



可扩展、实用的端到端同态加密VoIP电话会议
库尔特·罗夫洛夫,IEEE会员,大卫·布鲁斯·科usins,IEEE高级会员,丹尼尔·苏莫罗克,IEEE会员
摘要
我们提出了一种在商用移动设备和数据网络上实现可扩展、安全的网络语音(VoIP)电话会议的方法,该方法采用端到端同态加密(HE)。我们假设一种诚实但好奇的威胁模型,即攻击者即使能够观察参与者之间的所有通信并访问电话会议服务器,也无法获取未加密数据,从而无法窃听通话内容。以往的安全VoIP电话会议服务依赖于:1)电话会议客户端与其他客户端维持点对点加密连接,或 2)依赖可访问并操作未加密VoIP流的电话会议服务器。我们的方法仅在单个VoIP服务器上对加密状态下的VoIP数据流进行混合,且数据流在电话会议服务器上始终不被解密。本方案的创新之处在于采用高效VoIP编码以降低同态混合加密VoIP数据所需的电路深度,实现低带宽使用的参数化设计,并将其集成到现有的开源VoIP基础设施中。我们在商用iPhone上进行了实验评估,通过最低成本的 Amazon AWS云服务器实例作为VoIP服务器进行混合,并在商用数据网络和802.11n接入点之间进行通信。
1 引言
网络语音(VoIP)电话会议由于低成本便携式计算设备的普及以及便捷、经济的数据网络接入而变得日益重要。人们普遍认为被攻陷的数据网络或VoIP服务器可能被对手利用,窃取并泄露通过远程会议中的VoIP传输的敏感信息。
安全的网络电话远程会议部分通过点对点通信链路实现,这些链路使用点对点加密技术[1],[2]来保障安全。这种方法不具备可扩展性,需要建立 O(n²) 条点对点加密链路,导致带宽问题,从而降低用户体验质量。为解决可扩展性限制,可将语音信号发送至集中式电话会议服务器,由该服务器混合 VoIP信号,然后将混合后的信号返回给参会者。
迄今为止,电话会议服务器上的网络电话信号需要以明文形式进行混合,这意味着网络电话信号必须在服务器上解密。VoIP电话会议服务器通常托管在半安全的环境中,例如由亚马逊AWS¹或 Microsoft Azure²等通用云提供商托管。如果服务器遭到入侵,语音数据可能会泄露给攻击者,且电话会议已容易受到各种类型的中间人攻击[3]。因此,亟需一种具备端到端加密的VoIP电话会议方案,使得除拥有解密密钥的客户端外,任何一方都无法访问明文的网络电话信号。我们提出了一种在加密状态下对数据进行混合的电话会议方法。该方法即使在攻击者能够观察到电话会议服务器执行的所有通信和数据操作的情况下,也能防止通信内容泄露。
电话会议客户端使用加法性编码方案对其语音样本进行编码,并在其加法同态加密方案下对其编码后的语音数据进行加密,并将加密的语音样本发送到VoIP电话会议服务器。该VoIP电话会议服务器对加密网络语音信号执行加密信号混合操作。此加密混合操作包含同态加法。电话会议服务器将加密混合的结果发送回客户端。客户端对结果进行解密、解码并播放。我们的方法预先共享了一个共享私钥。
我们方法的创新之处在于:
- 一种高效的VoIP编码,用于降低加密网络电话数据同态混合的电路深度。
- 一种仅使用同态加法的同态混合操作。
- 一种提供同态加法的简化同态加密。
- 用于安全性、高语音质量和低带宽使用的参数化。
- 集成到现有的开源VoIP基础设施中。
- 在低成本移动设备和云计算基础设施以及商业数据网络上进行实验。
我们的方法的密码学基础是一种高效的加法性同态加密方案的实现。该密码系统基于实用同态加密领域的最新进展[4]。特别是,我们的方法基于基于格的同态加密的最新进展,是对LTV方案[5]的简化,而该方案本身是一种类NTRU密码系统[6]。
我们将语音数据编码和加密实现集成到现有的 Mumble/Murmur开源VoIP电话会议框架³中。我们实验性地评估了在通用iOS客户端(如iPod Touch和iPhone)上运行的端到端加密VoIP电话会议应用,混合使用最低成本的亚马逊AWS云服务器实例以及商用蜂窝数据网络或通用802.11n无线接入点。
本文的组织结构如下。第2节讨论了相关的远程会议方法以及应用同态加密的研究工作。第3节讨论了我们的安全模型、对攻击者的假设,以及针对可扩展VoIP电话会议能力的设计目标。第4节讨论了我们端到端加密的网络电话远程会议能力的整体架构。在第5节中,我们进行了描述我们对所基于的LTV‐based homomorphic cryptosystem[5]进行了简化。我们在第6节介绍了自定义的网络电话编码方案,在第7节介绍了同态混合操作。在第8节中,我们描述了将密码系统与 Mumble开源网络语音框架集成的方法。第9节讨论了在参数化编码方案、密码系统和网络语音混音器时所做的工程权衡。第10节讨论了实验。我们在第11节进行了安全分析。最后,在第12节中,我们总结了本文的研究成果,并探讨了未来的工作方向。
2 相关工作
安全网络语音技术的进步主要集中在为传输中数据提供安全性,解决身份与密钥管理以及诸多其他安全性问题。最近有一些研究工作致力于应对这些挑战,包括使用安全多方计算(SMC)在多个服务器上混合加密网络语音信号,其限制条件是每个客户端需信任一个服务器。
