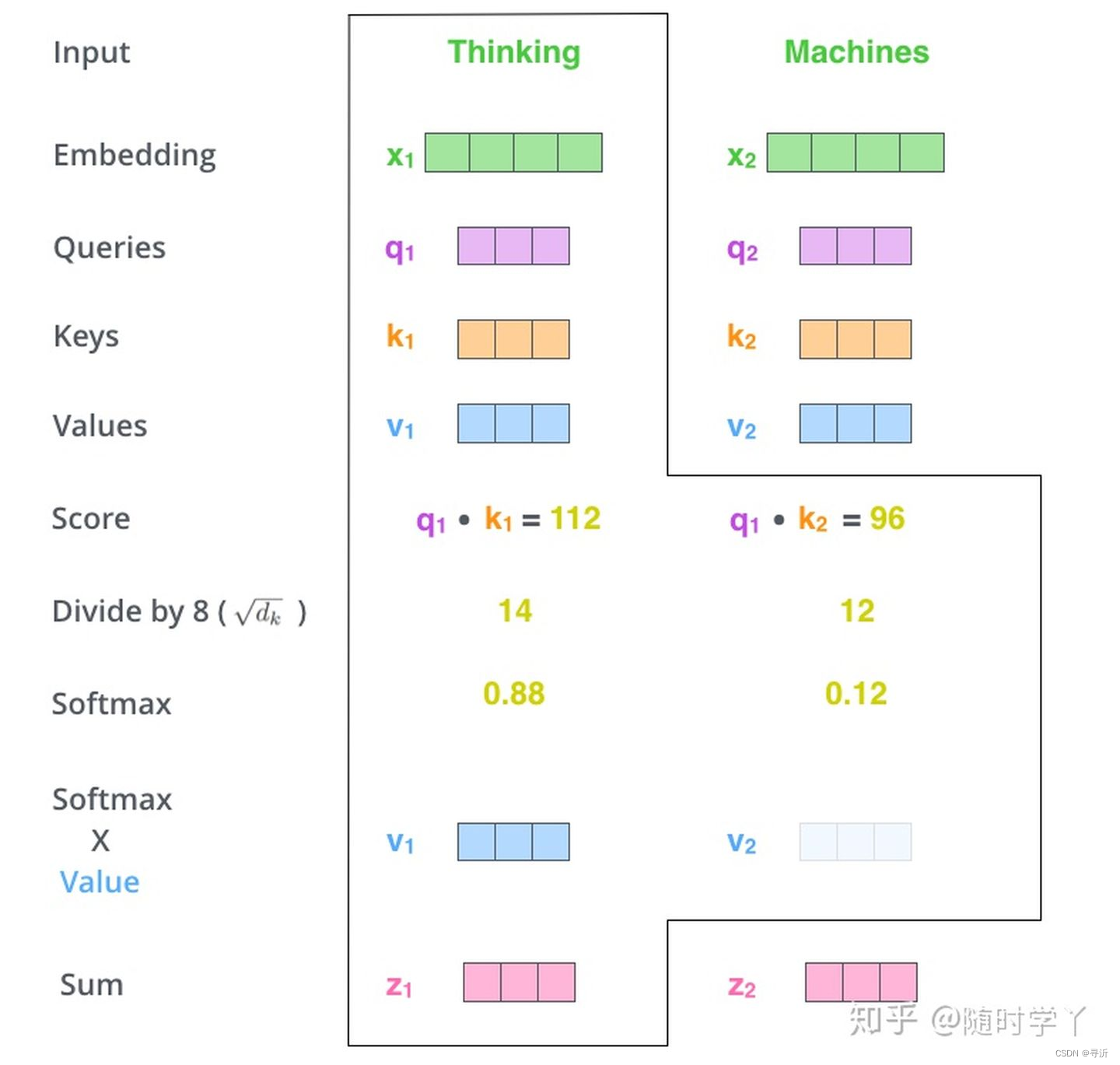
在上述的Self-Attention 机当中,解决了三个问题:
- 不需要目标词汇,能够学习序列子空间的内部结构
- 解决了RNN 和 LSTM 序列关系学习中需要串行的计算方式。
- 跨越了两个词汇之间距离对用户序列的影响。
看完 Self-Attention我们来看下 Multi-Head Self-Attention 是怎么回事。
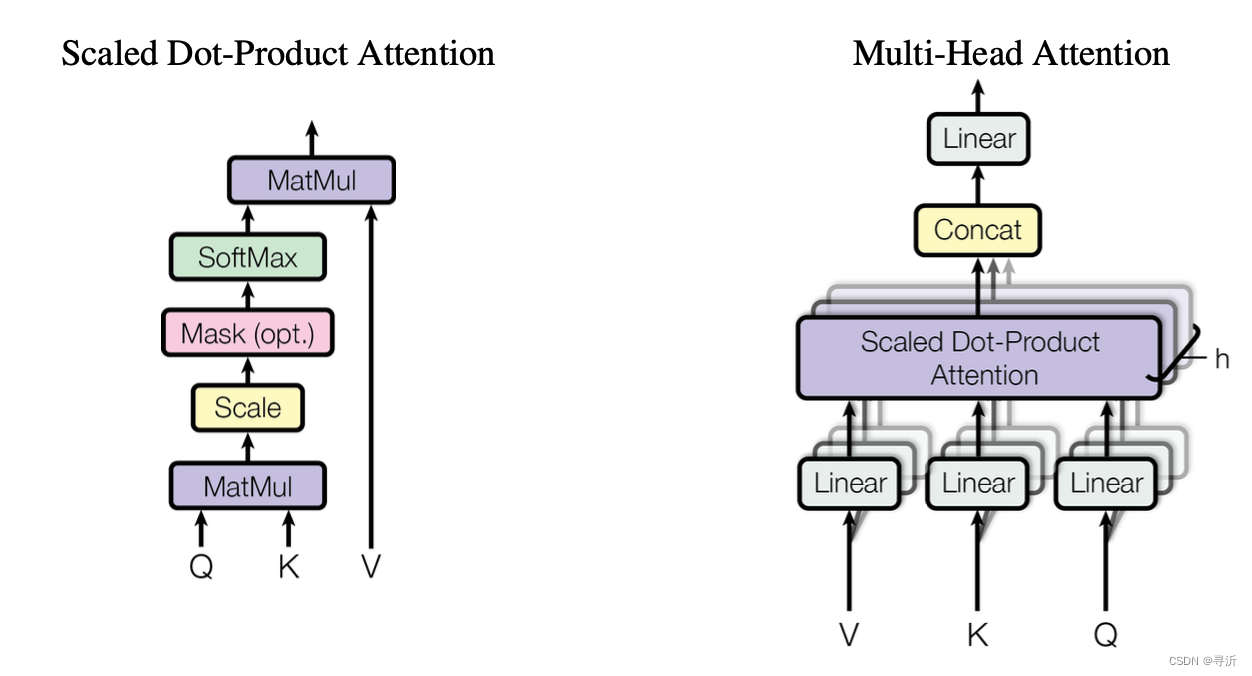
在 Multi-Head Self-Attention 当中相当于使用了多个 Self-Attention。例如原来
d
a
t
t
e
n
i
o
n
=
1024
d_{attenion}=1024
dattenion=1024,现在设置
8
8
8个分割头,分别对输入的序列做Self-Attention,那么这个时候我们可以使用将
d
a
t
t
e
n
t
i
o
n
=
128
d_{attention} = 128
dattention=128。最终,讲每个独立的 Self-Attention 得到的结果 Concat 起来。
至于为什么这种方式有效,俺也不知道。
2.3.2 残差连接和层归一化(Residual Connection & Layer Normalization)
残差连接部分主要是将模型的输入和输出相加,是指在经过网络处理之后,讲输入直接加到输出上。也就是
y
=
F
(
x
)
+
x
y = F(x) + x
y=F(x)+x。这种连接方式能够使得网络更有效地学习更深层的特征表示,缓解梯度消失。
层归一化(Layer normalization) 是一种对每个样本的数据进行归一化的方法。具体计算方式如下:
μ
=
1
n
∑
i
=
1
n
x
i
σ
=
1
n
∑
i
n
(
x
i
−
μ
)
2
x
^
i
=
x
i
−
u
σ
\begin{align} & \mu = \frac{1}{n}\sum_{i=1}^nx_i \\ & \sigma=\sqrt{\frac{1}{n}\sum_i^n(x_i-\mu)^2} \\ & \hat x_i = \frac{x_i-u}{\sigma} \\ \end{align}
μ=n1i=1∑nxiσ=n1i∑n(xi−μ)2x^i=σxi−u
即对于每个样本的每个维度,都计算出该维度的均值和标准差,然后将原值减去均值再除以标准差。得到归一化之后的值。这种方法能够环节梯度消失的问题,使得神经网络能够更好地学习和表示句子中的语义信息。