我们的方法基于之前被认为在广泛的实际应用中效率较低的基于格的同态加密(HE)[10]。针对同态加密运行时挑战的解决方案已通过多种途径进行探索,包括提高方案效率 [11],[12], 以及实现的效率 [13]–[16]。
除了同态加密设计中的运行时挑战外,对于同态加密数据的数据结构和表示方法也缺乏足够的实践经验[17]。将熟悉的数据结构和算法(例如网络电话混合)移植以高效地与同态加密结合使用仍是一个持续的挑战,尤其是如何在加密输入数据上实现这些算法的高效加密执行。我们将完整的网络电话数据帧放入每个密文中,这种设计比网络电话的行业标准更简单,例如μ律编码器[18]。
3 威胁模型和功能目标
为了明确我们加密远程会议概念的功能和安全目标,我们提出了高层次的设计考虑:
1) 加密工作因子 :我们应提供足够的加密工作因子以保护远程会议。对于我们的基于格的方案,当前的安全估计表明根Hermite因子 δ< 1.007通常提供80位安全强度和足够的工作因子 [19]。
2) 服务器被攻破 :即使服务器被诚实但好奇的攻击者完全攻破并观察所有内部服务器操作,数据的机密性也应得到保障。
3) 延迟 :端到端延迟应低于150毫秒,这在实践中被认为是可接受的 [20]。
4) 音质 :应具备可接受的音质,最好支持全双工,以便用户在说话时也能听到对方。
5) 可扩展性 :远程会议能力应能够扩展以支持两个以上参与者,且音质或延迟无明显下降。
6) 带宽使用 :远程会议能力提供的密文膨胀应比当前AES加密方法低一个数量级以内。
7) 广域地理区域 :该能力应适用于跨大陆距离的通信。
4 端到端加密的网络电话会议架构
在我们的使用场景中,多个客户端通过公共数据网络(如公共互联网)连接到VoIP服务器。每个客户端对语音数据流进行采样、编码并加密。客户端将其加密流发送至服务器。服务器对这些流执行同态混合操作,并将加密结果发送回各个客户端。客户端对接收到的数据进行解密、解码,并向用户播放。
在会话中,服务器合并来自客户端的未加密(明文)数字音频信号的编码样本时,通常采用的方法是将这些编码后的样本相加以实现。在电话会议服务器上用于合并已编码但未加密的数字音频信号样本的函数称为Mix函数。这提示了一种设计加密VoIP电话会议的方法,即设计明文Mix函数的同态加密版本。我们将该同态加密版本的Mix称为 EvalMix。Mix的设计思路表明,EvalMix可以通过对加密的音频信号进行同态相加来构建。为此,需要一种加法同态加密方案和一种加性编码方案。
这种方法。(如果编码方案 Encode() 满足 Encode(a+ b) = Encode(a)+ Encode(b),则其具有加法性。)
主要挑战在于设计一种同态求值函数Eval Mix,使得对于两个语音样本 v₁和 v₂及其相应的编码Enc(pk, v₁)和Enc(pk, v₂),我们知道信号混合的结果Mix(v₁, v₂)等于Dec(sk, EvalMix(Enc(pk, v₁), Enc(pk, v₂))),其中数字音频流被编码为明文。我们应能够对Enc和EvalMix操作进行参数化,使其具备足够的安全性与资源高效性,从而实现端到端加密的VoIP电话会议的实用性。如果{Enc(pk, v₁), Enc(pk, v₂), Enc(pk, v₃)}是从三个客户端接收到的由服务器接收的加密音频块,则服务器应返回给客户端1一个密文 c′₁,该密文在解密后等于Mix(v₂, v₃)。
5 加法同态格基密码系统
我们构建了基于格的LTV全同态加密方案[5]及其实现[4]。关于基于格的密码学的数学基础可参见文献 [21],而文献[22]综述了基于格的方案。
我们的同态加密密码系统提供了核心的公钥加密原语:密钥生成(KeyGen →(pk, sk))、加密(Enc(pk, µ) → c)和解密(Dec(sk, c) → µ),其中 pk是公钥, sk是私钥, µ是明文,c是密文。我们的方案被定义为加法同态加密方案,因为它提供了一个操作EvalAdd(c₁, c₂)→ c₃,当参数化以满足正确性约束时,有Dec(Enc(a+ b)) = Dec(EvalAdd(Enc(a), Enc(b)))。
我们对[4],[5]中方案的主要简化是移除了对 EvalMult的支持。[4],[5]中通用方案的正确性和安全性约束在我们的简化方案中仍然成立,并且我们可以在保持安全性和正确性的同时选择更小的具体参数。
5.1 明文和密文表示
我们使用2的幂次分圆多项式,这意味着明文和密文向量表示模 p整数环上次数为 2ˣ[21]的多项式的系数。几乎所有我们需要在明文和密文上支持的操作都是线性变换,通过将维度限制为2的幂次,我们降低了实现复杂度。这直接转化为更高效的实现。
对于 n为2的幂的情况,我们定义环 R=Z[x]/(xⁿ + 1) (即模整数多项式)
xⁿ+ 1),其中对于任意正整数 q,定义密文空间 Rq= R/qR(即模 xⁿ+ 1的整数多项式,系数为模q)。有关数学预备知识的更多细节可参见[21]。
明文空间为 Rp,其中 p ≥ 2为某个整数,表示明文是长度为n、模 p的整数向量。通常 p远小于 2⁶⁴,我们通常选择 p介于2和 2¹²之间。
5.2 基于LTV的LSB编码方案
在基于格的加密方案中,明文、密文和其他环元素可以表示为等效的求值表示或中国剩余定理变换(CRT)表示[21]。通过应用一种称为中国剩余定理变换(CRT)的特殊数论变换,可将环元素从求值表示转换为CRT表示[21]。更具体地,我们可以将密文从其求值表示 ce转换为其CRT表示 ccrt,通过计算ccrt= CRTq(ce),其中CRT的参数化选择如[23]所示。逆中国剩余定理变换(CRT⁻¹)将环元素从 CRT表示转换回求值表示。在这种情况下, ce可以通过应用逆CRT变换 ce=CRT⁻¹q(ccrt)从 ccrt中恢复。
我们简化的LTV加密方案对密文表示方式是无关的。除非另有说明,我们假设采用CRT表示。
CRT表示的优势在于,在此表示下,密文上的加法和乘法运算可以高效地按元素进行。
我们的密码系统操作描述如下:
-
密钥生成 :选择一个“短” f ∈ R,使得 f= 1 mod p,且 f在模 q下可逆。具体而言, f是一个包含 n个整数的向量,当且仅当其每个模‐q中国铁路总公司求值均非零时, f在模 q下可逆。“短”元素 f可从离散高斯分布中选取。例如,我们可以令 f= p · f′+1(其中1是长度为n 、所有元素均为1的向量),其中 f′服从高斯分布。该高斯分布为零中心,其分布参数记为 r。我们输出 sk= f。如上所定义的私钥,最高效率的表示方式是其求值表示形式。类似地,我们选择一个“短”的 g ∈ R,也可能来自离散高斯分布。 g在其求值表示中被采样表示方法,但随后会转换为其CRT表示。f⁻¹(模 q)的CRT表示是 f1的模‐q逆元。我们以双CRT表示输出pk= h= g · f⁻¹ mod q。
-
加密(pk= h, µ ∈ Rp) :选择一个“短” r ∈ R和一个“短” m ∈ R ,使得m= µ mod p。向量 r和 m在其求值表示中进行采样,然后转换为其CRT表示。我们输出 c= p · r · h+ m mod q。具体而言,m可以选择为 m= p · m′+ µ,其中 m′是在其求值表示中采样的高斯分布值,然后转换为其CRT表示。
-
解密(sk= f, c ∈ Rq) :计算 b= f · c mod q,并将其提升为系数在 [−q/2, q/2) 内的整数多项式 b ∈ R。输出 µ=b mod p。
该方案支持加法同态:
EvalAdd(c₀, c₁)= c₀+ c₁ mod q
5.3 方案的安全性
[5]中的安全性证明可直接应用于我们在此讨论的更简单的加法性同态方案。特别是,[5]中的引理3.6 证明了该方案的安全性。我们不提供详细的安全性证明。在第9节中,我们利用了[19],[24]–[26]中的进一步参数选择和噪声管理优化,这些优化不会影响[5]中给出的安全性证明。
6 网络电话信号混音器与加法性编码
设网络电话音频信号的采样和数字化表示为一系列 y位整数[v₁, v₂,…]。定义 vi=[vi₁, vi₂,…, viₘ]表示一个样本块,编码([vi₁,…, viₘ])=[zi₁,…, ziₙ]= zi,其中 zi是模 p的明文,加密([zi₁,…, ziₙ])=[ci₁,…, cin]= ci,其中 ci是模 q的密文。样本加法器是网络电话系统中最简单的混合函数。我们将其用作明文混合操作的模型。
定义1。 Mix
:我们按如下方式定义Mix操作,其中 j= bt/2c:
Mix(z₁,…, zₜ)=
{
z₁, if t= 1
Mix(c₁,…, zj)+ Mix(zj+1,…, zₜ), otherwise
}
我们的目标是证明,对于我们的Encode和 Decode函数,在与Mix结合使用时,针对合适的参数设置和任意样本 v₁, v₂,…, vₜ(其中 t是表示活跃说话者数量的变量),以下性质成立:
Decode(Mix(Encode(v₁),…, Encode(vₜ))) = v₁+ v₂+ · · ·+ vₜ
在设计Encode和Decode操作时,应避免在将 Mix函数应用于已编码但未加密的明文数据时,明文信号发生wrap‐around。具体而言,对于明文样本zj₁, zj₂,…,如果存在某个 j使得∑i zij> p成立,则 Mix操作输出的编码后的明文数据会发生 wrap‐around p。如果在明文数据上发生这种 wrap‐around,则即使不进行解密,所得到的混合音频信号也会出现失真。如果明文数据中出现了这种失真,则由于公式2的性质,在对加密输入信号应用EvalMix操作后所产生的加密输出信号中也将存在该失真。
为了确保由于明文环绕而不会产生失真,我们设计了Encode和Decode,以保证在假设同时发言的网络电话会议参与者不超过 t人的情况下,使用我们定义的EvalMix操作时,公式1始终成立。请注意, t是一个可以随着VoIP功能的使用而改变的变量,只要客户端就 t值达成一致,以确保统一的编码和解码操作即可。我们设计的Encode和Decode能够适用于任意选择的 t。我们的设想是,参数 t将在每个会话中进行设置。我们实验性地评估了不同 t值下的各种场景,其中会话中的活跃说话者超过 t人,以研究该变量对方案可用性的影响。