在 Decoder 每个层的子结构当中包含两个残差连接和归一化的操作,分别在 Attention 之后以及前馈网络之后。
2.3.3 前馈神经网络(Position-wise Feed-Forward)
在 Decoder 里面除了 Attention 之外另外一个子网络是一个全连接的位置前馈网络层,简称 FFN。FFN 是 Transformer 模型当中的一个关键组件。在编码器和解码器的每个层当中,都包含了一个 FFN 子层,通过 FFN 独立地学习每个位置的非线性特征,从而提高模型的表达能力。在 FFN 当中使用 ReLU 或者是 GELU 作为激活函数。
具体的结构如下:
- 第一个线性层: 将输入向量映射到一个更高维度的隐藏空间。这个线性层的权重矩阵具有形状 [ d m o d e l , h i d d e n d i m ] [d_{model}, hidden_{dim}] [dmodel,hiddendim],其中 d m o d e l d_{model} dmodel 是隐藏层的维度。
- 激活函数: 将一个线性层的输出传输给激活函数,引入非线性特征。
- 第二个线性层: 将激活函数输出映射回原始的输出空间维度为 d m o d e l d_{model} dmodel
2.4 Decoder 结构
解码器的输出是一个表示目标序列概率分布的张量,也就是输出的是一个大小为
[
b
a
t
c
h
_
s
i
z
e
,
s
e
q
_
l
e
n
,
t
a
r
g
e
t
_
v
o
c
a
b
_
s
i
z
e
]
[batch\_size, seq\_len, target\_vocab\_size]
[batch_size,seq_len,target_vocab_size]的 Tensor。
其中:
b
a
t
c
h
_
s
i
z
e
batch\_size
batch_size: 表示每个 batch 的大小。
s
e
q
_
l
e
n
seq\_len
seq_len: 表示序列的长度。
t
a
r
g
e
t
_
v
o
c
a
b
_
l
e
n
target\_vocab\_len
target_vocab_len: 表示所有候选词汇的长度。
这样,我们就能知道在序列中每个位置上词汇表中所有词汇的概率,然后通过 argmax 函数选择最大的词汇作为最终的输出,作为预测的结果。
Decoder 在训练阶段和推理阶段的输入输出存在一些差异。
| 训练阶段 | 推理阶段 | |
|---|---|---|
| 输入 | 输入的是样本中目标词汇之前的词汇和起始符号。例如要预测 you 时候输入 : [<s>, How, are] | 输入的是之前预测出来的词汇和起始符号 |