定义 2. 编码
:我们不妨假设输入是在模 2ʸ下采样的。我们将编码 操作定义为[z₁, z₂,…, zₙ]:=编码([v₁, v₂,…, vₘ])其中
zi= ∑ j∈{ kn+i|0≤c,kn+i≤m} vj ∗ 2ᵏ⁽ʸ⁺ˢ⁾ mod p
请注意,我们在编码中使用(y+ s)位的数据样本表示方法,即使我们假设来自音频源的样本具有 y位的表示方法。这是为了添加额外的填充位,以便在最多对 t ≤2ˢ个说话者的编码样本进行相加时,拥有额外的最高有效位
避免 ∑i zij> p 对于某些 j。通常我们将 t 设置为 2 的幂,因此在支持每个会话最多 4 个活跃说话者的情况下,我们设置 t= 4,使得 s= 2。
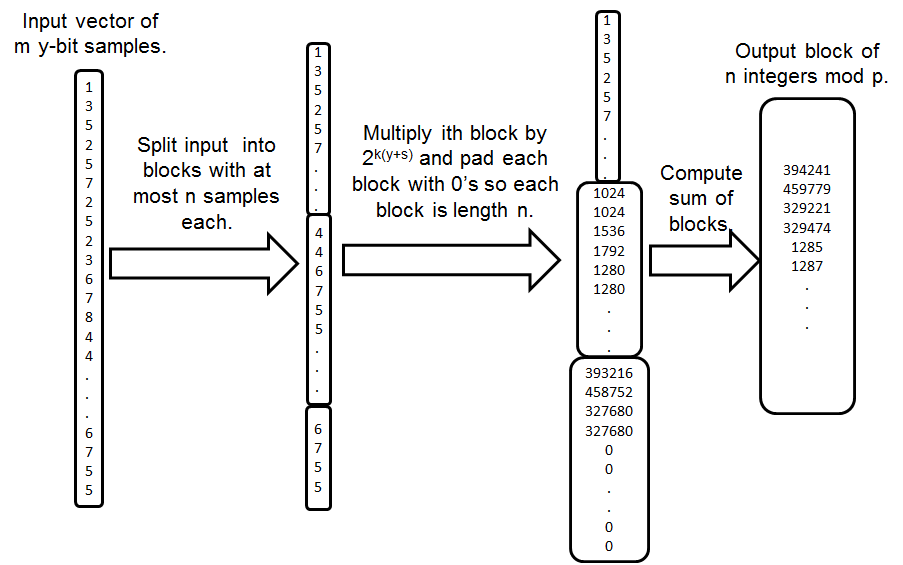
该方案的图示如图1所示,具体执行步骤如下:
- 我们首先将长度 m网络电话数字化音频样本输入 [v₁, v₂,…, vₘ] 分割成块[v₁, v₂,…, vₙ],[vₙ₊₁, vₙ₊₂,…, v₂ₙ],…,[v₁₊ₖₙ,…, vₘ]。每个块包含 n 个样本,最后一个块除外,其长度为 m mod n(当 m mod n> 0 时),否则最后一个块的长度为 n。这意味着除非 m 是 n 的倍数,否则 < n 个样本的最后一个块就是无法放入前若干个长度为 n 的样本块中的剩余样本。
- 对于第 i个块,我们将该块中的所有样本乘以 2ᵏ⁽ʸ⁺ˢ⁾,使得在二进制表示中, k(y+ s)最低有效位均为零,且y最高有效位是原始样本的左移结果,并带有两个填充位。
- 我们将每个块中每个索引的样本全部相加。
请注意,我们可以按照编码函数的表述方式对(y+ s)个整数输入进行编码。在编码后数据元素zi的二进制表示中,位于[k(y+ s) + 1: k(y+ s) + y]的比特位表示第(kn+ i)个样本。为了记号上的简化,我们称zi到第 b位,其中最低有效位为第1位。我们在编码输出的二进制表示之间插入额外的二进制00填充,使得对于所有 i、 j和 k,均有zi j [k(y+ s)+ y+1: k(y+ s) + y+ s]=[00]。这样做的目的是,对于四个已编码的样本z₁i 、 z₂i 、 z₃i 、⋯⋯、 zₜi ,我们知道其求和结果z′i = z₁i + z₂i + z₃i + · · ·+ zₜi ,即输出
由混合操作产生,在位置[k(y+s)+1: k(y+s)+y+s]处具有位,用于容纳对第(kn+ i)个样本求和后可能产生的溢出。我们将这两个用于捕获溢出的填充位称为溢出位。因此,我们的编码方案要求明文模数 p必须满足条件p ≥ 2ᵇ⁽ʸ⁺ˢ⁾,其中 b= dm/ne。
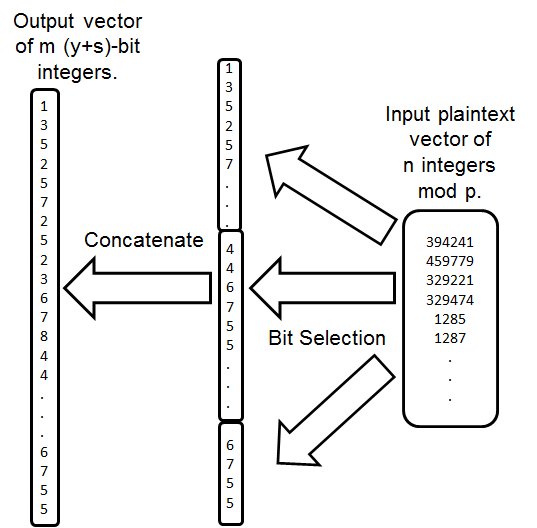
解码操作是 编码 操作的逆操作。解码 操作将 [k(y+ s)+ 1:(k+ 1)(y+ s)] 位置中的比特作为第 (kn+ i) 个返回的样本。注意,解码 操作的输出对 mod 2ʸ⁺ˢ 取模,这需要额外的 2 个比特。我们这样做是为了使解码的输出能够容纳编码输入的求和结果而不发生回绕。
定义 3。解码
:我们定义解码 操作如下:
[v₁, v₂,…, vₘ]:=解码([z₁, z₂,…, zₙ])其中
vₖₙ₊ᵢ= zi[k(y+ s)+ 1:(k+ 1)(y+ s)].
图2展示了我们的解码过程如何实现。在该图的右侧,我们取输入向量。对该块进行复制并执行位选择。与编码操作类似,这些操作都非常高效,因为它们仅涉及位选择,而位选择在实现上极为高效。
我们现在可以证明,通过以下定理1和定理2,方程1成立。定理1表明编码方案具有加法性,定理 2表明解码和编码方案的组合具有加法性。我们利用这些性质来证明加密的网络电话系统在使用与明文Mix操作对应的同态加密时,不会扭曲混合加密信号。
定理1
。 给定 v₁,… , vₜ,
Encode(v₁)+ · · ·+ Encode(vₜ) mod p = Encode(v₁+ · · ·+ vₜ mod 2ʸ⁺ˢ).
证明
。根据定义,对于 vh=[v₁ₕ, v₂ₕ,…, vₘₕ], zh=[z₁ₕ, z₂ₕ,…, zₙₕ],
ziₕ= ∑ j∈{kn+i|0≤c,kn+i≤m} vⱼₖ ∗ 2ᵏ⁽ʸ⁺ˢ⁾ mod p
定义 A={kn+ i|0 ≤ c, kn+ i ≤ m},通过将这两个方程相加
∑ h∈{1,…,t} ziₕ mod p = ∑ h∈{1,…,t} (∑ j∈A vⱼₕ ∗ 2ᵏ⁽ʸ⁺ˢ⁾) mod p =∑ j∈A ((∑ h∈{1,…,t} vⱼₕ) ∗ 2ᵏ⁽ʸ⁺ˢ⁾) mod p
因此,
Encode(v₁)+ · · ·+ Encode(vₜ) mod p = Encode(v₁+ · · ·+ vₜ mod 2ʸ⁺ˢ).
定理2 。如果 t ≤ 2ˢ,解码(编码(v₁) + · · ·+编码(vₜ) mod p) =(v₁+ · · ·+ vₜ mod 2ʸ⁺ˢ)。
证明
。根据定理1,编码(v₁)+ · · ·+编码(vₜ)mod p=编码(v₁+· · ·+ vₜ mod 2ʸ⁺ˢ)因此,
Decode(Encode(v₁)+ · · ·+ Encode(vₜ) mod p) = Decode(Encode(v₁+ · · ·+ vt mod 2ʸ⁺ˢ))
如果我们把 z′ = Encode(v₁ +· · ·+ vₜ mod 2ʸ⁺ˢ)和 v′ = Decode(Encode(v₁ + · · ·+ vₜ mod 2ʸ⁺ˢ))进行赋值,那么根据 Decode操作的定义,我们知道
v′ₖₙ₊ᵢ = z′i[k(y+s)+1:k+1(y+s)] = (∑l∈{1,…,t} vlₖₙ₊ᵢ) mod 2ʸ⁺ˢ.
7 低深度同态加密VOIP信号混合器
如上所述,定义 vi =[vi₁, vi₂,…, viₘ]以表示一个样本块,Encode([vi₁,…, viₘ])=[zi₁,…, ziₙ]= zi,其中 zi是模 p的明文
加密(pk,[z₁ᵢ,…, zₙᵢ])=[c₁ᵢ,…, cᵢₙ]= cᵢ其中 cᵢ是一个 mod q密文。
我们滥用记号,并在不失一般性的前提下假设所有加密操作均使用一个公共公钥 pk进行,因此我们将Enc(pk, zi)表示为Enc(zi)。对于解密操作,我们也采用类似的记号简化,假定使用一个共同的私钥 sk,使得Dec(sk, ci)在记号上简化表示为Dec(ci)。
为了支持端到端加密的网络电话会议,我们使用编码函数Encode、解码函数Decode和混合函数 Mix,结合加密函数Enc和解密函数Dec ,定义一个操作EvalMix ,该操作是明文Mix操作的同态加密等价形式。我们的目标是设计EvalMix操作,使其在适当参数化和任意样本 v₁, v₂,…, vₜ下满足以下性质,其中 t是一个表示活跃说话者数量的变量:
Decode(Dec(EvalMix(ci,…, ct))) = Decode(Mix(v₁, v₂,…, vₜ))
在此方程中, ci= Enc(Encode(vi))表示对样本vi进行编码后的加密。该EvalMix函数对这些密文执行加密的同态混合,当解码并解密后,其结果与样本数据在未经过编码和加密的情况下直接混合的结果相同。
定义 4。EvalMix
:我们将同态混合函数 EvalMix定义为先前定义的 EvalAdd操作的推广,其中 j= bt/2c。
EvalMix(c₁,…, cₜ)=
{
c₁, if t= 1
EvalAdd(EvalMix(c₁,…, cj), EvalMix(cj+1,…, ct)), otherwise
}
请注意,我们的EvalMix操作可以通过在不同线程上评估递归分支来优化并行执行。
我们在定理4中证明了公式2对我们的EvalMix操作成立。为了证明这一点,我们首先需要证明:如果将加密信号输入到EvalMix函数中,则解密输出为明文信号的和。然后,在定理4的证明中利用这一性质,证明如果将编码后的网络电话信号作为输入馈送到EvalMix操作中,则解密和解码输出即为VoIP信号的混合。
定理3
。对于输入的明文 z₁,…, zₜ和明文模数 p ,假设进行了适当参数化,以在重复应用 EvalAdd操作后实现正确解密,
Dec(EvalMix(Enc(z₁),…, Enc(zₜ)))=(z₁+ · · ·+ zₜ mod p).
证明
。我们通过关于 t的广义归纳法证明来演示这一点。
对于基础情况, t= 1,EvalMix(c₁)= c₁ mod q 根据定义成立。根据我们加密方案解密的正确性,Dec(Enc(z₁))= z₁mod p,因此 Dec(EvalMix(Enc(z₁)))=(Dec(Enc(z₁))mod p)= z₁。
假设对于 t′< t,
Dec(EvalMix(Enc(z₁),…, Enc(zₜ′))=(z₁+ · · ·+ zₜ′ mod p).
根据EvalMix的定义,我们知道
EvalMix(c₁,…, cₜ) = EvalAdd(EvalMix(c₁,…, cj), EvalMix(cj+1,…, ct)).
通过代入,
EvalMix(Enc(z₁),…, Enc(zₜ)) = EvalAdd(EvalMix(Enc(z₁),…, Enc(zj)), EvalMix(Enc(zj+1),…, Enc(zt))).
因此,
Dec(EvalMix(Enc(z₁),…, Enc(zₜ)) = Dec(EvalAdd(EvalMix(Enc(z₁),…, Enc(zj)), EvalMix(Enc(zj+1),…, Enc(zt)))).
根据EvalAdd操作的正确性,
Dec(EvalMix(Enc(z₁),…, Enc(zₜ)) = Dec(EvalMix(Enc(z₁),…, Enc(zj))) + Dec(EvalMix(Enc(zj+1),…, Enc(zt))) mod p.
根据归纳假设,
Dec(EvalMix(Enc(z₁),…, Enc(zₜ))=(z₁ + · · ·+ zj+ zj+1 + · · ·+ zₜ mod p).
定理4
。 对于 t ≤ 2ˢ,
Decode(Dec(EvalMix(Enc(Encode(v₁)), …, Enc(Encode(vₜ)))))) = Mix(v₁, v₂,…, vₜ)
证明。我们从定理3得知
Dec(EvalMix(Enc(z₁),…, Enc(zₜ))) = z₁+ · · ·+ zₜ mod p.
通过代入,
Decode(Dec(EvalMix(Enc(Encode(v₁)), …, Enc(Encode(vₜ))))) = Encode(v₁)+ · · ·+ Encode(vₜ) mod p).