| 输出 | 每个位置的概率,最后 softmax 计算出来的概率 tensor 用来计算损失 | argmax 最后输出的 token id |
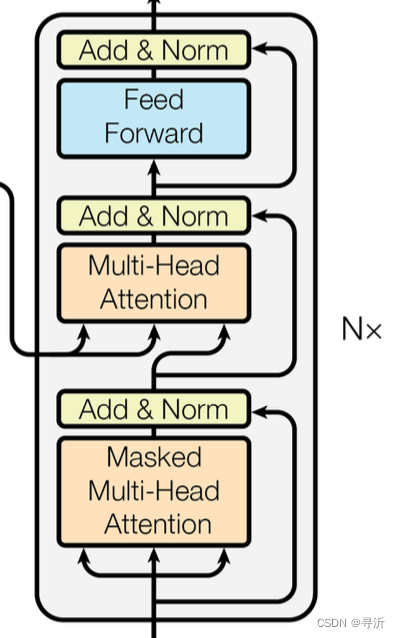
接下来我们来看下 Decoder 的整体结构,Decoder 的输入除了已经预测的序列结果之外,还包括 Encoder 部分的 Embedding 输入。在整个 Decoder 部分包含两部分的工作:
2.4.1 Masked Multi-Head Attention
在Decoder 的输入当中,为了防止数据的泄露。在我们对当前的token 进行Multi-Head Attention 进行编码的时候,不能泄露后面的数据信息。
例如,在翻译任务当中,我们输入[你,最近,怎么样? ]的时候,输出的翻译结果为[How, are, you, ?]。对于 Decoder 的部分,预测不同 token 的时候序列输入分别是:
- Step 1: <S>
- Step 2: <S> How
- Step 3: <S> How are
…
在上面的例子中,Step 3 中对 How进行 Multi-Head Attention 的时候。如果使用了are的信息实际上。可以理解为对 How 的编码泄露了后续的信息。因此在每一步的编码中需要对当前编码位置的后面 token 做 mask。
在已知需要 mask 的情况下,如何在一个序列输入当中对不同的 token 进行编码时做不同的 mask 呢? 比如,对于[How, are, you, ?] 的这句输出,不同位置分别需要做的 mask 如下。
[
<
S
>
H
o
w
a
r
e
y
o
u
?
<
/
s
>
]
[
0
1
1
1
1
1
0
0
1
1
1
1
0
0
0
1
1
1
0
0
0
0
1
1
0
0
0
0
0
1
0
0
0
0
0
0
]
\begin{bmatrix} & <S> \\ & How\\ & are\\ & you\\ & ? \\ & </s> \end{bmatrix} \begin{bmatrix} 0& 1& 1& 1& 1& 1&\\ 0& 0& 1& 1& 1& 1&\\ 0& 0& 0& 1& 1& 1&\\ 0& 0& 0& 0& 1& 1&\\ 0& 0& 0& 0& 0& 1&\\ 0& 0& 0& 0& 0& 0&\\ \end{bmatrix}
<S>Howareyou?</s>
000000100000110000111000111100111110