根据定理1可知,(Encode(v₁)+· · ·+Encode(vₜ) mod p)= Encode(v₁+· · ·+vt mod 2ʸ⁺ˢ)因此,
Decode(Dec(EvalMix(Enc(Encode(v₁)), …, Enc(Encode(vₜ))))) = Encode(v₁+ · · ·+ vt mod 2ʸ⁺ˢ).
根据定理2,对于 t ≤ 2ˢ,有Decode(Encode(v₁) +· · ·+Encode(vₜ) mod p) =(v₁+ · · ·+ vt mod 2ʸ⁺ˢ),因此,
Decode(Dec(EvalMix(Enc(Encode(v₁)), …, Enc(Encode(vₜ)))))=(v₁+ · · ·+ vt mod 2ʸ⁺ˢ).
根据定义,(v₁+ · · ·+ vt mod 2ʸ⁺ˢ) = 混合(v₁, v₂,…, vt)因此如果 t ≤ 2ˢ,
Decode(Dec(EvalMix(Enc(Encode(v₁)), …, Enc(Encode(vₜ))))) = Mix(v₁, v₂,…, vt) .
利用定理4,我们现在可以提供加密的网络电话混合功能,使得远程会议参与者能够在单个信道上收听来自其他参与者的多个混合音频信号。我们方案的一个重要特点是支持全双工通信,意味着参与者在接收混合信号的同时也可以进行传输。
从实际可用性角度而言,电话会议参与者不希望自己自己的声音通过混合操作反馈给自己。即使回传延迟低至10毫秒,该反馈信号也会使说话者感到不适,尽管在正常对话中来自其他参与者的类似延迟通常不易被察觉。因此,我们需要同时支持多种混合操作,使得客户端语音流(v₁,…, vₜ)中,第 i个客户端接收到的混合信号为∑j∈{1,…,t}{i} (vi)。
EvalAdd操作在 EvalMix函数都非常高效,因为它们仅涉及向量分割、乘以二和按位连接,这些操作在实现上都极为高效。针对多个接收者的这种求和方式在计算上是高效的,仅依赖于求和操作,并且也可以以并行方式进行。我们在第9节中更深入地讨论了与具体参数选择相关的工程权衡。
8 端到端加密的网络电话会议原型
我们使用 MathWorks MATLAB 环境实现了安全网络电话会议原型中的加法同态密码系统部分,因为该环境原生支持向量和矩阵操作。MATLAB 语法非常适合我们基于 LTV 的密码系统设计所需的原始格操作。我们使用 MATLAB Coder 工具包生成了实现的 ANSI C 版本,并使用 gcc 编译生成的 ANSI C 代码,使其可在 Linux 环境中作为可执行文件运行,用于参数 t 调优。
我们通过将我们的同态加密库以及编码/解码 功能与一个现有的开源VoIP电话会议库集成,构建了端到端加密VoIP电话会议能力。我们选择 Mumble VoIP库进行此集成,因为Mumble技术成熟、提供高音质,并可在多种平台上运行。我们重点研究iOS客户端,因为这些客户端是Mumble客户端中最成熟的开源版本。
通过与 Mumble 库集成,我们的端到端加密网络电话库具有与标准 Mumble 功能相同用户界面、使用模式和部署模式。尽管我们未将此应用程序公开发布,但修改后的 Mumble 软件可以通过应用商店模式进行部署,或作为二进制文件使用开发工具加载到 iOS 设备上。
客户端集成相对简单,但有几个值得注意的例外情况,旨在减少丢包并提高音质:
- 客户端应用程序生成的语音数据包包含480个样本,采样率为48千赫,相当于10毫秒的音频。然而,客户端上的声卡驱动生成的数据包略大。因此,声音数据包的周期略大于10毫秒,并且偶尔会连续生成两个声音数据包。原始服务器设置了10毫秒的定时器,每10毫秒接收一个数据包。我们在服务器上添加了一个小队列,这样当我们在不到 10毫秒内接收到两个数据包时,不会丢包。
- 我们在服务器上生成了新的帧编号,而不是重用客户端的帧编号。客户端将帧编号与时间相关联。此修改减少了时间抖动。
- 加密和解密操作是处理器密集型的,因此我们一次性对多个音频数据包进行批处理。我们将加密和解密操作移至低优先级线程,同时使用高优先级线程接收并队列化新的音频数据包(包括来自网络和麦克风的数据包)。这有助于防止客户端因忙于解密或加密而导致音频数据包丢失的情况。
- 我们通过一种近似的离散高斯操作改进了噪声样本生成的效率,该操作将来自客户端伪随机数生成器的32位均匀分布样本通过查找表映射为多个离散高斯样本。
我们的改进通过提升音质和效率并减少丢包,使得音频采样率得以提高,并降低了加密延迟。因此,客户端能够以48千赫的速率生成16位音频样本,这是Mumble VoIP客户端的标准配置。该吞吐量提供的音质明显优于公共交换电话网络。
9 面向端到端加密网络电话会议的参数化与适配
通过为编码/解码和密码系统操作选择参数,我们将初始的高级端到端加密VoIP电话会议能力目标具体化,以实现以下目标:
- VoIP信号数据以足够高的速率进行采样,从而将充分高的语音质量编码到明文中。
- 端到端VoIP传输的端到端延迟不得超过经典的 150毫秒限制[20]。
- 我们的目标吞吐量不会比AES加密操作所需的吞吐量大太多,即密文膨胀小于10,或总带宽使用低于 6.4兆比特每秒,这可以由大多数商用无线数据传输协议支持 [27]。
- 明文通过足够大的工作因子被安全加密为密文,以防止未经授权的解密。这意味着 δ ≤ 1.007 对于80位安全性 [19]。
- 多个加密的网络电话流的同态混合可以在会话期间成功地被解密和解码。我们讨论了在任何时间实例最多支持 t= 4个活跃说话者的情况,但此参数可推广。
- 所有这些操作都需要在通用硬件(如配备64位处理器的iOS和Linux设备)上高效运行。这意味着最大的密文模数必须小于 2⁶⁴。