当前的词汇,只能看到自身和这个词汇之前的词汇 token,因此在预测时候会得到如上述所示的 mask 矩阵。mask 矩阵的创建代码如下:
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
x = tf.random.uniform((1, 3))
temp = create_look_ahead_mask(x.shape[1])
temp
在 Multi-Head Attention当中对 mask 的使用如下:
scaled_attention_logits += (mask * -1e9)
对于 mask 的值非 0 的部分会加上一个无穷小的值。
2.4.2 Multi-Head Attention的结构堆叠
在 Mask Multi-Head Attention 之后,Transformer Decoder部分依旧采用类似于Encoder 部分的堆叠结构。主要由四个部分组成:
- Multi-Head Attention: 用来对学习Decoder 序列输入内部和Encoder 输入内部的子空间
- Add & Norm: 用来构建残差和归一化,防止梯度消失
- Position-wise Feed-Forward: 使用一个前馈网络来捕获更多特征
- Add & Norm: 用来构建残差和归一化,防止梯度消失
2.5 Liner和 Softmax
对于 Decoder最后的输出结果,通过一个线性层,然后进行 softmax 得到最终的输出结果,最终的输出结果是一个 [ b a t c h _ s i z e , s e q _ l e n , v o c a b _ s i z e ] [batch\_size, seq\_len, vocab\_size] [batch_size,seq_len,vocab_size] 的 Tensor 表示每个词汇的概率
[1] Self Attention 概述
[2] 拆 Transformer 系列二:Multi- Head Attention 机制详解随时学丫
[3] 为什么Transformer 需要进行 Multi-head Attention?
[4] transformer中的前馈网络有什么用?
[5] 训练过程中的 Mask实现
[6] 理解语言的 Transformer 模型
[7] 碎碎念:Transformer的细枝末节
[8] 关于Vanilla Transformer的种种细节

















 6497
6497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