为了实现这些更具体的目标,我们调整的参数是:
- q,密文模数。
- p,明文模数。
- n,环维度。
- y,网络电话采样位深度。
- φ,网络电话采样率。
- m,每网络电话块的采样数。
- s,编码方案中的填充位数。
因此,我们将约束条件设定为:
- q < 2⁶⁴,在64位处理器上实现最优执行的最大密文模数。
- p > 2ᵈᵐ⁄ⁿᵉ⁽ʸ⁺²⁾,根据第9节中 Encode操作的定义,用于4个主动发言客户端的无损编码。
- q > 4pr√nw,用于正确解密,其中r= 3是离散高斯噪声参数, w= 4.5是我们从[4],[5]中采用的加密系统的保证参数。
- n > (log q)/(4log δ),用于安全性 [25],[28]。
- s ≥ log₂(t),因为编码中样本间的0填充比特以及我们的正确性证明在最大数量的说话者同时讲话时仍然成立。
在这些优化约束下,我们希望:
- 最小化 Encode、Enc、EvalMix、Dec和Decode的运行时间。我们在[4]中发现,加密操作的运行时间在 n上呈线性关系。对于Encode和Decode运行时间的朴素算法在 n上也呈线性关系。因此,我们尝试在满足所有其他约束的同时最小化 n。
- 最小化(qn)/(2ʸ⁺²m),即密文膨胀。
- 保证吞吐量 φ2ʸ不会导致足以对语音质量产生负面影响的丢包。
我们基本上固定 φ并通过实验评估语音质量。鉴于大量变量、针对我们可分析的变量(如密文膨胀)的高度非线性优化约束,以及实验性评估条件的普遍存在,例如丢包率、语音质量和软件运行时间,我们通过明文操作进行了初步实验,以确定初始的数据采样率和编码参数。我们实验性地观察到,支持超过4个活跃说话者在实际应用中意义不大,因为对于任何一个听众来说,很难跟上如此多参与者同时发言的对话。我们通过实验确定,使用40毫秒块、48 KHz VoIP数据、5位深度的明文混合能够提供足够用于正常对话的良好音质。原生应用以每10毫秒数据为一组提供采样数据,但我们合并4个10毫秒的块,形成每个音频块包含1920个样本的 m。
我们使用环维度 n= 1024 ,每个块包含1920个样本,并得到一个明文模数 p= 2¹⁴= 16384。然后将q设置为1236950597633,这需要41位来表示。这些参数导致根Hermite因子的上限为 δ= 1.00696,目前认为该值具有足够的安全性,并提供至少80位的安全性[19]。从音频输入(5位的1920个样本)和密文输出(41位的1024个样本)来看,最终的密文膨胀比约为4.37。
在这些参数设置下,我们观察到在iPhone 5s上运行时,编码与加密操作平均耗时9.2毫秒,解密与解码耗时4.6毫秒。VoIP服务器上的加法运算耗时 0.5毫秒。从马萨诸塞州剑桥市传输加密VoIP流量到北弗吉尼亚的亚马逊AWS服务器平均需要15毫秒。这使得VoIP流量的总平均延迟小于150毫秒。这些参数满足我们的性能目标。实验表明延迟处于较高水平,说话较快的用户需要放慢语速才能进行对话,尽管这种语速显得不自然。
10 端到端加密的网络电话电话会议实验
我们实验性地评估了部署在全球各地亚马逊AWS数据中心的VoIP服务的性能。我们在iPod Touch和 iPhone 5s客户端上安装了客户端软件,并通过波士顿大都会区(美国新英格兰地区的主要城市)的各种连接类型将每个客户端连接到各个服务器。这些连接包括通过高速企业互联网连接的802.11n无线企业网关、4G LTE,通过T-mobile商业无线服务以及康涅狄格州农村地区的AT&T DSL连接的3G和2G连接。
我们测量了上传和下载吞吐量、丢包率以及由实验者定义的主观音频质量。上传和下载吞吐量通过客户端上的Ookla吞吐量测量应用[29]进行测量。VoIP掉线率通过在VoIP服务器上植入工具以测量掉线率来实验性地获取。语音质量则相对于公共交换电话网络语音质量进行评估,其中“优秀”表示 VoIP通话质量优于公共交换电话网络,“良好”表示VoIP通话质量与公共交换电话网络相当,“较差”表示VoIP通话质量比公共交换电话网络差但仍可用于通信,“不可用”表示连接完全无法用于通信。
所有实验均在工作日晚上持续2小时进行,使用两个iPodTouch客户端,并将服务器部署在亚马逊 AWS t1.micro实例[30]上。客户端始终通过独立的互联网连接运行,因此一个客户端对另一个客户端造成显著拥塞或丢包的可能性很低。
表1:连接类型的实验性测量数据吞吐量(兆比特/秒)
| 连接类型 | 上传速率 (Mb/s) | 下载速率 (Mb/s) |
|---|---|---|
| 企业级802.11n | 38.22 | 36.53 |
| 4G LTE | 35.82 | 17.00 |
| 3G | 6.31 | 0.43 |
| 2G | 0.20 | 0.16 |
| 农村DSL | 2.55 | 0.47 |
我们观察到,除2G连接外,所有最后一公里无线连接均提供了可接受的网络电话会议功能。在所有可接受的连接中,最低的上传或下载吞吐量出现在3G下载:0.43兆比特/秒。由于网络电话的下载和上传数据流是对称的,这意味着使用我们的原型进行网络电话会议至少需要0.43兆比特/秒的上传和下载吞吐量连接。
表2:不同服务器位置和客户端互联网连接类型的丢包率
| 服务器位置 | 客户端位置 | 企业级802.11n | 4G LTE | 3G | 2G | 农村DSL |
|---|---|---|---|---|---|---|
| 北弗吉尼亚 | 康涅狄格州 | 0% | 10% | 10% | 66% | 33% |
| 俄勒冈州 | 康涅狄格州 | 0% | 2% | 3% | 71% | 35% |
| 加利福尼亚北部 | 康涅狄格州 | 0% | 7% | 8% | 67% | 34% |
| 爱尔兰 | 康涅狄格州 | 0% | 7% | 7% | 73% | 38% |
| 新加坡 | 康涅狄格州 | 5% | 2% | 2% | 68% | 39% |
| 东京 | 康涅狄格州 | 1% | 3% | 4% | 69% | 37% |
| 悉尼 | 康涅狄格州 | 5% | 3% | 3% | 67% | 34% |
| 圣保罗 | 康涅狄格州 | 0.30% | 4% | 6% | 76% | 34% |
我们观察到,客户端与服务器之间的距离对丢包率影响较小,而连接类型则具有非常大的影响。在丢包率方面达成协议。这意味着连接可能成为网络电话服务的瓶颈。
通过在各个亚马逊AWS位置的每台服务器观察到的不同客户端连接类型的主观网络电话会议质量,对语音质量没有观察到影响。相反,我们发现连接类型对语音质量有非常大的影响。企业级802.11n、4G LTE和3G均提供了足够的语音质量,而2G和农村DSL连接提供的语音质量较差,甚至无法使用。
除了对连接‐服务器配对进行测试外,我们还测试了在任意时刻有超过 t= 2ˢ个客户端同时发言的影响。我们在美国东部不同地点使用3台iPod Touch和4台iPhone 5s客户端,连接至位于亚马逊 AWS北弗吉尼亚数据中心的单个VoIP服务器建立会话。在7个客户端连接同时运行的情况下,当4个用户同时发言时,仍能保持有效的对话,且未观察到语音失真。当6个用户同时发言并有1个客户端静默收听时,除非这6个客户端说话音量极大近乎喊叫,否则未出现因混合导致的音频裁剪现象。然而,当超过4名参与者同时发言时,由于参与者无法在心理上跟踪如此多人的同时讲话,导致交流效果显著下降。因此,在实际网络电话会议中,将同时发言的说话者数量限制为4个是一个合理的选择。
11 安全分析
尽管我们的原型创新旨在应对观察所有服务器行为的诚实但好奇的攻击者,但我们的设计可以进一步扩展以提供更广泛的安全性。例如,如果攻击者攻陷了一个客户端,即使该攻击者能够观察到所有其他客户端的网络流量,在至少存在另外两个客户端的情况下,攻击者也无法确定是哪个客户端在说话。这是由于无法基于密文观测将混合后的信号映射回其原始来源。两个不同信号的加密结果彼此之间以及与白噪声加密结果之间是不可区分的。
最近的出版物提出了子域格攻击[31],[32]的概念。尽管这些攻击对某些依赖DSPR[5]的NTRU密码系统变体具有相关性,但我们的参数设置并不满足这些攻击的条件。
对端到端加密VoIP电话会议活动的一种可能的有效攻击方式是:被攻破的客户端向电话会议混合器中注入噪声,从而降低各客户端参与者之间相互交流的能力。此类攻击是电话会议系统普遍存在的漏洞。一种可行的长期应对方法是支持同态滤波以抵御噪声注入,并可能提供某些功能,使客户端能够告知混合器他们希望收听哪些其他参与者。在短期内,应用认证技术来识别潜在对手可能有效解决这些问题。
另一个问题是密钥分发。我们密码系统中的密钥相对较小:41*1024比特。这些密钥可以通过现有的公钥基础设施,使用加密的平面文件轻松分发,甚至可以利用Diffie‐Hellman类型的技術生成共享密钥。此外,通过将方案推广为依赖LTV方案[5]的多密钥特性,可以取消先前对密钥协调的假设。
12 讨论与正在进行的活动
本文提出并讨论了一种可扩展的VoIP电话会议方法,该方法提供端到端加密。我们评估认为,如第3节所述,已实现我们在实际性和安全性方面的设计目标。
我们分层架构愿景的另一个方面是能够在服务器端混合搭配计算基板,以提高可扩展性和吞吐量。尽管我们仅使用了有限深度的加法同态加密能力,但我们的加密系统实现实际上是全同态加密(FHE)系统[4]的一个简化版本。通过软件修改和参数选择上的调整以维持安全性,我们的电话会议实现可以推广以支持FHE操作。工程上的权衡在于,当服务器计算更深的电路时,端到端延迟会增加。
[4]显示乘法评估操作的运行时间目前过长,无法在VoIP服务器上执行这些操作。如果乘法评估操作的运行性能能提升一到两个数量级,则执行比同态混合更深的电路所产生的延迟将变得可接受。这为加密数据上的更深层次操作提供了一条设计路径。
一个初步的可行应用是使用低通滤波器实现加密噪声抑制。低通滤波器,例如加权移动平均,可以在深度较浅且仅包含少量乘法运算的电路中支持此操作。该操作可通过将编码和加密后的样本乘以明文多项式[0, 1, 0, 0,…, 0](该多项式被编码为CRT表示)来生成单个样本的时间延迟。可以获取多个此类延迟样本,并对多个延迟进行求和计算,得到密文,解密后可获得平均样本。如果编码和解码操作经过充分补偿以支持更多加法运算,则该操作实质上构成一个低通滤波器,可用于抑制噪声。
这种更通用的设计能够防范诸如噪声注入等潜在的实际攻击。更深层次的操作,例如在加密数据上运行的语音识别操作,将需要非常深的电路,以至于当前的同态加密实现必须使用自举操作来维持安全性。在当前的全同态加密实现中,自举操作所需时间比 EvalMult操作长多个数量级,因此要使更深的电路满足网络电话延迟约束变得实用,还需在自举实现方面取得多项突破,或甚至需要全新的、更高效的全同态加密方案。自举功能有望首先在定制的高性能硬件中实现实用化,例如基于定制FPGA或ASIC 的协处理器[33],[34]。当与一种此前未实现过的自举方案的变体结合使用时[35],我们的设计提供了实现更通用的VoIP电话会议能力的可能性,该能力可在加密的网络电话信道上集成信号检测和噪声滤波操作。我们的端到端加密的网络电话功能基于分层的软件服务栈,通过底层基于格的原语实现支持高层的同态加密操作,从而为与其他硬件加速协处理器的集成提供了基础。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









